This Quickstart guide contains key tips for optimal performance when using Snowpark Python. The guide is broken up into multiple labs, each covering a key concept that can improve performance and/or efficiency while running workloads in Snowpark.
Prerequisites
- Understanding of Snowpark Python Dataframes
- Understanding of Python UDFs
- Understanding of Python UDTFs
- Understanding of Snowpark Python Local Testing Framework
- Familarity with using Notebook IDEs and Snowflake Notebooks
What You'll Learn
In this quickstart, you will learn how to make optimized decisions when using Snowpark Python. These choices will be compared with others to show performance improvements. Each concept is broken up into a lab, listed below:
- Lab 1: Using Vectorized UDFs in Snowpark and scenarios that suit Vectorization
- Lab 2: Using Regular and Vectorised UDTFs to significantly boost performance of your Snowpark workloads
- Lab 3: Using Cachetools library to improve performance
- Lab 4: Using the local testing framework to test your DataFrame operations on your development machine or in a CI (continuous integration) pipeline before deploying code changes to your account
What You'll Need
- A Snowflake account with Anaconda Packages enabled by ORGADMIN. If you do not have a Snowflake account, you can register for a free trial account.
- A Snowflake account login with ACCOUNTADMIN role. If you have this role in your environment, you may choose to use it. If not, you will need to 1) Register for a free trial, 2) Use a different role that has the ability to create database, schema, tables, stages, tasks, user-defined functions, and stored procedures OR 3) Use an existing database and schema in which you are able to create the mentioned objects.
Step 1: Cone Github Code
In your preferred local directory, clone the code repository by running the below command in Mac terminal or Windows Shell.
git clone https://github.com/sfc-gh-hayan/sfguide-snowpark-python-top-tips-for-optimal-performance.git
Step 2: Snowflake Environment Setup
Create a fresh database in your Snowflake account for the following labs. Login to Snowsight and issue the following command:
CREATE DATABASE SNOWPARK_BEST_PRACTICES_LABS;
We'll also standardize the warehouse we will use for the following labs. Run the following command:
CREATE OR REPLACE WAREHOUSE compute_wh WAREHOUSE_SIZE=SMALL INITIALLY_SUSPENDED=TRUE;
Step 3: Import notebooks for the lab1, lab2, lab3.
We will use Snowflake Notebook for first three labs and jupyter notebook in your local python environment for lab4. All those full notebooks are under notebook folder in your local repository. Import notebooks for Labs 1,2 and 3 using Snowsight.
While importing,for notebook location:
- Specify default warehouse as
COMPUTE_WHas created above. - Specify the default database as
SNOWPARK_BEST_PRACTICES_LABSand default schema asPUBLIC. This is where notebooks will be stored, you can also specific any database and schema that your role has access to.
Lab Summary
The Snowpark API provides methods that help to create a User Defined Function which allows developers to extend the functionality of Snowflake by writing custom functions in languages such as Java, Scala, and Python. These functions enable users to specify custom business logic for data transformations. When you create UDFs, the Snowpark library uploads this code to an internal stage. Following which, you can call these executables on the Snowflake server side where the data resides. As a result, the data doesn't need to be transferred to the client in order for the function (read UDF) to process the data.
Naturally, you're wondering then, what is a Vectorised UDF?
The Python UDF batch API or Vectorised UDFs enables defining Python functions that receive batches of input rows (aka chunked rows) as Pandas DataFrames and return batches of results as Pandas arrays or Series. This helps to significantly improve performance in comparison to UDFs that perform row by row execution.
The goal of this lab is to compare the performance of a UDF Operation with and without using the Python UDF Batch API (or Vectorised UDFs).
In this notebook, we will do the following:
- We will work with 4 datasets, namely Customers and Orders from the TPCH Datasets of different sizes (15M to 1.5B records) freely and instantly available in Snowflake through an inbound share.
- We will use 3 different Virtual Warehouse sizes, i.e., Small, Medium, and Large.
- We will execute 4 different use-cases, namely, Numerical Computation, String Manipulation, Regex Masking, and Timestamp Manipulation. Please note, these are hypothetical use-cases but are commonly found when working with data in Snowflake.
