With the growth of your data and business, so does the complexity involved in traditional approaches and architecture. Snowflake and Fivetran have partnered to bring you the Data Cloud and the most automated data integration solution which helps customers simplify data pipelines for all your businesses so you can focus on your data and analytics instead of infrastructure management and maintenance. In this virtual hands-on lab, you will follow a step-by-step guide to perform marketing analytics for Google Ads data by using Fivetran, Snowflake, and dbt. Let's get started.
Prerequisites
To participate in the virtual hands-on lab, attendees need the following:
- Github account - Participants will need to create, or already have, an account on Github. Other git-based source control hosting sites will work fine (Gitlab, Bitbucket), but the instructions will assume Github. An account on Github is free: link. See appendix 1 for step-by-step instructions.
- Snowflake Free Trial - Registrants of the virtual hands-on lab need to sign up for a free trial. Please sign up using an email address that hasn't been used previously. See appendix 2 for step-by-step instructions.
- OPTIONAL: Log in to your Google account, if you have one.
- OPTIONAL: Google Ads account credentials.
Sample Google Ads data will be provided if you do not have a Google Ads account.
What You'll Need During the Lab
- Sample Google Ads data - a public Google Sheet with three workbooks. Each workbook will become a table in our sample Google Ads data schema. The above link takes you to a page full of Google Sheets links – all of these sheets are copies of the same data, you can use any link on that page.
- dbt Project Github Repository
- SQL Script file - Participants will load this file into a Snowflake worksheet when prompted during the lab. Save this file where you can easily find it during the lab.
What You'll Learn
- How to begin a Fivetran trial through Snowflake's Partner Connect
- How to load Google Ads data into Snowflake using Fivetran
- How to run a dbt project via Fivetran to generate models
- How to create analyst sandboxes in Snowflake using clones
- How to leverage data in Snowflake's Data Marketplace
What You'll Build
- A sophisticated marketing data analytics pipeline leveraging Fivetran, dbt, and Snowflake
- Login to your Snowflake trial account.
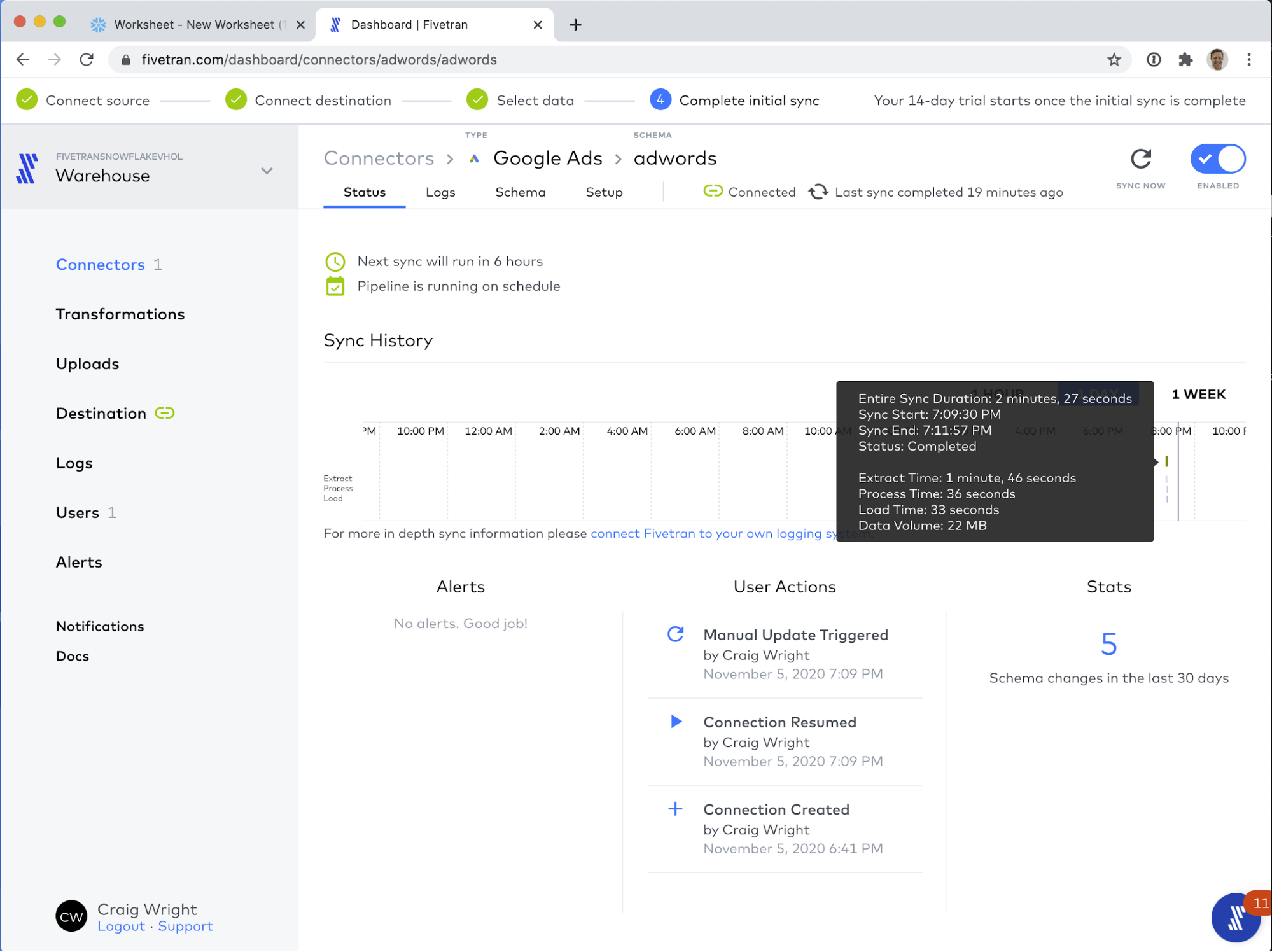
- UI Tour (SE will walk through this live). For post-workshop participants, click here for a quick tour of the UI.
- Let's change our role and enable notifications. We need to work in the ACCOUNTADMIN role for this lab and notifications are how Snowflake will alert you when resource monitor thresholds have been crossed. Click on your User Name in the upper right-hand corner.
- You'll get a popup with 4 items; click on Switch Role.
- Select ACCOUNTADMIN.
- The UI will refresh and you should see ACCOUNTADMIN under your username. If you don't, go back to step 5.

- Click on your username again and you'll get the same popup with 4 items; click on Preferences.
- Click on Notifications.
- Select All, which will send notifications to your email address and this UI (in the Notifications tile in the upper right).
- Now let's create your Fivetran account. Click on the Partner Connect tile at the top of the UI...
- ...and then click on the Fivetran tile inside Snowflake Partner Connect. (if you aren't in the ACCOUNTADMIN role you'll receive a warning. Go back and complete steps 6-9.)

- Click on Connect.
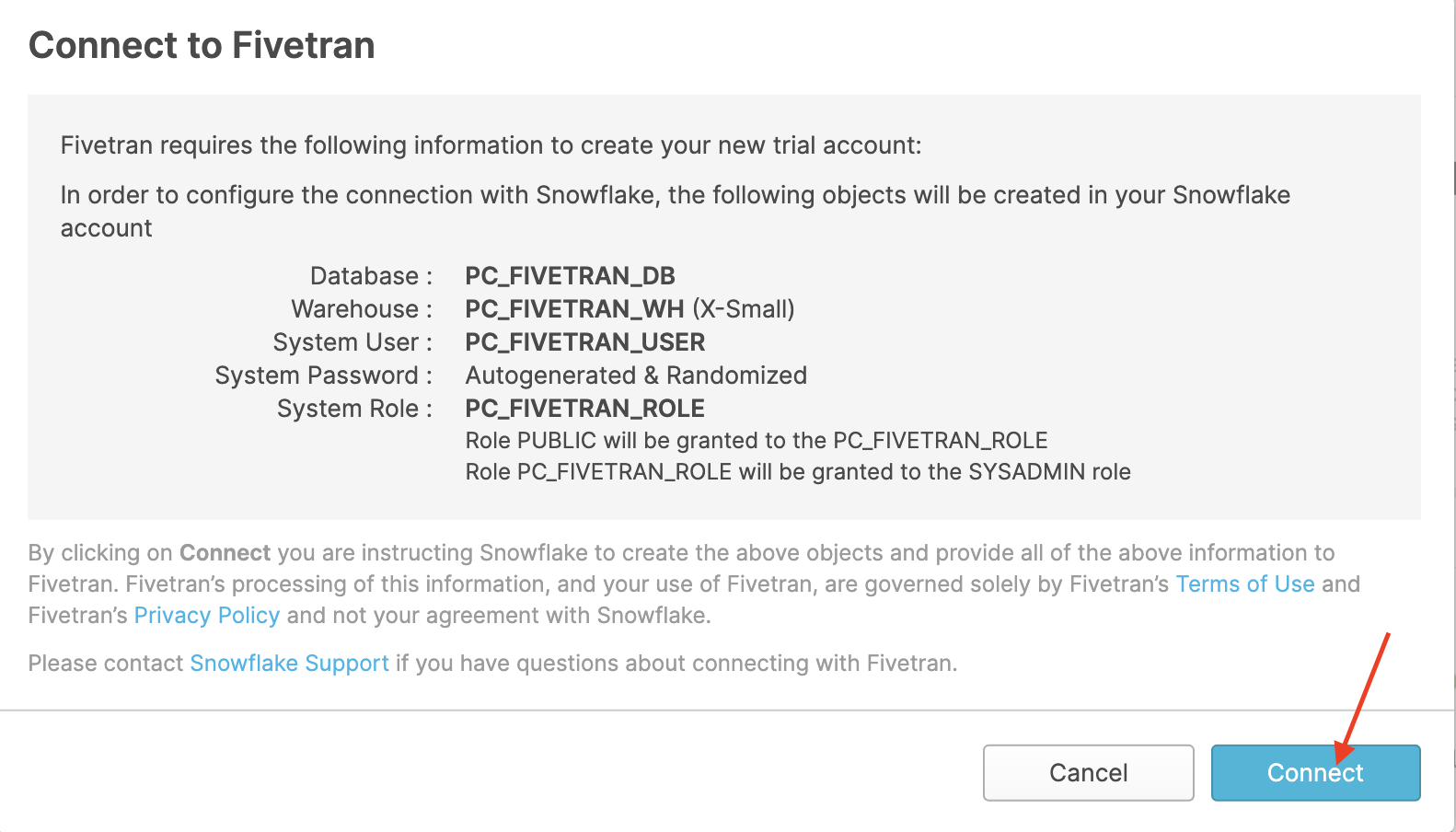
- Click on Activate in the pop-up that appears. This will open a new browser tab and take you to Fivetran where you will enter a password for the trial account.


In the next three sections we will create an automated data pipeline, with an extract-load (ELT) architecture::
- Extract and Load:
- Complete Fivetran Account Setup
- Upload Sample Adwords Data using the Fivetran Google Sheets Connector
- Transform:
- Create our first dbt project
- Setup Fivetran dbt Transformations
Let's get started!
Complete Fivetran Account Setup
- Create a password.
- That is it! Hang out on this screen until the next section. To log into Fivetran in the future, you can navigate to https://fivetran.com/dashboard. Your email is the same as your Snowflake email (at the time you connected with Partner Connect) and your password is whatever you entered in Step 1 of this section.
Note: The Setup Fivetran dbt Transformations section assumes you have uploaded the sample data as outlined in this section. If you used your own Google Ads data, that is fine; you will just need to edit the dbt_project.yml file as discussed in the next section.
For your convenience we have included sample Google Adwords data in the form of a Google Sheets containing three workbooks. Each workbook corresponds to a table to be synced to the Snowflake warehouse. This gives us the opportunity to explore another Fivetran feature, the Google Sheets connector. Google Sheets is, in fact, the most popular connector used by Fivetran customers. In the next section, we will:
- Use the Google Sheets connector to create a new Schema and Tables
- We will create one Google Sheets connector per table.
- We will use any one of the Google Sheet links found in this document: link
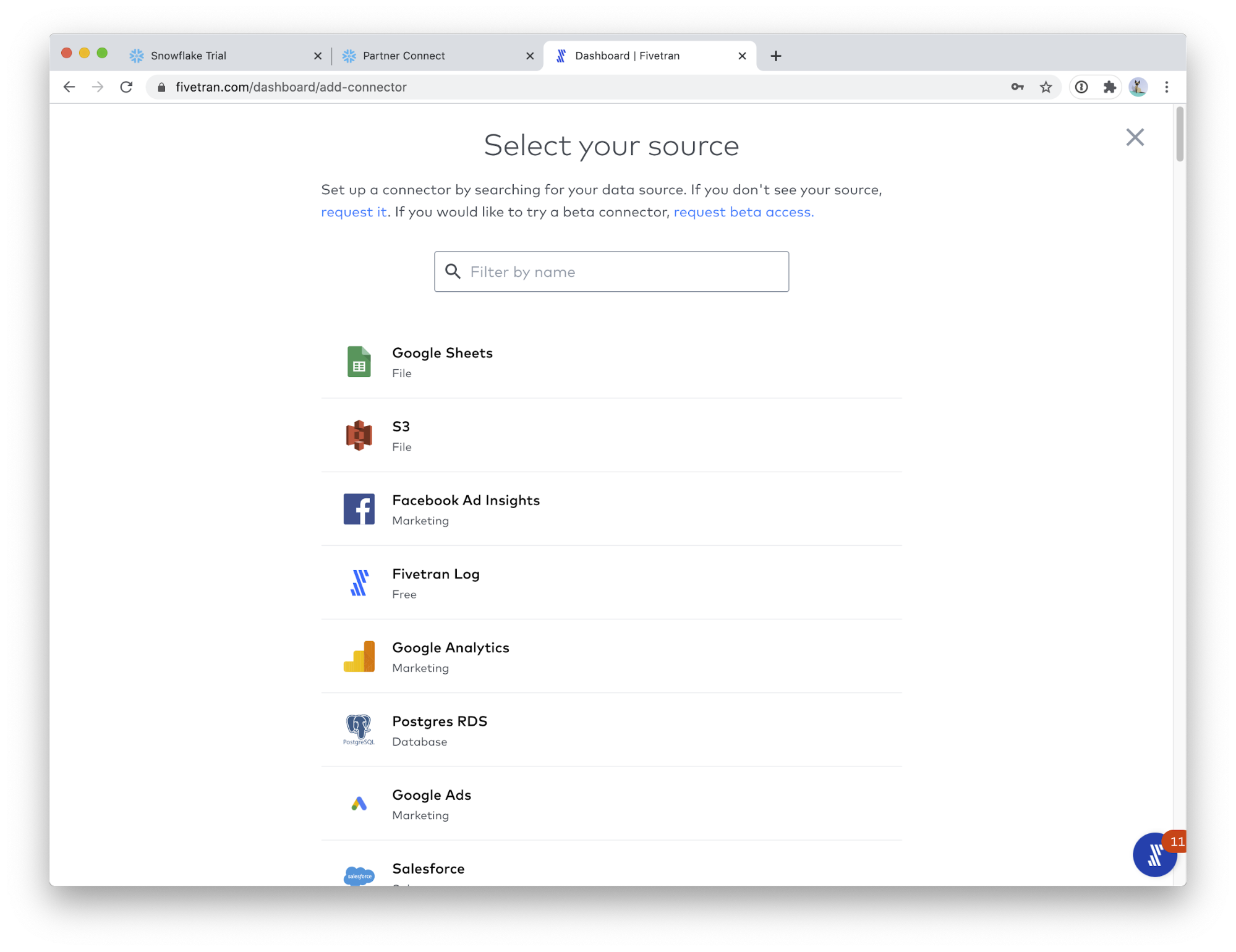
- Google Sheets is the first connector in the list! Click on Google Sheets.
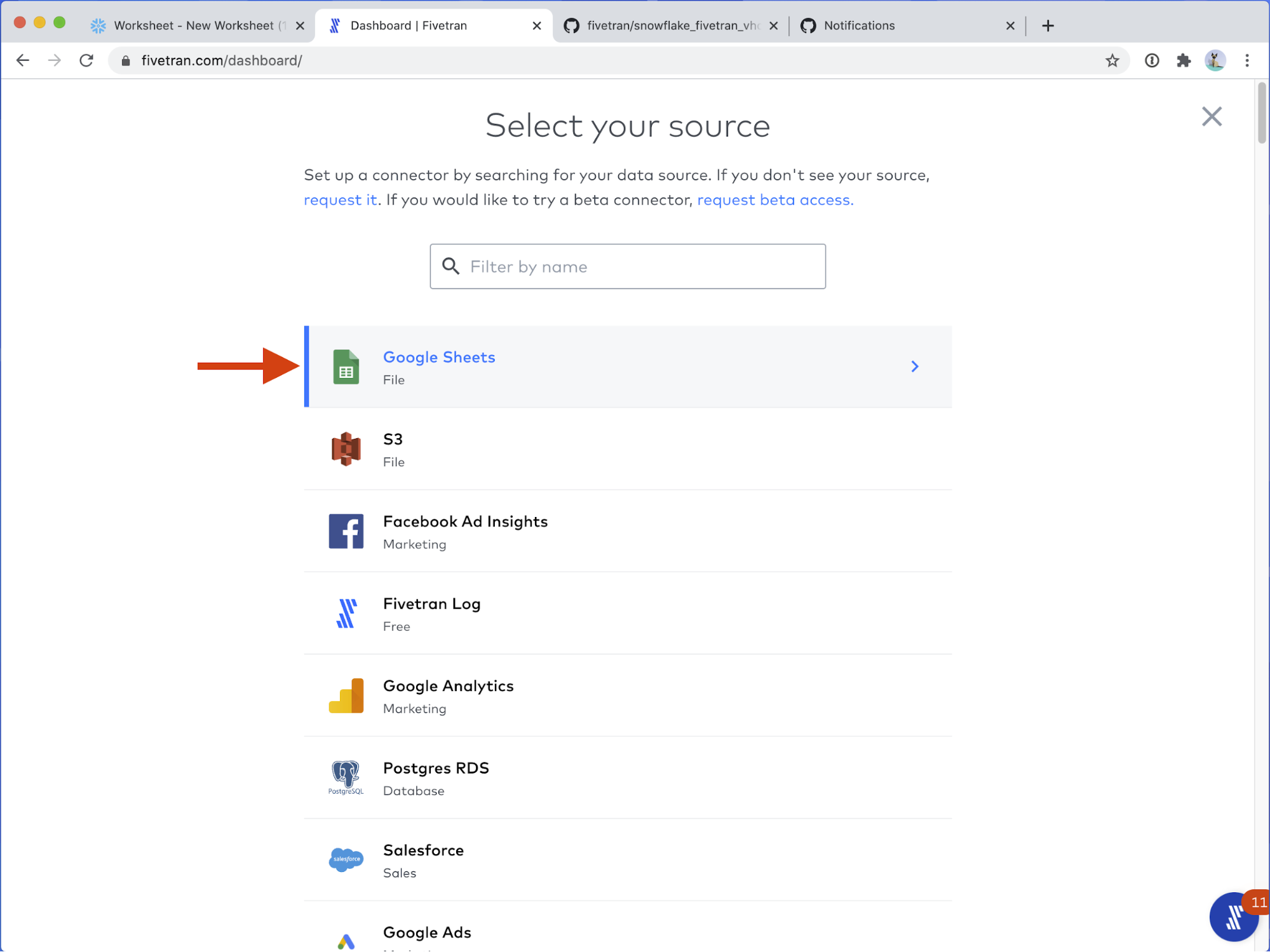
- You should see this screen.
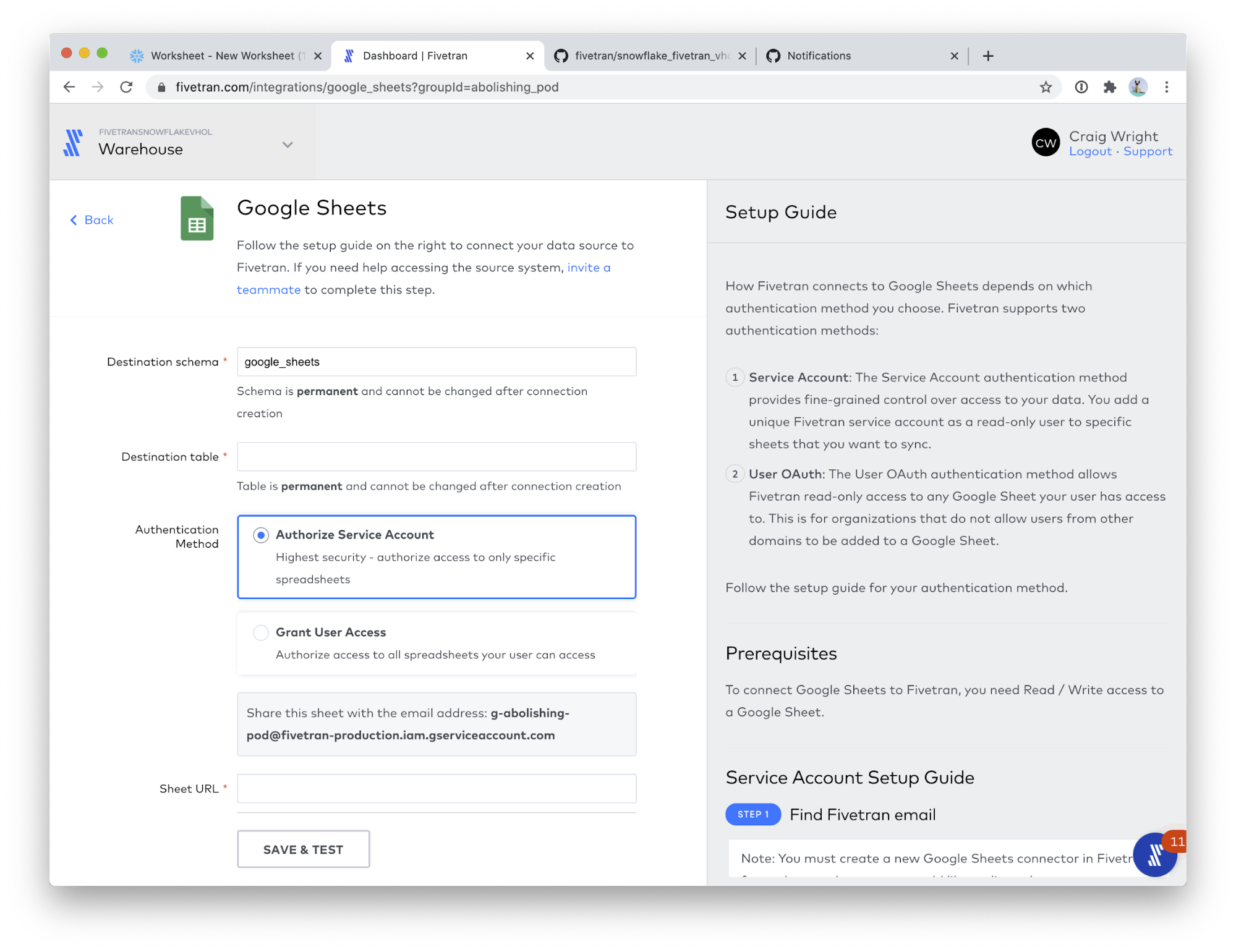
- Please use the following values for the two fields:
- Destination schema: google_ads_demo
- Destination table: final_url_performance
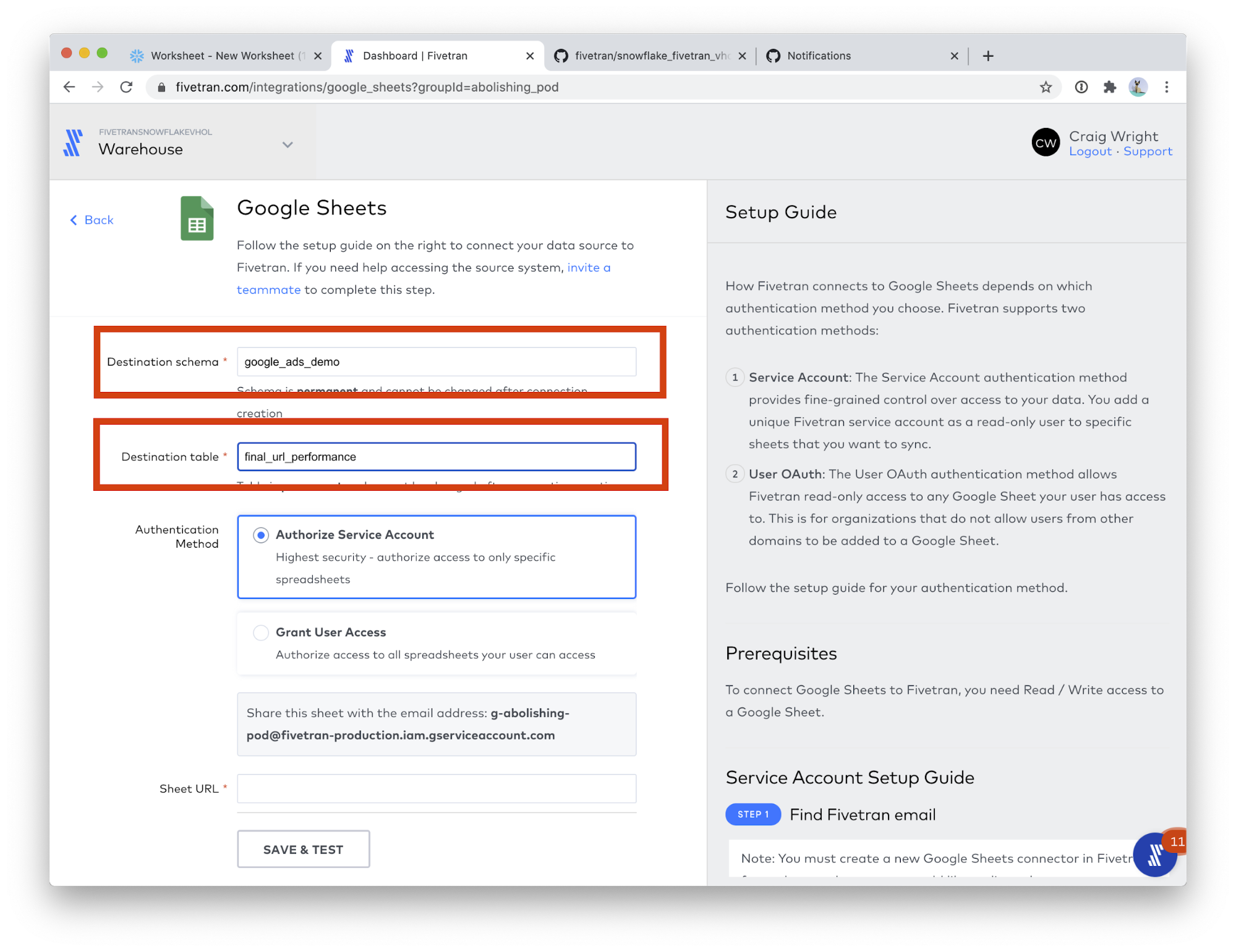
- Scroll down the page a bit, and paste the URL you just copied into the Sheet URL field. (Follow these instructions to get a Google Sheets URL) Then, click the FIND SHEET button. This step will take a few moments.
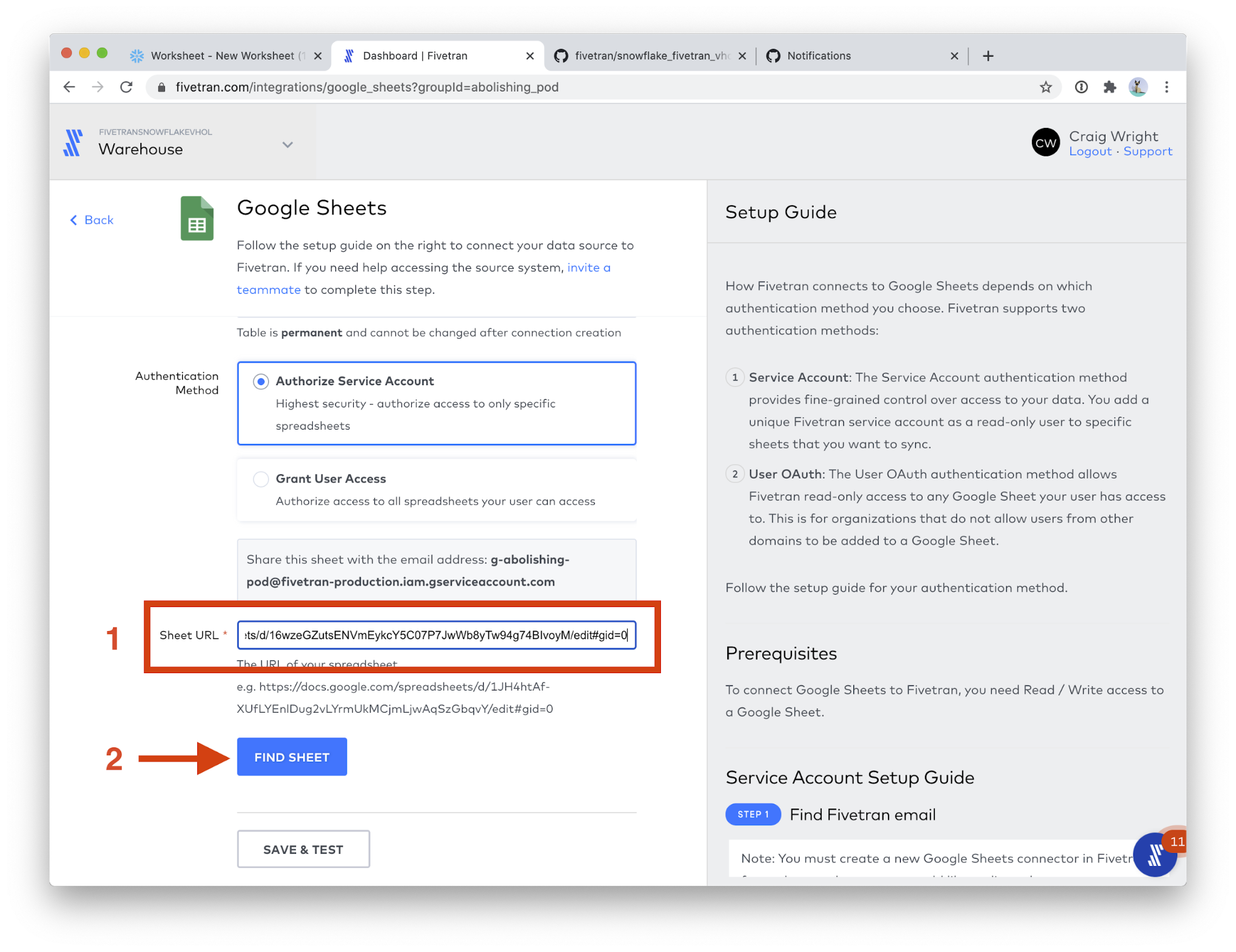
- In the Named Range field, choose final_url_performance.
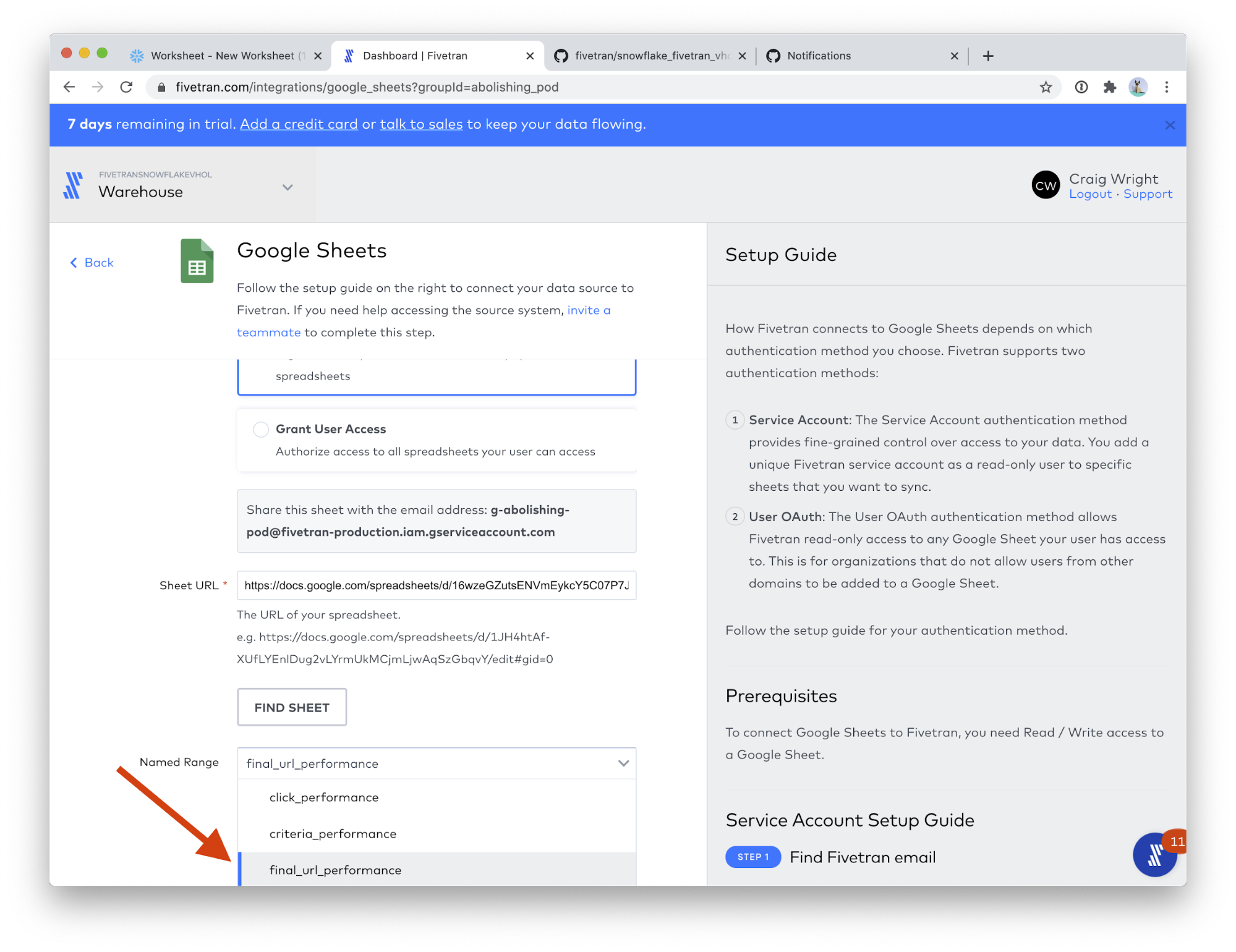
- Click SAVE & TEST.
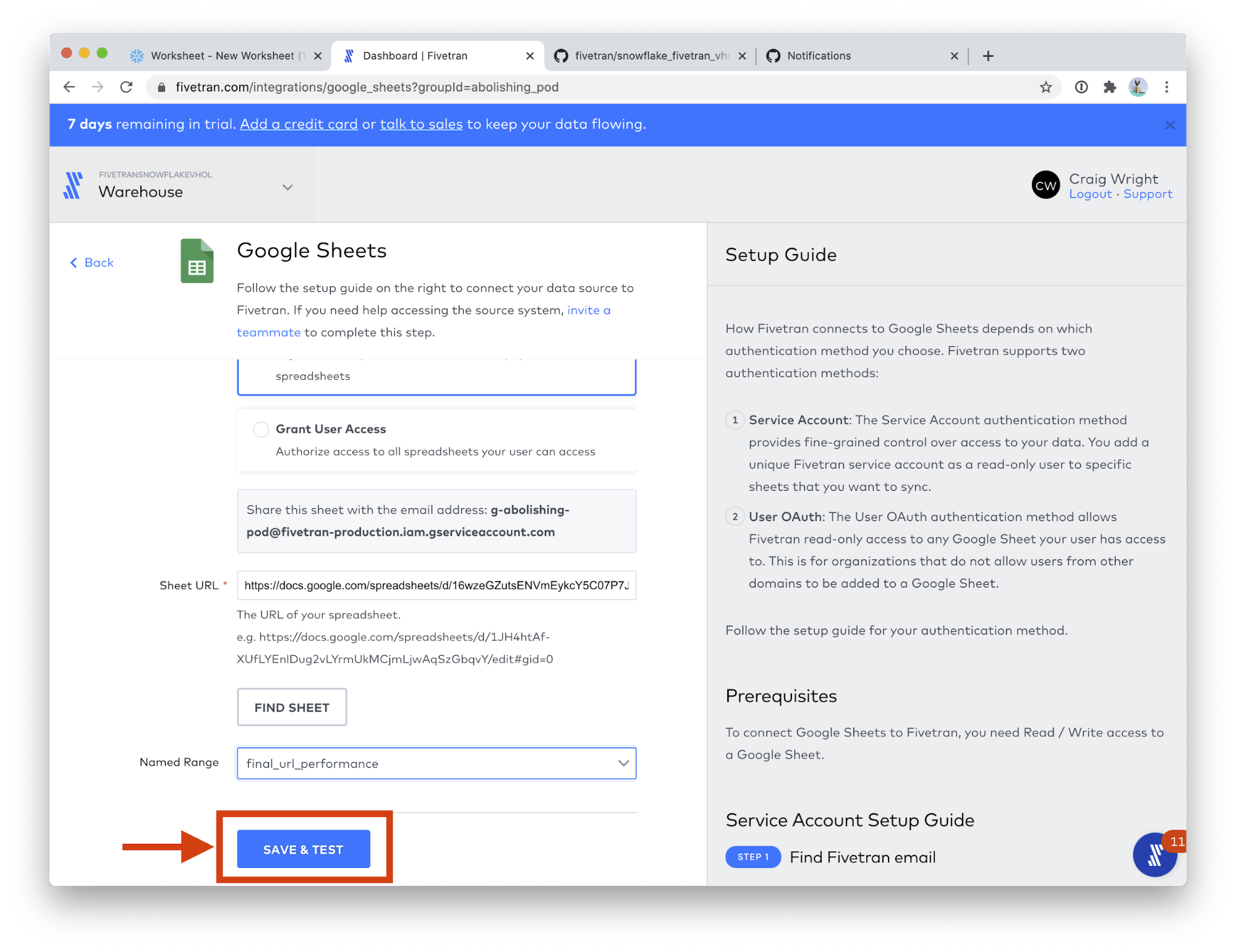
- When you see All connection tests passed!, click the VIEW CONNECTOR button.
