이 리소스 최적화 가이드는 해당 시리즈에 포함되어 있는 4개의 모듈 중 하나를 나타냅니다. 이러한 가이드는 고객이 자신의 크레딧 소비를 더 잘 모니터링하고 관리할 수 있도록 돕는 것을 목적으로 합니다. 고객이 자신의 크레딧이 효율적으로 사용되고 있다는 것을 자신할 수 있도록 돕는 것은 지속적이며 성공적인 파트너십에 중요합니다. 이 리소스 최적화를 위한 Snowflake 빠른 시작 세트와 더불어 Snowflake는 커뮤니티 지원, 교육 및 프로페셔널 서비스를 제공합니다. 유료 서비스에 대한 자세한 내용은 다가오는 훈련 및 교육에서 확인하십시오.
이 블로그 포스트는 여러분이 Snowflake의 리소스 최적화 기능을 더 잘 이해할 수 있도록 합니다.
marketing@snowflake.com으로 Snowflake 팀에 문의하십시오. Snowflake는 여러분의 피드백을 소중하게 여깁니다.
사용량 모니터링
사용량 모니터링 쿼리는 지정된 기간 동안 가장 많은 크레딧을 소비하는 웨어하우스, 쿼리, 도구 및 사용자를 식별하기 위해 설계되었습니다. 이러한 쿼리는 예측했던 것보다 더 많은 크레딧을 소비하는 리소스가 무엇인지를 결정하고 소비를 줄이는 데 필요한 조치를 취하는 데 사용할 수 있습니다.
학습할 내용
- 소비 동향 및 패턴 분석 방법
- 소비 변칙 확인 방법
- 파트너 도구 소비 메트릭 분석 방법
필요한 것
- Snowflake 계정
- 계정 사용량 데이터 공유를 보기 위한 액세스
관련 자료
- 리소스 최적화: 설정 및 구성
- 리소스 최적화: 청구 메트릭
- 리소스 최적화: 성능
리소스 최적화 Snowflake 빠른 시작 내에 있는 각 쿼리 이름의 오른쪽에는 ‘(T*)'로 Tier 지정이 있습니다. 다음 Tier 설명은 이러한 지정을 더 잘 이해하는 데 도움이 됩니다.
Tier 1 쿼리
본질적으로 Tier 1 쿼리는 Snowflake의 리소스 최적화에 매우 중요합니다. 또한 각 고객이 규모, 업계, 위치 등에 관계없이 자신의 소비 모니터링에 대해 도움을 받기 위해 사용해야 합니다.
Tier 2 쿼리
Tier 2 쿼리는 리소스 최적화에 대한 추가적인 깊이를 제공하는 동시에 프로세스에서 중요한 역할을 수행합니다. 또한 모든 고객과 고객의 워크로드에 필수적이지는 않을지라도 과도한 소비가 확인되었을 수 있는 모든 추가 영역에 대한 추가적인 설명을 제공할 수 있습니다.
Tier 3 쿼리
마지막으로 Tier 3 쿼리는 Snowflake 소비를 최적화하는 데 있어서 모든 부분을 확인하고자 하는 고객이 사용할 수 있도록 설계되었습니다. 이러한 쿼리는 이 프로세스에서 여전히 매우 유용하지만 Tier 1 및 2의 쿼리만큼 중요하지는 않습니다.
Tier 1
설명:
지정된 기간 동안 각 웨어하우스의 총 크레딧 소비를 보여줍니다.
결과 해석 방법:
다른 웨어하우스보다 더 많은 크레딧을 소비하는 특정 웨어하우스가 있나요? 있어야 하나요? 해당 웨어하우스를 대상으로 예측한 것보다 더 많은 크레딧을 소비하는 특정 웨어하우스가 있나요?