Prerequisites
- Your snowflake user needs to have access to database SNOWFLAKE_SAMPLE_DATA. For instructions to import SNOWFLAKE_SAMPLE_DATA, please click here.
- By now, you should have finished setting up Snowflake Notebook you will run.
What You'll Do
This lab consists of the following major steps:
- Importing libraries and connecting to Snowflake
- Creating the dataframes of test data from the TPCDS dataset
- Setting up the virtual warehouses prior to testing
- Running four test suites on typical UDF operations
- Numeric Computation (~3 minutes)
- String Manipulation (~5 minutes)
- Batch Sizing (~5 minutes)
- Timestamp Manipulation (~60 minutes)
- Analyzing the results, forming conclusions, and cleanup
Run the lab
In Snowsight, open a notebook called lab1_vectorized_udfs_snow.ipynb and run each of the cells.
Analysis
Below is analysis of the tests ran in the notebook. Please compare these findings with the results in your notebook.
Recap
Before we look into the results, let's recap what we have done so far:
- We took 4 different TPCH datasets of varying sizes.
- Used 3 different Virtual Warehouse sizes, i.e., Small, Medium, and Large.
- On 4 different hypothetical use-cases.
- Generated results that will allow us to compare the performance of a UDF Operation with and without using Vectorised UDFs.
Numeric Computation Use Cases
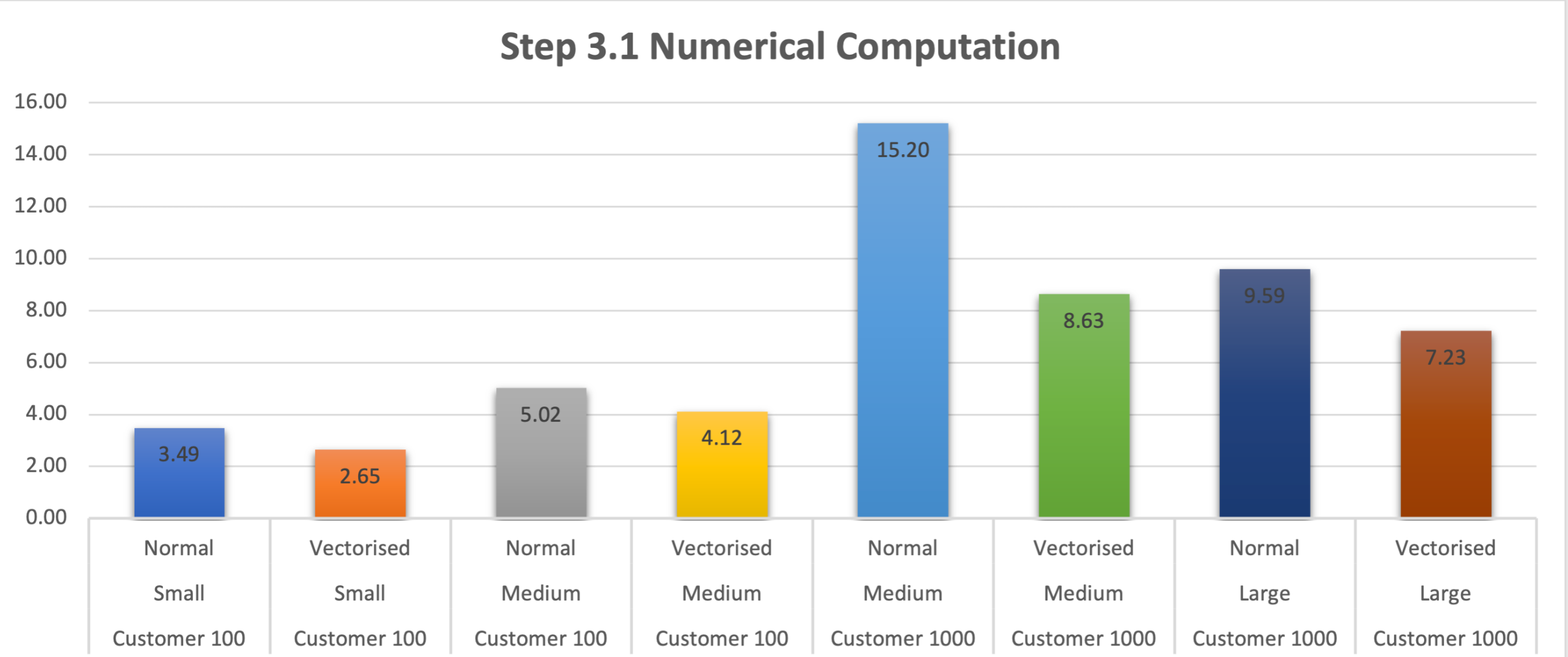
- For Numerical Computation, keeping the same dataset and warehouse size, Vectorised UDFs outperform Normal UDFs
- This is also seen when we change the size of the warehouse (to Large) to accommodate the change in dataset size (to Customer 1000)
- MemoryViews through the Buffer Protocol allows Python code to expose the internal data (array or buffer) of an object without intermediate copying. Without going into too much depth, this allows us to enable faster computations and reduced memory usage on large numerical datasets (including Boolean [0, 1]) efficiently. For more details, please see this part of the documentation and this article.