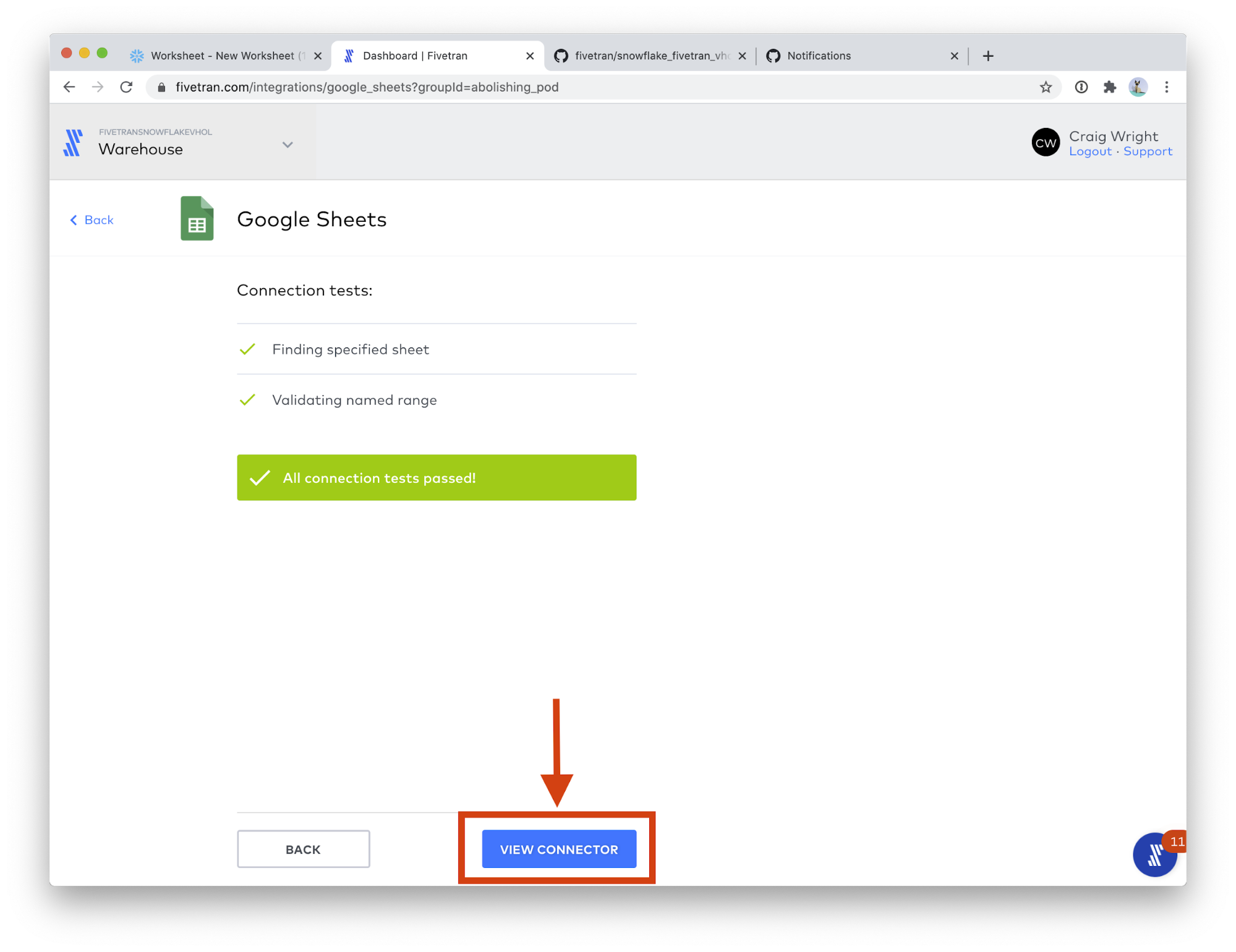
- Click Start Initial Sync. This will start the data sync into the warehouse! Now any updates to these sheets will be automatically synced to Snowflake.
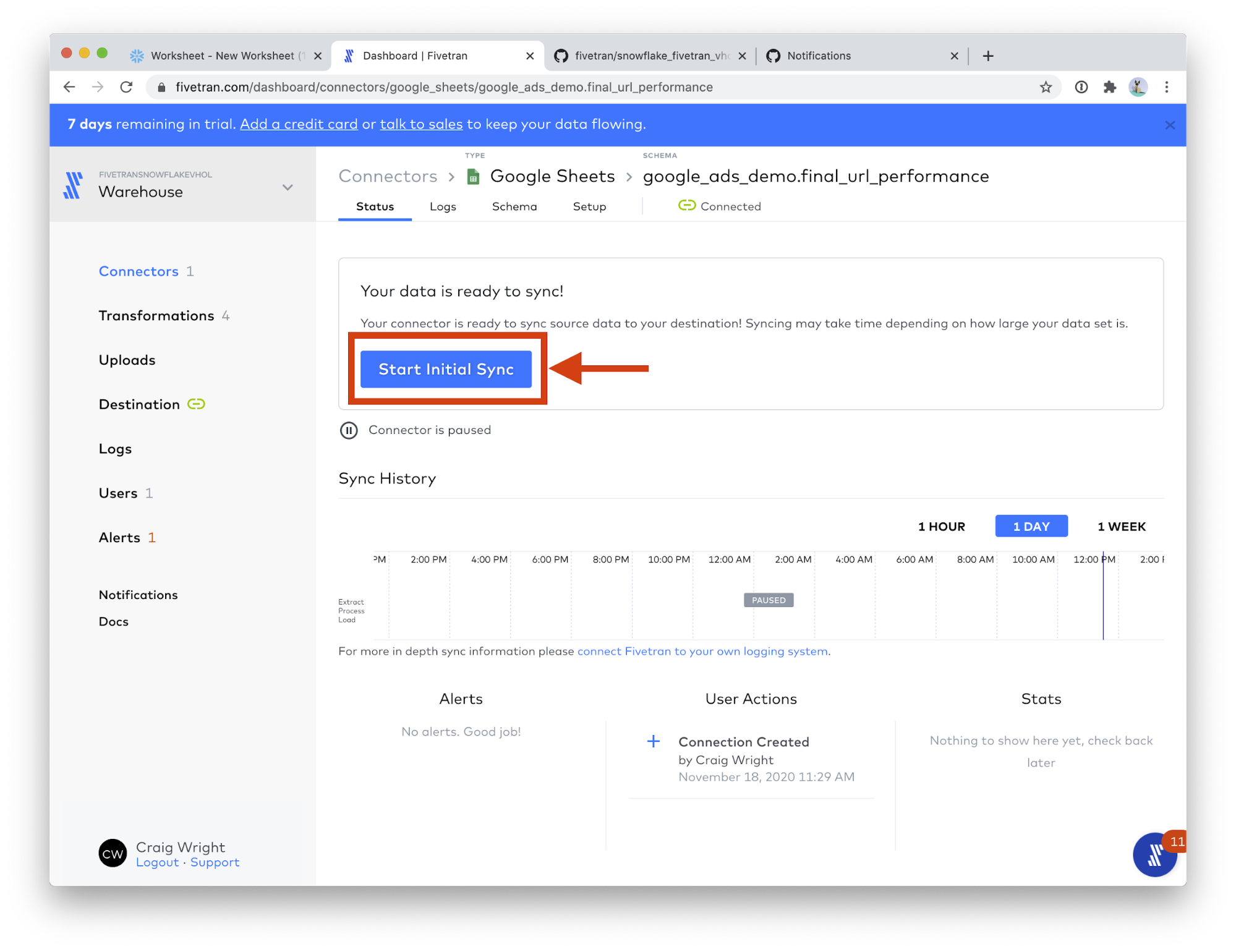
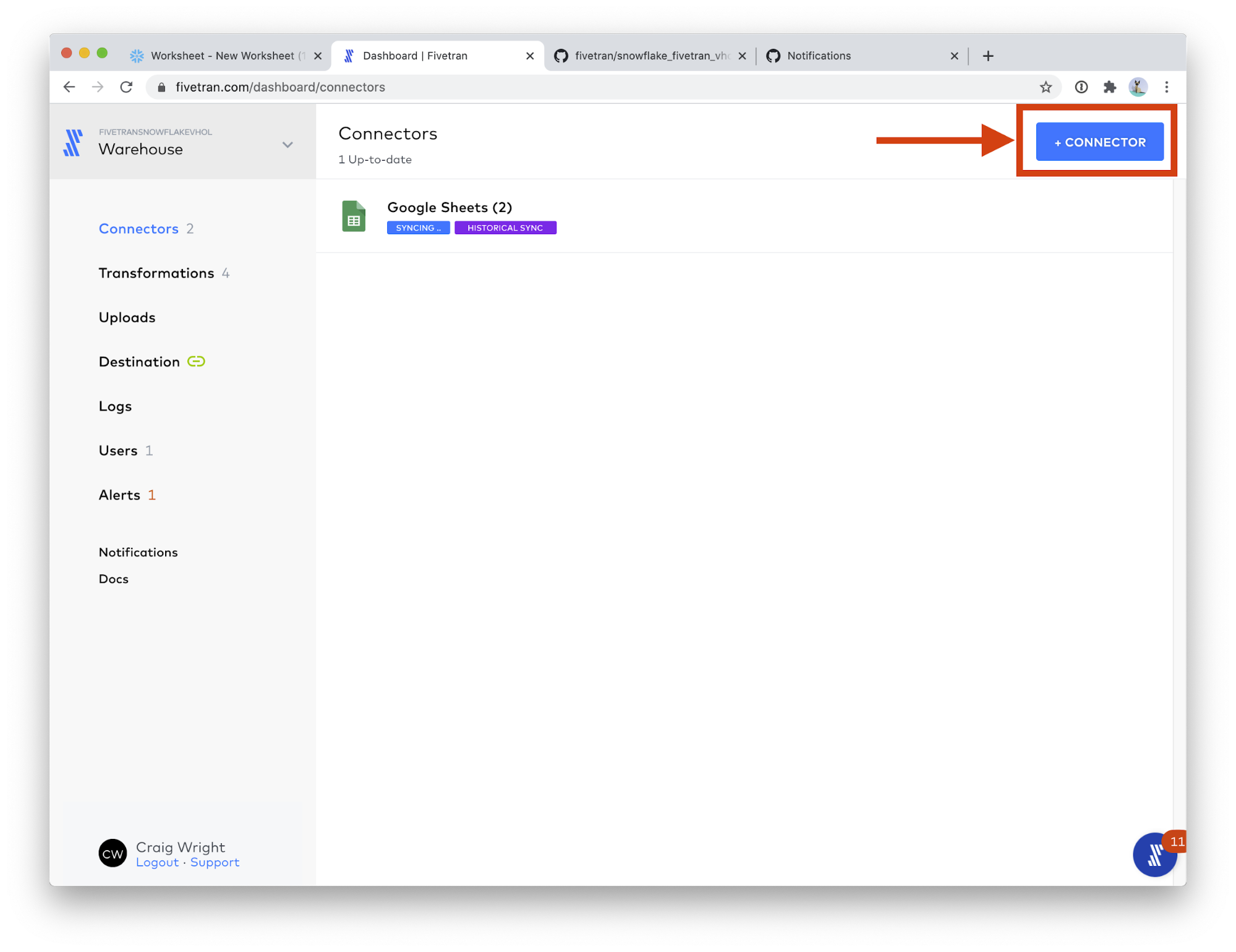
- Great! The Google Sheets connector is now syncing. Let's setup the next table. Click the Connectors menu.
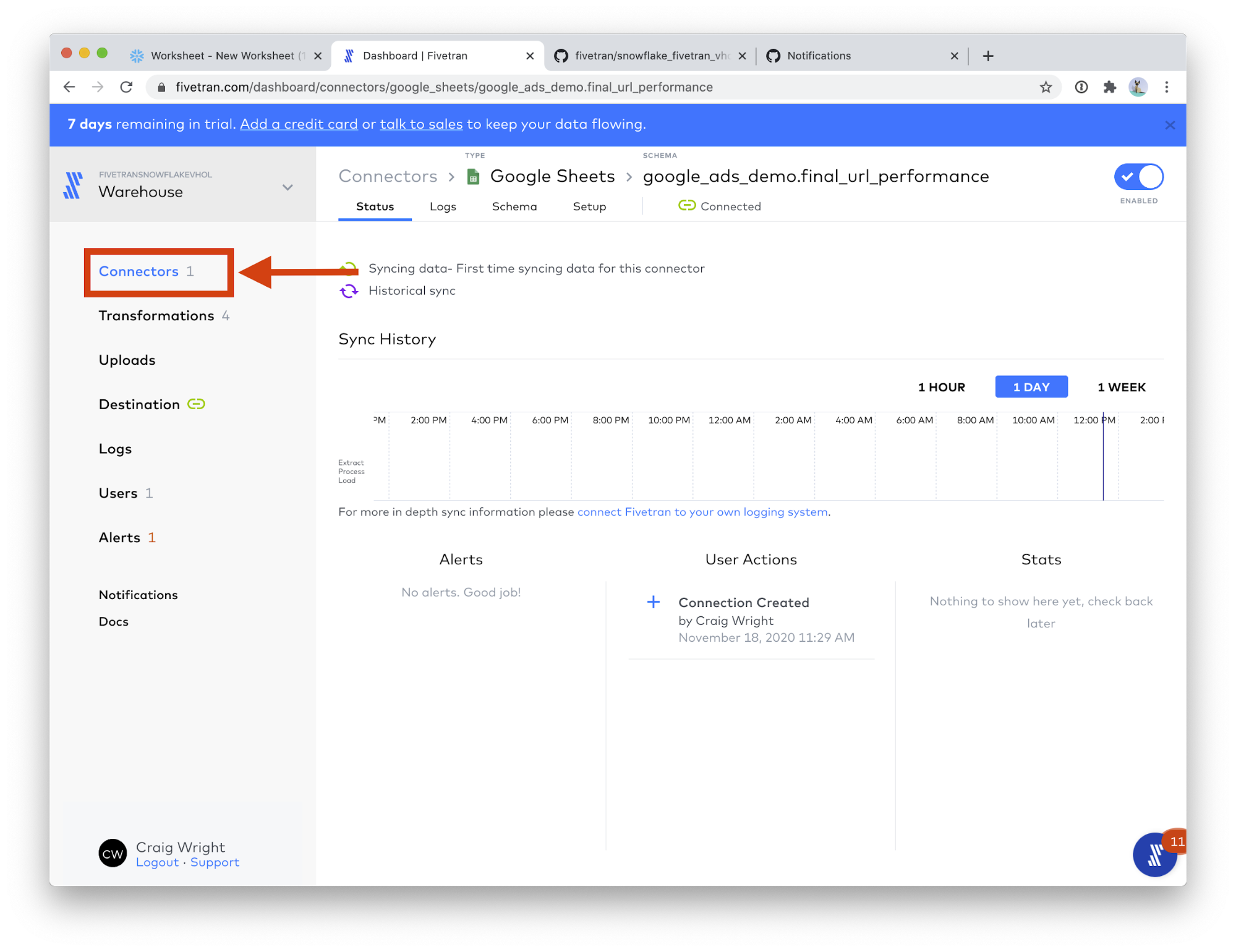
- Click the + Connector button.
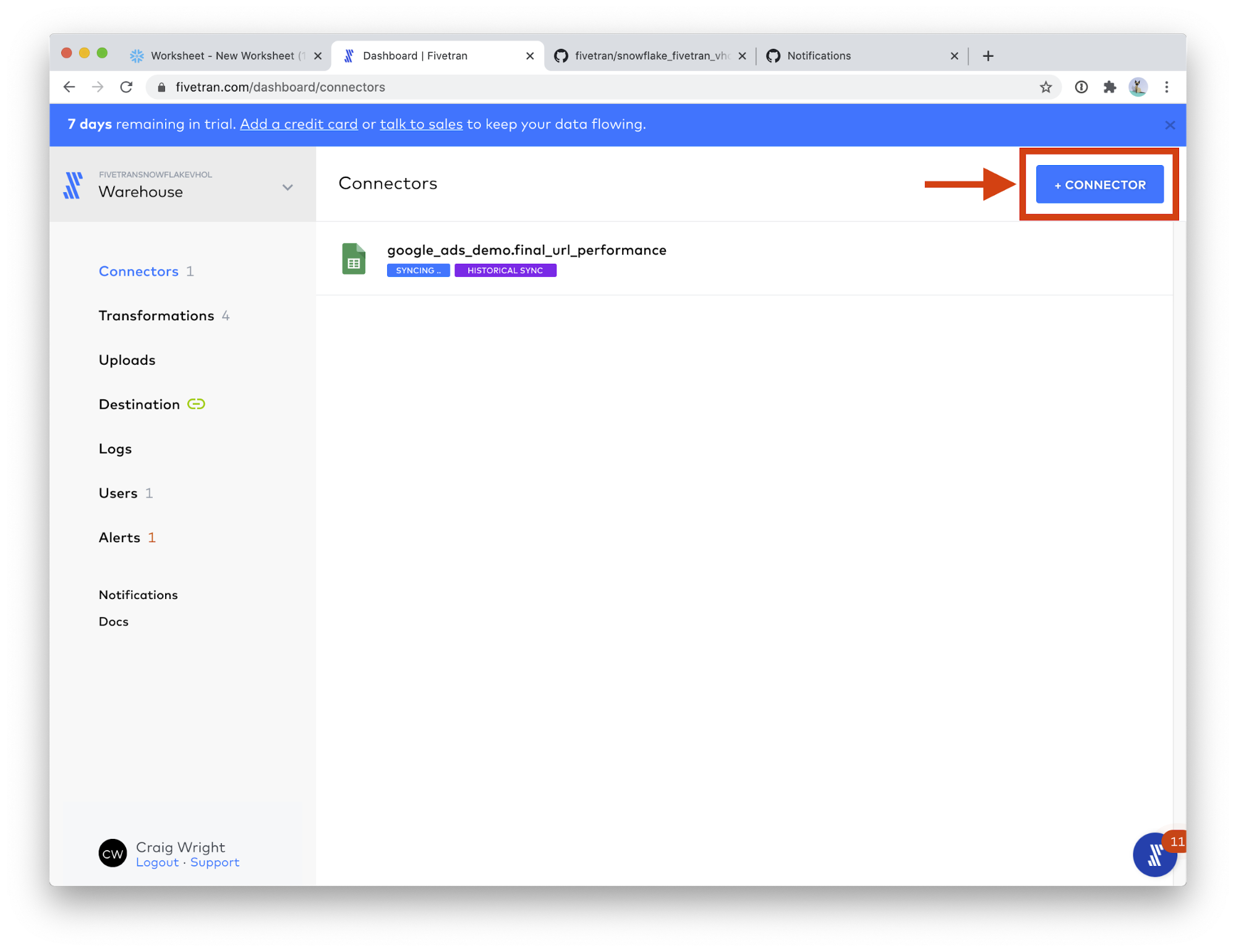
- Please use the following values for the two fields:
- Destination schema: google_ads_demo
- Destination table: criteria_performance
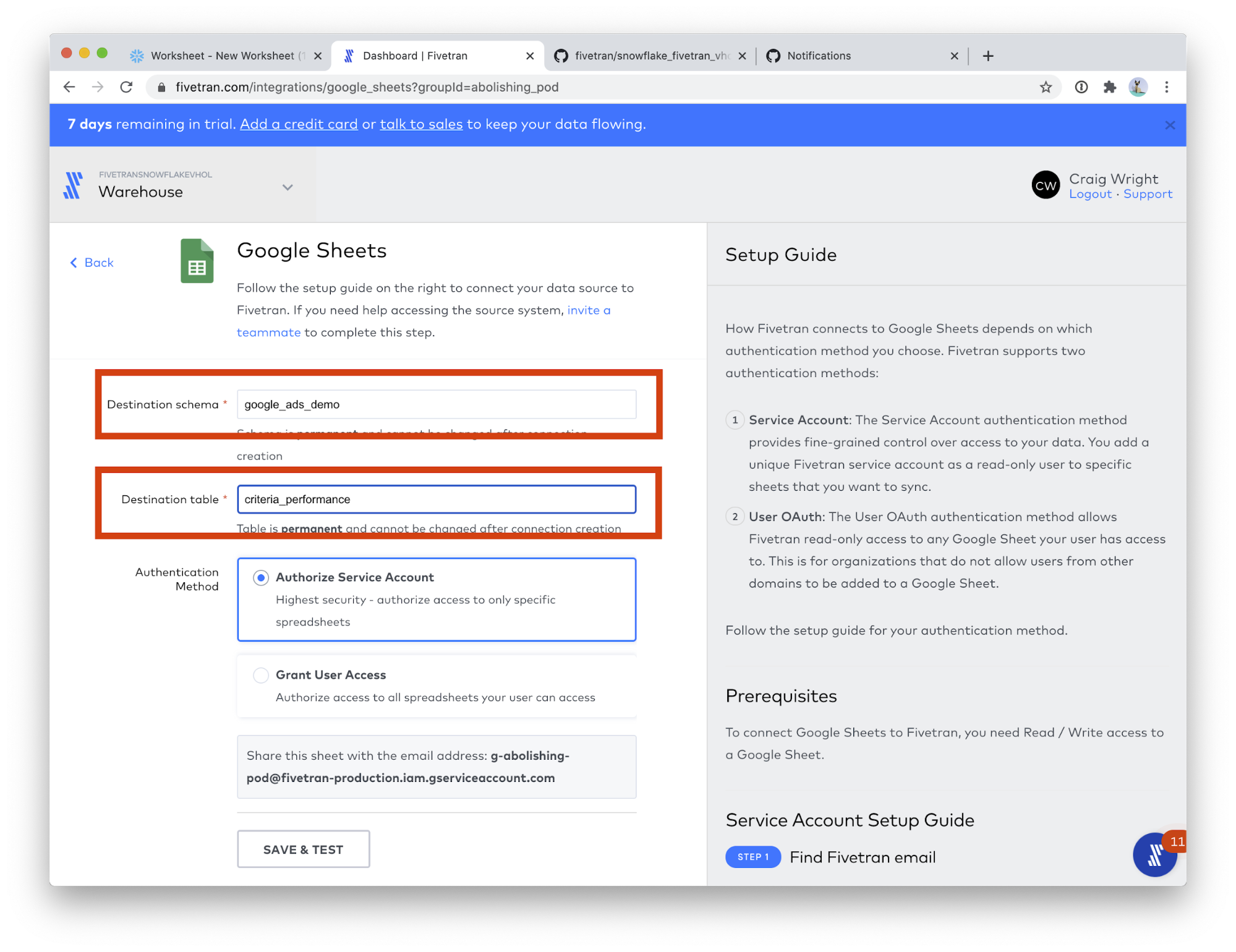
- Scroll down the page a bit, and paste the URL you just copied into the Sheet URL field. (Use the same Sheets URL as step 4, or follow these instructions to get a new Google Sheets URL.) Then, click the FIND SHEET button. This step will take a few moments.
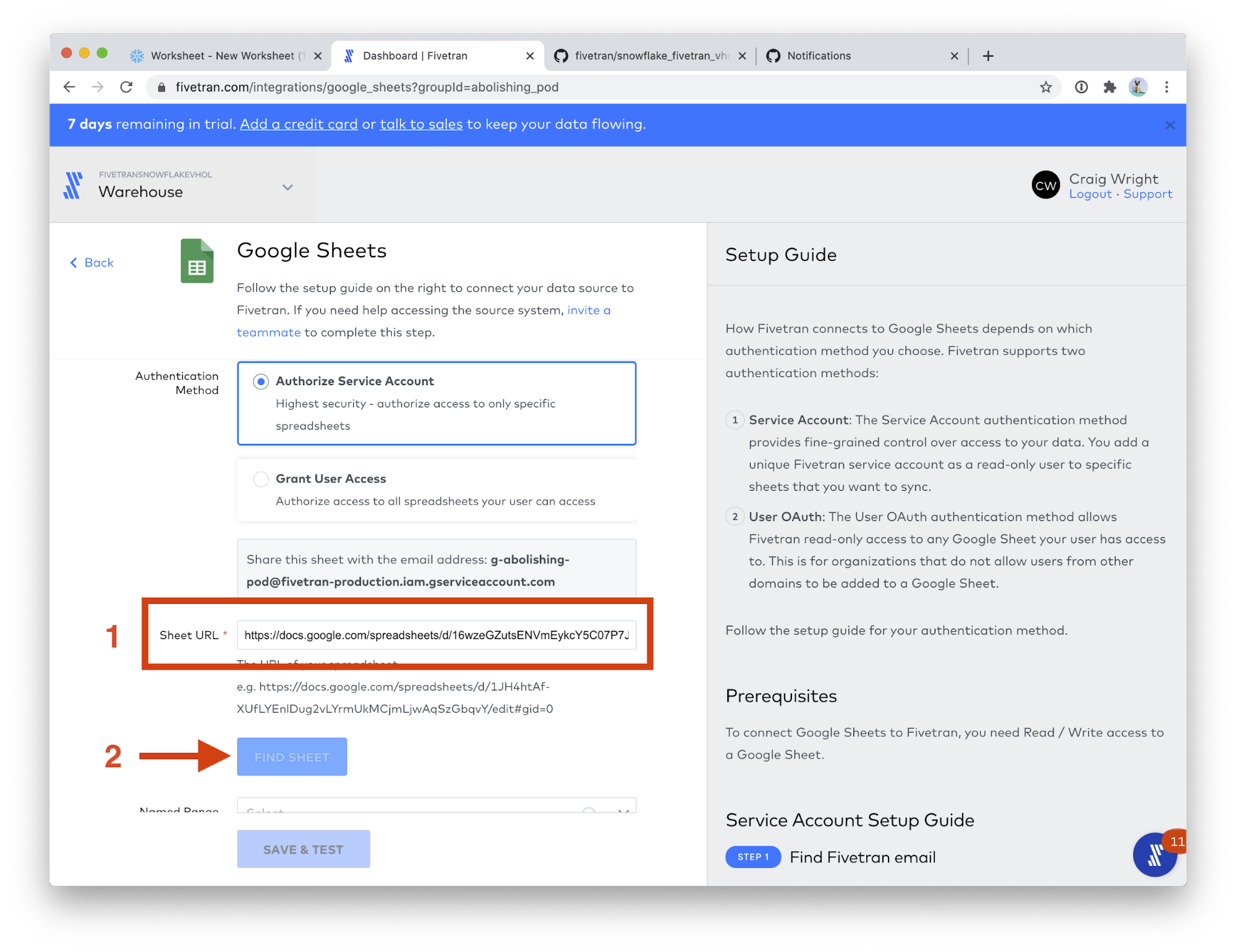
- In the Named Range field, choose criteria_performance. Click SAVE & TEST.
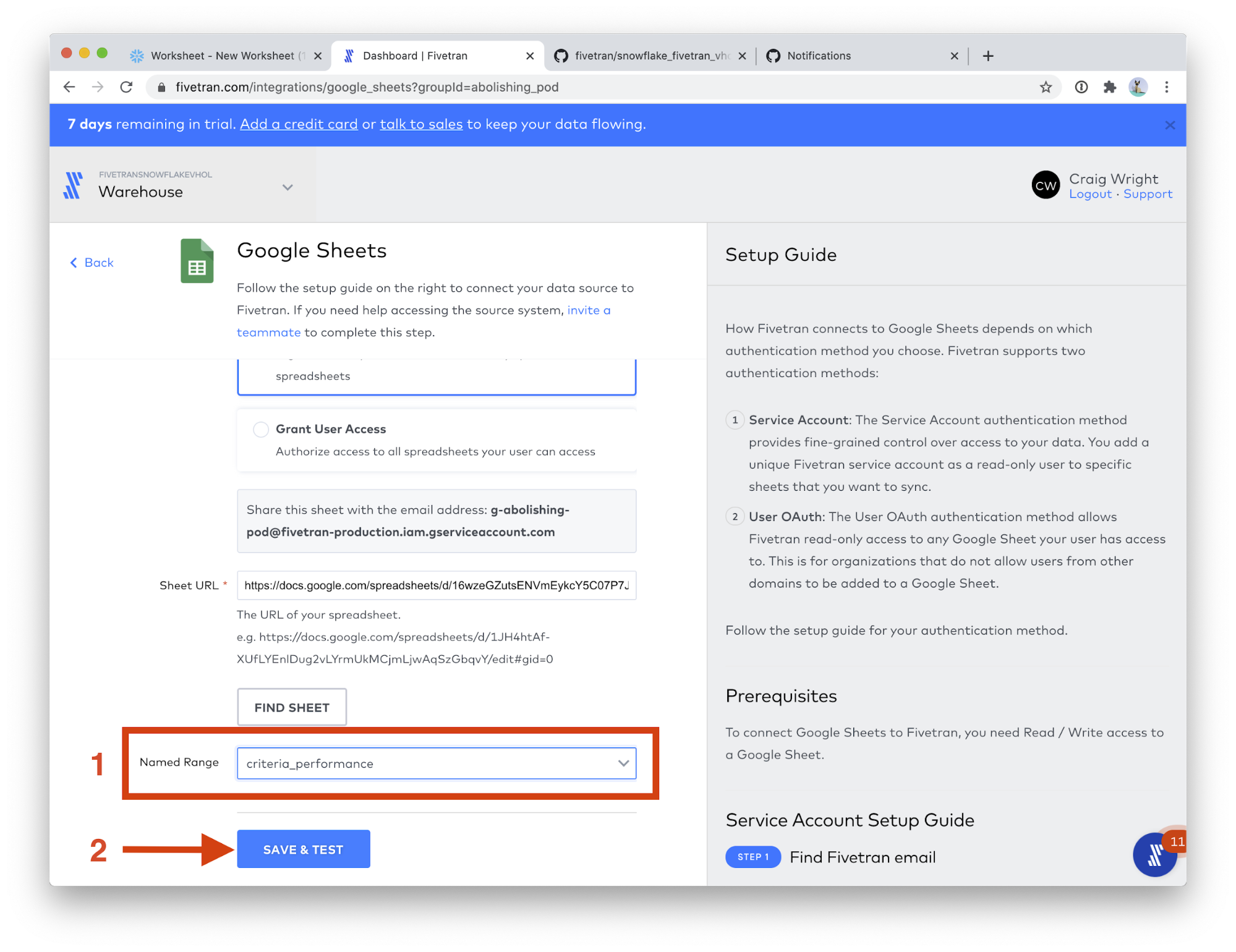
- When the connection tests complete, click VIEW CONNECTOR.
- Click Start Initial Sync. Then click Connectors on the left-hand menu.
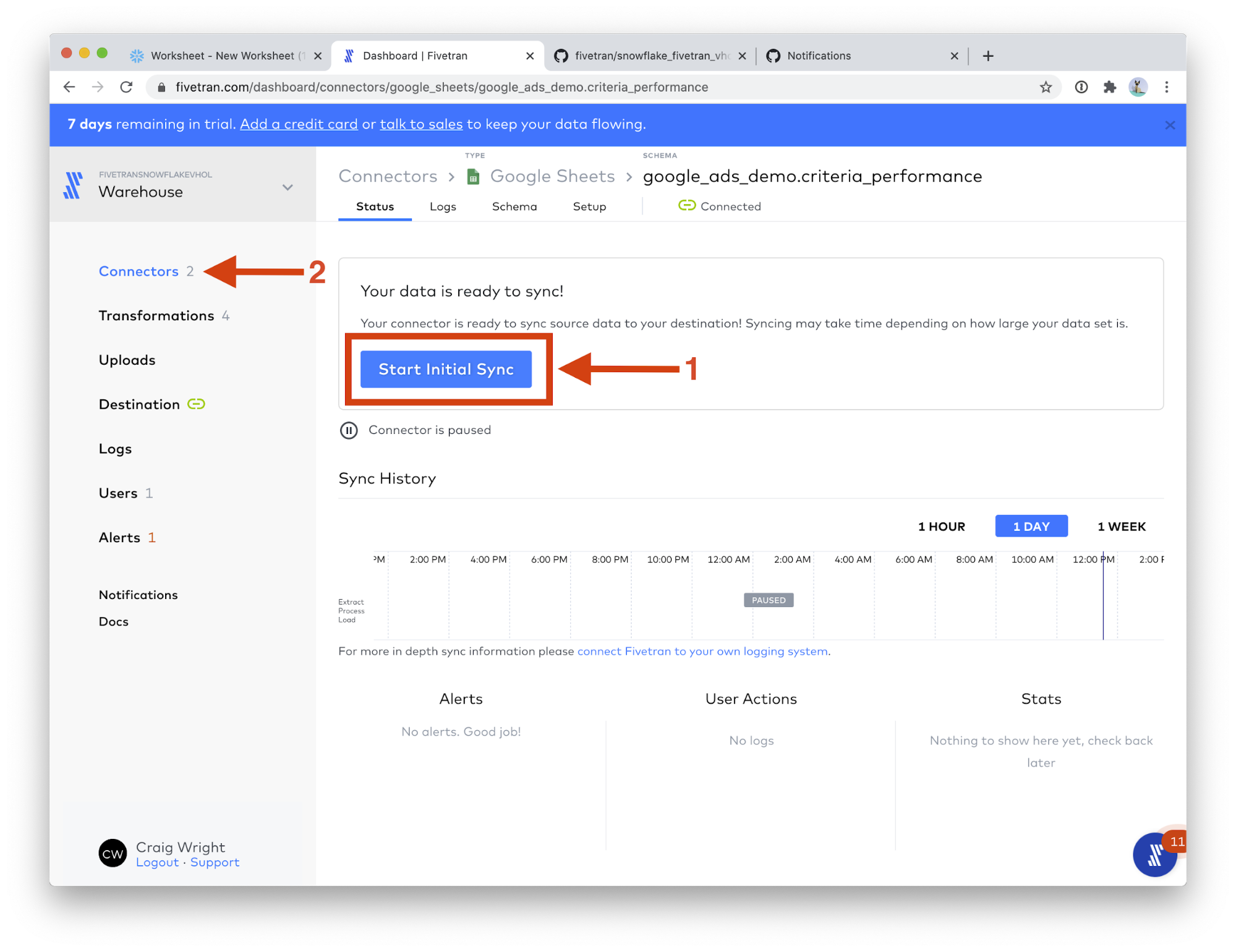
- Click + Connector.
- Please use the following values for the two fields:
- Destination schema: google_ads_demo
- Destination table: click_performance
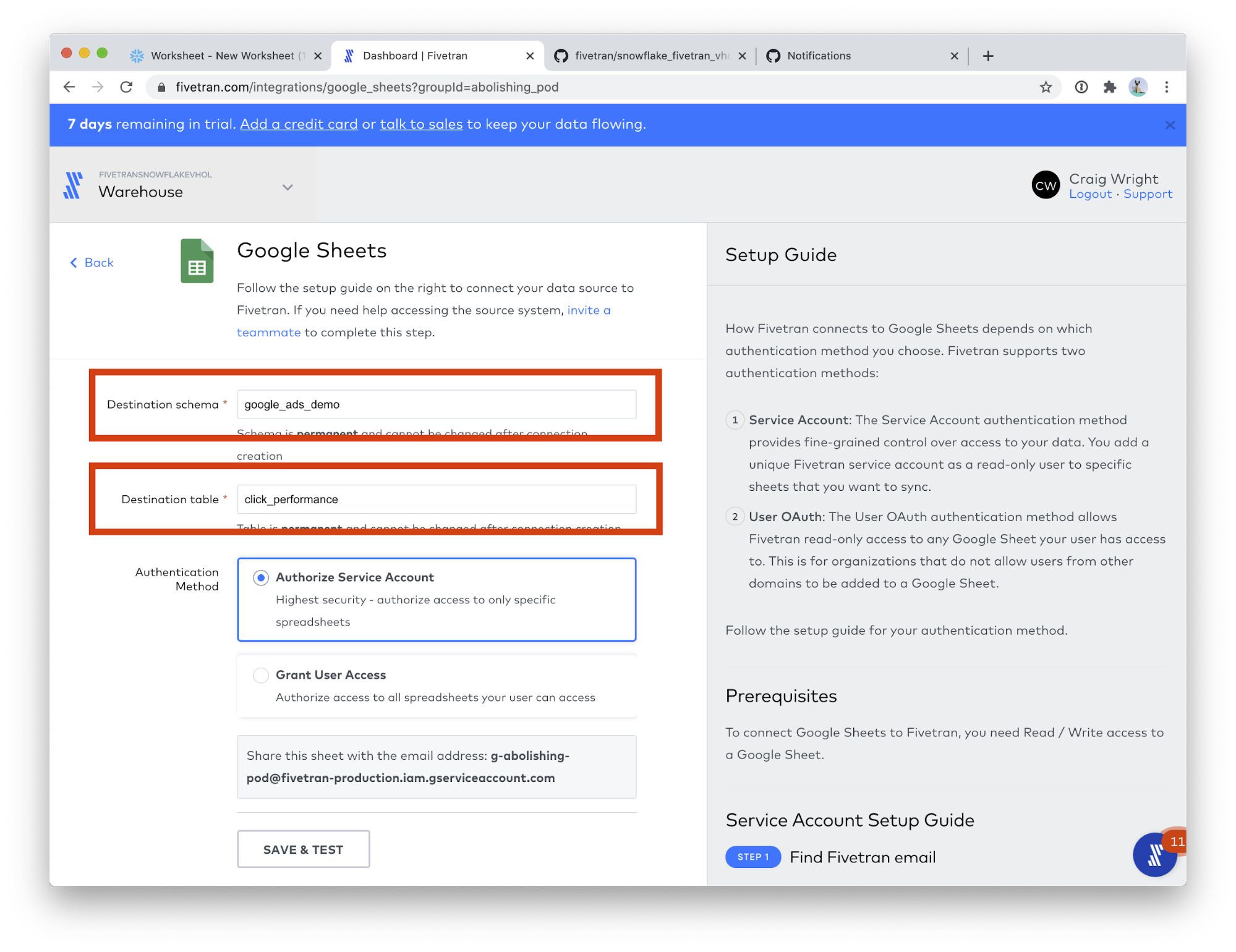
- Scroll down the page a bit, and paste the URL you just copied into the Sheet URL field. (Use the same Sheets URL as step 4, or follow these instructions to get a new Google Sheets URL.) Then, click the FIND SHEET button. This step will take a few moments.