주요 스키마:
Account_Usage
SQL
// Credits used (all time = past year)
SELECT WAREHOUSE_NAME
,SUM(CREDITS_USED_COMPUTE) AS CREDITS_USED_COMPUTE_SUM
FROM ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
GROUP BY 1
ORDER BY 2 DESC
;
// Credits used (past N days/weeks/months)
SELECT WAREHOUSE_NAME
,SUM(CREDITS_USED_COMPUTE) AS CREDITS_USED_COMPUTE_SUM
FROM ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
WHERE START_TIME >= DATEADD(DAY, -7, CURRENT_TIMESTAMP()) // Past 7 days
GROUP BY 1
ORDER BY 2 DESC
;
스크린샷
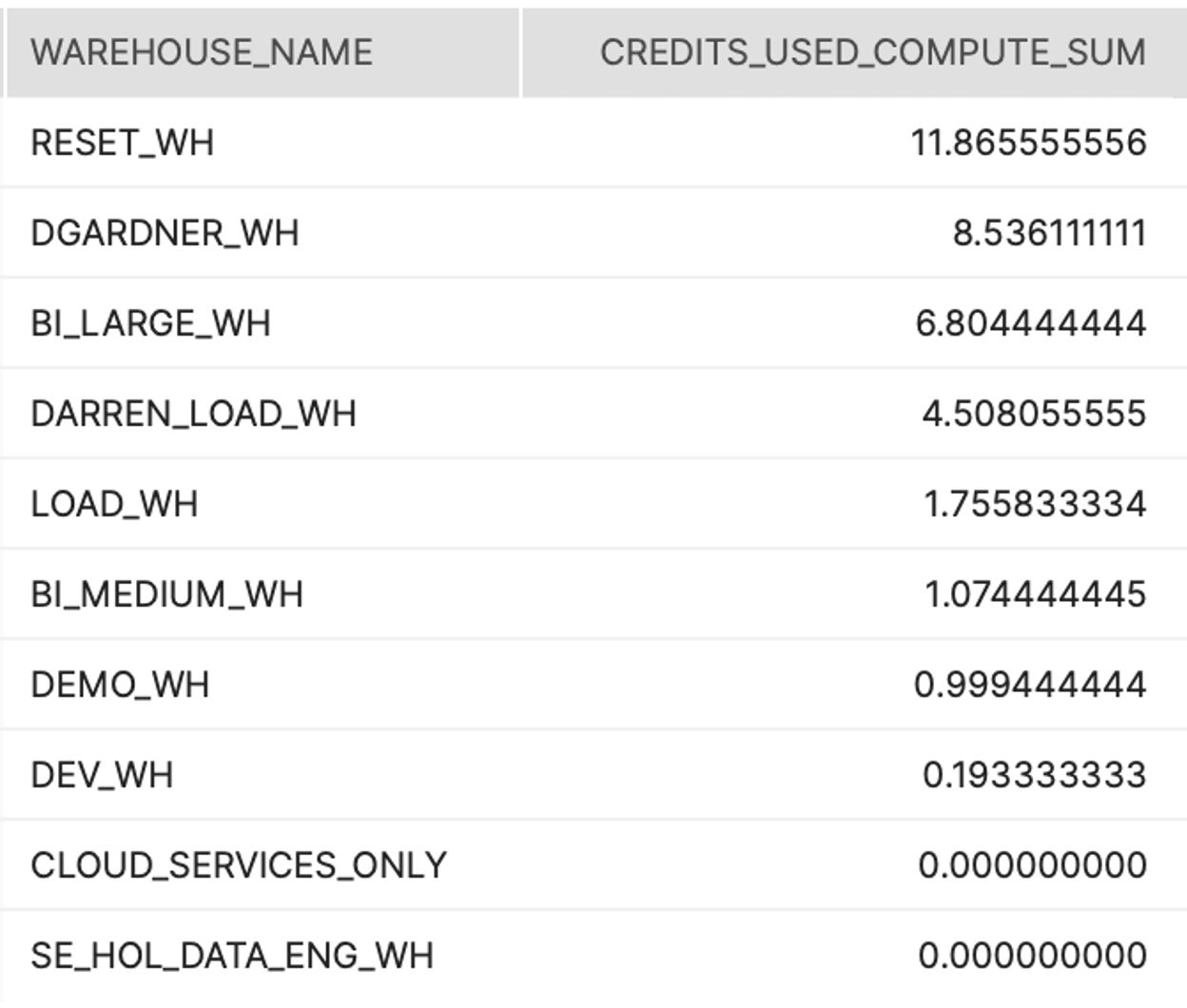
Tier 1
설명:
지난 7일간의 소비 동향(가장 많은 때, 가장 낮을 때)을 더 잘 이해할 수 있도록 시간별로 총 크레딧 소비를 보여줍니다.