- What is peculiar is the behavior when working with a Medium warehouse and Customer 100 dataset. Where it performs slightly less efficiently than a Small Warehouse. This could have several reasons, but what we noticed in the Query Profile was:
- It takes the Medium warehouse up to 35% of the time to initialize as compared to ~10% of time for a Smaller warehouse.
- Another is the time it took to create the python sandbox environment, i.e. ~900ms on a Medium warehouse compared to <400ms for a Smaller warehouse.
- The last one especially could compound across the UDFs that get created and to cause the slight difference in performance.
- Of course, this previous point above doesn't carry across the other dataset and warehouse size.
- Another interesting point we see in the above chart is the difference in performance between Vectorised UDFs Medium and Large Clusters for the Customer 1000 dataset. The Medium cluster performs better than the Large cluster. This is the law of diminishing returns in play, where increasing WH size will eventually "out-scale" the data, in the sense that the number of vCPUs exceeds the number of batches, and so you no longer see any improvement in performance.
- Optional Work: Leverage
GET_QUERY_OPERATOR_STATS()table function for a more detailed and thorough analysis.
Non-Numeric Computation Use Cases

As expected, it makes sense not to use Vectorised UDFs for Non-numeric operations
- But apart from the obvious, let's check out what the Query Profile looks like for the String Manipulation for Customer 100 Dataset when using a Small warehouse:
- The Total (and by extention Average) UDF Handler Execution Time was about half for a Normal UDF when compared to the Vectorised UDF
- The Average UDF encoding/decoding time was less than 1/100th of a millisecond for a Normal UDF when compared to 5 ms for a Vectorised UDF
- We have to appreciate the difference of orders of magnitude here and especially when compounded, really makes the difference in performance between a Normal and Vectorised UDF
- The Python Sandbox environment creation time was 1/3rd for Normal UDFs when compared to Vectorised UDFs
- It is also important to note that the Bytes scanned and written were almost the same, and the partitions were the same as no partitioning had been done to this dataset.
- Optional Work: Leverage
GET_QUERY_OPERATOR_STATS()table function for a more detailed and thorough analysis.
Batch Sizes
Additionally, when using Vectorised UDFs, you may want to play around with Batch Sizes.
- This is done with the input argument to the decorator @udf like so:
@udf(max_batch_size=1000)
def vect_udf_bc_100(inp: PandasSeries[float]) -> PandasSeries[float]:
return (inp - df_customer_100_mean + df_customer_100_stddev) * 10000.0
It is important to note:
- Setting a batch size doesn't guarantee which records will be present in a particular batch
- It also doesn't guarantee that a batch size will be of the same size. For instance, if the argument
max_batch_size = 50000, does not mean 50k records are sent per batch - An increase in batch size doesn't guarantee improvement in performance
- A very very low batch size (e.g. ~50-200) does slow performance depending on the size of the dataset. While a moderately sized batch (e.g. ~2000) does improve performance. This is what I have seen in my tests
- Typically, Snowflake automatically picks a batch size for you which is performance efficient and should suffice in most cases
- There are some use cases where we've seen customers set batch sizes using UDTF partition-by logic. This helps to guarantee contiguous batch sizes, although not exactly a common best-practice but can make sense in some use cases. More on how partition-by works in the next lab - "Vectorised UDTFs".