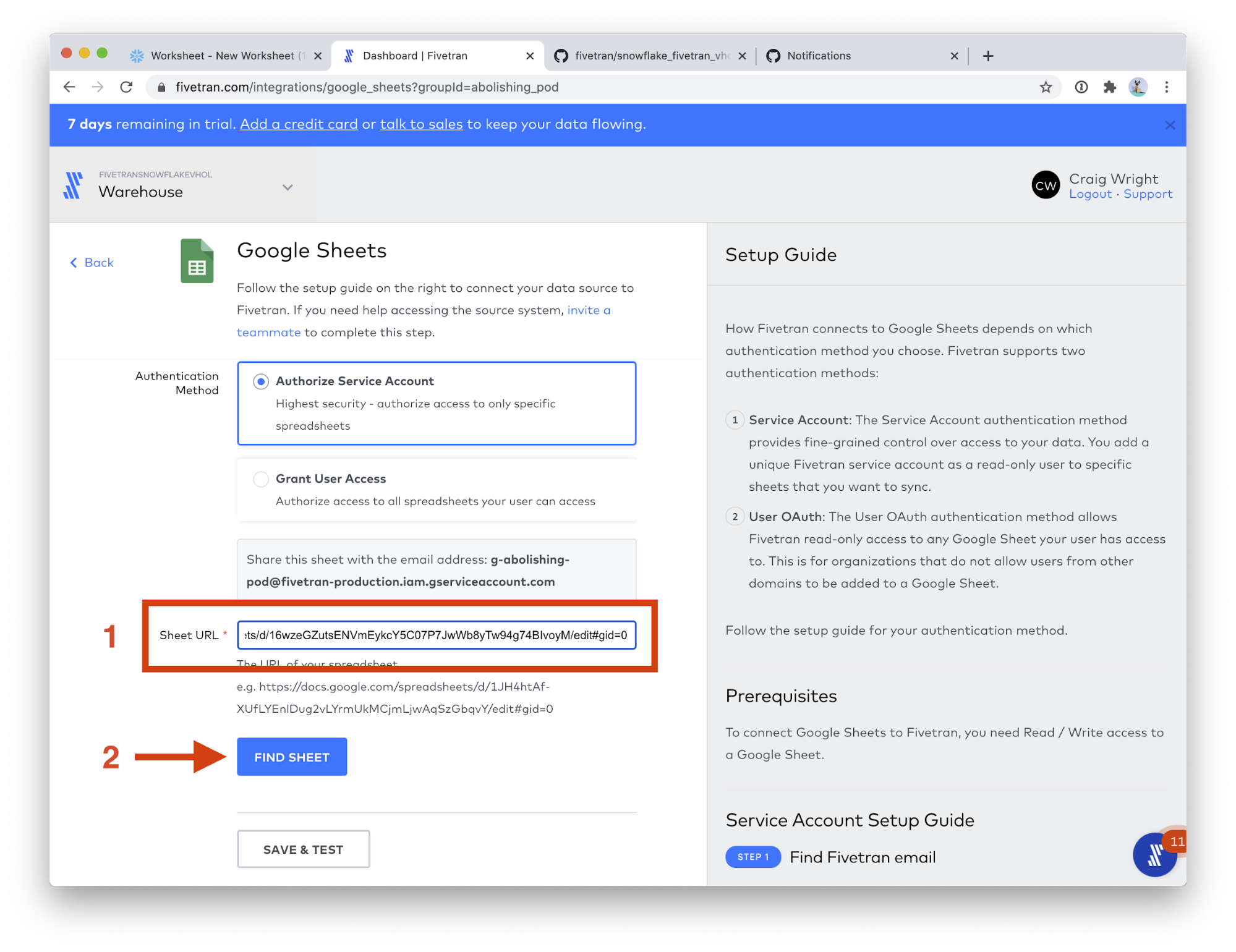
- In the Named Range field, choose click_performance. Click SAVE & TEST.
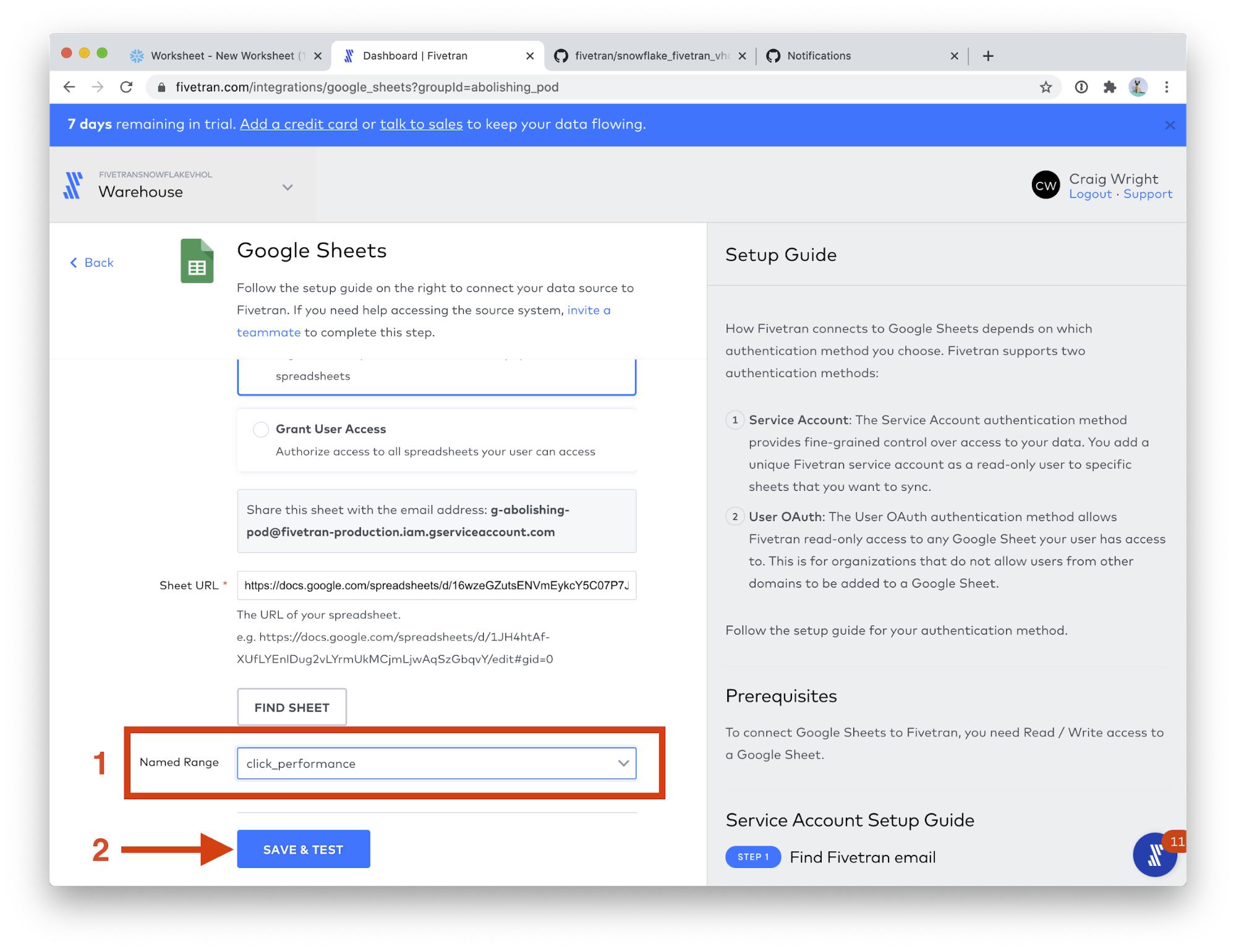
- When the connection tests complete, click VIEW CONNECTOR.
- Click Start Initial Sync. Then click Connectors on the left-hand menu.
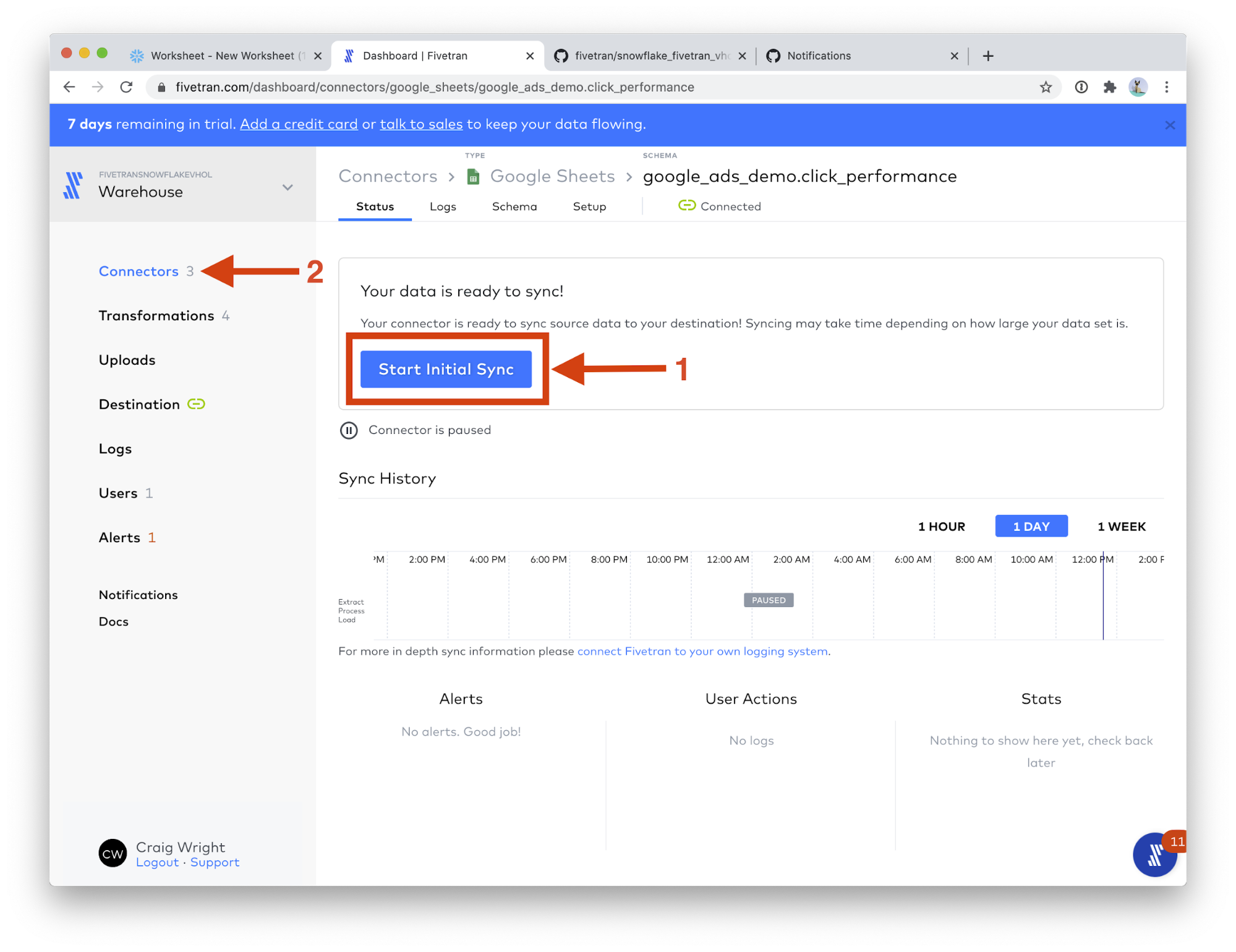
- Congratulations! You can see your 3 Google Sheets connectors running, each creating one of our three sample data tables. Click on Google Sheets (3).
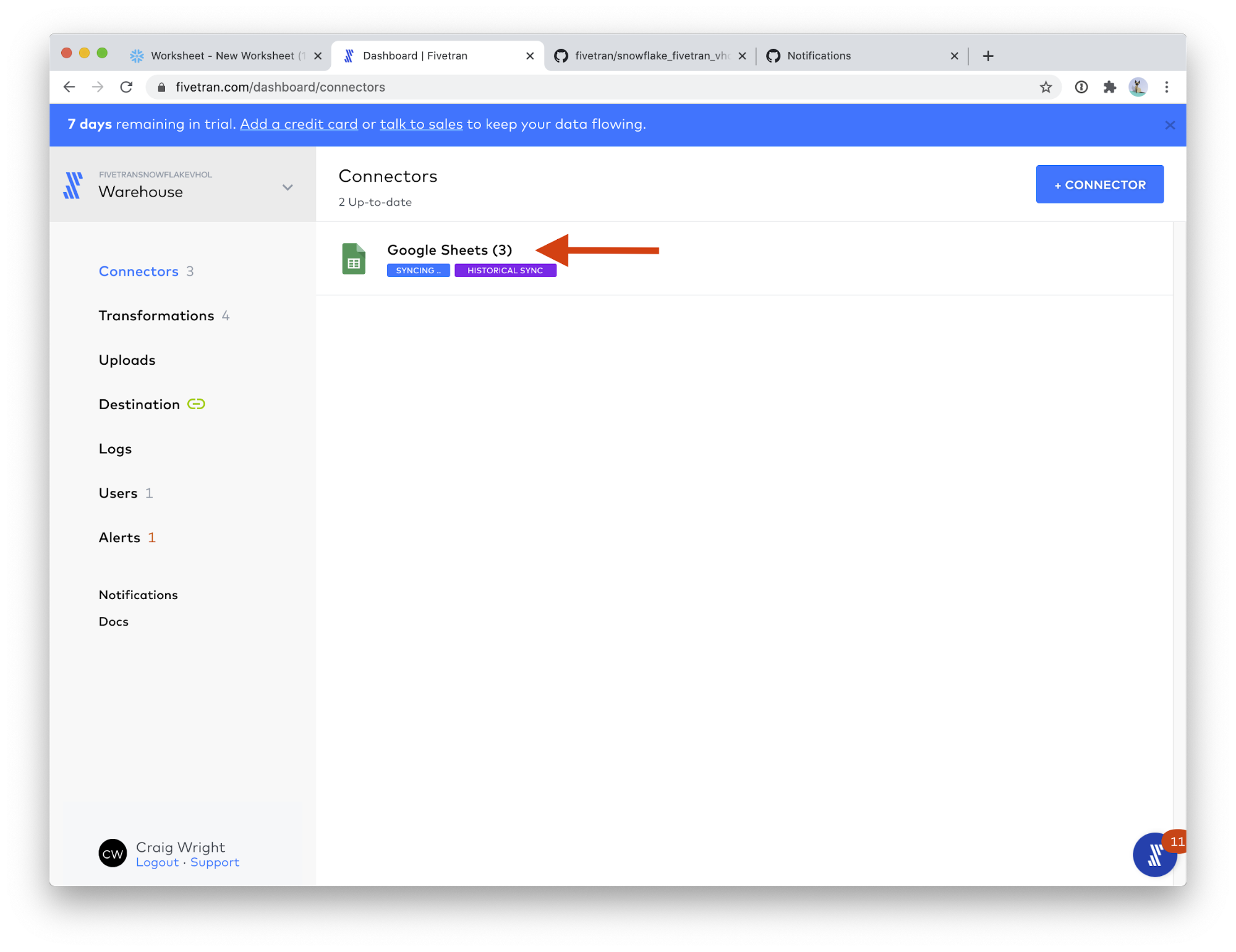
This view shows you all of your Google Sheets connectors. Some of your connectors may still be syncing, that is fine; we will have time for them to complete while we perform the next part of the lab.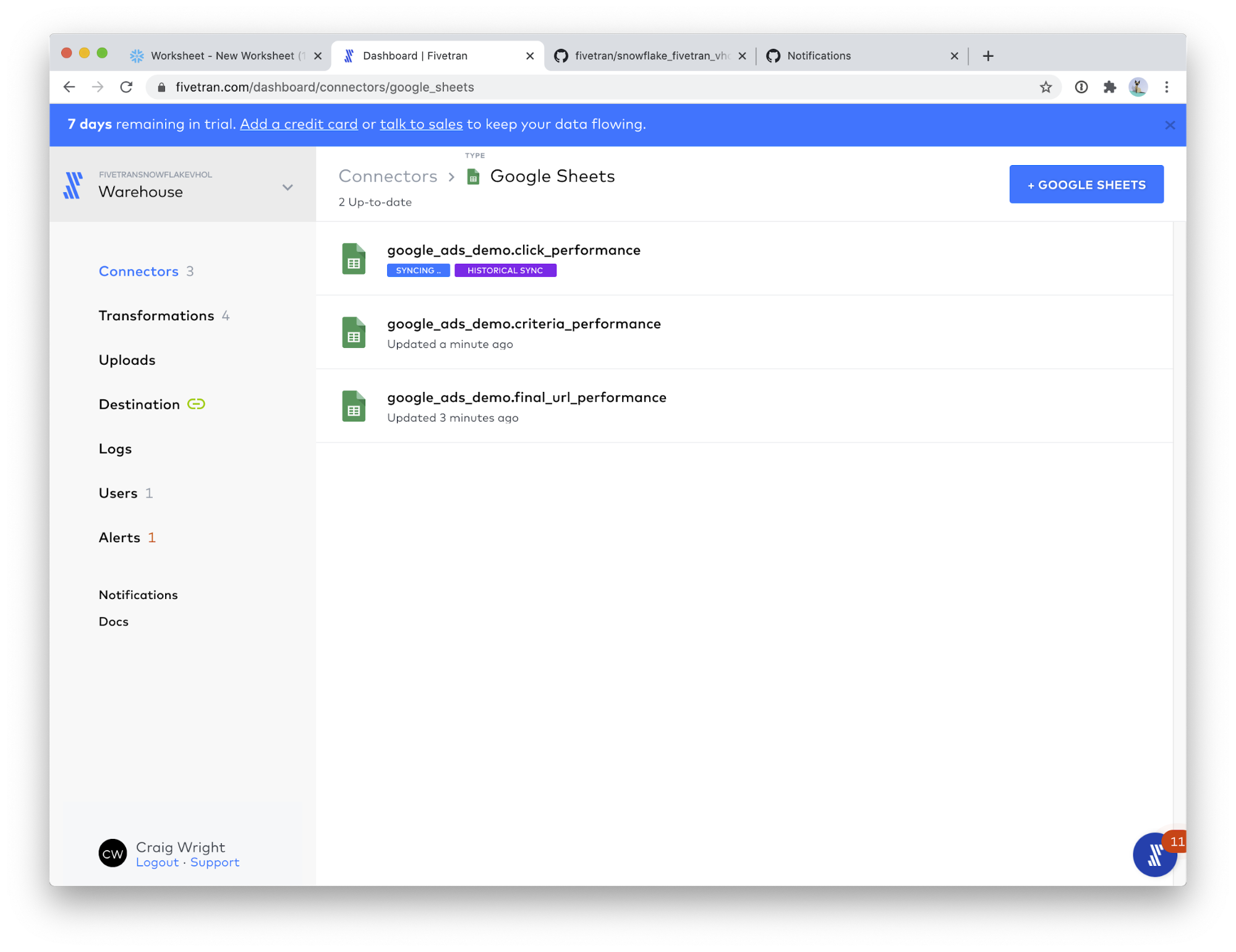
In Snowflake (optional): When the sync is complete, you can see your schema and tables in Snowflake's Worksheet view. You should be able to see the data in the tables by clicking into the PC_FIVETRAN_DB database, into the GOOGLE_ADS_DEMO schema, then clicking on one of the tables and then clicking Preview Data.
Note: The Setup Fivetran dbt Transformations section assumes you have uploaded the sample data as outlined in the previous section. If you use your own Google Ads data, that is fine; you will just need to edit the dbt_project.yml file as discussed in this section.
For your convenience, we have created a sample dbt Github project that is already configured to work with Fivetran's dbt_google_ads_source and dbt_google_ads packages. You can find the sample repository at the following link: https://github.com/fivetran/snowflake_fivetran_vhol
This section assumes that you have created a Github account and are logged into that account. In this section we are going to:
- Fork the sample github repository.
- Explore the files in the project.
When you click https://github.com/fivetran/snowflake_fivetran_vhol and you are logged in, you should see the following screen. Notice the user / owner is fivetran and the repository is named snowflake_fivetran_vhol.
- On the upper right (but below your user icon) is a Fork button. Click it!
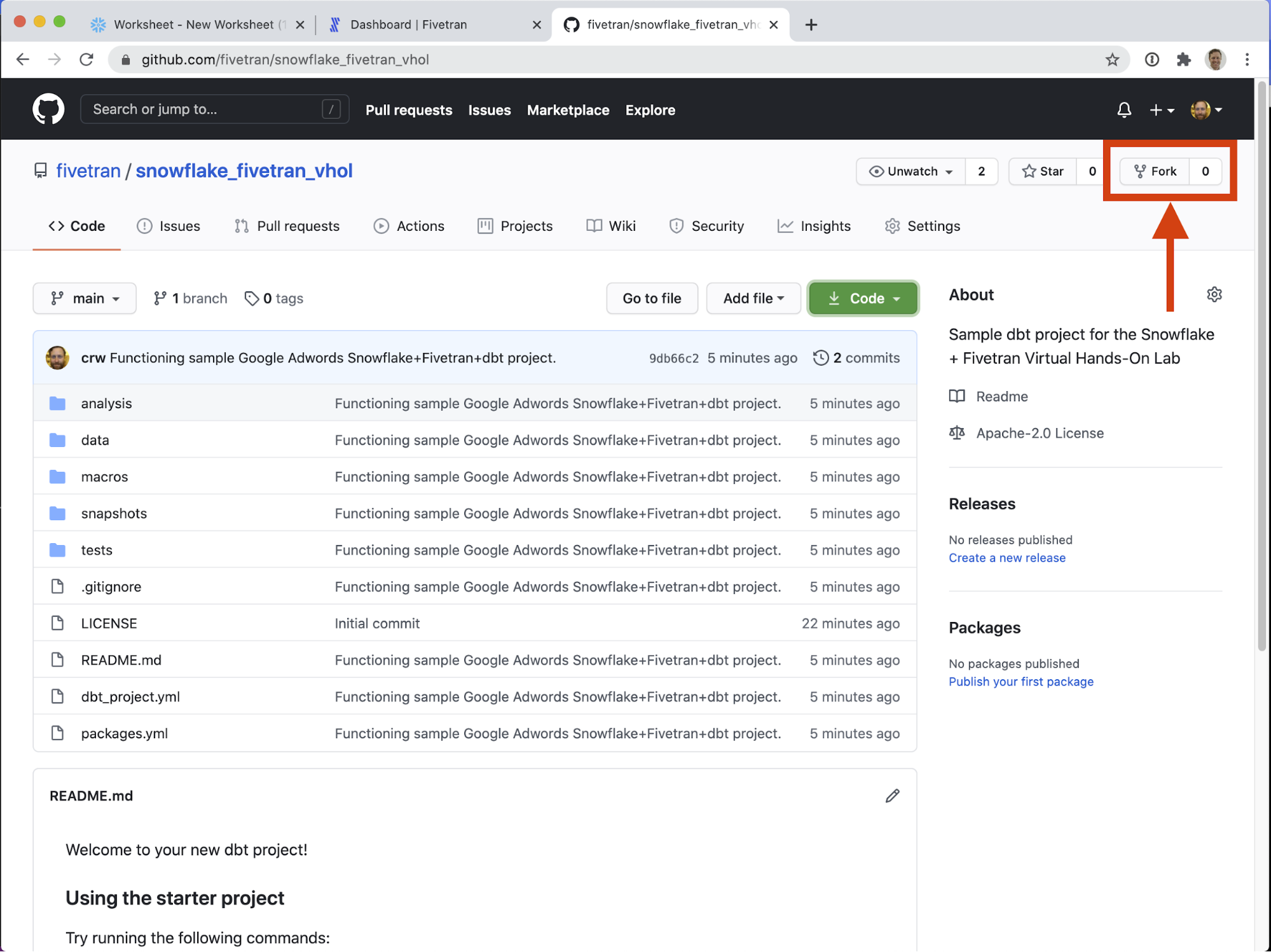
- If you have access to multiple github accounts, you will have the option to select into which account to fork this repository. Choose your personal user account.
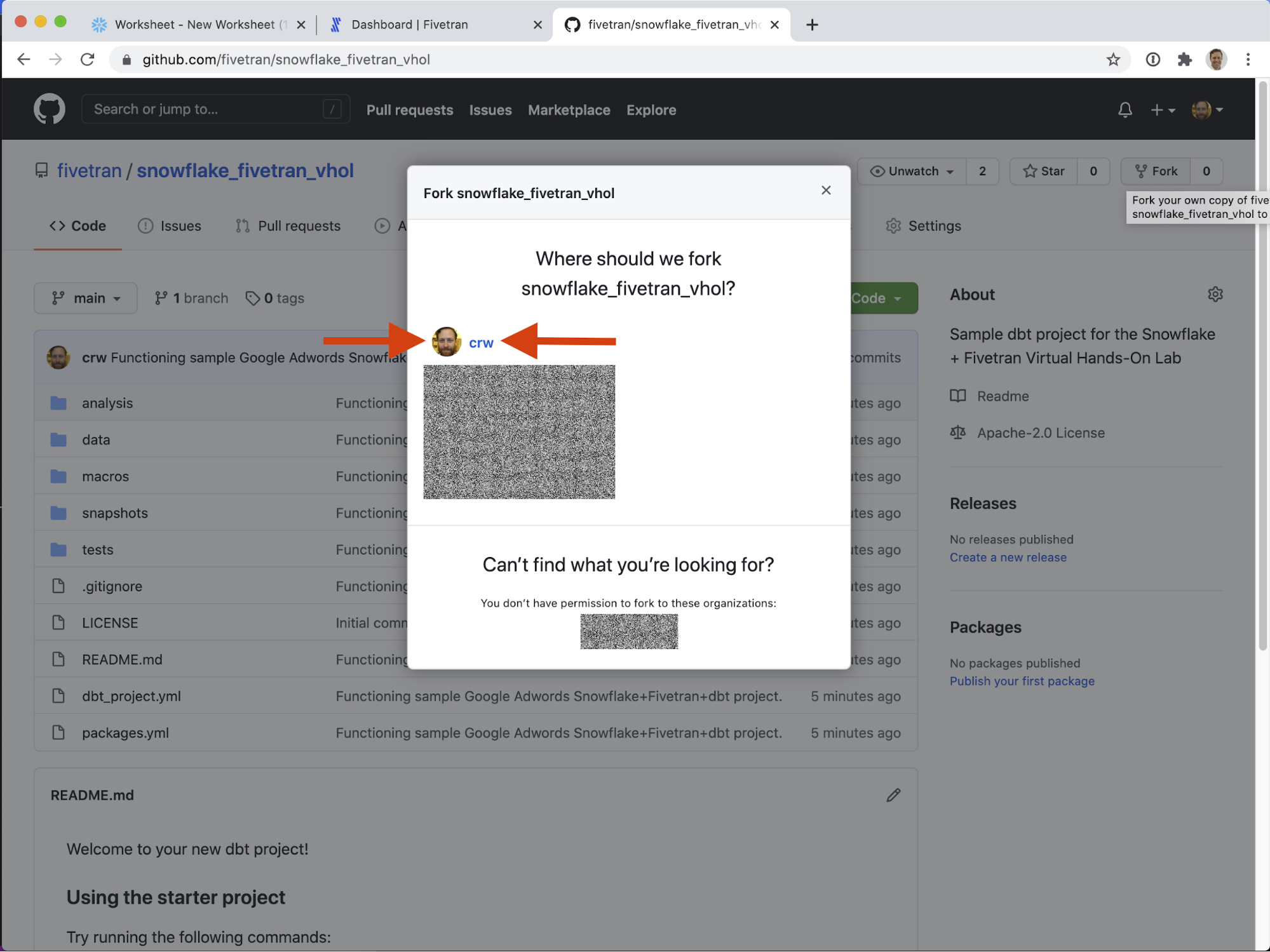
That's it! Notice in the screenshot above the user / owner is crw and the repository is (still) named snowflake_fivetran_vhol - but now that repository is under your personal Github account. I can now manipulate this repository however I like, without impacting the sample repository. 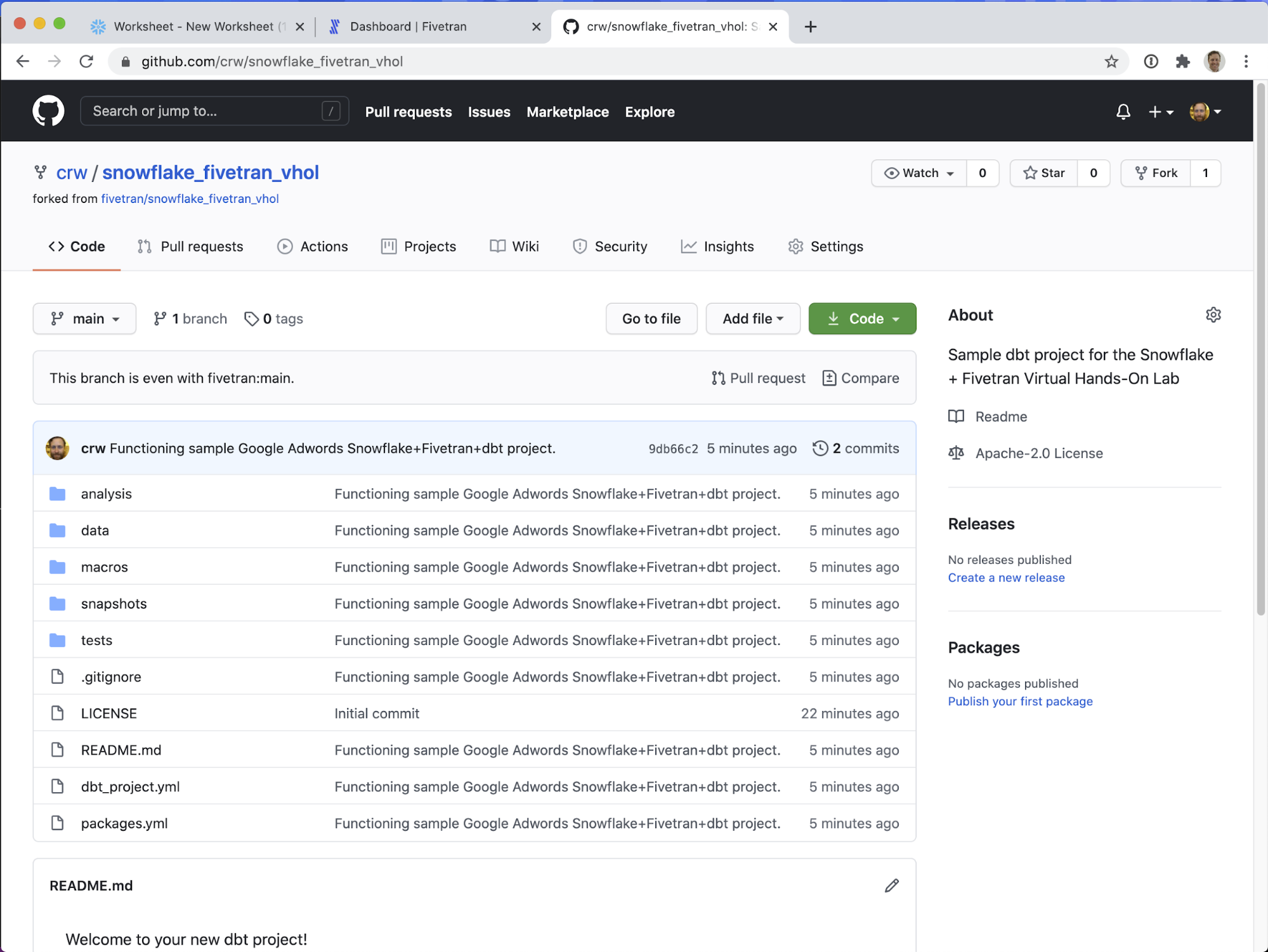
Congrats! You have successfully created your first dbt project! That was easy! The next section is OPTIONAL and not required for the workshop. It is included for your information only.
There are three very important configuration files to be aware, all at the top level of the file tree.
- dbt_project.yml - general dbt project settings.
- packages.yml - include packages that bring functionality to your dbt project, like those provided by Fivetran to enhance your data!
- deployment.yml - a Fivetran-specific configuration file that controls how frequently the dbt jobs run.
dbt_project.yml: 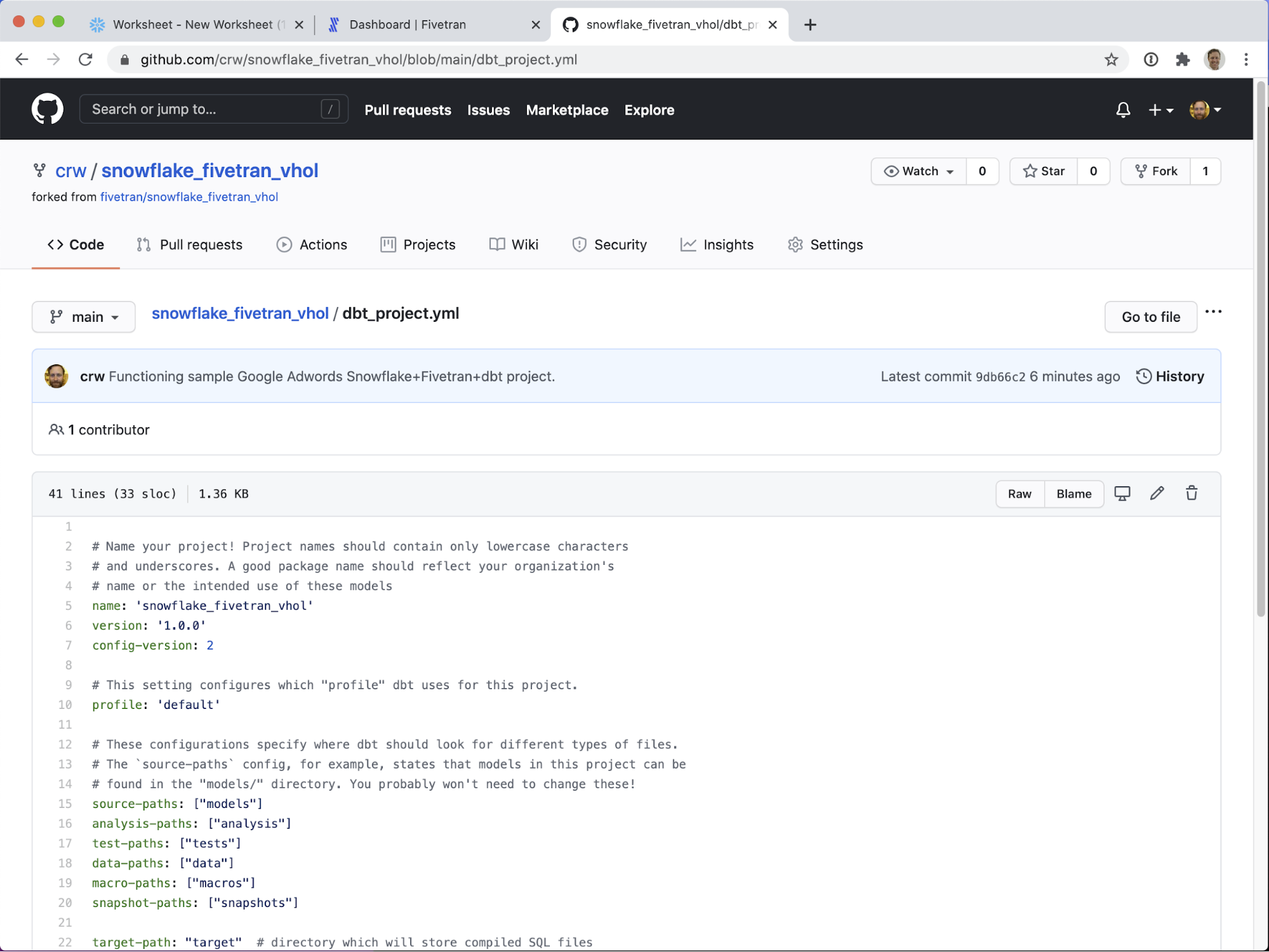
Various configuration settings are found in this file. Please see dbt's documentation for more information on these settings.