결과 해석 방법:
하루 중 어떤 시간에 소비가 급증하나요? 예측한 대로인가요?
주요 스키마:
Account_Usage
SQL(시간, 웨어하우스별)
// Credits used by [hour, warehouse] (past 7 days)
SELECT START_TIME
,WAREHOUSE_NAME
,CREDITS_USED_COMPUTE
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
WHERE START_TIME >= DATEADD(DAY, -7, CURRENT_TIMESTAMP())
AND WAREHOUSE_ID > 0 // Skip pseudo-VWs such as "CLOUD_SERVICES_ONLY"
ORDER BY 1 DESC,2
;
스크린샷
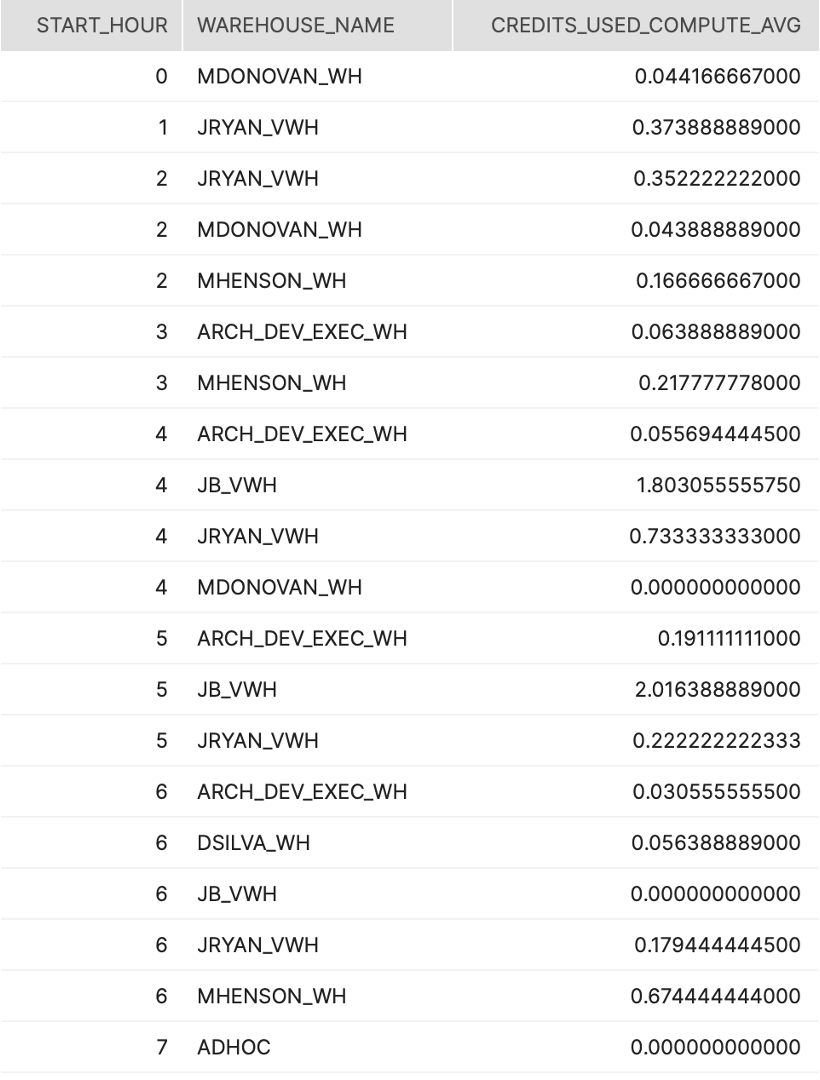
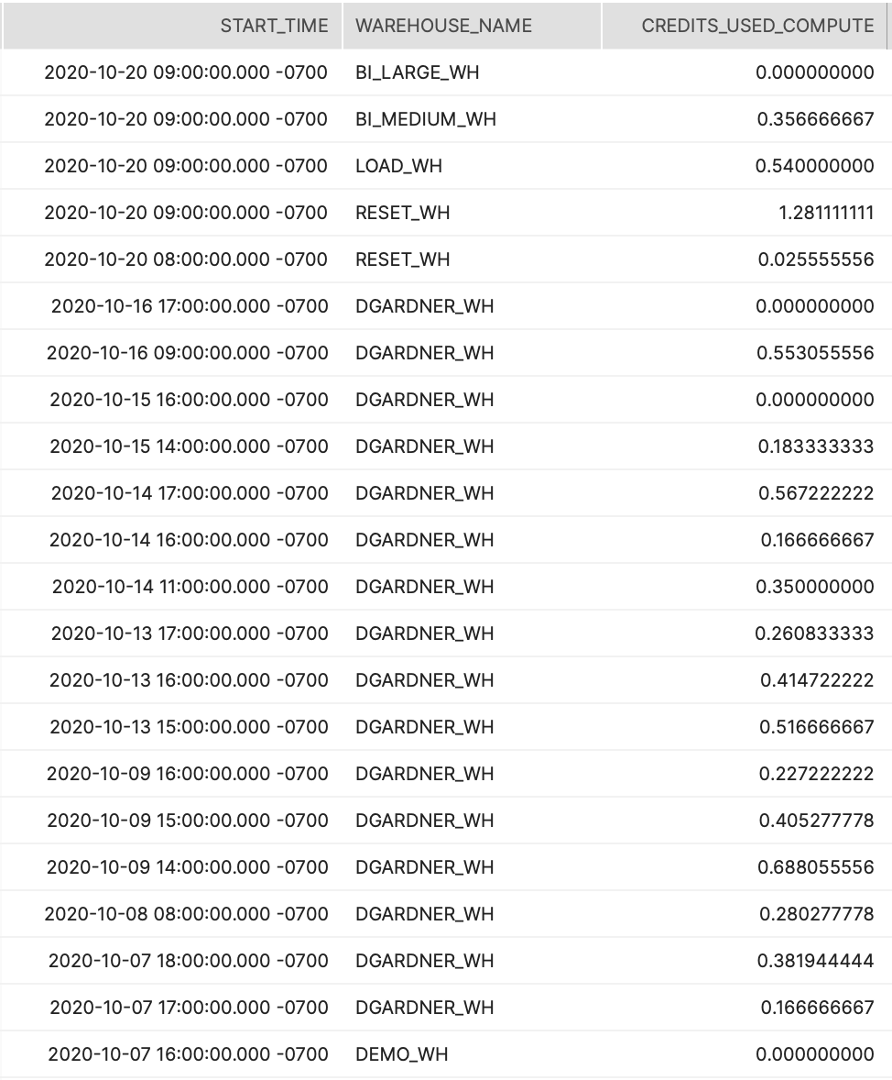 ####SQL(시간)
####SQL(시간)
SELECT DATE_PART('HOUR', START_TIME) AS START_HOUR
,WAREHOUSE_NAME
,AVG(CREDITS_USED_COMPUTE) AS CREDITS_USED_COMPUTE_AVG
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
WHERE START_TIME >= DATEADD(DAY, -7, CURRENT_TIMESTAMP())
AND WAREHOUSE_ID > 0 // Skip pseudo-VWs such as "CLOUD_SERVICES_ONLY"
GROUP BY 1, 2
ORDER BY 1, 2
;
스크린샷
Tier 1
설명:
일반적인 쿼리 활동을 더 잘 이해하는 데 도움이 되도록 시간별로 실행되는 평균 쿼리 수를 보여줍니다.
결과 해석 방법:
시간별로 몇 개의 쿼리가 실행되나요? 예측했던 것보다 더 많거나 적은가요? 이러한 현상의 이유는 무엇일까요?