Conclusion
- For Numerical Computations, you can expect between 30% and 40% improvement in performance using Vectorised UDFs
- Don't forget the note on the law of diminishing returns.
- For Non-Numeric Computations/Manipulations, you're more than likely to see a degradation in performance when comparing between the two UDF types we discussed, and we would recommend sticking with non-vectorised UDFs.
- Native code looping - For numeric computation, vectorised UDFs through Pandas pass the logic to numpy arrays that loop over the data using machine-level code. This prevents back and forth of expensive Python code and hence improves performance of vectorised UDFs on numeric data. This doesn't happen for non-numeric data and essentially you are running code row by row but with the added overhead of Python.
- Memory footprint - Vectorised code uses more memory and if you're using heavyweight strings, it results in a massive memory footprint.
- If you're working with Numerical Computations, I would also experiment with different Warehouse and Batch Sizes to get more performance as a result. But remember, higher sizes does not always mean or always guarantee higher performance.
- Don't forget the note on contiguous batch sizes through Vectorised UDTFs.
- Lastly, make sure to dive deep into Query Profiling either through the Snowsight UI or GET_QUERY_OPERATOR_STATS() table function to squeeze in that extra bit of performance
Cleanup
Lab Summary
Snowpark Python User Defined Table Functions are a feature within Snowflake's Snowpark environment that allow users to define custom table functions using Python. UDTFs are functions that can generate multiple rows of output (a table) based on the input parameters. They are particularly useful for tasks like exploding arrays or performing complex calculations that result in multiple rows of data.
You might be wondering what is the difference between a UDF vs a UDTF:
UDF | UDTF |
Single-row (or random batch) scalar operations | Stateful processing on user-partitioned data; partitions are independent |
Pandas-type functionality only useful for vectorized UDFs | Pandas-based processing may be used in endPartition method |
Memory footprint likely not an issue, may not benefit from Snowpark-optimized warehouses, except for when using large artifacts | Potentially large memory footprint depending on number and size of partitions |
Rows are independent | Rows are related/dependent |
One-to-one | Many-to-one, one-to-many, many-to-many, one-to-one relationships all supported |
UDF returns native Snowflake rowsets | UDTF returns tuples, DFs must be iterated over |
So, what are Snowpark Python Vectorised UDTF then?
Vectorized processing is a method where operations are applied to multiple elements (vectors) simultaneously, rather than processing them one by one. In this context, vectorized processing allows for efficient handling of large datasets by performing operations on batches of data at once.
The goal of this lab is to compare the performance of a UDTF vs Vectorised UDTF Operations.
In this lab, we will do the following:
- We will work with Customers from the TPCH Datasets of different sizes (15M to 1.5B records) freely and instantly available in Snowflake through an inbound share.
- We will use 3 different Virtual Warehouse sizes, i.e., Small, Medium, and Large.
- We will execute on single use-case, namely, Numerical Computation.But we will experiment with regular UDTF, end-partition vectorised UDTF, and process method vectorised UDTF.
Prerequisites
- Your snowflake user needs to be granted to a role have write access to database SNOWFLAKE_SAMPLE_DATA. For instructions to import SNOWFLAKE_SAMPLE_DATA, please click here.
- By now, you should have finished setting up Snowflake Notebook you will run.
What You'll Do
This lab consists of the following major steps:
- Importing libraries and connecting to Snowflake
- Creating the dataframes of test data from the TPCDS dataset
- Setting up the virtual warehouses prior to testing
- Running different test suites on different UDTF types
- Batch processing
- Memory calcuations
- Redudntant calculations
- Vectorized operations
- Analyzing the results, forming conclusions, and cleanup
Some initial key pointers in the difference in vectorised UDTF performance between process method and end partition method is in the way the data is handled and processed:
- Batch Processing Overhead: The process method produces an output row for each input row, even if the actual computation does not vary row by row. This introduces significant overhead, especially if there are many rows.
- Memory Management: The process method has to repeatedly handle memory allocation and deallocation, leading to inefficiencies. In contrast, the end partition method processes the entire dataset at once, allowing for more efficient use of memory and computational resources.