As previously mentioned, if you want to use your own Google Ads data, you will need to edit dbt_project.yml. You can edit files directly in Github using the pencil icon at the top of the file view (mid-upper right, to the right of the Blame button). All you need to do is remove or comment out the lines that say:
vars
google_ad_schema: 'GOOGLE_ADS_DEMO'
That's it! Remove those lines and you are good to go. This assumes, of course, that you loaded your own Google Ads data in the previous section! If you have an ADWORDS schema in your Snowflake warehouse, you successfully loaded Google Ads data.
packages.yml:
This is where you can include outside packages to run! See hub.getdbt.com for a complete list and installation instructions. As of this writing, Fivetran has created over 17 packages, including packages for Netsuite, Salesforce, Twitter Ads, Marketo, Zendesk, Mailchimp, and more! 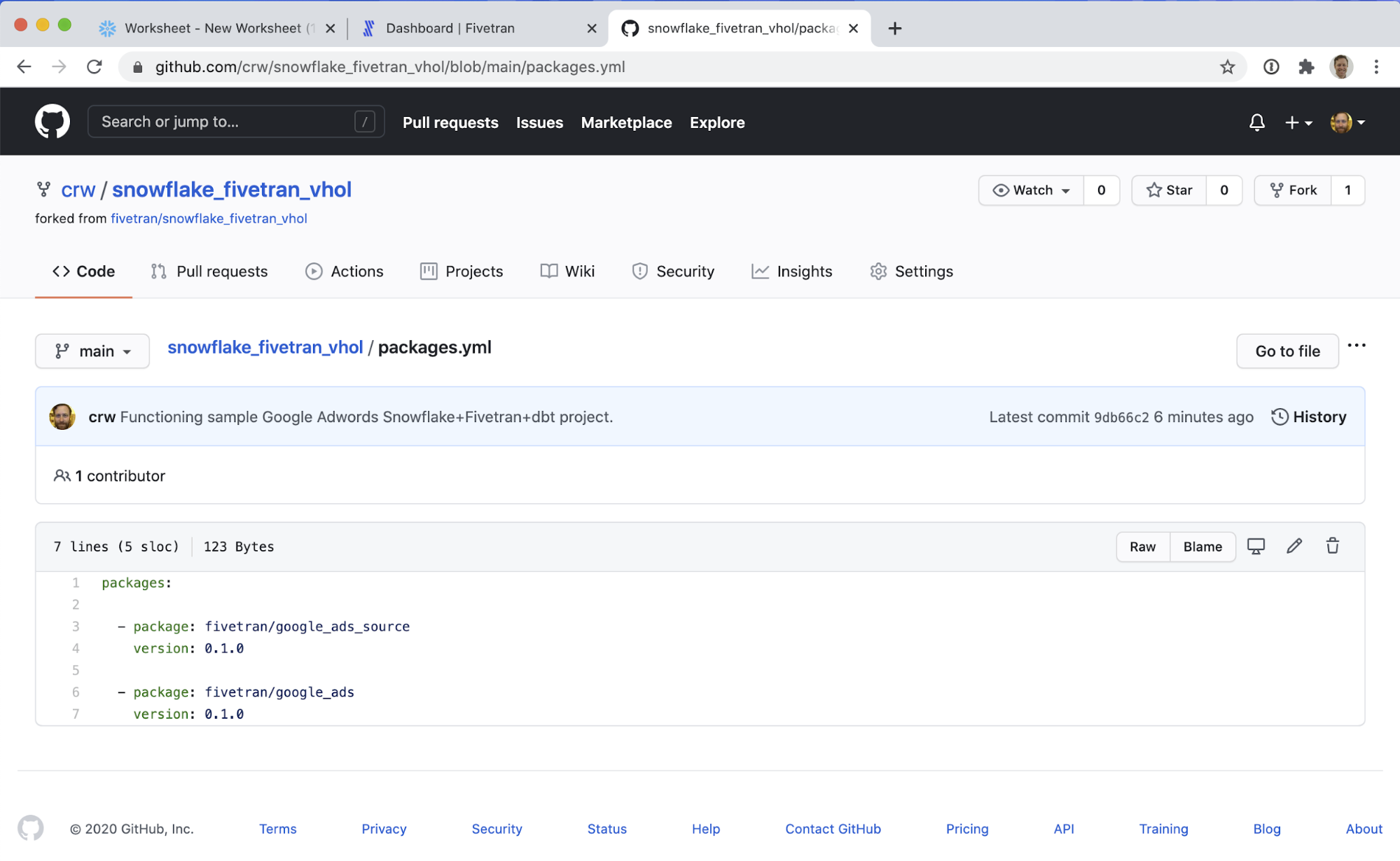
deployment.yml:
This is a Fivetran-specific file that configures what jobs will run when, leveraging a crontab-style syntax for scheduling. Documentation can be found in the file itself. Remember, as described above, you can edit files directly in Github!
In this section we will take the dbt project we created in the previous section, and run it via Fivetran to generate models! We will be showing how Fivetran is used to orchestrate dbt jobs, and the first step is to connect to your dbt project in Github. There are a lot of steps in this section, but for the most part they are not too complicated. Let's get started!
Note: dbt Transformations in Fivetran are in beta as of this writing. Depending how you signed up for your Fivetran trial, you may or may not see the option to "Try dbt Transformations". If you do not see this option, please reach out to us and we will try to get you enabled to try this feature.
If you see this screen, please reach out to Fivetran sales – we can enable dbt Transformations beta for your account.
- If you have not already, switch back to your Fivetran tab in your web browser. First click on the Transformations section of your Fivetran interface. You should see the following interface. We will be clicking the button labeled Try dbt Transformations.
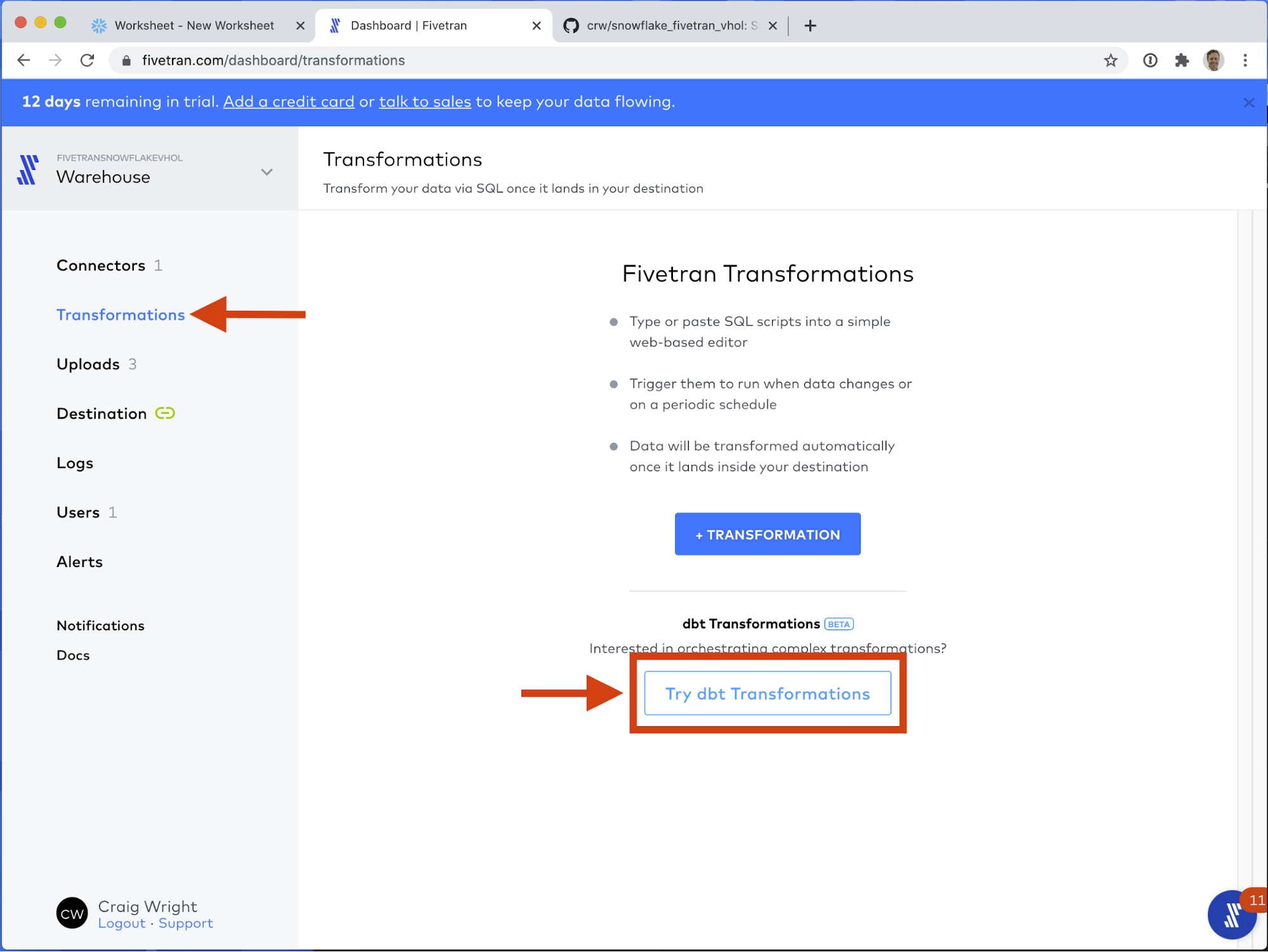
- Click Enable dbt Transformations
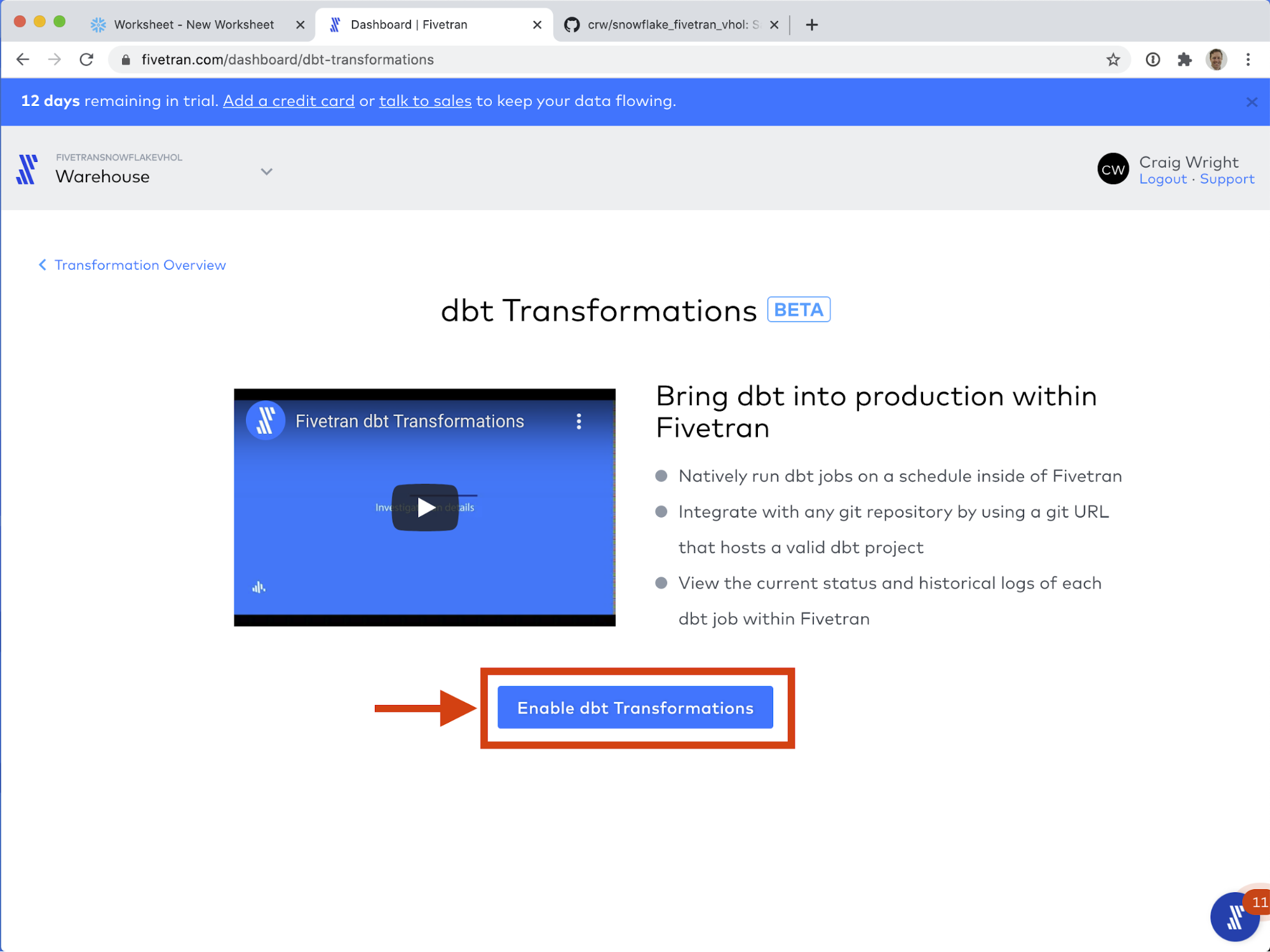
- Click I am ready to connect my Git repo.
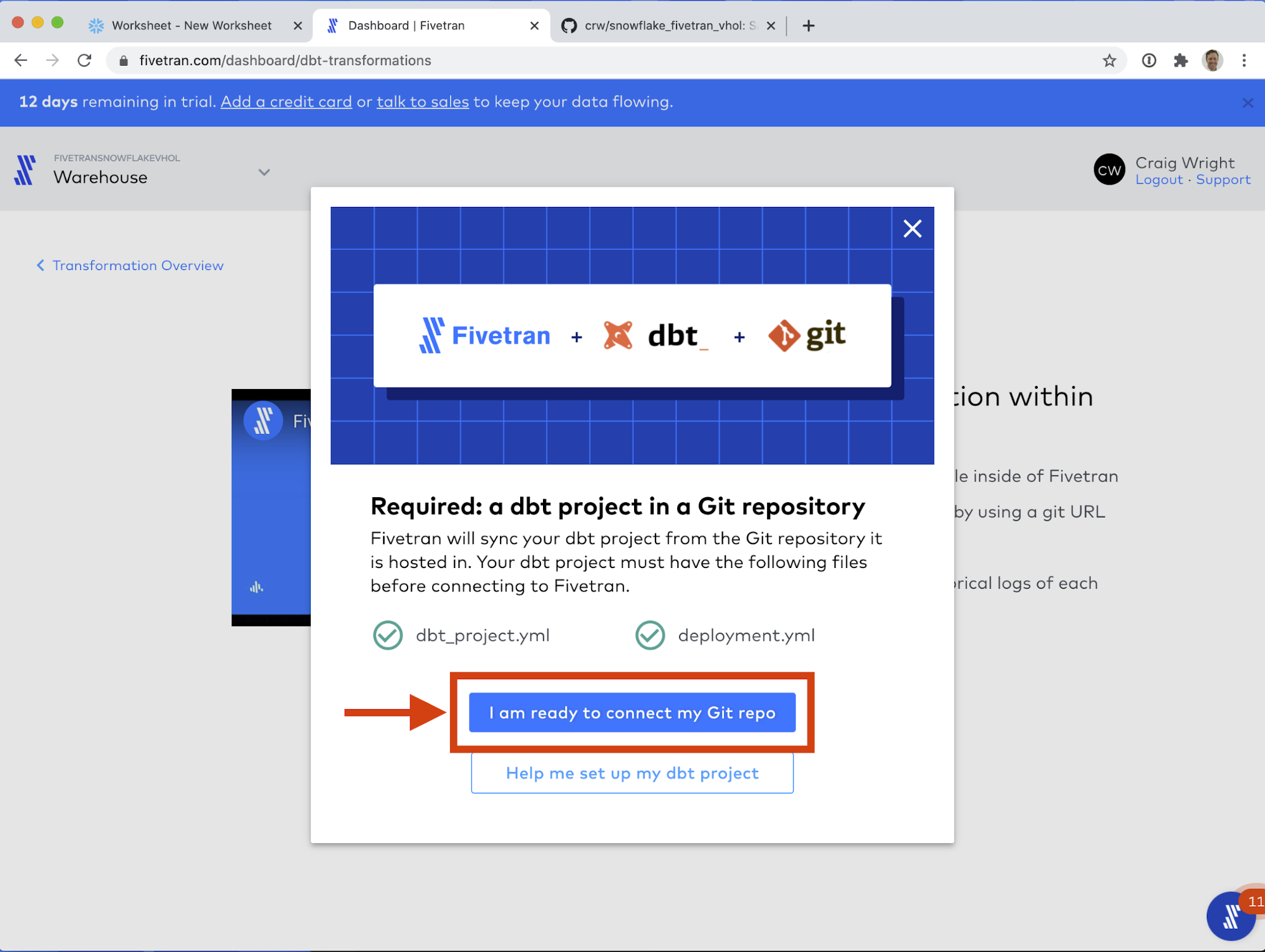
- Now we will configure the connection to Github. Next to Public Key, click Copy to Clipboard (the papers icon).
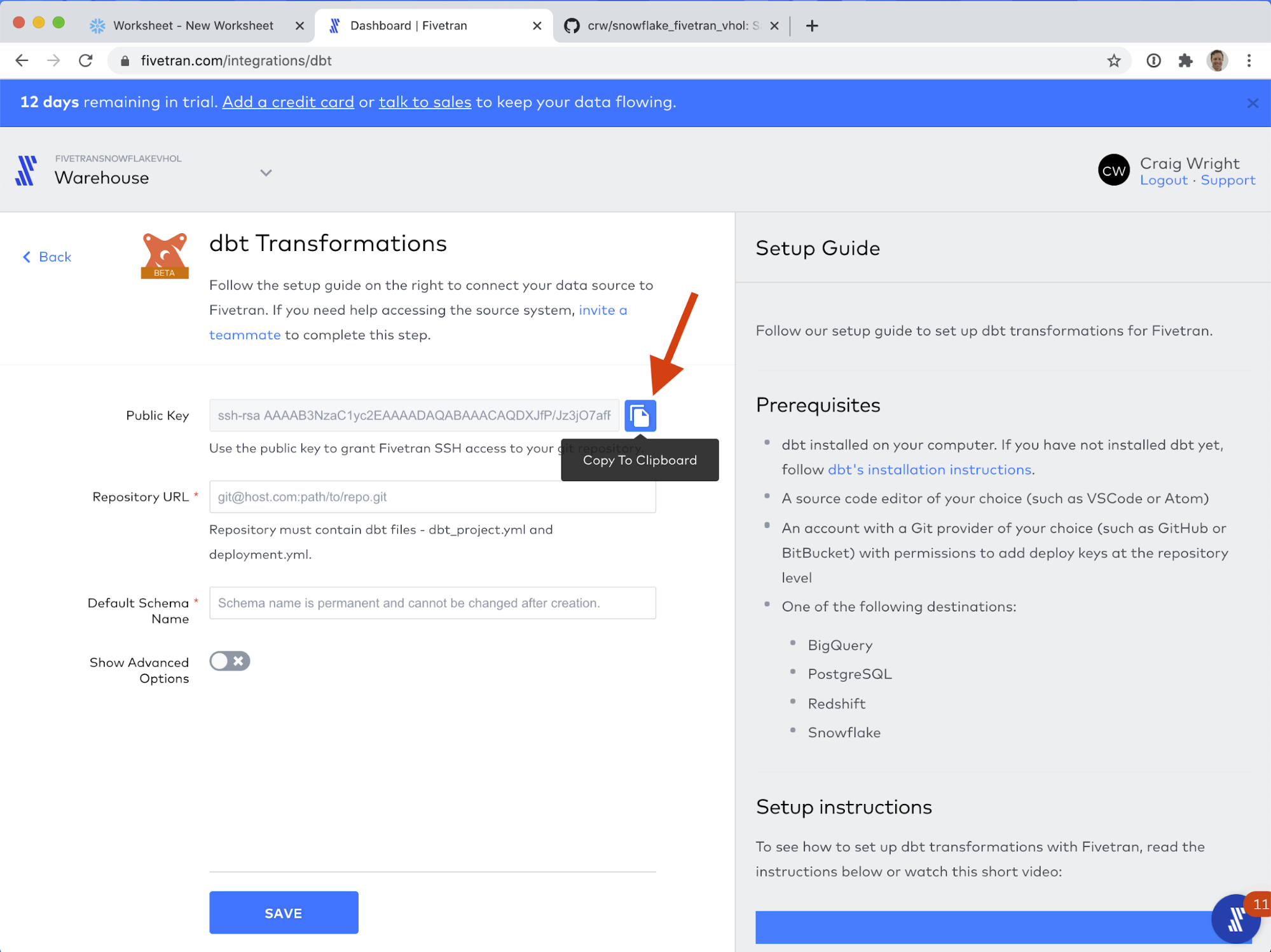
- On the Github repository we created above (your_username/snowflake_fivetran_vhol) click on Settings (farthest-right of the tabs under the repository name.)
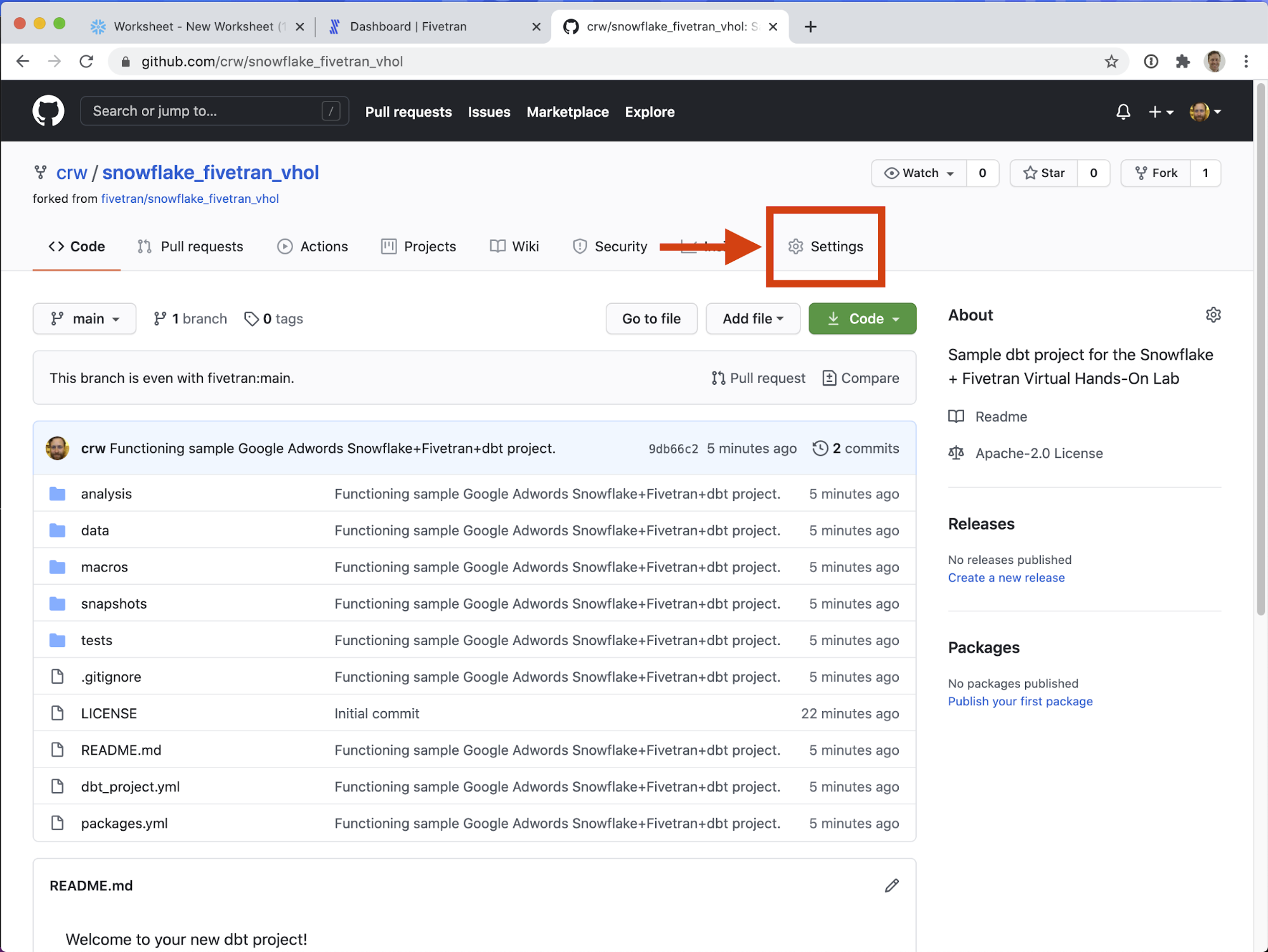
- On the left-hand navigation, click on Deploy Keys (lower half, under Integrations, above Secrets).
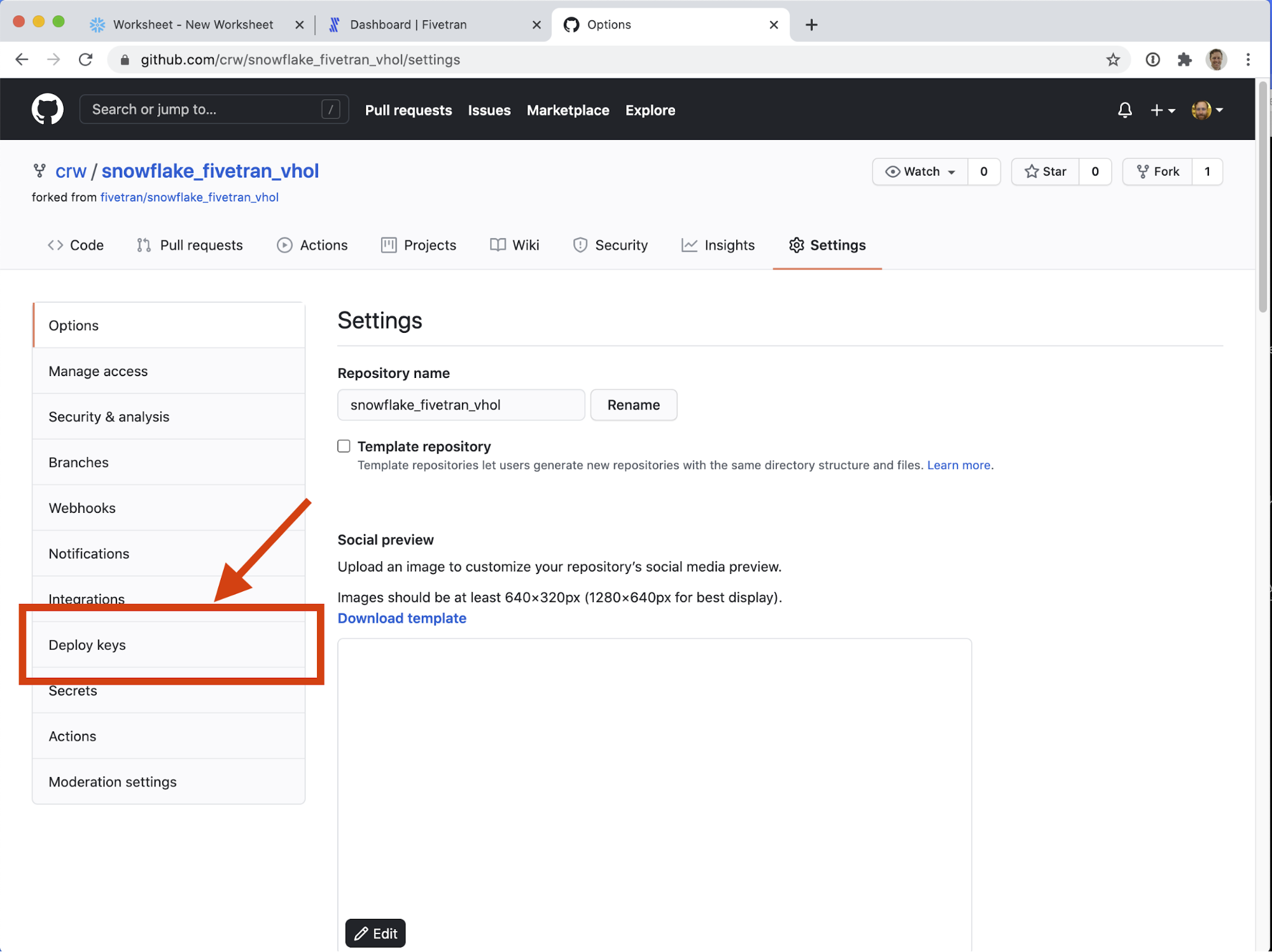
- Click Add deploy key, on the mid-upper-right hand side of the screen.
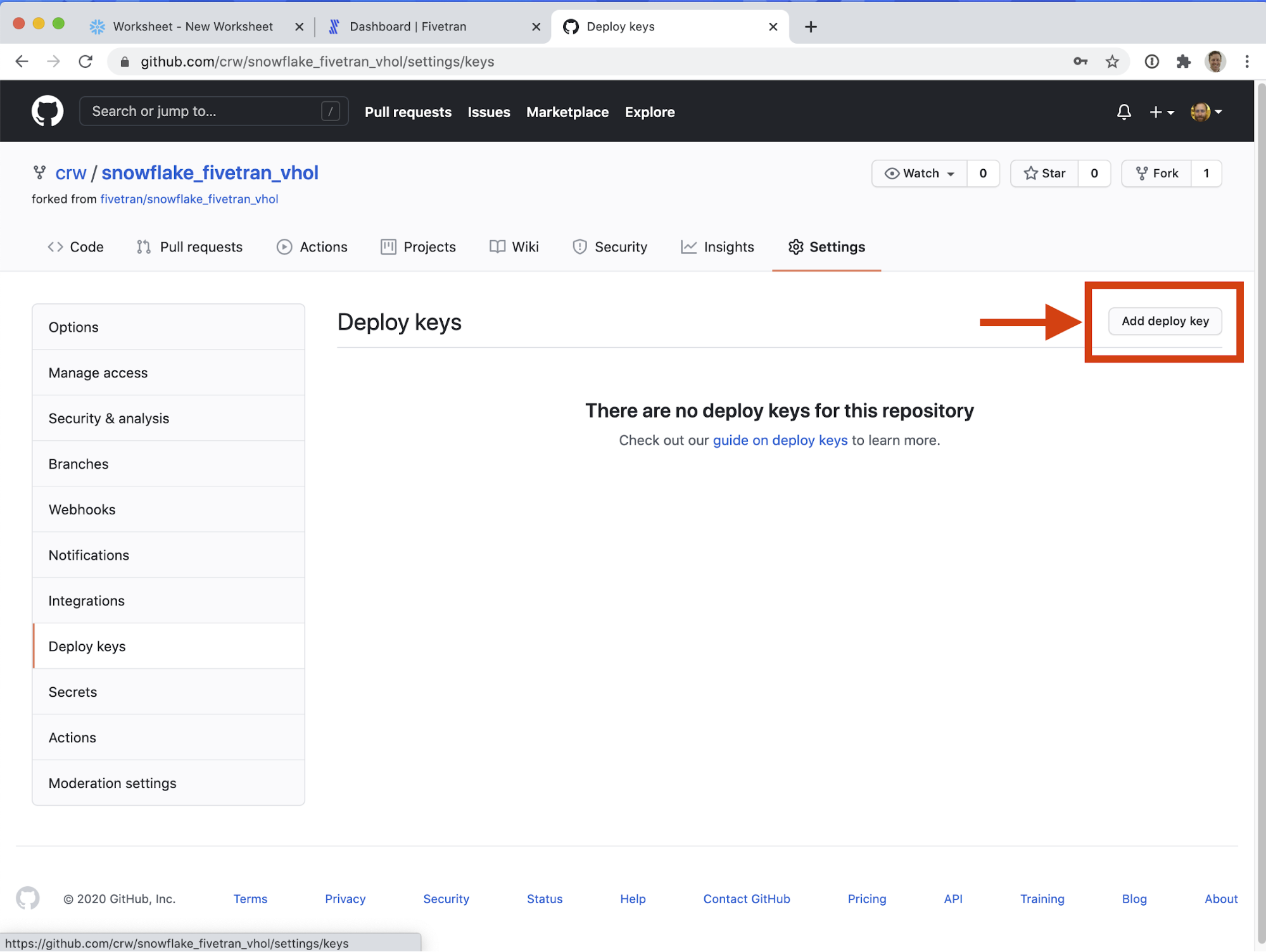
- Give the deploy key a memorable, distinct title, like Fivetran dbt access. Paste the previously-copied deploy key in the Key field. DO NOT check "Allow write access" - currently Fivetran only requires read access to the repository. Click Add key
Phew! Done! If at any time you want to revoke Fivetran's access to this repository, come back to this screen and delete the deploy key we just created. - Before leaving Github, return to the Code tab.
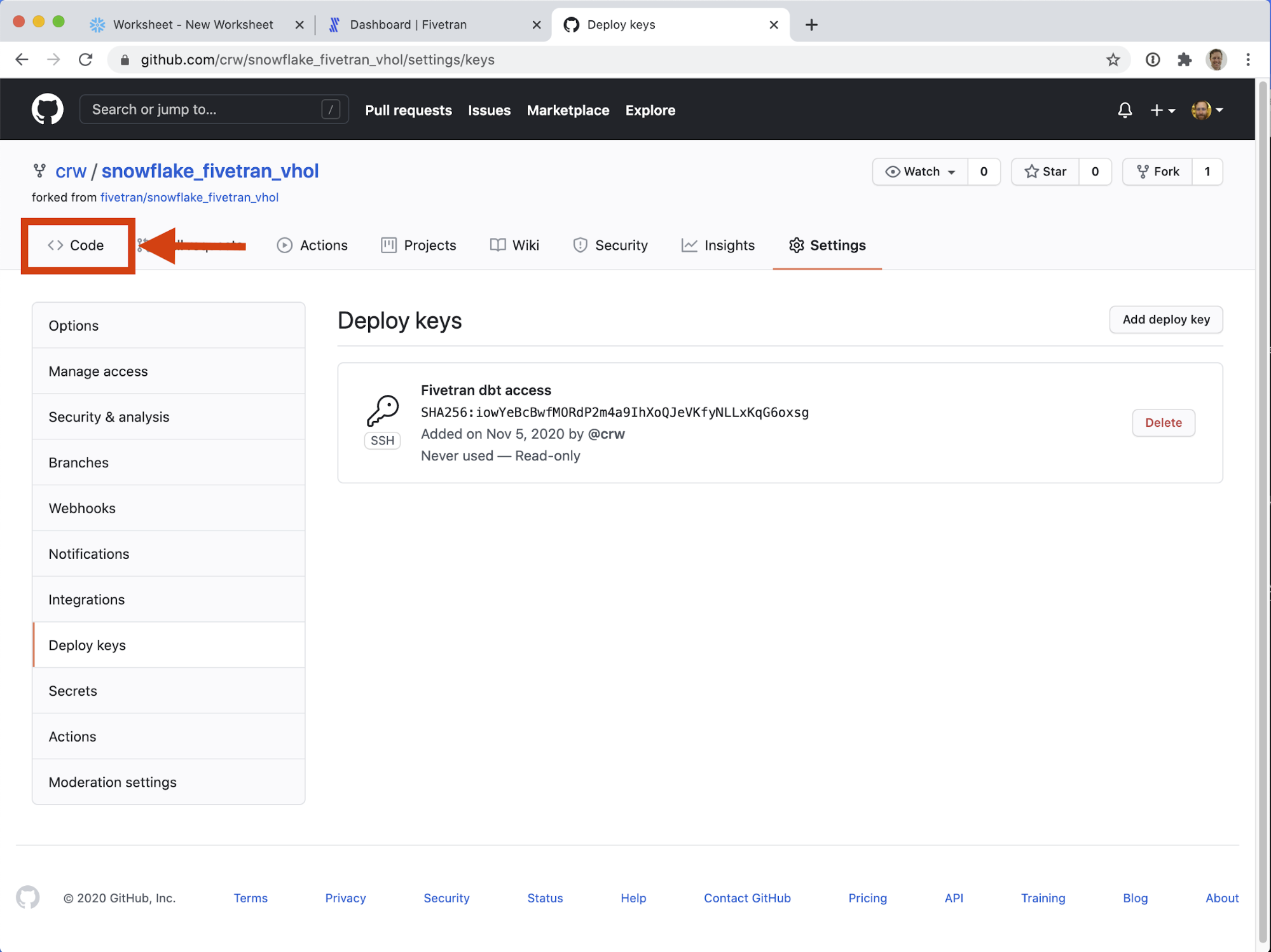
- Now click the green Code button. Make sure the SSH tab is selected, and copy the: git@github.com:your_username/snowflake_fivetran_vhol.git URL. We will need it on the next step. Note: it is safe to ignore errors about not having an SSH key configured here. The Deploy Key we configured will give Fivetran access to this repository.