주요 스키마:
Account_Usage
SQL
SELECT DATE_TRUNC('HOUR', START_TIME) AS QUERY_START_HOUR
,WAREHOUSE_NAME
,COUNT(*) AS NUM_QUERIES
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE START_TIME >= DATEADD(DAY, -7, CURRENT_TIMESTAMP()) // Past 7 days
GROUP BY 1, 2
ORDER BY 1 DESC, 2
;
스크린샷
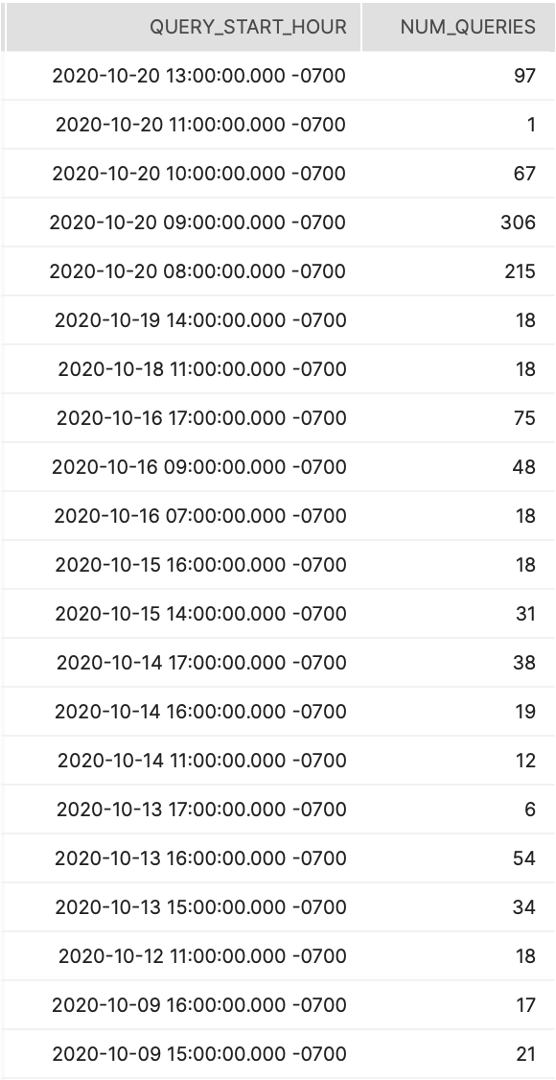
Tier 1
설명:
이 쿼리는 주 및 웨어하우스별로 그룹화된 일별 평균 크레딧 소비를 반환합니다.
결과 해석 방법:
이를 사용하여 작년 주에 걸쳐 웨어하우스의 크레딧 소비 변칙을 확인합니다.
주요 스키마:
Account_Usage
SQL
WITH CTE_DATE_WH AS(
SELECT TO_DATE(START_TIME) AS START_DATE
,WAREHOUSE_NAME
,SUM(CREDITS_USED) AS CREDITS_USED_DATE_WH
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
GROUP BY START_DATE
,WAREHOUSE_NAME
)
SELECT START_DATE
,WAREHOUSE_NAME
,CREDITS_USED_DATE_WH
,AVG(CREDITS_USED_DATE_WH) OVER (PARTITION BY WAREHOUSE_NAME ORDER BY START_DATE ROWS 7 PRECEDING) AS CREDITS_USED_7_DAY_AVG
,100.0*((CREDITS_USED_DATE_WH / CREDITS_USED_7_DAY_AVG) - 1) AS PCT_OVER_TO_7_DAY_AVERAGE
FROM CTE_DATE_WH
QUALIFY CREDITS_USED_DATE_WH > 100 // Minimum N=100 credits
AND PCT_OVER_TO_7_DAY_AVERAGE >= 0.5 // Minimum 50% increase over past 7 day average
ORDER BY PCT_OVER_TO_7_DAY_AVERAGE DESC
;
스크린샷
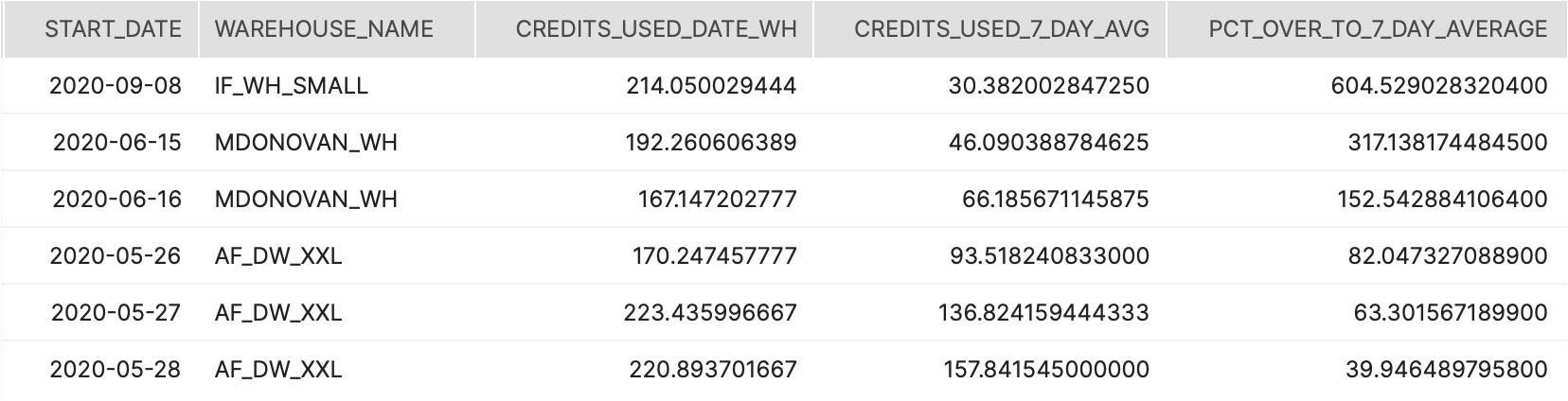
Tier 1
설명:
이 쿼리는 계약 기간 동안 일별로 3개의 다른 소비 메트릭을 제공합니다. (1) 계약된 소비는 전체 기간 동안 사용량이 일정할 경우 소비되는 금액입니다. (2) 실제 소비는 여러 사용량 뷰에서 가져오는 것이며 일별 수준으로 금액을 집계합니다. (3) 예측된 소비는 앞으로의 소비를 예측하기 위해 실제 데이터에서 직선 회귀를 생성합니다.
결과 해석 방법:
이 데이터는 계약 금액과 비교하여 미래 예측을 추정하기 위해 지속적인 총계산을 통해 선 그래프로 매핑되어야 합니다.
주요 스키마:
Account_Usage
SQL
SET CREDIT_PRICE = 4.00; --edit this number to reflect credit price
SET TERM_LENGTH = 12; --integer value in months
SET TERM_START_DATE = '2020-01-01';
SET TERM_AMOUNT = 100000.00; --number(10,2) value in dollars
WITH CONTRACT_VALUES AS (
SELECT
$CREDIT_PRICE::decimal(10,2) as CREDIT_PRICE
,$TERM_AMOUNT::decimal(38,0) as TOTAL_CONTRACT_VALUE
,$TERM_START_DATE::timestamp as CONTRACT_START_DATE
,DATEADD(day,-1,DATEADD(month,$TERM_LENGTH,$TERM_START_DATE))::timestamp as CONTRACT_END_DATE
),
PROJECTED_USAGE AS (
SELECT
CREDIT_PRICE
,TOTAL_CONTRACT_VALUE
,CONTRACT_START_DATE
,CONTRACT_END_DATE