- Redundant Calculations: In the process method, the same mean and standard deviation are computed and accessed repeatedly for each row, which is inherently inefficient compared to computing these values once in the end partition method.
- Vectorized Operations: The end partition method can leverage vectorized operations over the entire dataset, which is more optimized and faster in libraries such as NumPy and Pandas. The process method, despite being vectorized, doesn't fully leverage these optimizations when it processes data in a row-wise fashion.
Hence, you see the end partition approach can be significantly faster for this particular use case. This is not universal but unique to the specific contents of this UDTF.
- Furthermore, we will experiment with regular UDTF for running concurrent tasks with Worker Processes. We will also add multiple warehouse sizes here. But most importantly, we will test with multiple joblib backends.
- Lastly, we will experiment with Snowpark Optimised Warehouses.
Run the lab
In Snowsight, open a notebook called lab2_vectorized_udtfs_snow.ipynb and run each of the cells.
Analysis
Below is analysis of the tests ran in the notebook. Please compare these findings with the results in your notebook.
Recap
Before we look into the results, let's recap what we have done so far:
- We took 2 TPCH datasets of varying sizes.
- Used 3 different Virtual Warehouse sizes, i.e., Small, Medium, and Large.
- Generated results that will allow us to compare the performance of different UDTF types with and without using Vectorization.
Vectorized UDTF Type Use Cases
UDTF Type | Warehouse Size | Dataset | Duration (s) |
Regular | Small | Customer100 | 12.4 |
Regular | Medium | Customer100 | 12 |
Regular | Medium | Customer1000 | 72 |
Regular | Large | Customer1000 | 70 |
Regular Concurrent Tasks | Small | Customer100 | 12.9 |
Regular Concurrent Tasks | Medium | Customer100 | 7.67 |
Regular Concurrent Tasks | Medium | Customer1000 | 67 |
Regular Concurrent Tasks | Large | Customer1000 | 67 |
Regular Concurrent Tasks with loky | Small | Customer100 | 12.7 |
Regular Concurrent Tasks with loky | Medium | Customer100 | 7.73 |
Regular Concurrent Tasks with loky | Medium | Customer1000 | 68 |
Regular Concurrent Tasks with loky | Large | Customer1000 | 70 |
Regular Concurrent Tasks with loky | Snowpark Optimised Medium | Customer1000 | 69 |
Regular Concurrent Tasks with loky | Snowpark Optimised Large | Customer1000 | 68 |
End Partition Vectorised | Small | Customer100 | 11.7 |
End Partition Vectorised | Medium | Customer100 | 8.61 |
End Partition Vectorised | Medium | Customer1000 | 64 |
End Partition Vectorised | Large | Customer1000 | 64 |
Process Vectorised | Small | Customer100 | 154 |
Process Vectorised | Medium | Customer100 | 155 |
Process Vectorised | Medium | Customer1000 | 1726 |
Process Vectorised | Large | Customer1000 | 1550 |
Conclusion
The metrics we've gathered provide comprehensive insights into the performance of our numerical computations using different approaches and warehouse configurations:
- UDTF vs. Vectorized UDTF Performance Comparison
- Regular UDTFs:
- Regular UDTFs, both with and without multi-processing, showed consistent performance improvements with larger warehouse sizes. This trend was especially noticeable for larger datasets (Customer1000).
- The introduction of concurrent tasks and using the loky backend significantly reduced execution times for medium and large warehouses, showcasing the benefits of parallel processing. For instance, execution times dropped from 12 seconds (single-threaded) to 7.67 seconds (multi-threaded with loky) for the Customer100 dataset on a medium warehouse.
- Vectorized UDTFs:
- The end partition method for vectorized UDTFs consistently outperformed the regular UDTF approach, particularly for larger datasets. This method leverages vectorized operations efficiently, resulting in lower execution times. For example, the Customer1000 dataset's execution time reduced from 70 seconds (regular UDTF) to 64 seconds (vectorized end partition) on a large warehouse. Note, this is not universal and specific to the operations we are performing in this numerical processing use case. The opposite is also seen in other types of use cases, so you must carefully choose which UDT function to choose for which operation.