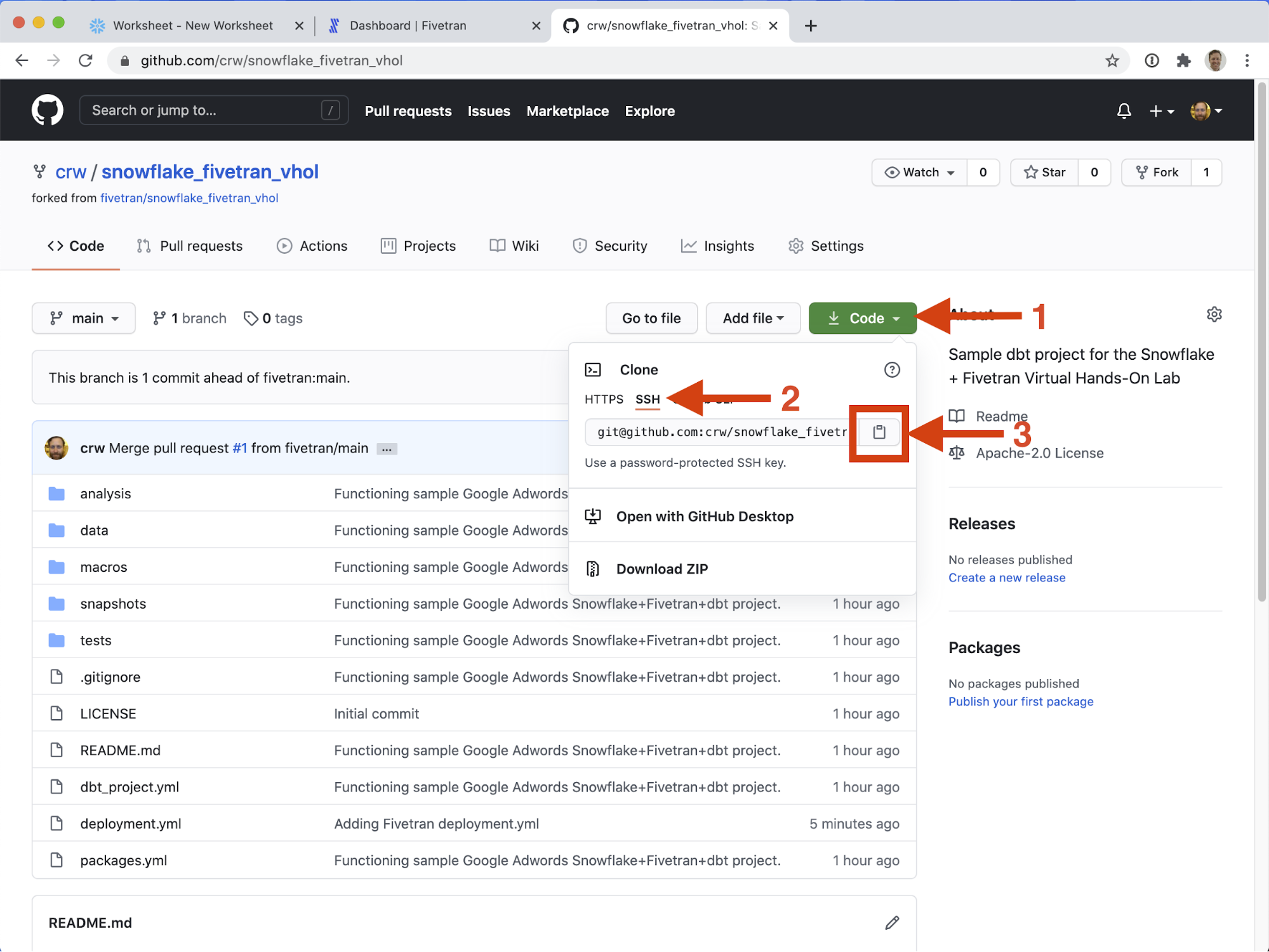
- Paste the value into the Repository URL field.
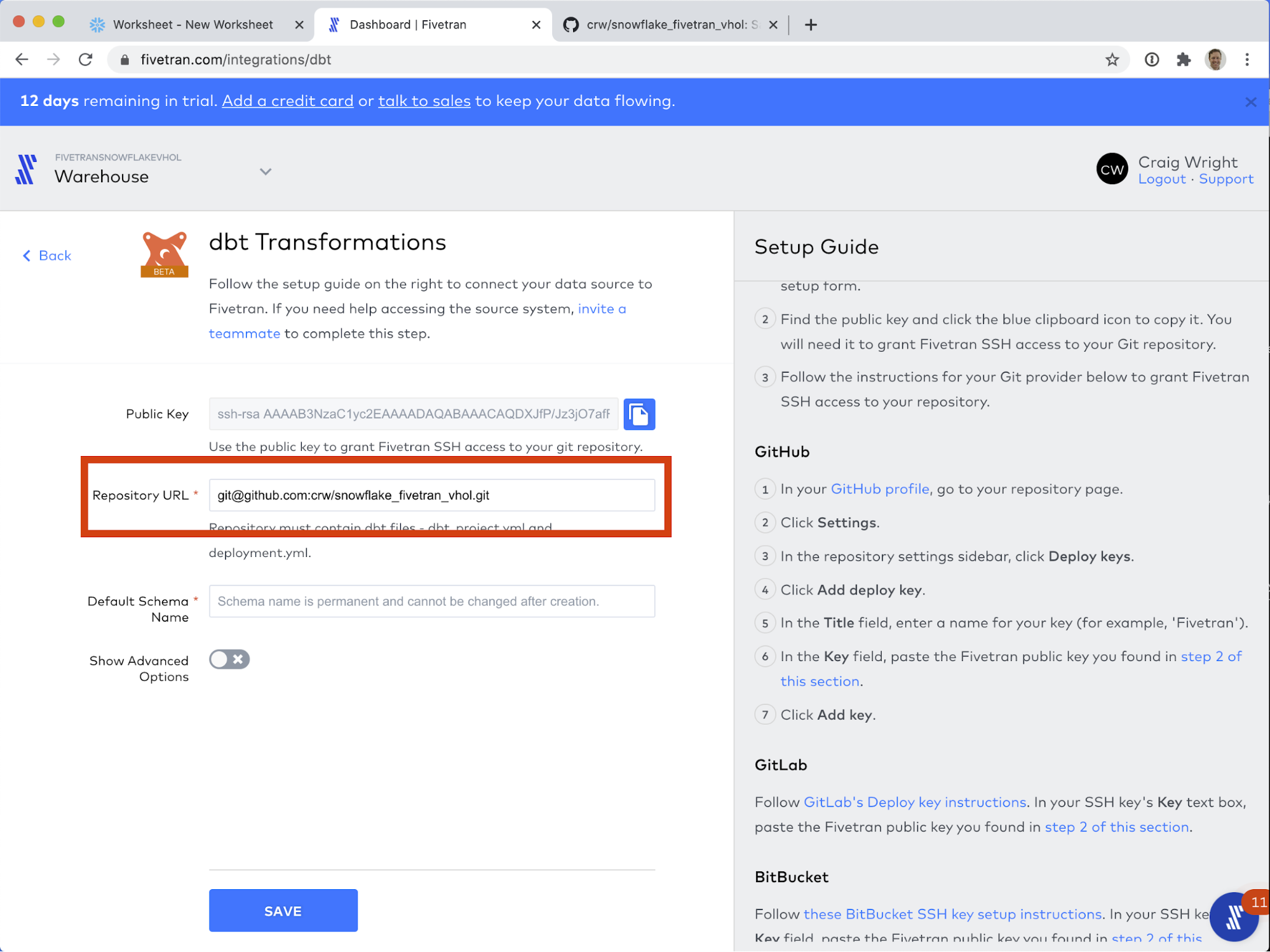
- For Default Schema Name field, enter GOOGLE_ADS_DBT
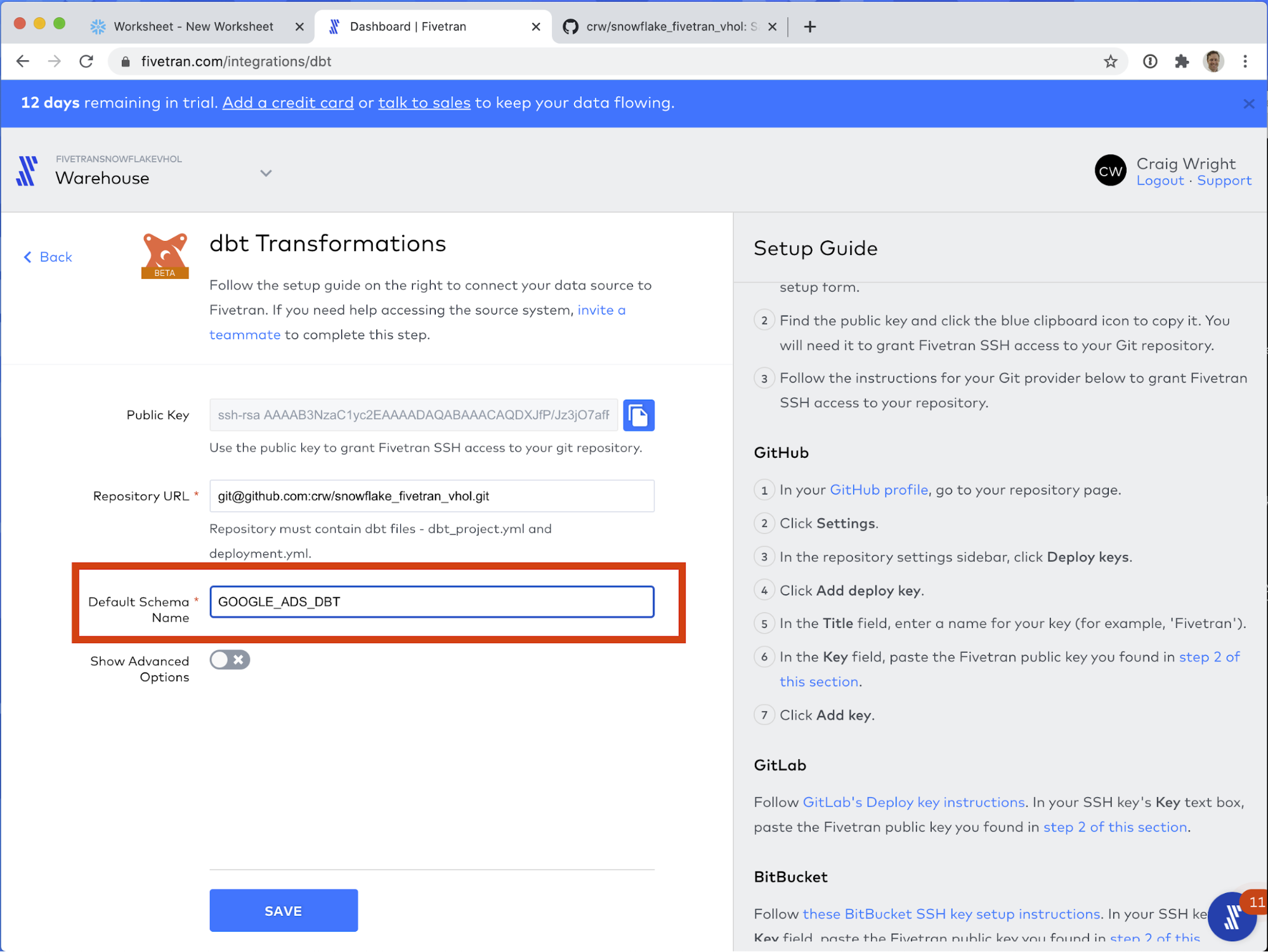 As of this writing, you need to perform the next actions to continue.Note: Github has changed their default branch name to "main". This change was made very recently, and Fivetran has not yet caught up to the new naming convention. For the time being, for this guide, we will need to manually change the branch name.
As of this writing, you need to perform the next actions to continue.Note: Github has changed their default branch name to "main". This change was made very recently, and Fivetran has not yet caught up to the new naming convention. For the time being, for this guide, we will need to manually change the branch name. - Click Show Advanced Options.
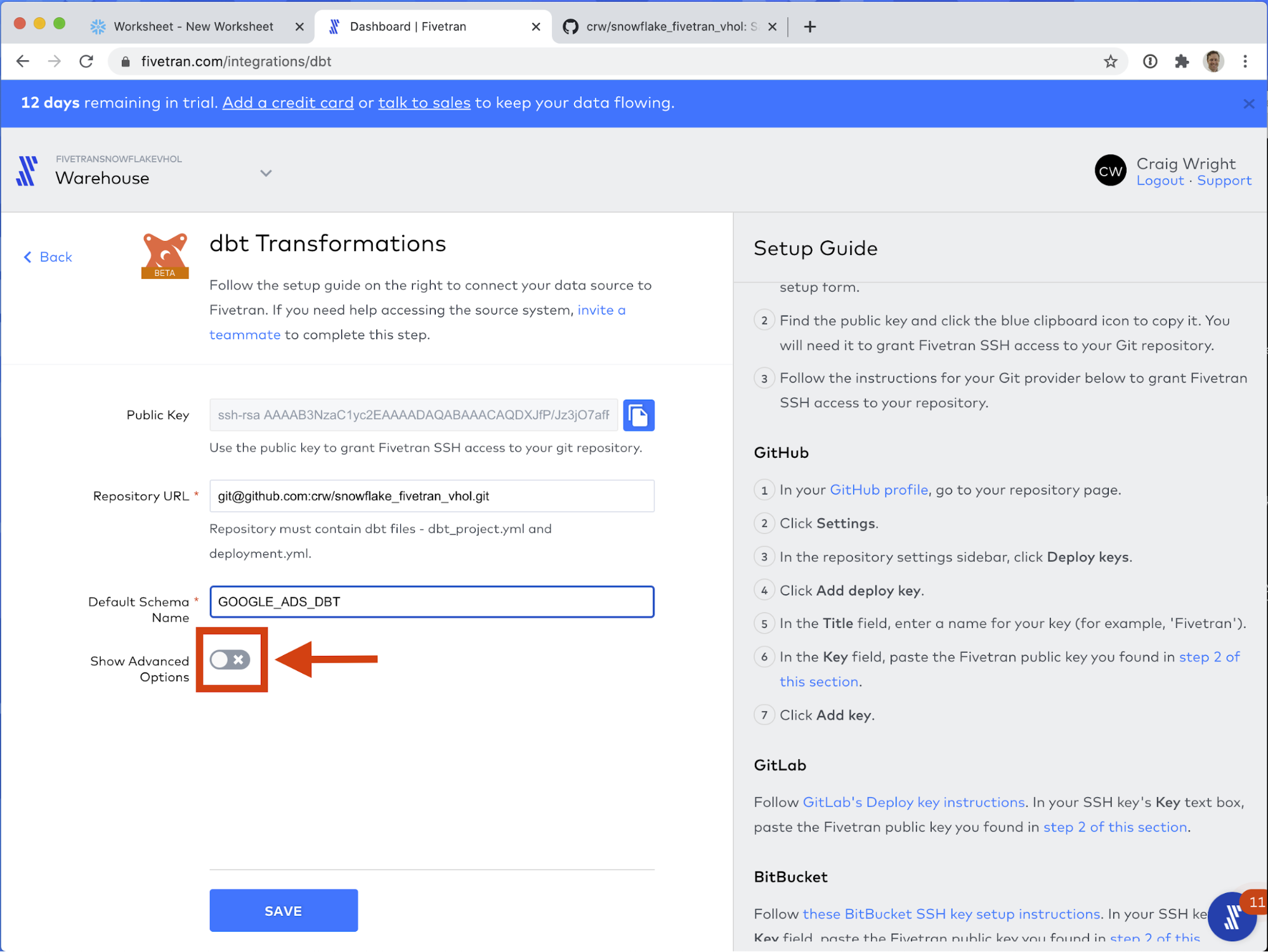
- Change the Git branch field's value to main.
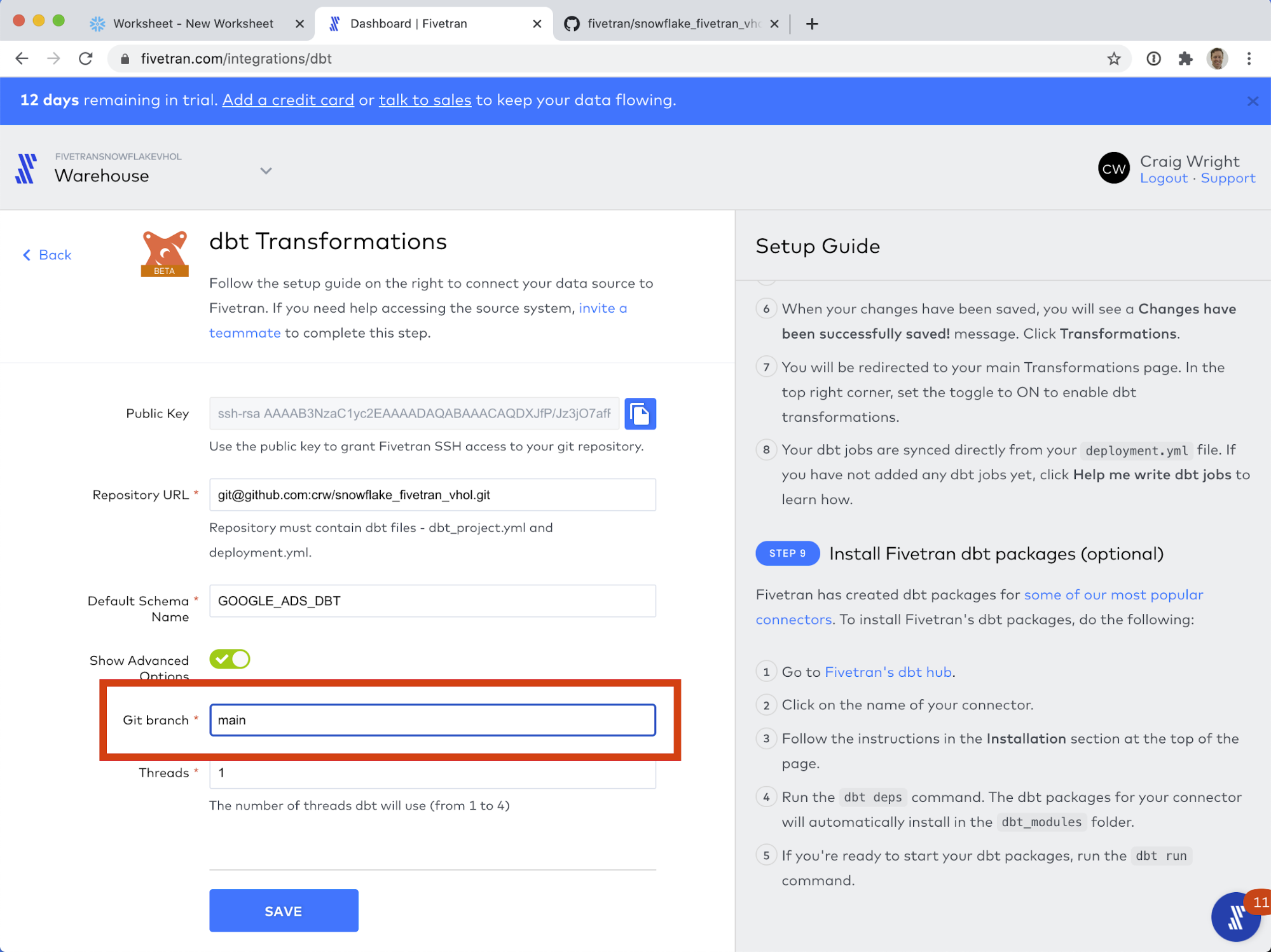
- Click SAVE. Then when you see the green success message, click TRANSFORMATIONS.
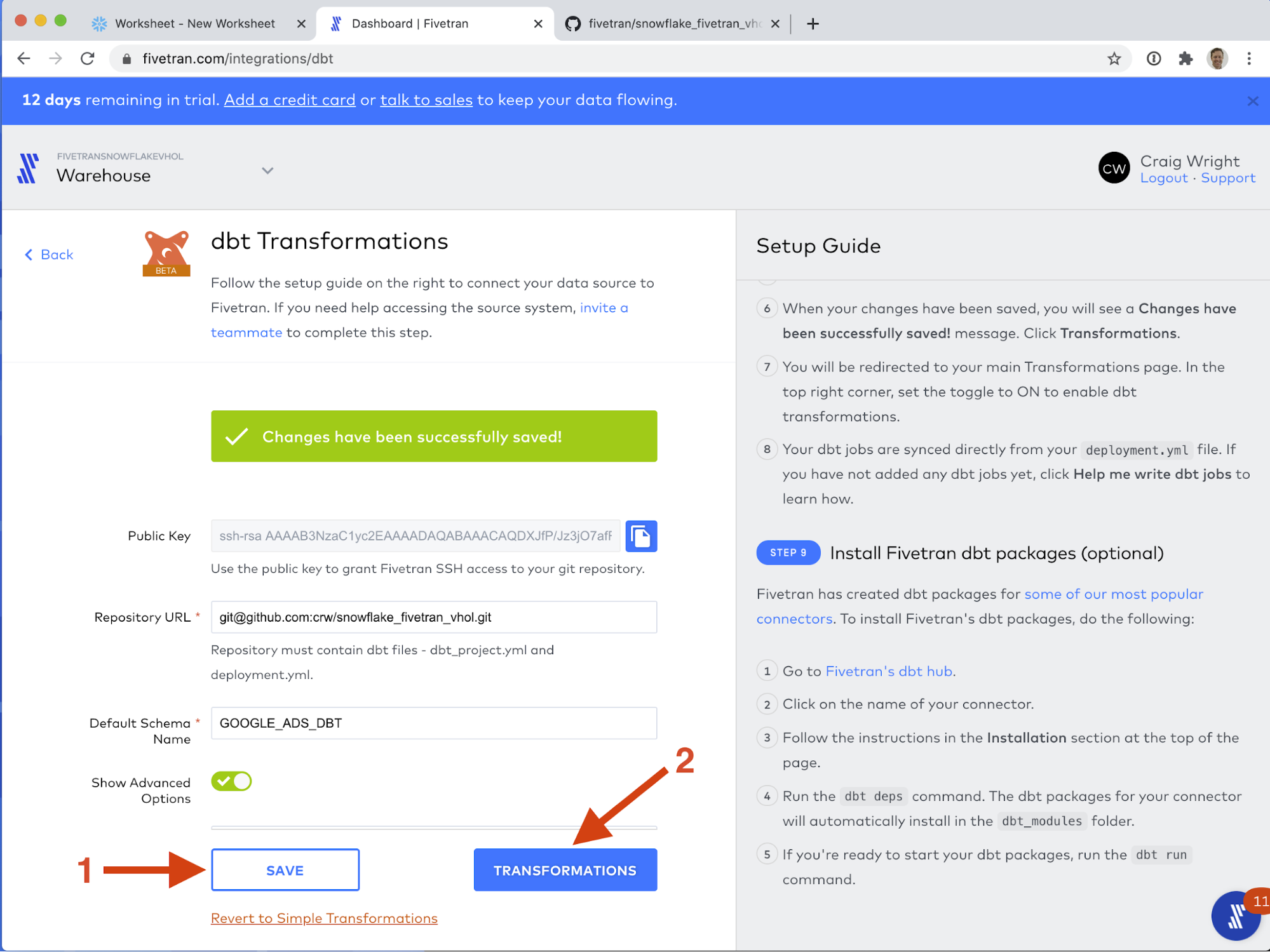
- That's it! Your dbt project is now configured to run and be orchestrated with Fivetran. In the upper right corner, there is a toggle switch, Activate dbt Transformations. Click this switch to start your transformations running.
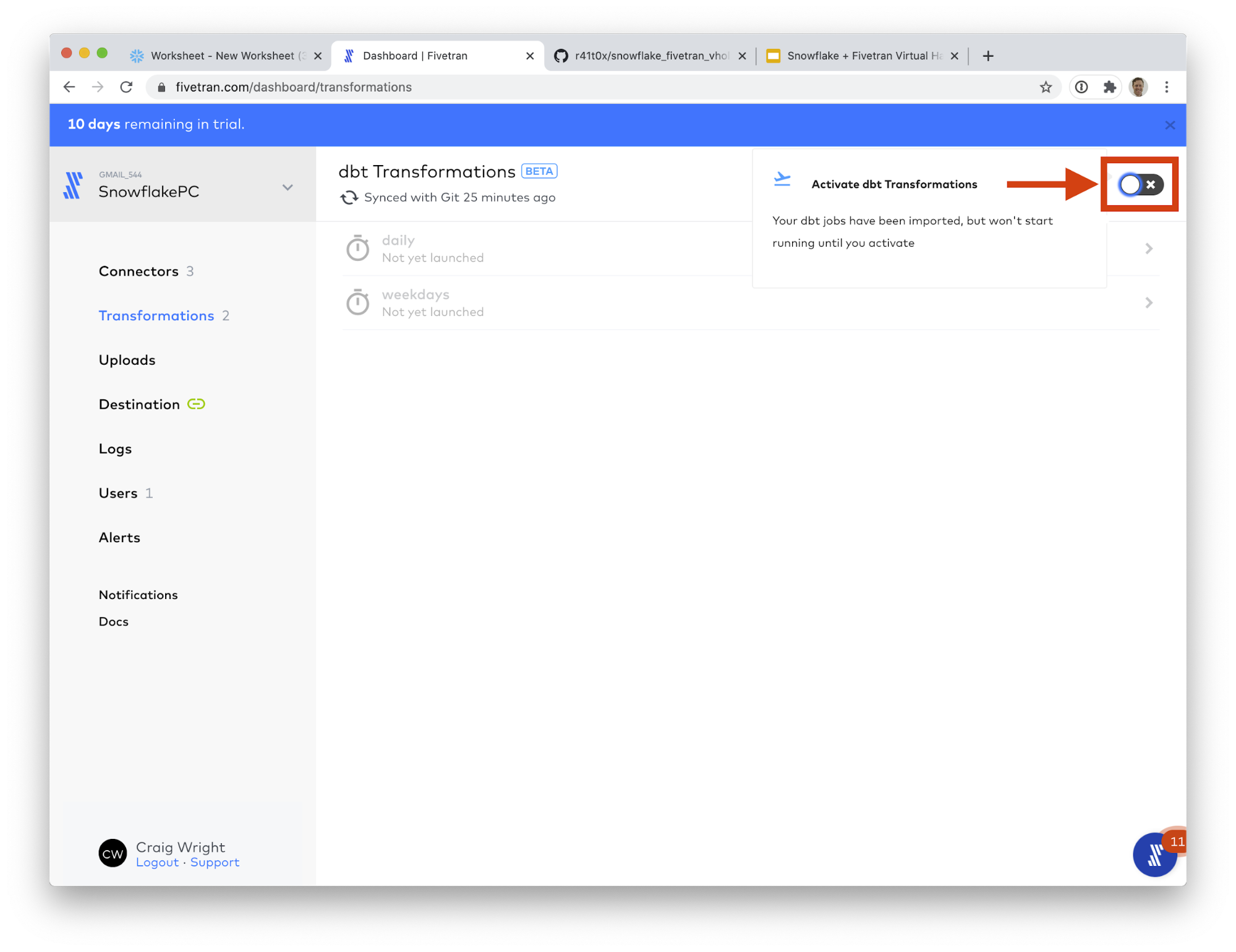
- Now if left to their own devices, your transformations will run on the schedules listed below. As a reminder, these schedules are configured in the deployment.yml file, as discussed in the previous section. But let's run one right away! Click on the weekdays line item.
- In the upper right corner, click Run now (the circular arrow icon.)
- The dbt job runs successfully! Click on the line item with the green checkmark next to it.
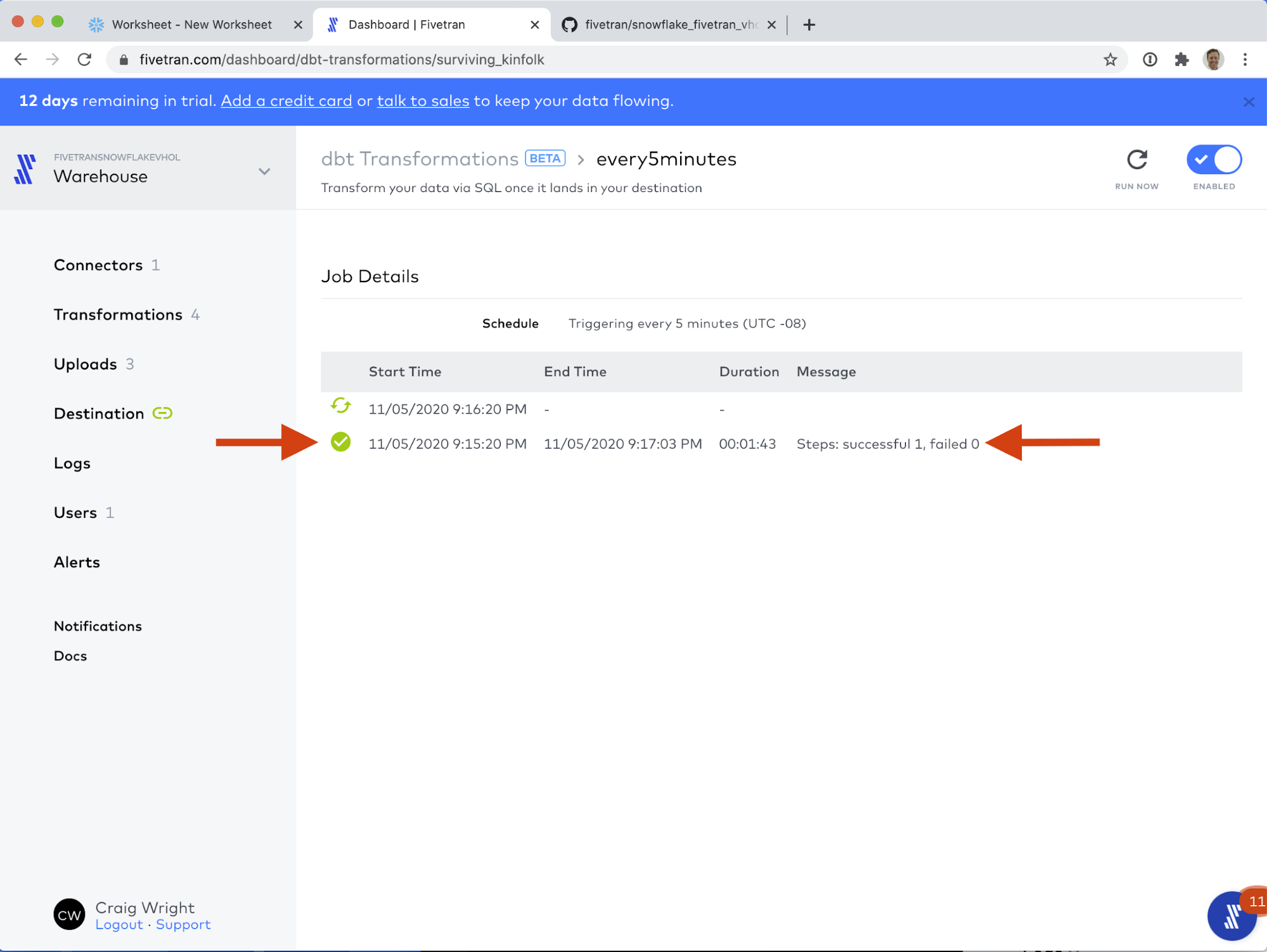
- Here we can see the results of running the dbt job. Click on the down arrow (caret) next to run models.
This exposes the results of running the dbt job. If you scroll to the bottom of the page, you can see the job ran successfully. 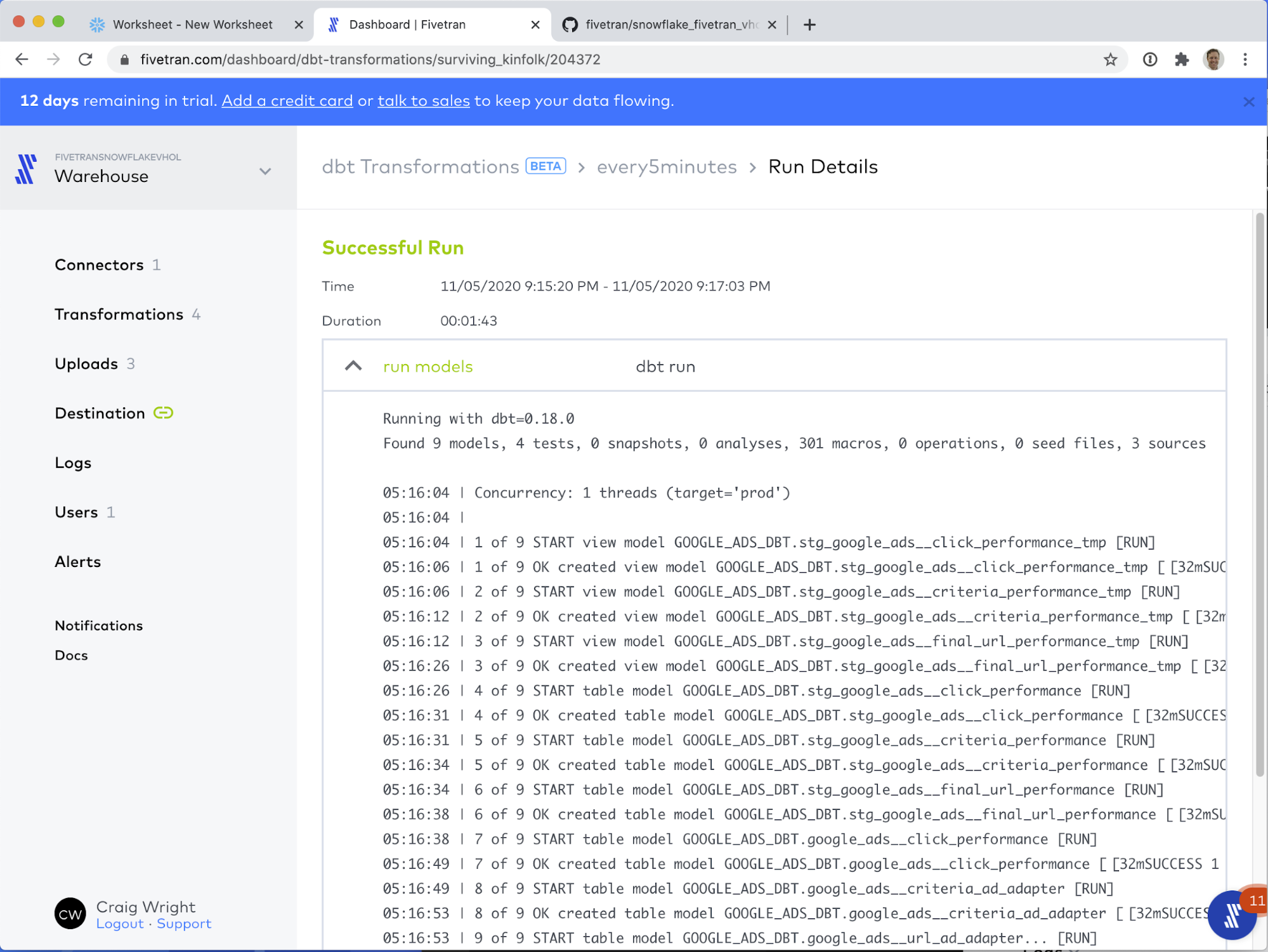
Congratulations! You have successfully run your first dbt job!
In Snowflake (optional): We can see the results of all of this hard work in the Snowflake Worksheets view. On the left hand column, you can see the GOOGLE_ADS_DBT schema which has the results of running our dbt job: fresh models, produced simply by including Fivetran's open source dbt_google_ads package! We are that much closer to exposing the true value of this data!
The tables created by these models do the following:
- GOOGLE_ADS__CRITERIA_AD_ADAPTER
- Each record represents the daily ad performance of each criteria in each ad group and campaign.
- GOOGLE_ADS__URL_AD_ADAPTER
- Each record represents the daily ad performance of each URL in each ad group, including information about the used UTM parameters.
- GOOGLE_ADS__CLICK_PERFORMANCE
- Each record represents a click, with a corresponding Google click ID (gclid).
Did You Know? All of the code that produces these models is open source! Fivetran officially supports over 20 open source dbt packages that model data delivered by Fivetran, typically to provide commonly required aggregations. You can see all of the available packages at https://hub.getdbt.com/ - scroll down to the Fivetran section.
The two packages we use in this lab are the Google Ads packages: google_ads_source source code on githubgoogle_ads source code on github
You can save considerable development time by leveraging Fivetran's open source dbt packages with data delivered by Fivetran. Now that you have a running dbt project, feel free to try including more packages!
The summary so far: Maintenance-free data pipelines and powerful in-warehouse transformations
In the previous sections, we learned the following skills:
- How to setup a Fivetran connector (in this case, a Google Sheets connector)
- How to create a dbt project by forking the snowflake_fivetran_vhol sample repository
- How to enable dbt Transformations in Fivetran by connecting our repository
In doing so, we have set up a complete, end-to-end modern data pipeline focusing on the advantages of the Extract-Load-Transform (ELT) architectural approach. Data loading is extremely simple to configure and comes with the benefit of hands-free maintenance, forever. dbt is a powerful transformation tool that comes with many open source Fivetran modeling packages out-of-the-box. Moreover, Fivetran manages the execution of those transformation jobs, and the jobs run natively in the Snowflake warehouse, exposing all of the pßower of Snowflake's query engine to your transformations.