,(TOTAL_CONTRACT_VALUE)
/
DATEDIFF(day,CONTRACT_START_DATE,CONTRACT_END_DATE) AS DOLLARS_PER_DAY
, (TOTAL_CONTRACT_VALUE/CREDIT_PRICE)
/
DATEDIFF(day,CONTRACT_START_DATE,CONTRACT_END_DATE) AS CREDITS_PER_DAY
FROM CONTRACT_VALUES
),
ACTUAL_USAGE AS (
SELECT TO_DATE(START_TIME) AS CONSUMPTION_DATE
,SUM(DOLLARS_USED) as ACTUAL_DOLLARS_USED
FROM (
--COMPUTE FROM WAREHOUSES
SELECT
'WH Compute' as WAREHOUSE_GROUP_NAME
,WMH.WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,WMH.START_TIME
,WMH.END_TIME
,WMH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*WMH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
UNION ALL
--COMPUTE FROM SNOWPIPE
SELECT
'Snowpipe' AS WAREHOUSE_GROUP_NAME
,PUH.PIPE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,PUH.START_TIME
,PUH.END_TIME
,PUH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*PUH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY PUH
UNION ALL
--COMPUTE FROM CLUSTERING
SELECT
'Auto Clustering' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME || '.' || SCHEMA_NAME || '.' || TABLE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,ACH.START_TIME
,ACH.END_TIME
,ACH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*ACH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.AUTOMATIC_CLUSTERING_HISTORY ACH
UNION ALL
--COMPUTE FROM MATERIALIZED VIEWS
SELECT
'Materialized Views' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME || '.' || SCHEMA_NAME || '.' || TABLE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,MVH.START_TIME
,MVH.END_TIME
,MVH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*MVH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.MATERIALIZED_VIEW_REFRESH_HISTORY MVH
UNION ALL
--COMPUTE FROM SEARCH OPTIMIZATION
SELECT
'Search Optimization' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME || '.' || SCHEMA_NAME || '.' || TABLE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,SOH.START_TIME
,SOH.END_TIME
,SOH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*SOH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.SEARCH_OPTIMIZATION_HISTORY SOH
UNION ALL