- Conversely, the process method in vectorized UDTFs performed poorly, with significantly higher execution times (e.g., 1550 seconds for Customer1000 on a large warehouse). This approach failed to leverage the full benefits of vectorized operations and faced substantial overhead due to processing each input row individually. Note, Vectorised process-by UDTFs operate over partitions and are more suited towards transformation use cases, another reason for why we are seeing these results.
- Regular UDTFs:
- Effect of Warehouse Size:
- The execution times vary across different warehouse sizes. Generally, larger warehouses allocate more computational resources, leading to faster execution times. This trend is evident in our results, where the execution times decrease as you move from the small to the medium and large warehouses. However, interestingly in some cases, Medium warehouses outperform Larger ones, and this could be attributed to right-sizing of warehouses for a specific computational task and dataset size. This is more art than science.
- Impact of Multi-processing:
- Multi-processing introduces parallelism, allowing the computation to utilize multiple CPU cores concurrently. This can lead to significant speedups, especially for tasks that can be parallelized effectively. In our case, we observed improvements in execution times when using multi-processing compared to a single-threaded approach.
- Back-end Selection:
- We experimented with different back-ends for multi-processing, default and the loky backend. It's essential to choose the most suitable backend for your specific workload and environment. The choice of backend can affect factors such as resource utilization, scalability, and compatibility.
- Snowpark Optimized Warehouses:
- Snowpark Optimized Warehouses provided optimized performance and resource allocation demonstrated by further improvements in execution times compared to traditional warehouses, even more when using the loky backend for multi-processing.
Cleanup
Lab Summary
Cachetools provides different caching algorithms and data structures to store and manage data efficiently. It uses different algorithms like Least Recently Used Cache(LRU), Least Frequently Used(LFU), RR Cache,TTL Cache. Cachetools are particularly useful for optimizing performance by storing the results of functions and reusing those results
In this lab, we will learn how to use the cachetools library in Snowpark Python UDFs and how it can be used to speed up UDF execution times when the UDF reads data from a file during each execution. For simplicity we will demonstrate this scenario using a pickle file which has the dictionary object serialized.
Background Information - Cachetools and pickle files
Cachetools
Cachetools is a Python library that provides a collection of caching algorithms. It offers simple and efficient caching methods, such as LRU (Least Recently Used) and FIFO (First In First Out), to store a limited number of items for a specified duration. The library is useful in applications where temporarily storing data in memory improves performance. It's easy to use and can be integrated into an application with just a few lines of code.
The Cachetools library with Snowpark UDF can be used for:
- Loading pretrained ML models from the stage for model inference
- Reading data which is stored in pickle file
Pickle File
A pickle file is a file format used to store Python objects as binary data. It is used in data engineering to store and retrieve data objects that can be used across different applications or scripts.For example, you might use pickle to store data objects such as pandas dataframes, numpy arrays, or even custom Python classes and functions. By using pickle, you can save these objects to disk and load them later without having to recreate the data from scratch.
Scenario
There is a ficticious system that generates transactional data along with the day of the week information for each row. To access the names of the weekdays, we are required to use a Python pickle file that is shared by the upstream data teams. This file contains the names of the weekdays, which may change in different scenarios. To ensure compatibility and security, the upstream data teams only provide access to this information through the pickle file.
To analyze this data in Snowflake Snowpark Python, we have created a Python User Defined Function (UDF) to efficiently retrieve the corresponding day name based on the day number which comes as an input. This UDF provides a convenient and reliable way to access the day names from the pickle file, allowing us to perform the necessary DataFrame transformations for our analysis.
Lately as the number of transactions are growing we are seeing performance degradation of our select queries which is using the UDF to fetch the required information from the pickle file. We need to look for ways to improve the performance of the Python UDF that we have created.
What You'll Do
This lab consists of the following major steps:
- Importing libraries and connecting to Snowflake
- Creating a pickle file
- Running a UDF without Cachetools
- Running a UDF with Cachetools
- Conclusion and Cleanup
Run the lab
In Snowsight, open a notebook called lab3_cachetools_library_snow.ipynb and run each of the cells.
Conclusion
Based on the our testing, we have identified that the total duration for the query using Cachetools decorator for this use case yields a significant performance increase for the Python UDF execution.