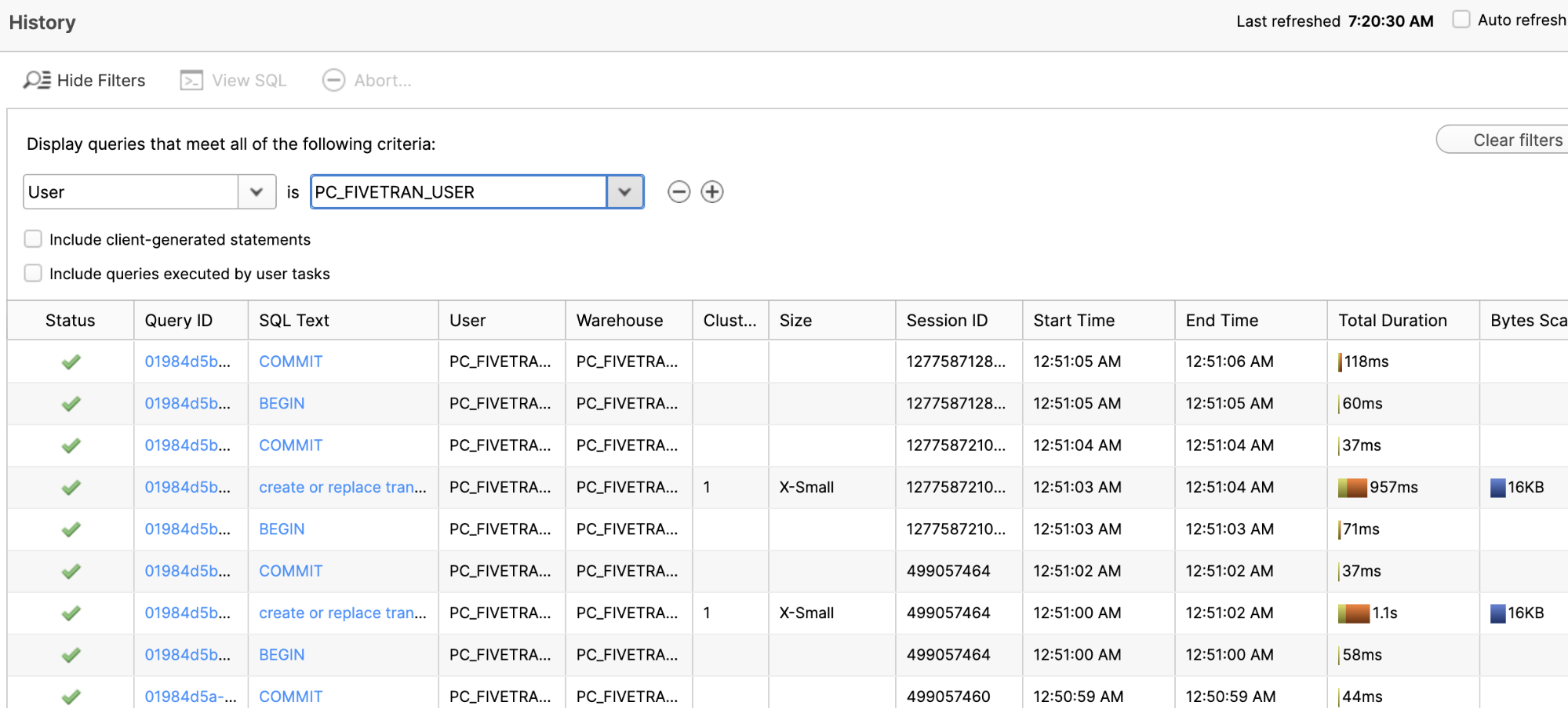
- Back in the Snowflake UI, let's take a quick look at the query history to see all the work that Fivetran/dbt performed.

- Click on Add a filter.
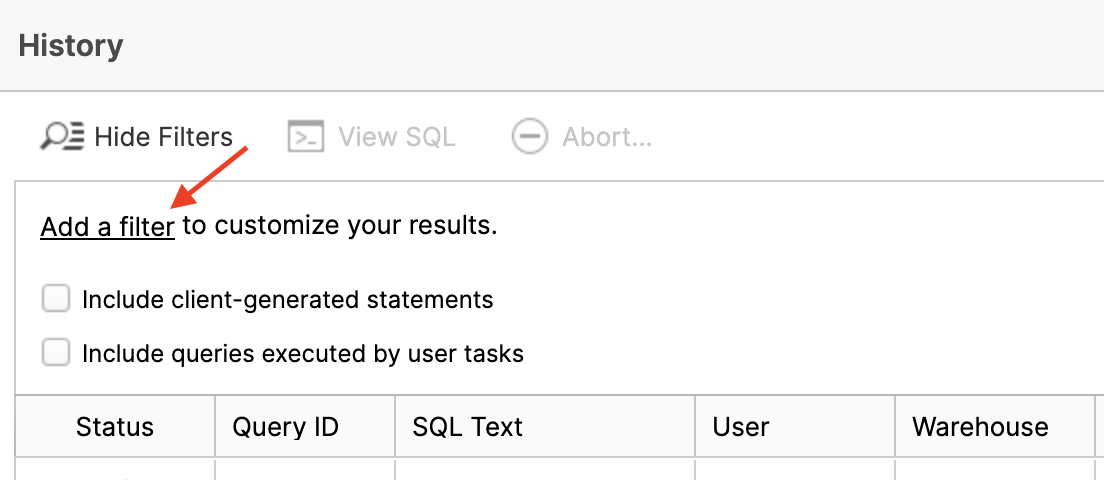
- Change the left box to User and select PC_FIVETRAN_USER in the right box. All of the Fivetran/dbt queries executed as this user.

- In the table below you can see all of these queries. Scroll down. Click on a SQL Text value and you'll see a pop-up of the specific SQL statement. You can read about this UI screen here.
- Click on the Worksheets tile at the top.
- Your screen will look like this. This is where we will do most of our remaining work.
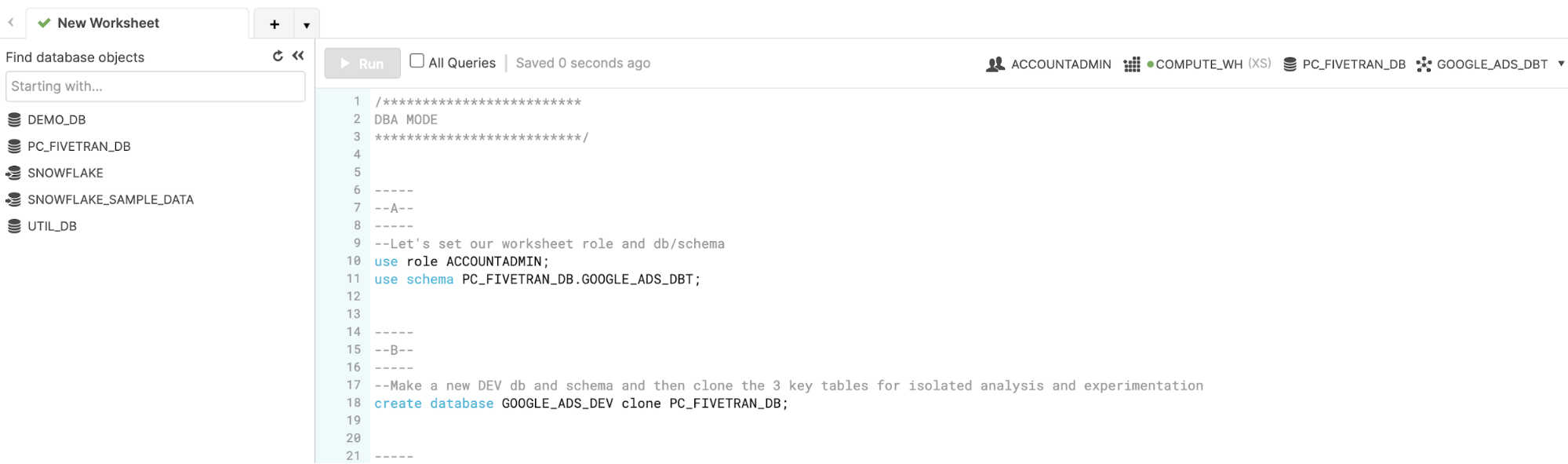
- Now load the script (vhol_script.sql) by clicking on the button and then selecting in the pop-up. Navigate your computer and find the script.
- The script should appear in your worksheet like this.
- Notice on the left-hand side is a database browser with a database called PC_FIVETRAN_DB. This is the database that you loaded with Fivetran. Click on it and you will see the schemas. GOOGLE_ADS_DEMO is where the data initially loaded and GOOGLE_ADS_DBT is the schema created by the dbt process. Click on GOOGLE_ADS_DBT and you'll see the tables and views that live within.
- Let's start our work performing DBA functions. We need to set the context we want to use within the worksheet. In each worksheet I can have a different role, warehouse, database, and schema. Each worksheet is independent of the others (like Snowflake compute!). My worksheet role can also be different from the role I have in the upper right-hand corner under my name.
Let's execute the SQL in script section A to set our worksheet context. To do so, highlight the two lines (use role..., use schema...) and click the button.
button.
Pro Tip: You may get a pop-up asking if you want to run both statements. If you don't want this warning every time, click in the check box and click OK.
/*-----
--A--
-----
--Let's set our worksheet role and db/schema*/
use role ACCOUNTADMIN;
use schema PC_FIVETRAN_DB.GOOGLE_ADS_DBT;
Notice that your worksheet context now has a default role, database, and schema but no warehouse (yet).

- Let's pretend that the data we loaded and transformed with Fivetran is our production data. We only want it to be changed by our Fivetran process. Since our analysts will want to experiment with and change the data, we'll CLONE the entire PC_FIVETRAN_DB database so they can have their own sandbox. This is a logical copy; it will consume no additional space unless the data in the clone starts to change. This is a fantastic tool for creating as many sandboxes as you need. It also works well for making time-specific snapshots.
Cloning reduces time to value - full production clones are fast and support more accurate analytical results because they are rich and complete data sets. - Run the Create Database SQL and the Use Schema commands in section B to make a clone, then refresh the database browser with the (small)
 button:
button:
/*-----
--B--
-----
--Make a new DEV db and schema and then clone the 3 key tables for isolated analysis and experimentation*/
create database GOOGLE_ADS_DEV clone PC_FIVETRAN_DB;
use schema GOOGLE_ADS_DEV.GOOGLE_ADS_DBT;
Now your analysts have GOOGLE_ADS_DEV - a complete clone of PC_FIVETRAN_DB.
- Next we need to create a warehouse (compute) for the analysts. For this workshop we'll create an Extra Small - the smallest unit of Snowflake compute - with an auto suspend time of 2 minutes and auto resume enabled. Auto resume means it will start up when a request is made. Run the SQL in section C to create the warehouse. Notice that this warehouse is now in your worksheet context.
/*-----
--C--
-----
--Create a virtual warehouse (compute) for the Marketing Analyst team to do their work*/
create or replace warehouse MKT_ANALYSIS with warehouse_size = 'XSMALL' auto_suspend = 120 --seconds
auto_resume = TRUE;
_**Snowflake compute is unique. It's (1) easy to define and manage; (2) fast to activate and suspend; (3) self-suspending; (4) self-healing; (5) isolated from the storage layer; (6) isolated from other compute; (7) quick to scale up/down and out/in; (8) non-disruptive when any of this is happening.**_
- For our last act as DBA we'll create a resource monitor to track warehouse consumption. Resource monitors are convenient tools for setting time-based consumption thresholds on compute at the warehouse or account level. You can set alerts for various thresholds and even prevent a warehouse from running once it reaches a credit value that you set.
/*-----
--D--
-----
--Create a resource monitor to track credit usage of the marketing virtual warehouse*/
create or replace RESOURCE MONITOR "MARKETING_ANALYSIS" with CREDIT_QUOTA = 20,
frequency = 'DAILY',
start_timestamp = 'IMMEDIATELY',
end_timestamp = null triggers
ON 100 PERCENT DO SUSPEND
ON 5 PERCENT do NOTIFY
ON 10 PERCENT do NOTIFY
ON 50 PERCENT do NOTIFY
ON 90 PERCENT do NOTIFY;
alter WAREHOUSE "MKT_ANALYSIS"
set RESOURCE_MONITOR = "MARKETING_ANALYSIS";
Run the two SQL statements in section **D** to create a resource monitor that has a daily 20 credit limit, sends an alert at 5%, 10%, 50%, and 99% thresholds, and suspends the warehouse at 100% (20 credits). The second statement associates the resource monitor to the warehouse.
- Now we'll switch to ‘Analyst mode'. In real life this would be a different person with a different userid and a different Role. An analyst might write a query like the one in section E of the script to answer the question "What was the best performing cranberry sauce campaign?" Go ahead and run it. We're working with tiny data sets in the lab but in reality we might run over millions or billions of rows.
/*-----
--E--
-----
--What was the best performing cranberry sauce campaign?*/
select ad_group_name,
campaign_name,
sum(spend) as TOT_SPEND,
sum(clicks) as TOT_CLICKS,
sum(impressions) as TOT_IMPRESSIONS,
sum(impressions) / sum(spend) as IMPRESSIONS_PER_DOLLAR,
sum(spend) / sum(clicks) as cost_per_click
from GOOGLE_ADS__URL_AD_ADAPTER
where ad_group_name = 'cranberry sauce'
group by ad_group_name,
campaign_name
order by 6 desc;
- These are interesting results, but you have a hypothesis: clicks increase with snowy weather. Let's go to the Snowflake Marketplace and find what we need. The Data Marketplace lives in the new UI called Snowsight (currently in Preview mode but feel free to test drive after the lab). Click on Preview App at the top of the UI.
- Click Sign in to continue. You will need to use the same user and pw that you used to login to your Snowflake account the first time.

- You're now in the new UI - Snowsight. It's pretty cool - with charting and dashboards and context-sensitivity - but today we're just focused on getting to the Data Marketplace. Click on Data...

- ...and then Marketplace...
- ...and now you're in! Over 100 providers have made datasets available for you to enrich your data. Today we're going to grab a sample of weather data. Click the Ready to Query checkbox...
- And then find the Weather Source tile. Once you find it, click on it.
- Here you'll find a description of the data, example queries, and other useful information. Let's get this data into our Snowflake account. You'll be amazed at how fast and easy this is. Click
 .
. 
- In the pop-up, rename the database to WEATHERSOURCE (important!), check the "I accept..." box and then
 . No need to add additional roles (though you might in real-life).
. No need to add additional roles (though you might in real-life).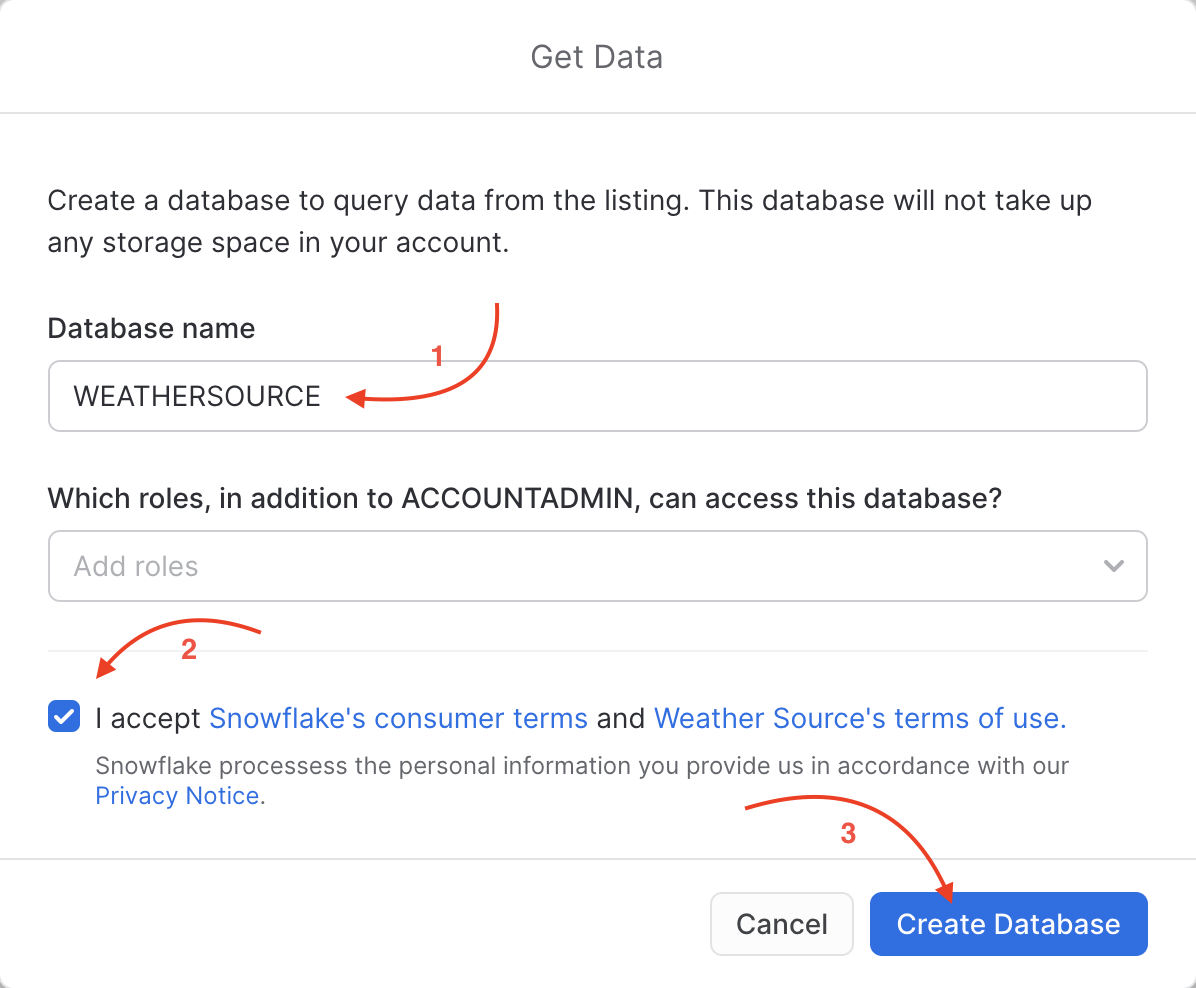 What is happening here? Weather Source has granted access to this data from their Snowflake account to yours. You're creating a new database in your account for this data to live - but the best part is that no data is going to move between accounts! When you query you'll really be querying the data that lives in the Weather Source account. If they change the data you'll automatically see those changes. No need to define schemas, move data, or create a data pipeline either. Isn't that slick?
What is happening here? Weather Source has granted access to this data from their Snowflake account to yours. You're creating a new database in your account for this data to live - but the best part is that no data is going to move between accounts! When you query you'll really be querying the data that lives in the Weather Source account. If they change the data you'll automatically see those changes. No need to define schemas, move data, or create a data pipeline either. Isn't that slick? - Now click Done. You can close this browser tab and go back to the other Snowflake UI that you started in.
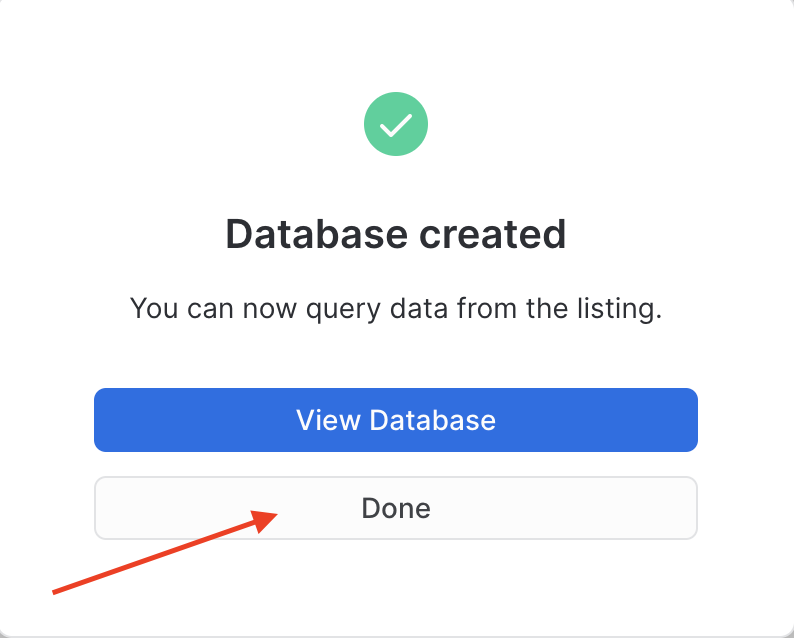
- Refresh the database browser and notice you have a new shared database, ready to query and join with your data. Click on it and you'll see views under the PUBLIC schema. We'll use one of these next.
- With production-sized data sets we are likely to have very large tables and complex queries; therefore, we might want to increase the amount of compute we're using to perform this analysis. In Snowflake this is fast and easy. Run the statement in section G. Notice how fast it scales up. No disruption. No shuffling of data. We've changed from an XS (one node cluster) to an XL (16 node cluster) in seconds. Ready to go!
/*-----
--G--
-----
--With production-sized data sets we might want to join and query tables with billions of rows
--In these cases it's easy and productive to scale up our virtual warehouse so these queries run faster*/
alter warehouse mkt_analysis set warehouse_size = 'XLARGE';
- So, let's join that weather data to our Google Ads data and see if there is a correlation between clicks and snowfall. Run the correlation query in section H. Remember that we're actually joining data across two accounts, but the experience and performance is seamless and fast.
/*-----
--H--
-----
--Is there any correlation between clicks and snowfall for any ad group?*/
select ad_group_name,
abs(corr(clicks, w.tot_snowfall_in)) as clicks_snow_corr
from GOOGLE_ADS__URL_AD_ADAPTER ga,
"WEATHERSOURCE"."PUBLIC"."HISTORY_DAY" w
where ga.date_day = w.date_valid_std
group by 1
order by 2 desc;
It's a weak correlation so maybe our hypothesis isn't worth exploring further. But our ability to quickly source Marketplace data and mash it with our own data has saved us lots of time and we can iterate further.

- Because this combination may yet have value, let's create a view that combines the correlations with the URL data so others can take a look more easily. Run the SQL in section I. One creates the view and the other queries it.
/*-----
--I--
-----
--Let's create new view with the correlations built in to the URL_AD_ADAPTER data*/
create or replace view GOOGLE_ADS__URL_AD_ADAPTER_CORR as (
with corr as (
select ad_group_name,
abs(corr(clicks, w.tot_snowfall_in)) as clicks_snow_corr
from GOOGLE_ADS__URL_AD_ADAPTER ga,
"WEATHERSOURCE"."PUBLIC"."HISTORY_DAY" w
where ga.date_day = w.date_valid_std
group by 1
),
base as (
select *
from GOOGLE_ADS__URL_AD_ADAPTER
)
select b.*,
c.clicks_snow_corr
from base b,
corr c
where b.ad_group_name = c.ad_group_name
);
select *
from GOOGLE_ADS__URL_AD_ADAPTER_CORR;
- Now that our heavy lifting is done, let's scale down the warehouse size. No need to pay for more compute than we need. Run the SQL in section J.
/*-----
--J--
-----
--Once we're done with our complex queries we scale the warehouse back down*/
alter warehouse mkt_analysis set warehouse_size = 'XSMALL';
- For our last trick let's imagine we've accidentally dropped the table we're working with. No one has ever done that! Run the DROP statement in section K and then refresh the database browser. Notice the table is gone. Now run the UNDROP and refresh. It's back! This is the power of time travel. You can restore lost data for up to 90 days of history.
/*-----
--K--
-----
--Let's look at one last great feature of Snowflake. Have you ever accidentally dropped a table? Or a database?
--Let's 'accidentally' drop a table.*/
drop table GOOGLE_ADS__URL_AD_ADAPTER;
/*--Fortunately, in Snowflake, this is an easy fix.*/
undrop table GOOGLE_ADS__URL_AD_ADAPTER;
: _Time Travel also enables you to query and replace tables as of a particular point in time or prior to a specific SQL statement._
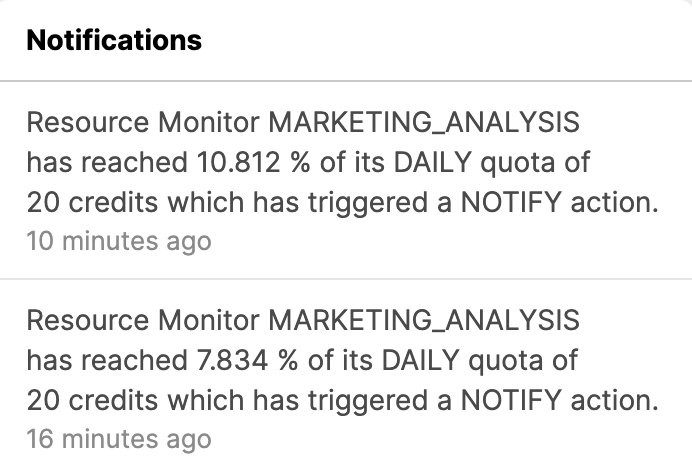
- One last thing. How is our Snowflake consumption looking? It's easy to understand. We'll look in two places. First, you might have a Notification, so click on that tile. When you have notifications enabled and resource monitors built, you'll get notifications.
- See anything that looks like this? These notifications come from the resource monitor we set up earlier in the lab. You'll also get emails with the same information.
- Now, click on the Account tile.

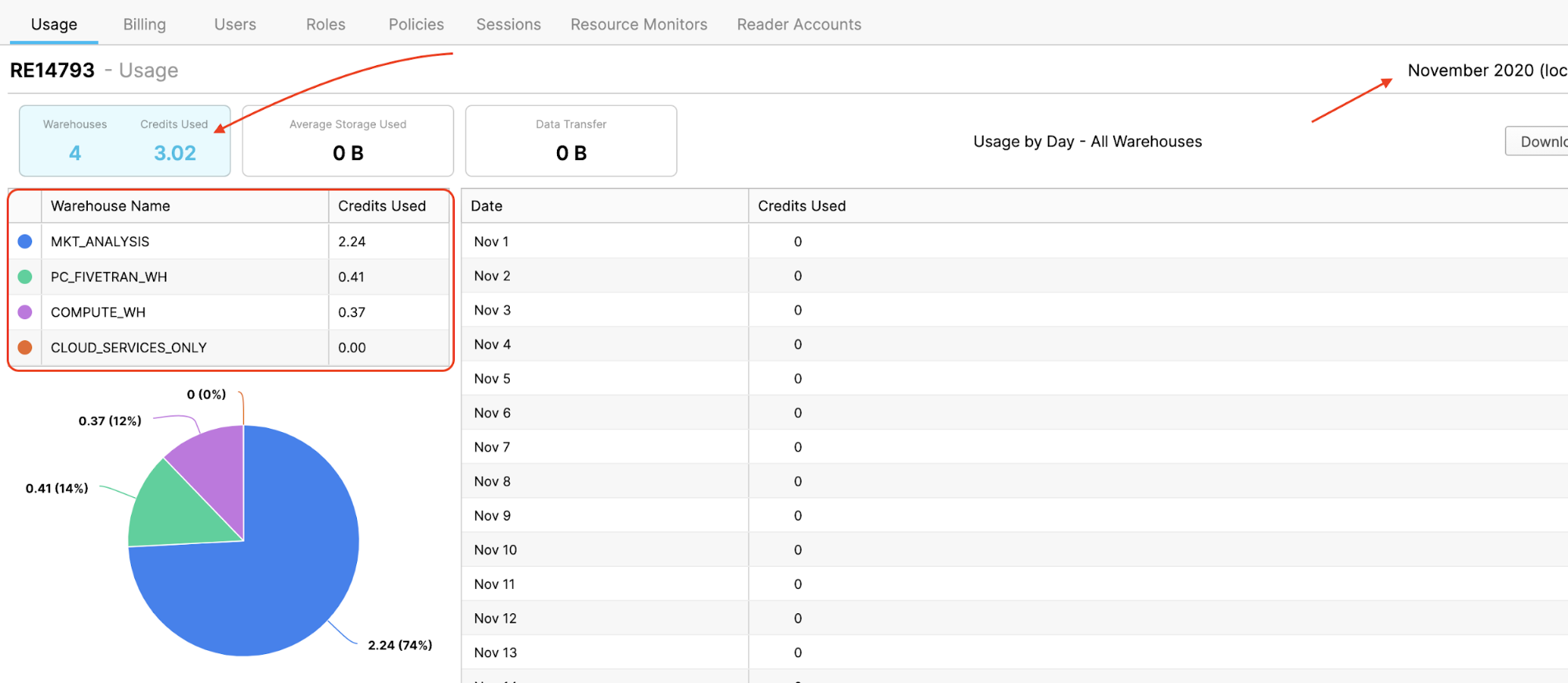
- Then click on Usage.

- Here you can see monthly/daily credit usage...
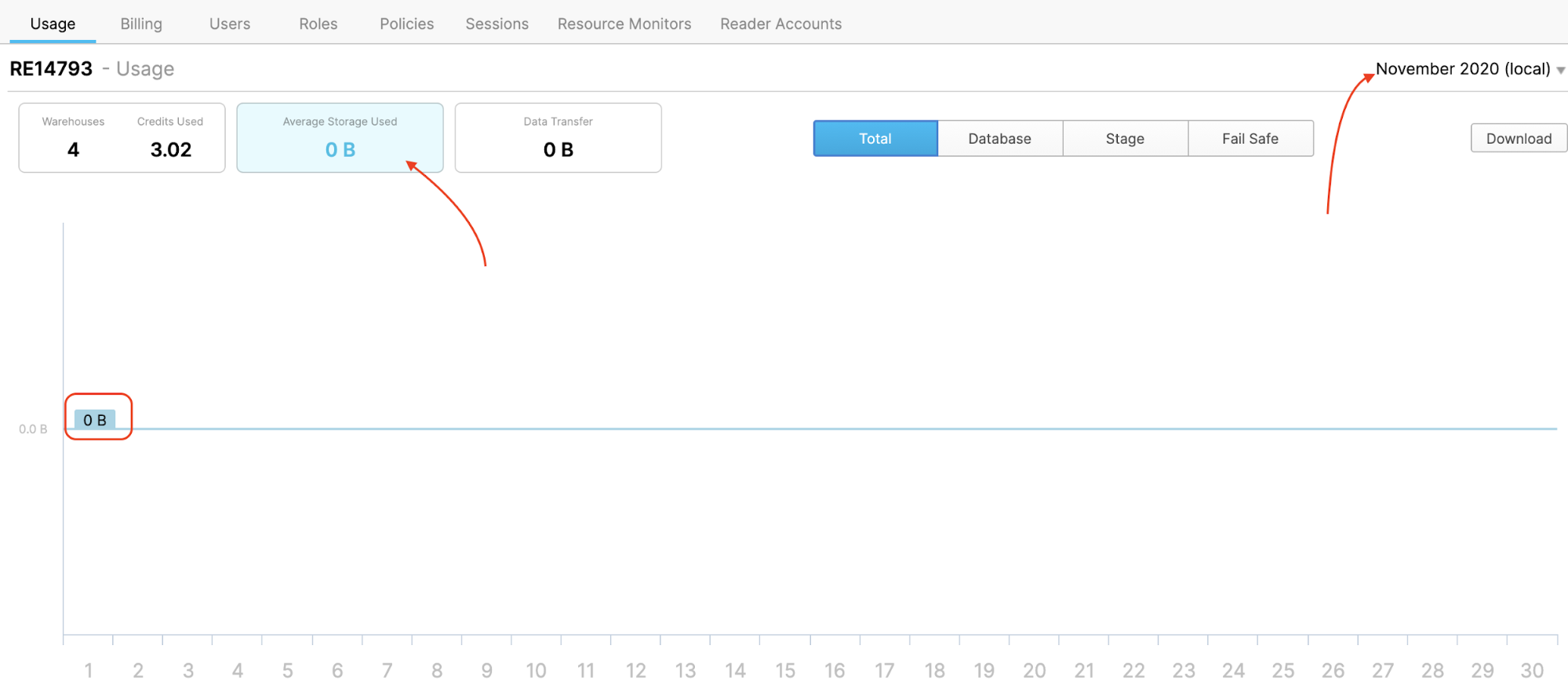
- ...and monthly/daily storage usage (you won't see much for storage yet since our data is small). In addition to these screens you can query the Snowflake metadata layer for the same info and build reports in your favorite BI tool.
This concludes the lab. We hope you learned a lot and are interested in exploring Fivetran and Snowflake for your use cases. Please feel free to ask questions.
Congratulations on completing this lab on automating data pipelines to drive marketing analytics! You've mastered the Fivetran and Snowflake basics and are ready to apply these fundamentals to your own data. Be sure to reference this guide if you ever need a refresher.
We encourage you to continue with your free trials by loading your own sample or production data and by using some of the more advanced capabilities of Fivetran and Snowflake not covered in this lab.
Additional Resources:
- Read the Definitive Guide to Maximizing Your Free Trial document
- Attend a Snowflake virtual or in-person event to learn more about our capabilities and customers
- Join the Snowflake community
- Sign up for Snowflake University
- Contact our Sales Team to learn more
What we've covered:
- How to begin a Fivetran trial through Snowflake's Partner Connect
- How to load Google Ads data into Snowflake using Fivetran
- How to run a dbt project via Fivetran to generate models
- How to create analyst sandboxes in Snowflake using clones
- How to leverage data in Snowflake's Data Marketplace
Enter a username, email address, and password. 
Solve the puzzle and continue! 
You can skip down to the bottom of this screen, or take the time to choose your interests. 
Choose Complete setup. 
Head to your email application and verify your email address. 
That's it! You now have a Github account. 
- Go to https://signup.snowflake.com/.
- Enter your personal information. You need to use a valid email address that you can access and haven't used previously.
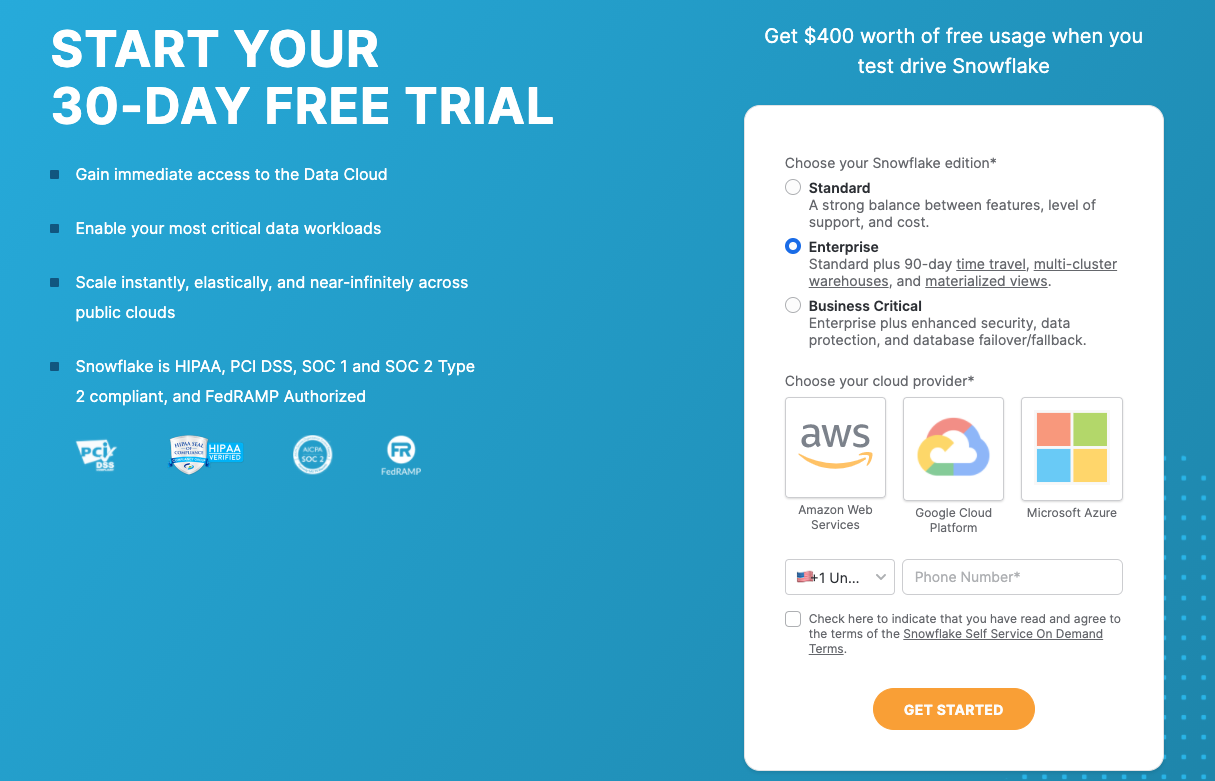
- When you sign up for Snowflake it auto-populates to Enterprise. This is the best choice for this lab. Choose the cloud/region closest to you and click the "GET STARTED" button.
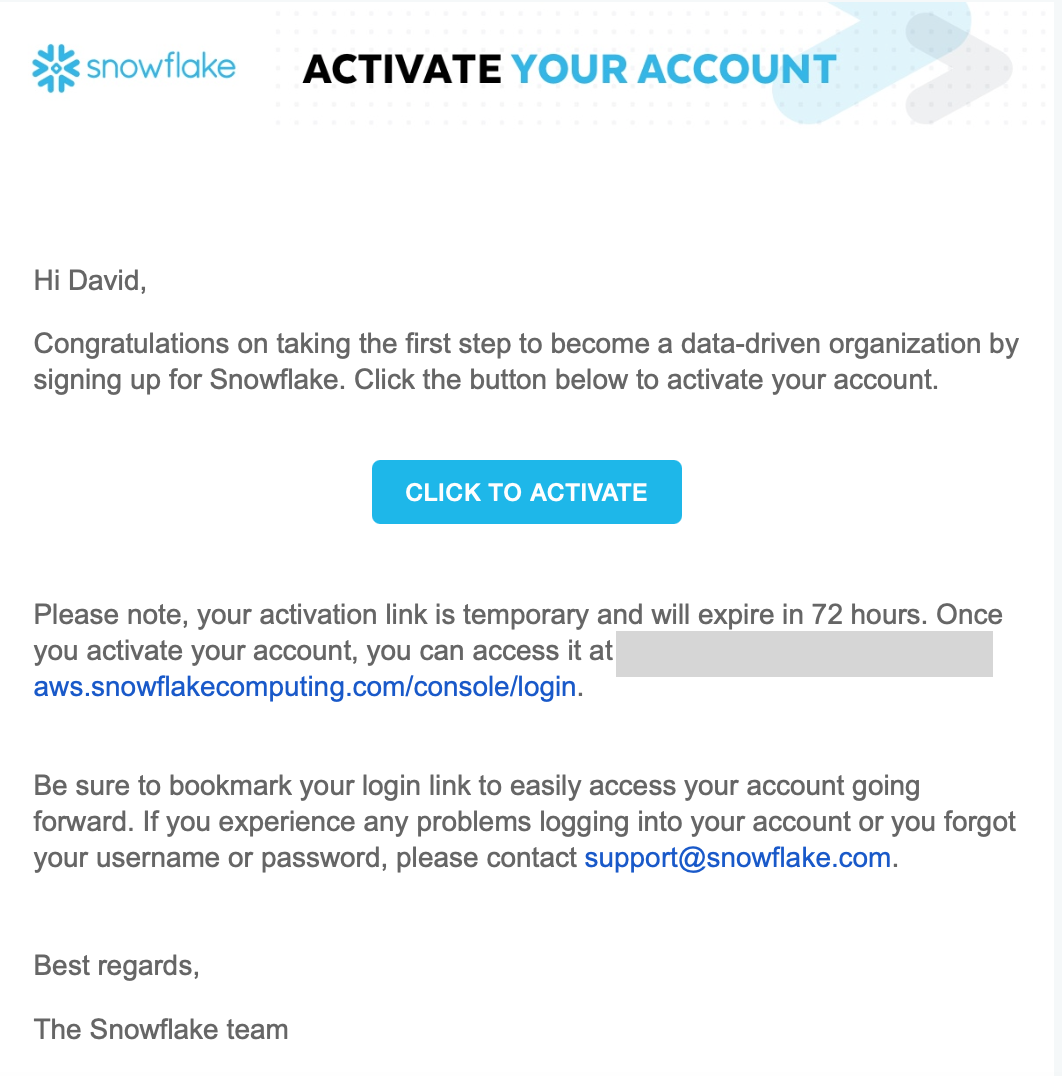
- Your account will provision in 1-2 minutes and you will receive an email activation link like this to create a user. Click on the CLICK TO ACTIVATE link.
- Next, you'll see this page your browser. Specify your username and password. Be sure to store your credentials in a safe location.
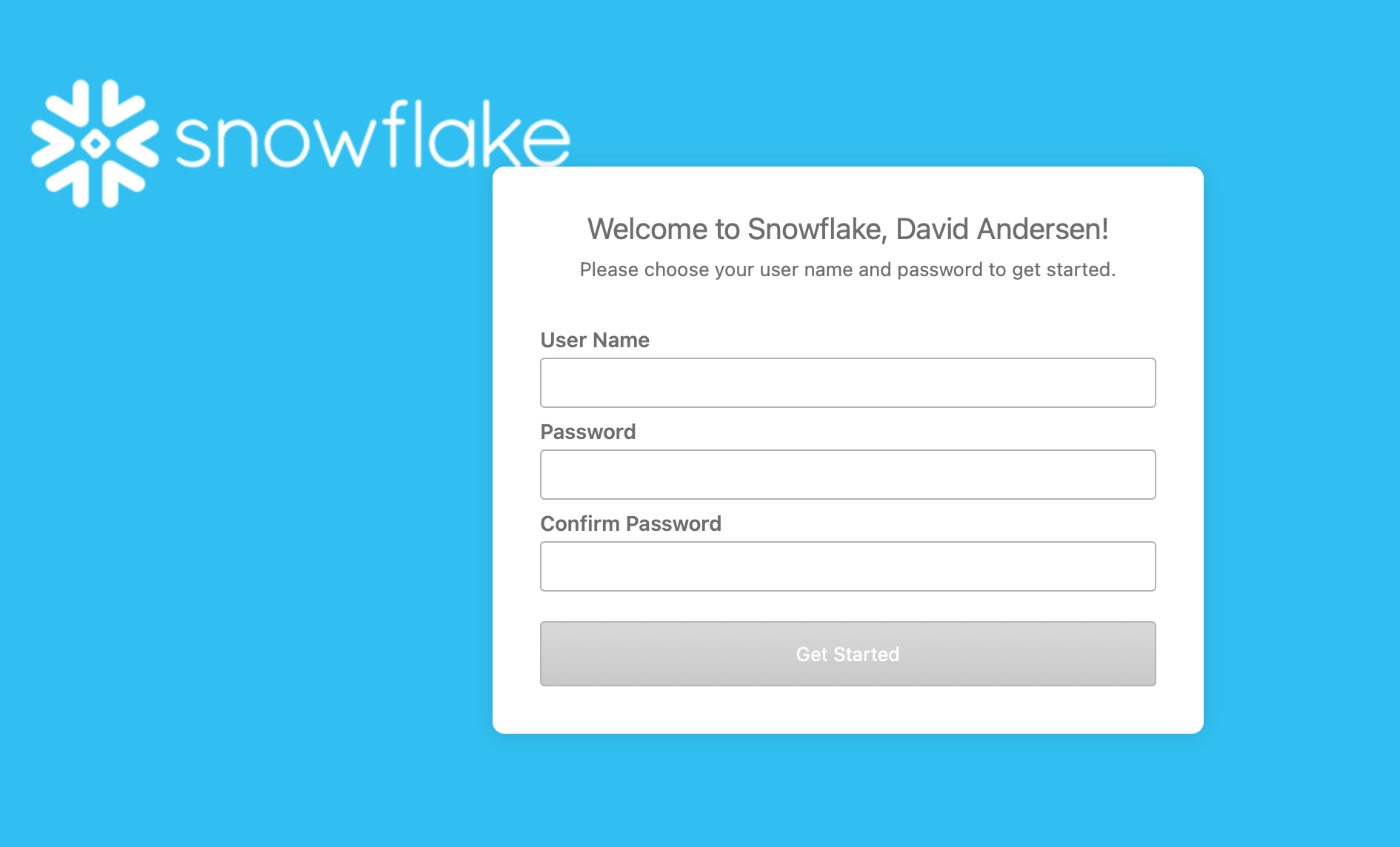
- You will be logged in to your new account and it will look like this. You will also receive another email with your username and account URL.
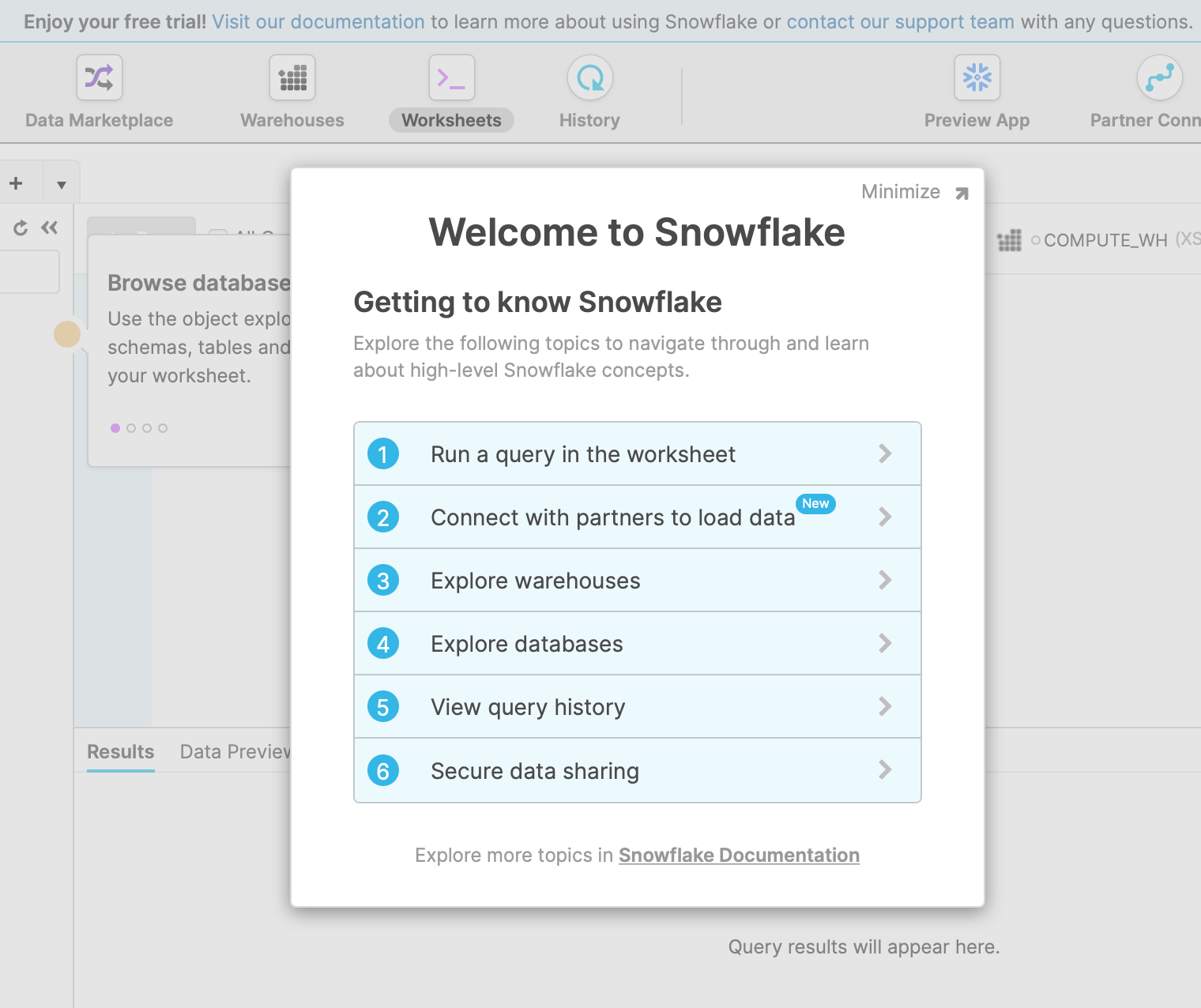
Congratulations, you are ready to work in Snowflake!
Log into Fivetran and you should see the following screen, which shows our selection of source connectors. Use the type-down or the drop-down menu to find the Google Ads connector. If you have already setup your first connector, you may need to go to the Connectors tab in the Fivetran web application, and choose + Connector.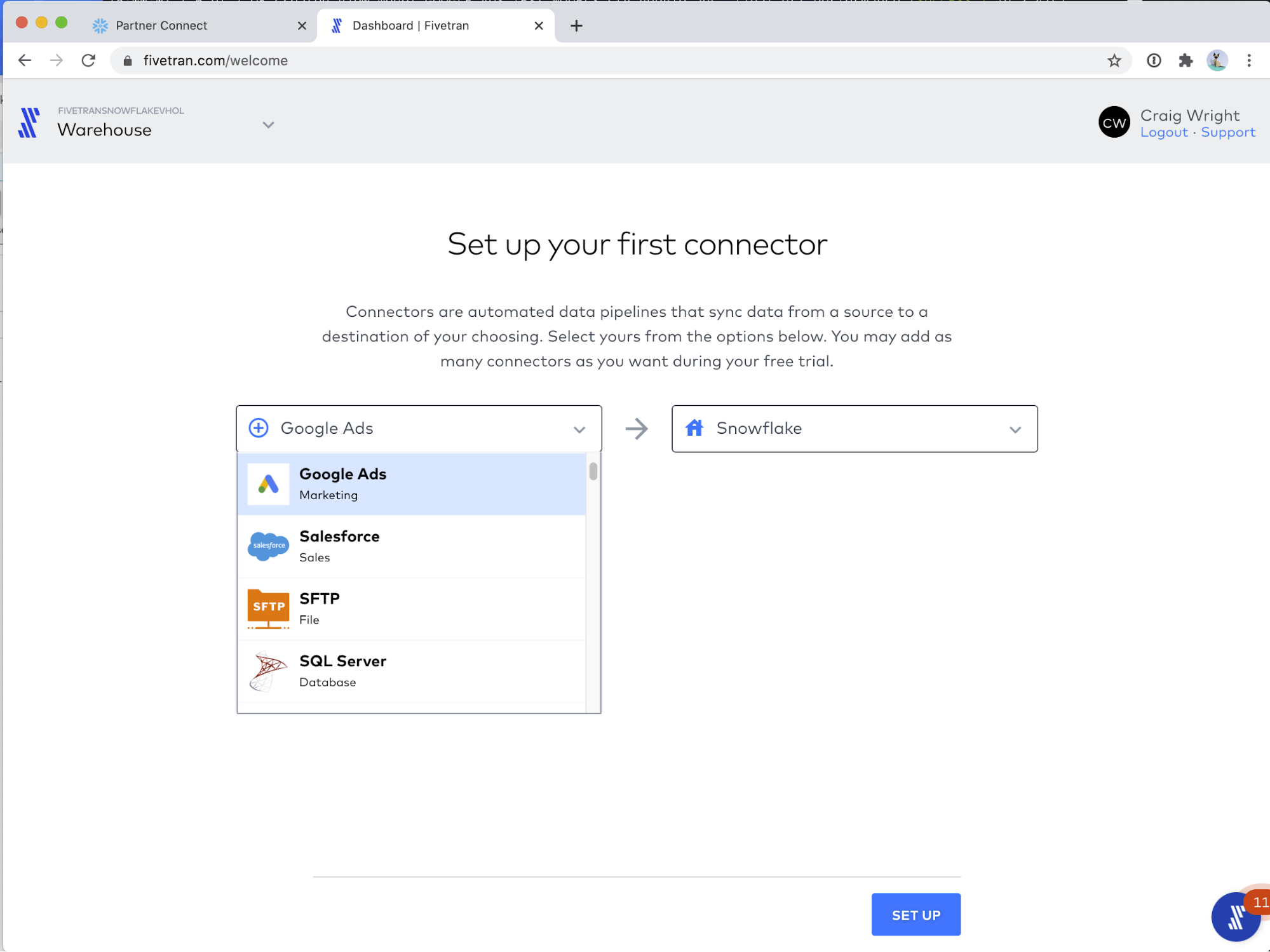
The Fivetran Google Ads connector setup screen is shown below, before we begin to modify it. On the left are the configuration controls. On the right are inline, helpful setup instructions.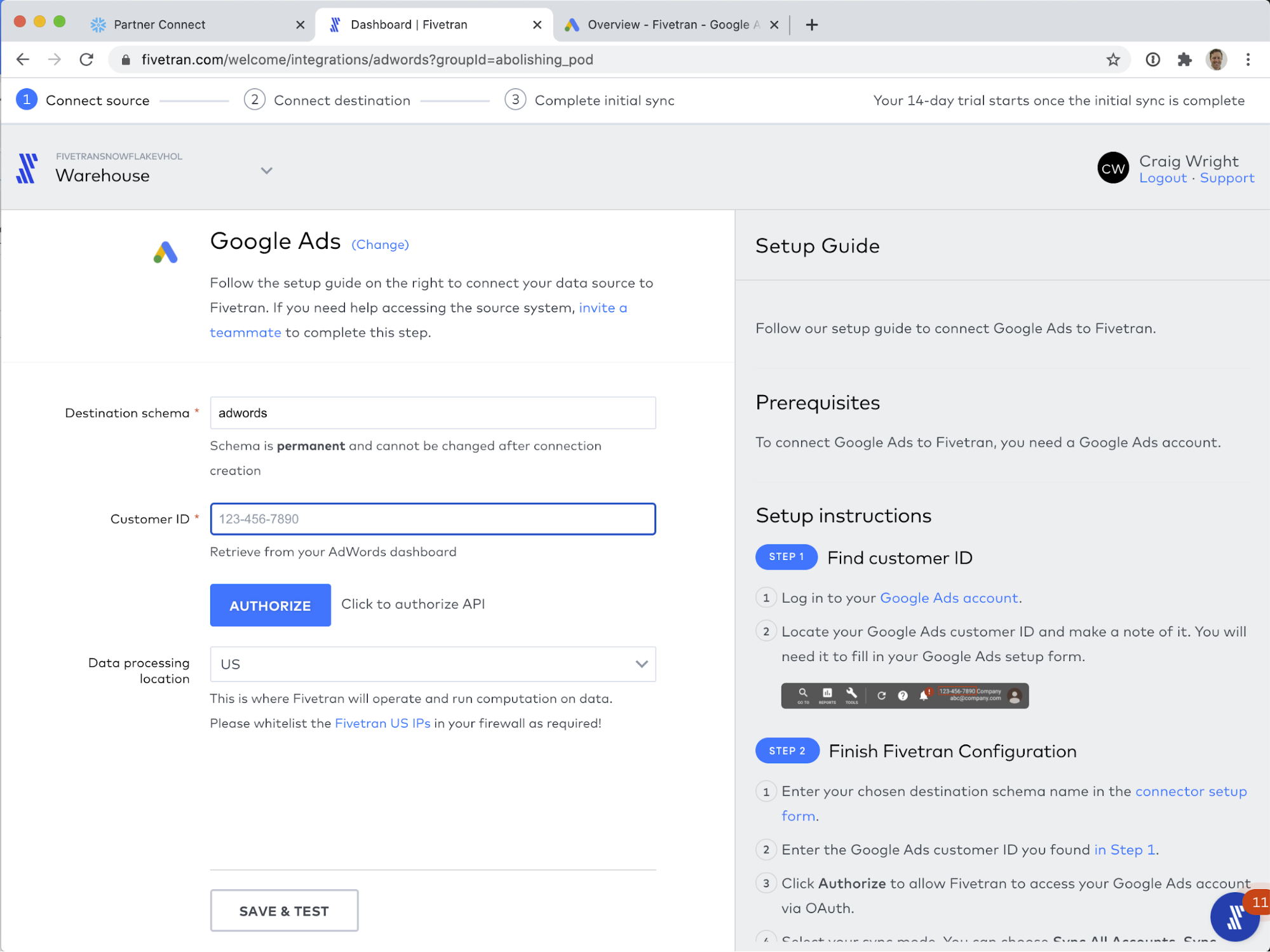
Obtain your customer ID per the instructions on the right.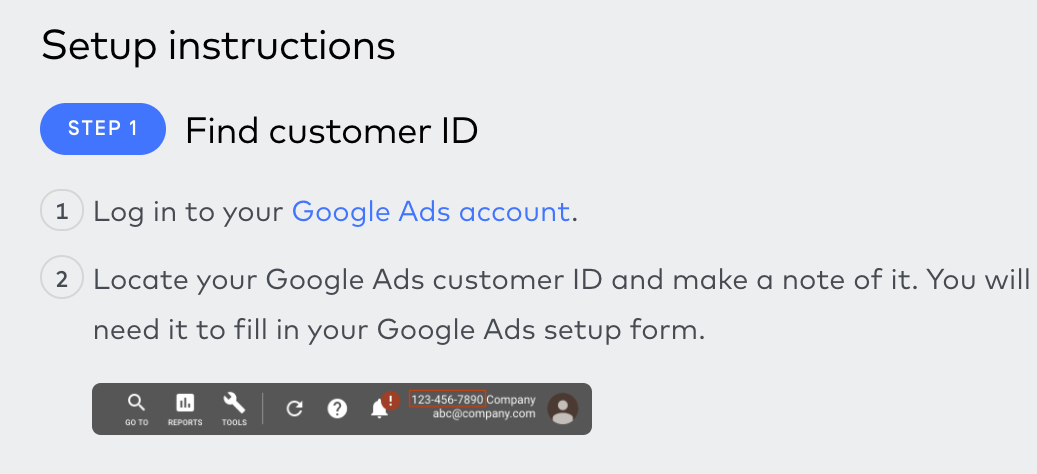
And enter it in the field on the left. Click AUTHORIZE to sign in to Google.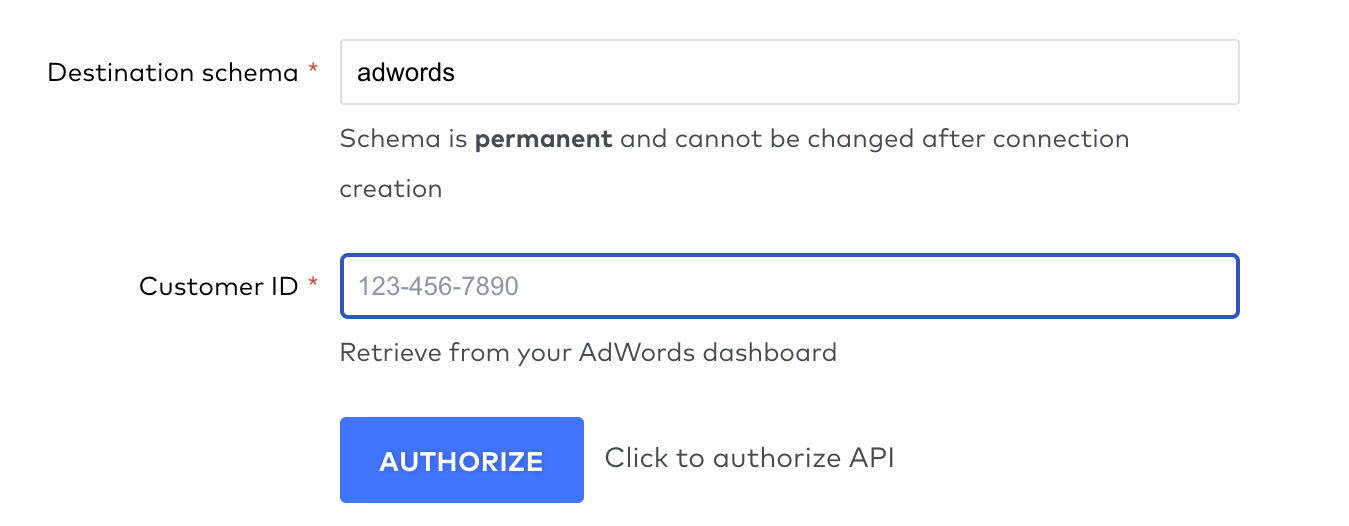
Choose the account with which you wish to authenticate.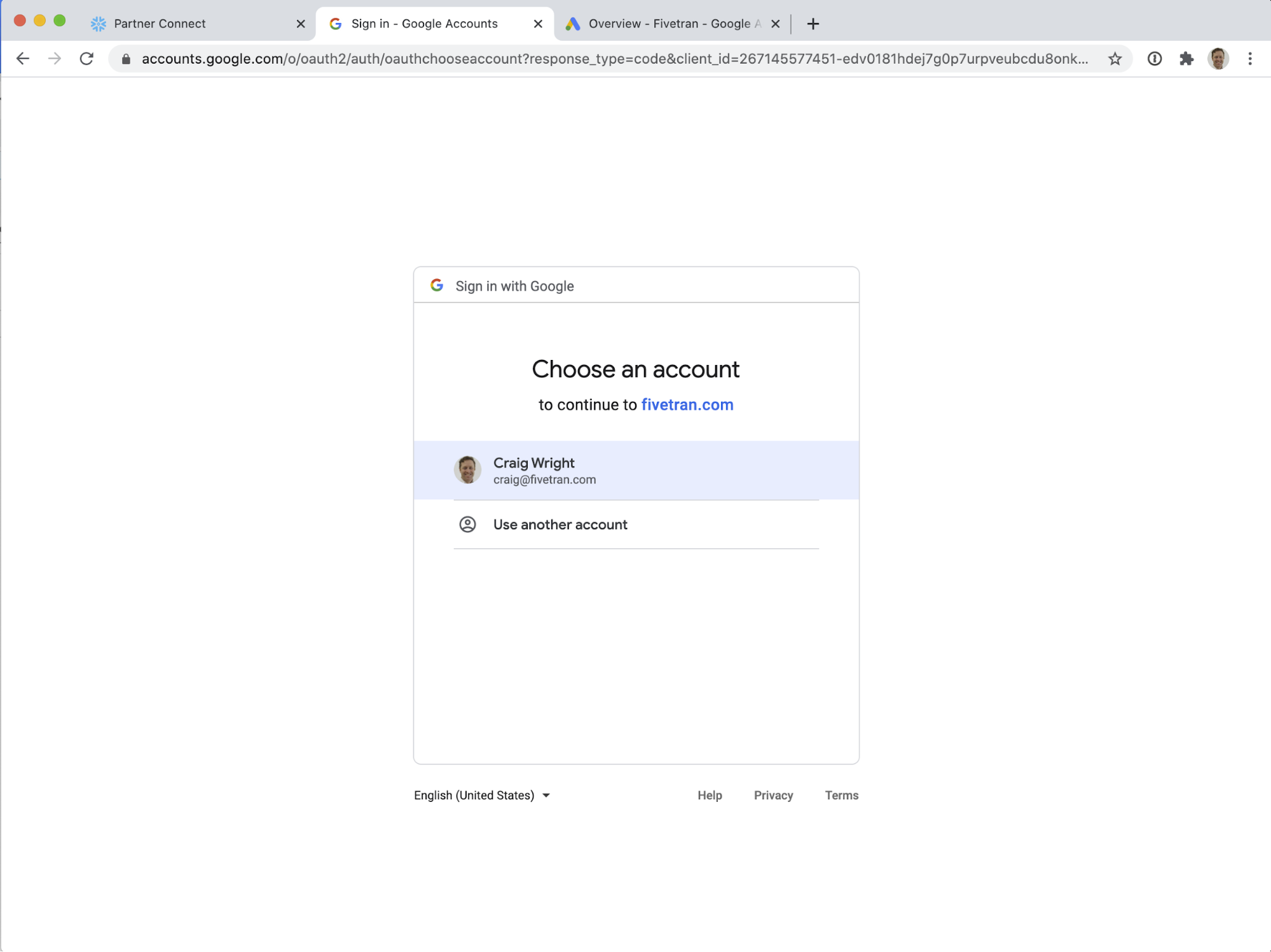
Authorize Fivetran to access your Google Ads data by clicking Allow.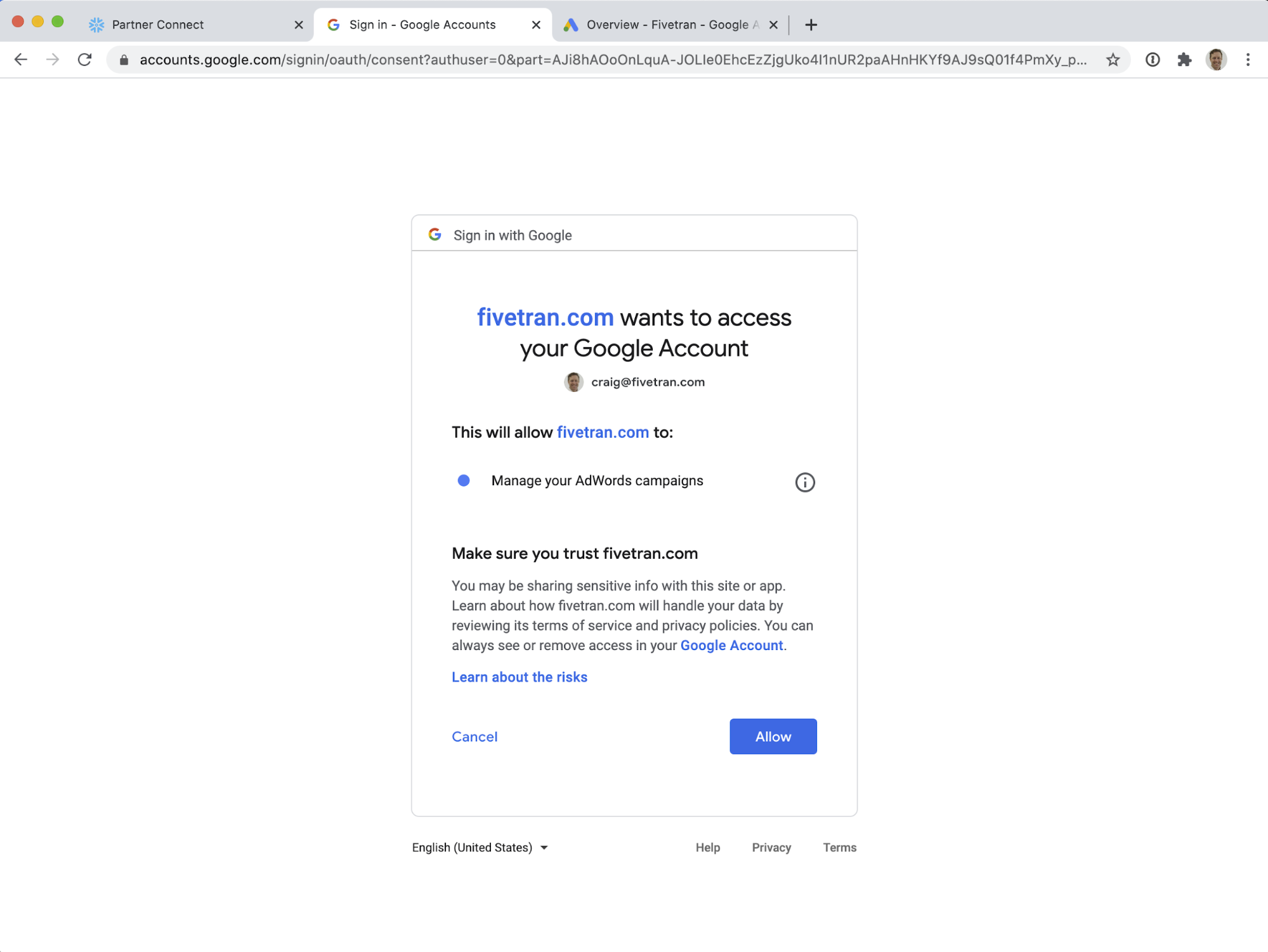
Now we need to configure three reports. These three reports will give us the raw data that we will use to generate our models later. Each report will require:
- A Destination Table Name
- A Report Type
- A selection of Fields
For each report, we will use Configuration Type: Use Custom Report.
You can find the configuration requirements for these three reports in the documentation of the Fivetran dbt package for Google Ads we will be using later, dbt_google_ads_source. You can always find a list of all of Fivetranour available packages on dbt Hub and in our documentation.
Ads connectors, also known as Marketing connectors, are different from most other Fivetran connectors in that, rather than replicate a set schema, you configure a series of reports. Each report becomes a table in the destination schema. This is necessary as the raw data that is returned from Ads connectors changes depending on the Fields chosen in the report. After the Hands-on Lab, you can always return to the connector setup and add more reports.