It is important to understand that the UDF executes code from top-to-bottom for every row/batch (if vectorised). This also includes any code that loads an artifact from disk, as in this case. So, if you have 1000 batches, without cachetools you will load the artifact 1000 times. But, with cachetools, you only load it once per Python process. This is also dependent on the warehouse size and the total nodes underneath.
Overview
The lab provides a local testing framework that allows users to leverage their compute resources from local machine to perform basic DE/DS tasks, instead of using Snowflake's built-in Virtual Warehouse. It's a great approach for users to save compute costs during development and testing phase.
Prepare Data
- Please requested access to a Snowflake marketplace dataset called ‘United States Retail Foot Traffic Data', or you can access it directly here.
- Once data share is available, run the below sql in a worksheet using the same sysadmin role. This is the database and tables we will use for this lab.
use role sysadmin;
create or replace database RETAIL_FOOT_TRAFFIC_DATA;
use database RETAIL_FOOT_TRAFFIC_DATA;
use schema PUBLIC;
create or replace table FOOT_TRAFFIC_JSON_DATA as select * from UNITED_STATES_RETAIL_FOOT_TRAFFIC_DATA.PUBLIC.FOOT_TRAFFIC_JSON_DATA WHERE json_data:state='CA' AND json_data:timestamp BETWEEN ('2021-01-01 00:00:00') AND ('2022-09-13 23:59:59');
Install Snowpark and required libraries in your local machine.
- If you don't have a local snowpark python environment, please run the below command in Mac Terminal(or Windows Shell if you are using Windows) to install Snowpark.
conda create --name env_py311 --override-channels -c https://repo.anaconda.com/pkgs/snowflake python=3.11
- In terminal, run the below scripts step by step to get into your local snowpark environment, install required libraries for local testing and start jupyter notebook.
conda activate env_py311
conda install --override-channels -c https://repo.anaconda.com/pkgs/snowflake notebook pytest python-dotenv snowflake pandas
jupyter notebook
- Open the directory where you cloned the github repo, modify connection.json file for account, user, password, role and warehouse based on your credentials.
{ "account" : "****", "user" : "****", "password" : "****", "role": "sysadmin", "warehouse": "app_wh", "database": "RETAIL_FOOT_TRAFFIC_DATA", "schema": "PUBLIC" }
Run the lab
Open up the jupyter notebook with name lab4_local_testing.ipynb in the local directory and run each of the cells.
Step 1: Running all tests locally
The below cell invokes .py jobs in test_integration folder and run the snowpark session using your local resources. Write down the time you kick off this cell.
%%bash
pytest test_integration/ --disable-warnings --snowflake-session local
Step 2: Running all tests through Virtual Warehouse
The below cell invokes .py jobs in test_integration folder and run the snowpark session using Snowflake Virtual Warehouse. Once first step 1 is done, wait 2 minutes before you kick off this job. Write down the time you kick off this cell.
%%bash
pytest test_integration/ --disable-warnings --snowflake-session live
Step 3: Go to snowsight query history to locate query history for Step 1 and Step 2.
You should be able to see query history with Step 2 using Virtual Warehouse, and you won't be able to find any query from Step 3 because it's using local compute resources and query history is not supported by local testing. Please refer to Snowflake documentation for details related to this.
Step 4: Clean up
Run the below command in a snowflake worksheet to drop the database and all objects under database SNOWPARK_BEST_PRACTICES_LABS.
DROP DATABASE IF EXISTS SNOWPARK_BEST_PRACTICES_LABS CASCADE ;
Lab Conclusion
Snowpark local testing framework provides developer a convenient way to easily toggle between live and local testing. Developers can leverage the local testing feature to save compute cost during development and testing phase.
Congratulations! You've successfully performed all the labs illustrating the best practices for getting optimal performance when using Snowpark Python. You're now ready to implement these concepts in your own projects.
What You Learned
- The performance benefits of Vectorised UDFs, and what type of operations benefit the most from them
- The performance of UDTF vs Vectorised UDTF operations using different approaches and warehouse configurations
- The performance benefits of the cachetools library
- How to test your code locally when working with Snowpark.