For the first report, use the following configuration:
- Destination Table Name: final_url_performance
- Report Type: FINAL_URL_REPORT
- Fields:
- AccountDescriptiveName
- AdGroupId
- AdGroupName
- AdGroupStatus
- CampaignId
- CampaignName
- CampaignStatus
- Clicks
- Cost
- Date
- EffectiveFinalUrl
- ExternalCustomerId
- Impressions
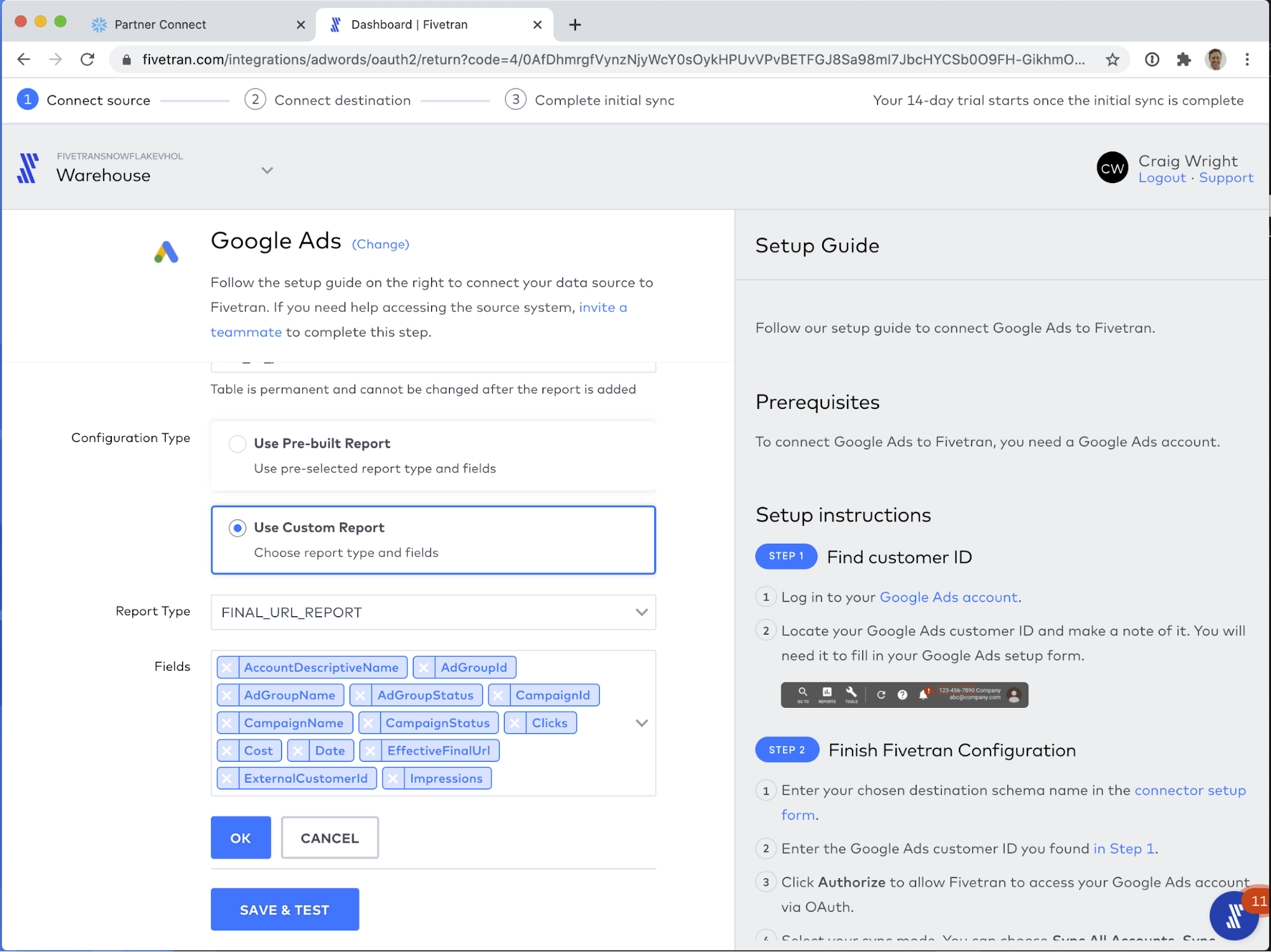
For the second report, use the following configuration:
- Destination Table Name: criteria_performance
- Report Type: CRITERIA_PERFORMANCE_REPORT
- Fields:
- AccountDescriptiveName
- AdGroupId
- AdGroupName
- AdGroupStatus
- CampaignId
- CampaignName
- CampaignStatus
- Clicks
- Cost
- Criteria
- CriteriaDestinationUrl
- CriteriaType
- Date
- ExternalCustomerId
- Id
- Impressions
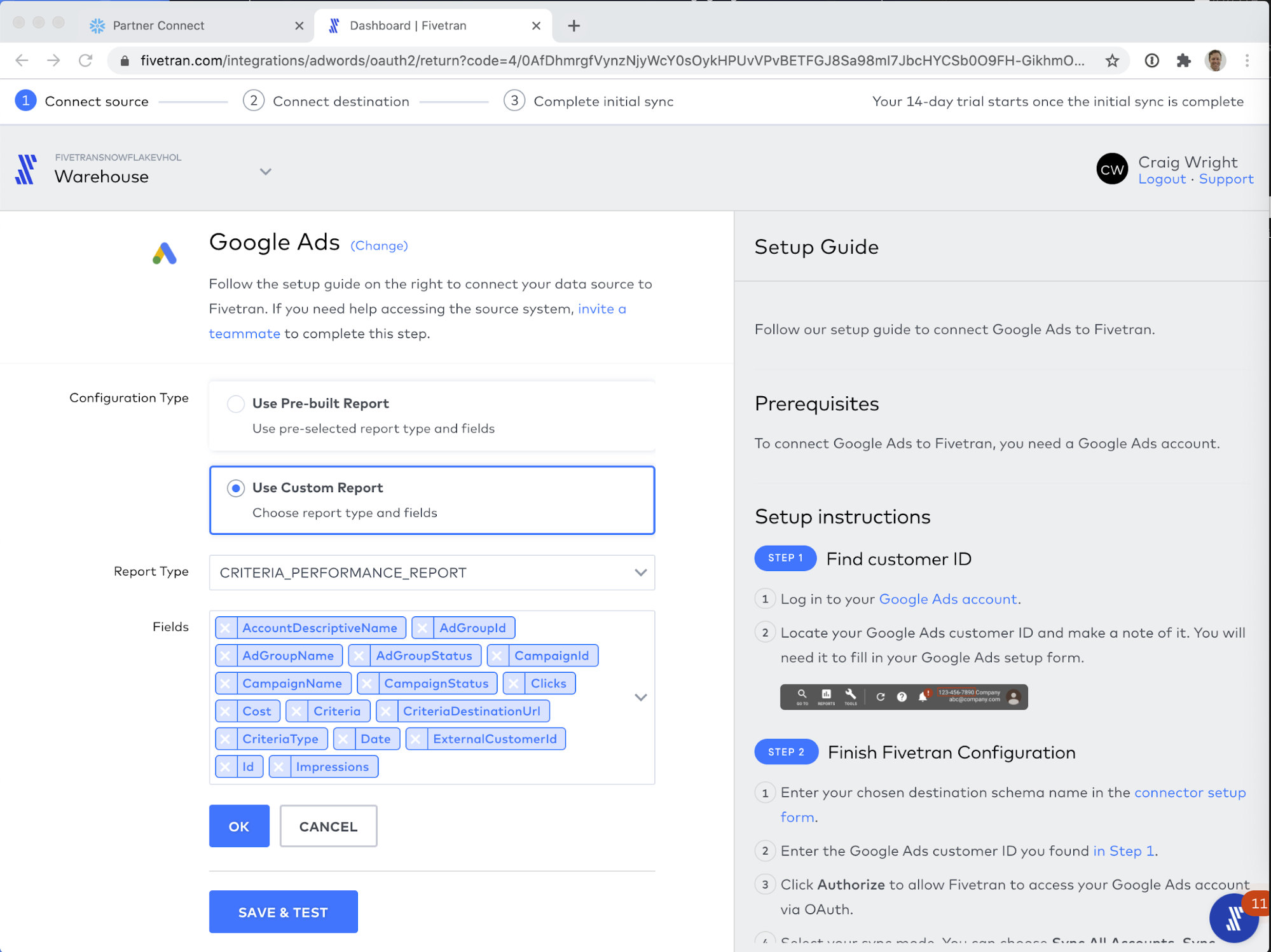
For the third report, use the following configuration:
- Destination Table Name: click_performance
- Report Type: CLICK_PERFORMANCE_REPORT
- Fields:
- AccountDescriptiveName
- AdGroupId
- AdGroupName
- AdGroupStatus
- CampaignId
- CampaignName
- CampaignStatus
- Clicks
- CriteriaId
- Date
- ExternalCustomerId
- GclId
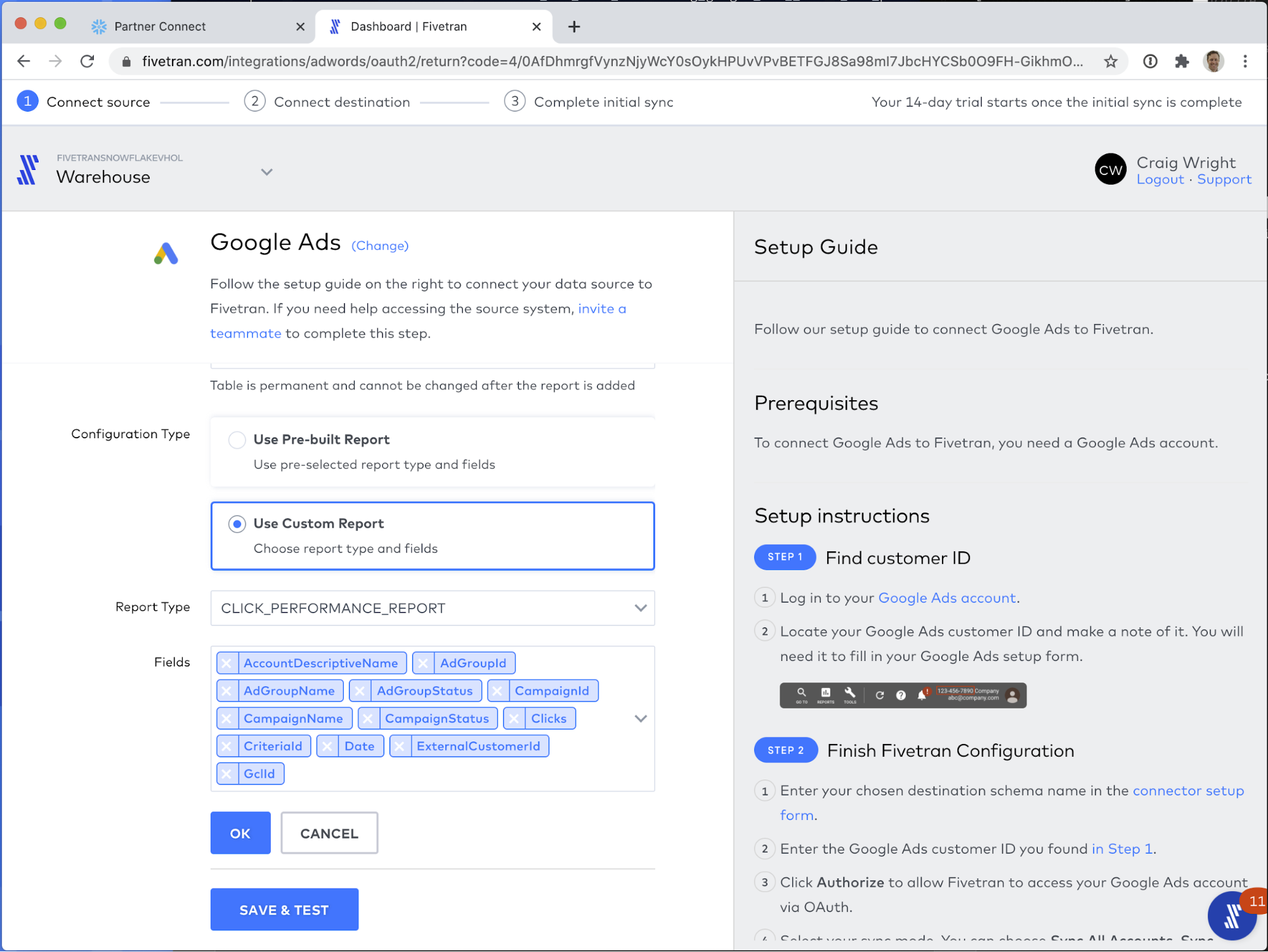
That's it for setting up reports! To review, your connector configuration screen should look like the screen shot below: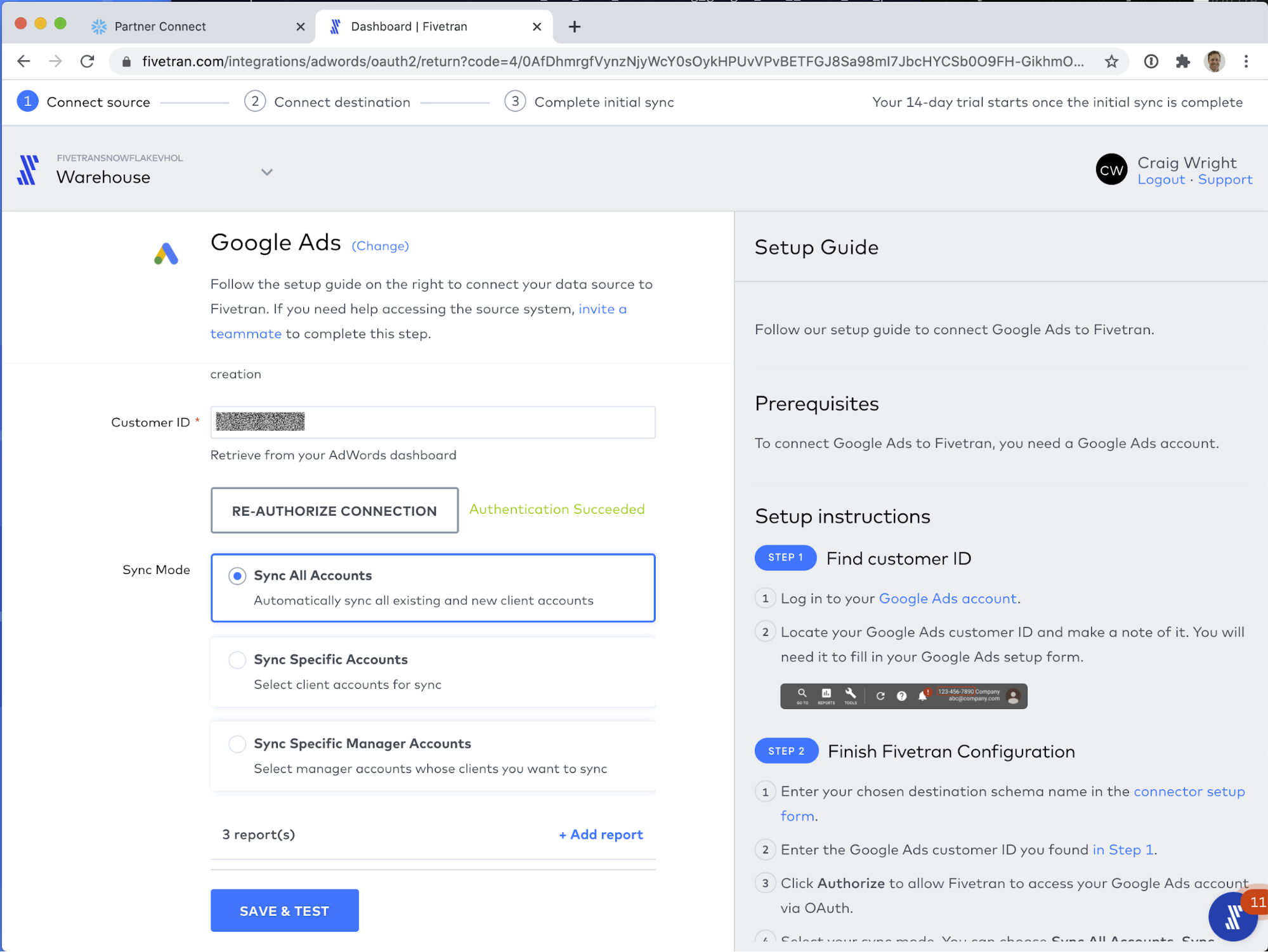
Great! Now click SAVE & TEST to save your configuration.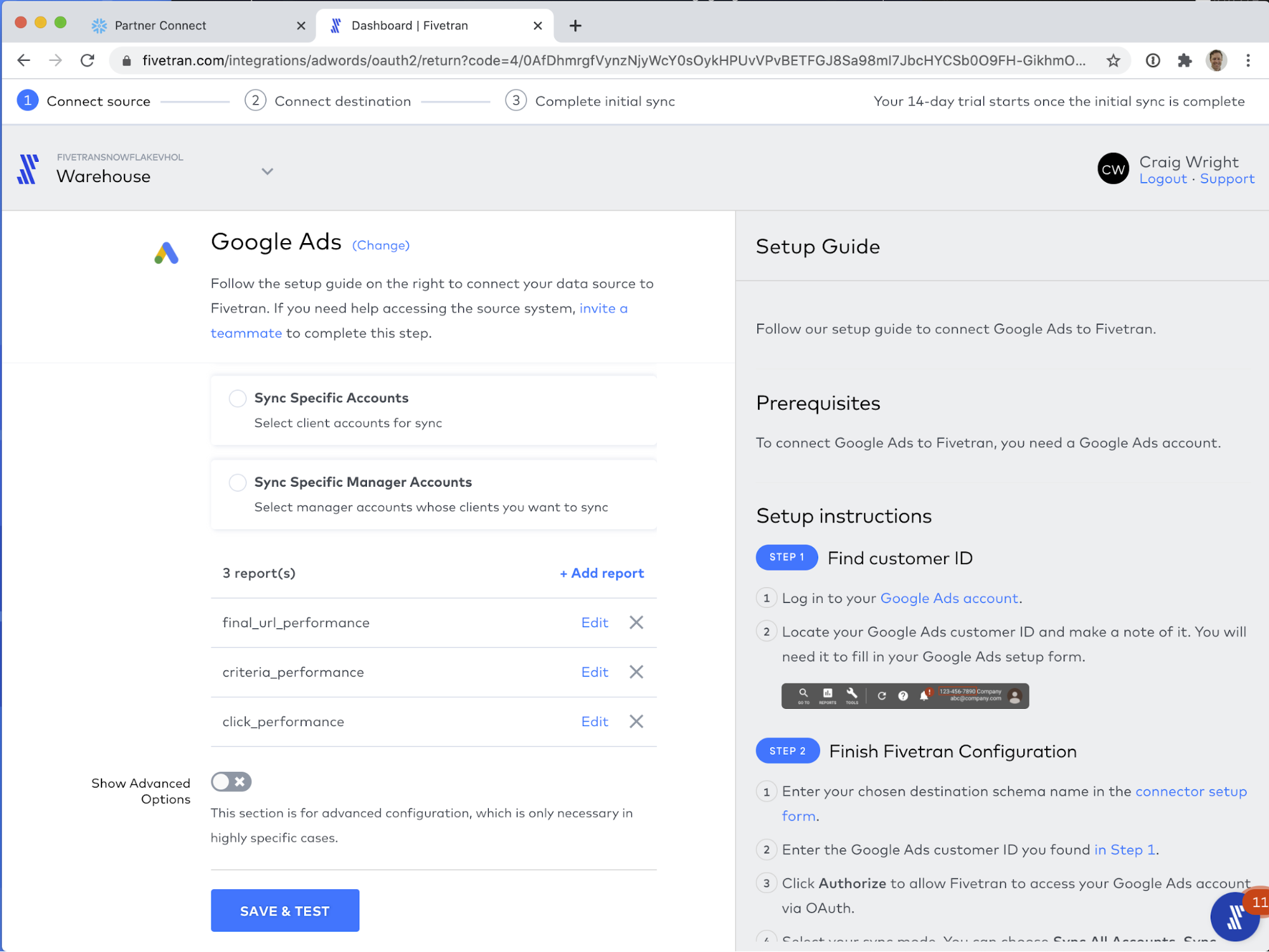
Click CONTINUE to see the next screen, where you can Start Initial Sync to start the data flowing!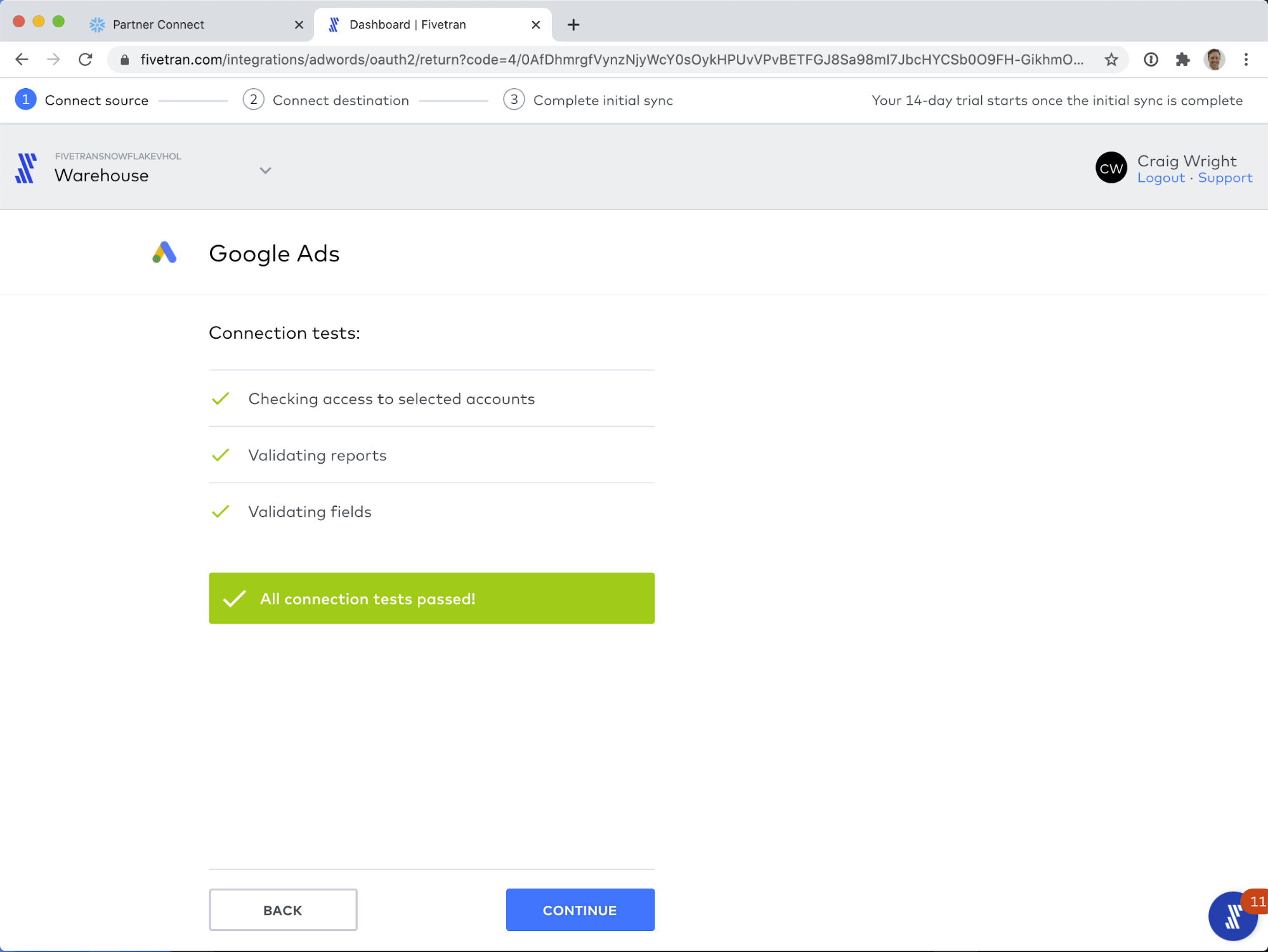
Fivetran does more than just sync Ad connector reports. Fivetran has over 170 source connectors that you can use to keep your data in sync in Snowflake. With Fivetran's Database (e.g.,x. Oracle, PostgreSQL) and Application (e.g., ex Salesforce, Marketo, NetSuite) connectors, your data is automatically kept up-to-date without any intervention on your part. Any schema changes to your source data are automatically updated in Snowflake with our Automatic Schema Migration technology. Never miss or lose data, and never worry about updating your data pipelines again.
Moreover, Fivetran keeps your data up-to-date on your schedule, with recurring syncs on the timetable you specify. Keep reading for more information.
Before we start the first sync, let's take a look at the configuration Fivetran provides for connectors. 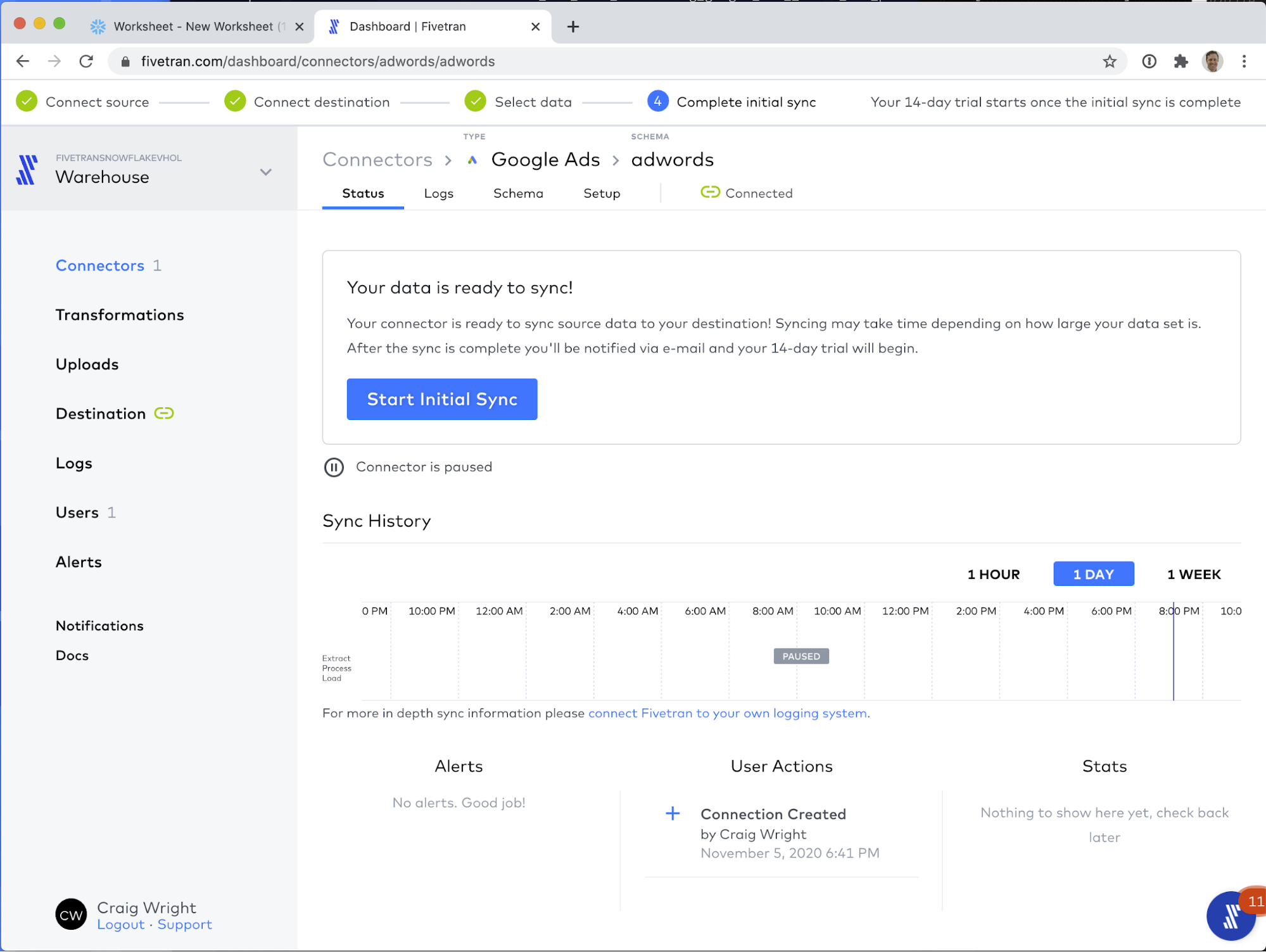
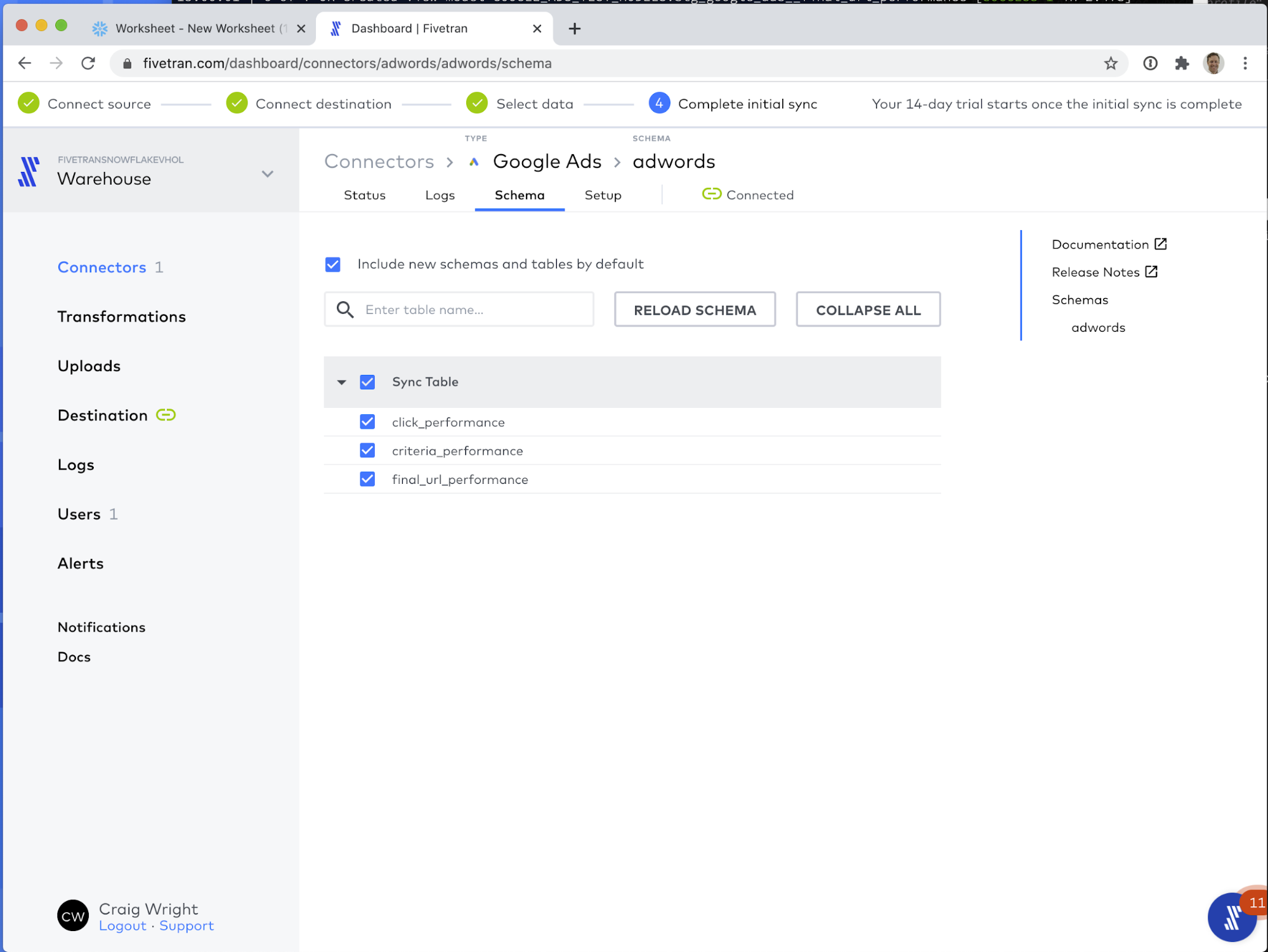
First let's look at the Schema tab. Here, depending on the connector type, you can configure up to three settings:
- Block a table from syncing to Snowflake.
- Block a column from syncing to Snowflake.
- Hash a column's values before they are stored in Snowflake.
- Used to protect Personally Identifiable Information from being accessed by the users of the data, while maintaining the ability to SQL JOIN on those values.
- Used to protect Personally Identifiable Information from being accessed by the users of the data, while maintaining the ability to SQL JOIN on those values.
With Ads connectors, you can enable or disable a particular report from syncing.
Next let's visit the Setup tab. There is one very important configuration tool here, and that is the Sync Frequency. This can be set to as frequently as every 5 minutes, to as infrequently as every 24 hours. Fivetran starts and stops the Snowflake warehouse used for data loading on demand, and is extremely efficient at data loading, so you only pay for the time Fivetran is actually loading data.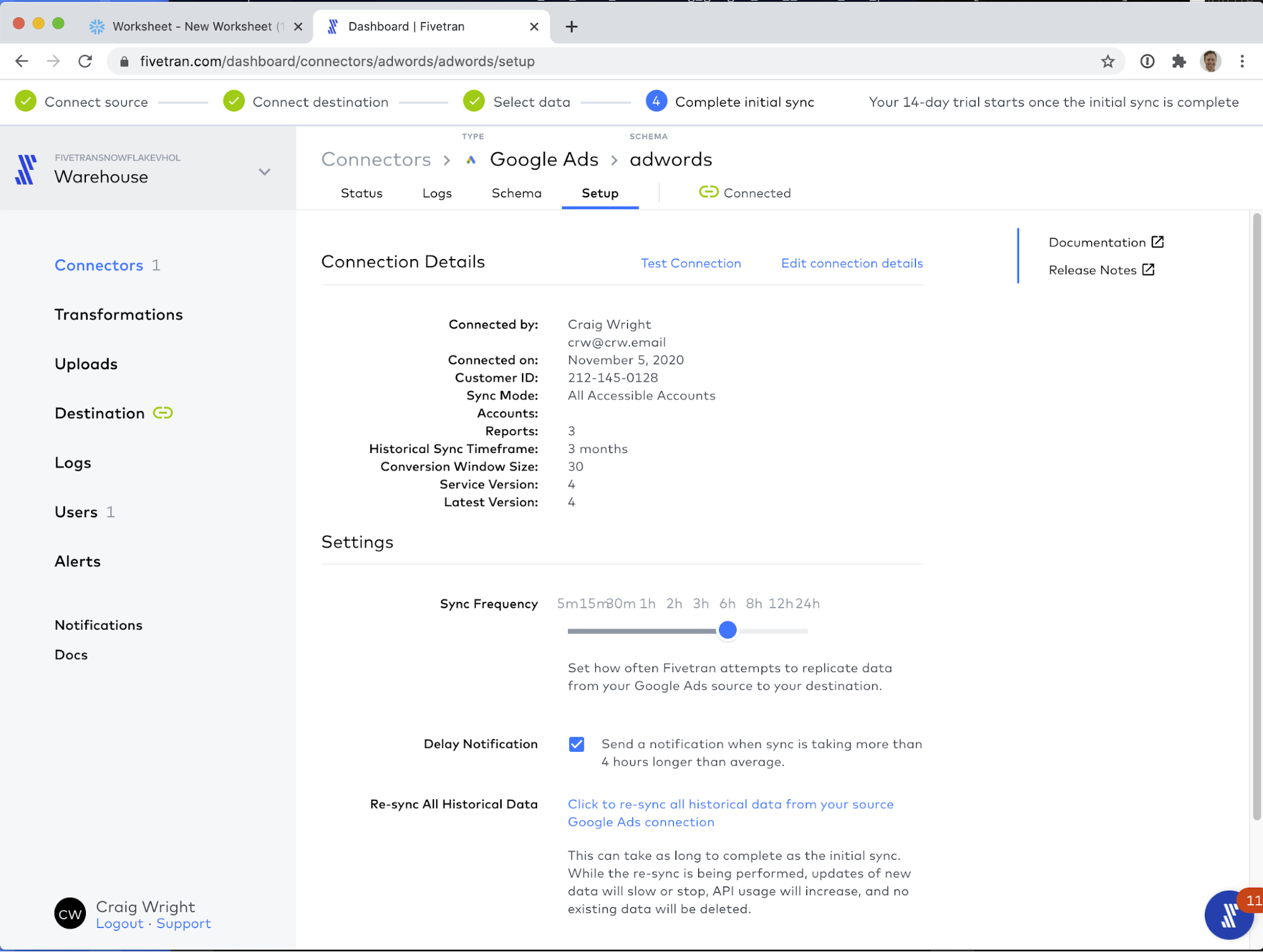
OK! That is it! The Schema setup in the Schema tab, and the Sync Frequency setting in the Setup tab are the only configuration details you need to manage, and even those can be left on the defaults for flawless operation! With that visited, let's go back to the Status tab and start the sync!
Once the Start Initial Sync button is clicked, you should see your sync start up.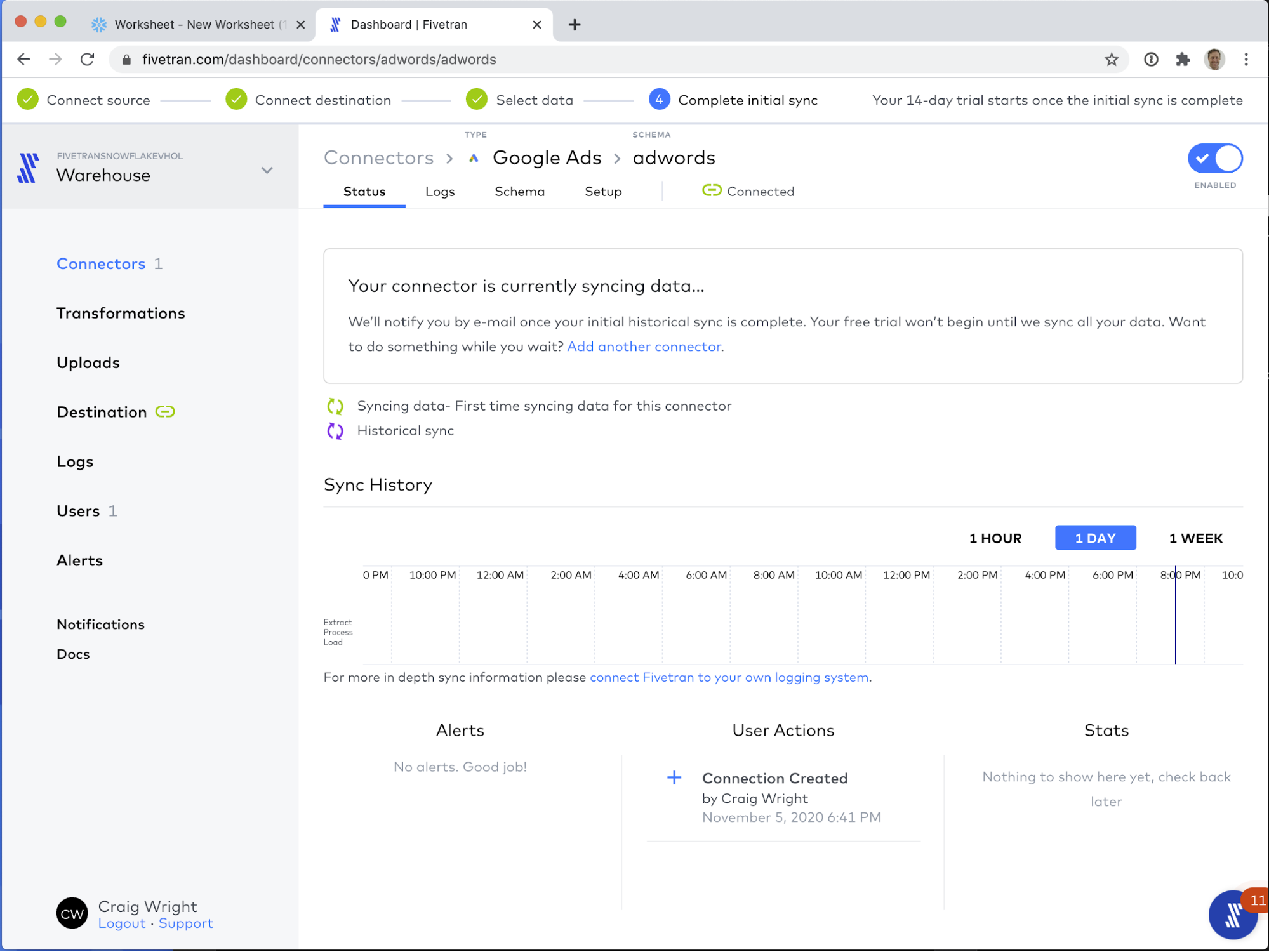
While the sync is running, we can take a quick detour into the Logs tab. This is a real-time view into the data loading process. Fivetran offers ways to export these logs into your preferred log aggregation service. We even have a free connector called the Fivetran Log connector, that exports log data, schema operation metadata, and Fivetran credit consumption data!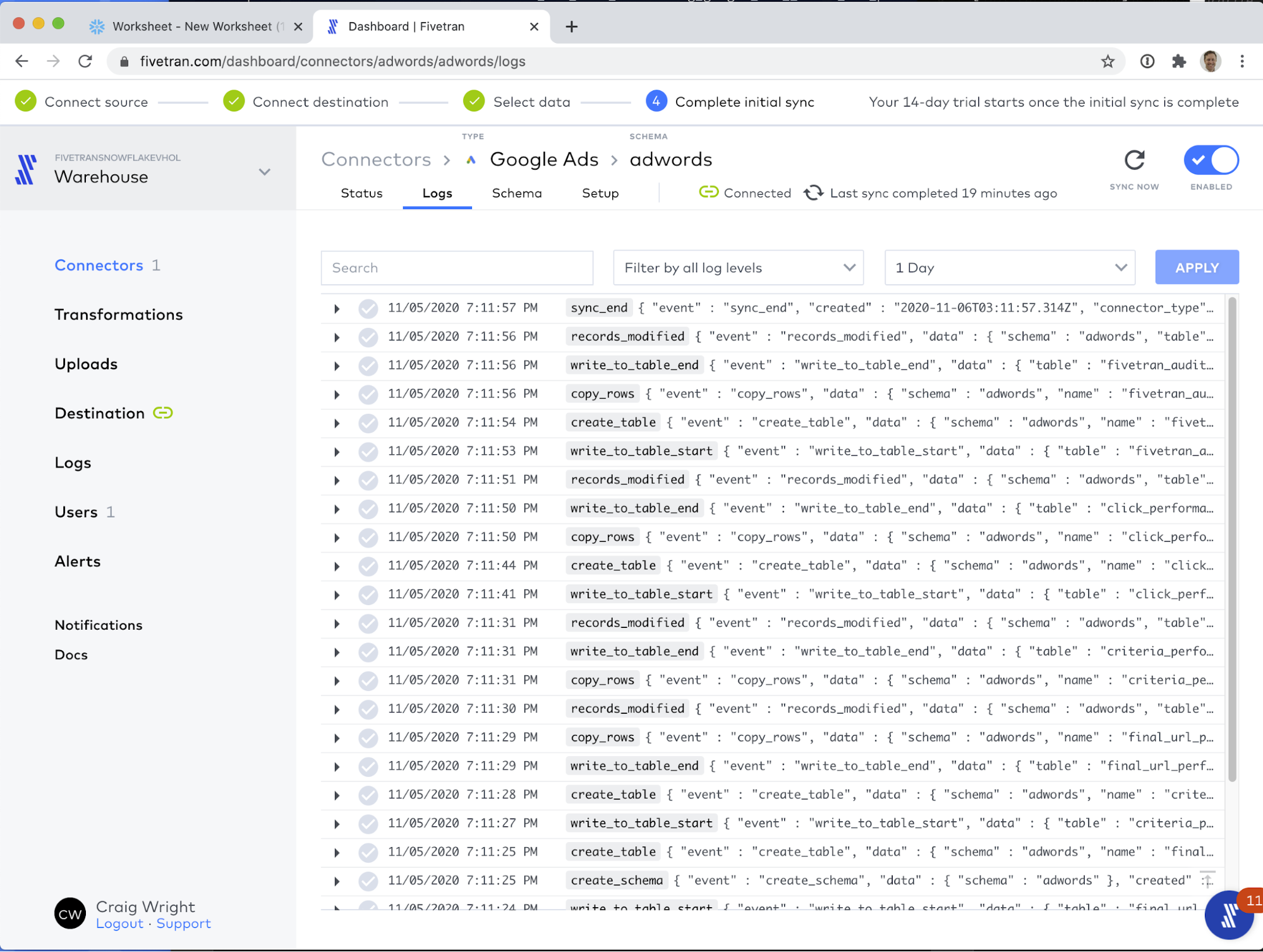
For this demo, I chose to only sync 3 months of historical data, so the initial sync finished relatively quickly at two and a half minutes. When your sync has completed, you will see its status on the timeline, as per below.