--COMPUTE FROM REPLICATION
SELECT
'Replication' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,RUH.START_TIME
,RUH.END_TIME
,RUH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*RUH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.REPLICATION_USAGE_HISTORY RUH
UNION ALL
--STORAGE COSTS
SELECT
'Storage' AS WAREHOUSE_GROUP_NAME
,'Storage' AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,SU.USAGE_DATE
,SU.USAGE_DATE
,NULL AS CREDITS_USED
,$CREDIT_PRICE
,((STORAGE_BYTES + STAGE_BYTES + FAILSAFE_BYTES)/(1024*1024*1024*1024)*23)/DA.DAYS_IN_MONTH AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.STORAGE_USAGE SU
JOIN (SELECT COUNT(*) AS DAYS_IN_MONTH,TO_DATE(DATE_PART('year',D_DATE)||'-'||DATE_PART('month',D_DATE)||'-01') as DATE_MONTH FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.DATE_DIM GROUP BY TO_DATE(DATE_PART('year',D_DATE)||'-'||DATE_PART('month',D_DATE)||'-01')) DA ON DA.DATE_MONTH = TO_DATE(DATE_PART('year',USAGE_DATE)||'-'||DATE_PART('month',USAGE_DATE)||'-01')
) A
group by 1
),
FORECASTED_USAGE_SLOPE_INTERCEPT as (
SELECT
REGR_SLOPE(AU.ACTUAL_DOLLARS_USED,DATEDIFF(day,CONTRACT_START_DATE,AU.CONSUMPTION_DATE)) as SLOPE
,REGR_INTERCEPT(AU.ACTUAL_DOLLARS_USED,DATEDIFF(day,CONTRACT_START_DATE,AU.CONSUMPTION_DATE)) as INTERCEPT
FROM PROJECTED_USAGE PU
JOIN SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.DATE_DIM DA ON DA.D_DATE BETWEEN PU.CONTRACT_START_DATE AND PU.CONTRACT_END_DATE
LEFT JOIN ACTUAL_USAGE AU ON AU.CONSUMPTION_DATE = TO_DATE(DA.D_DATE)
)
SELECT
DA.D_DATE::date as CONSUMPTION_DATE
,PU.DOLLARS_PER_DAY AS CONTRACTED_DOLLARS_USED
,AU.ACTUAL_DOLLARS_USED
--the below is the mx+b equation to get the forecasted linear slope
,DATEDIFF(day,CONTRACT_START_DATE,DA.D_DATE)*FU.SLOPE + FU.INTERCEPT AS FORECASTED_DOLLARS_USED
FROM PROJECTED_USAGE PU
JOIN SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.DATE_DIM DA ON DA.D_DATE BETWEEN PU.CONTRACT_START_DATE AND PU.CONTRACT_END_DATE
LEFT JOIN ACTUAL_USAGE AU ON AU.CONSUMPTION_DATE = TO_DATE(DA.D_DATE)
JOIN FORECASTED_USAGE_SLOPE_INTERCEPT FU ON 1 = 1
;
스크린샷
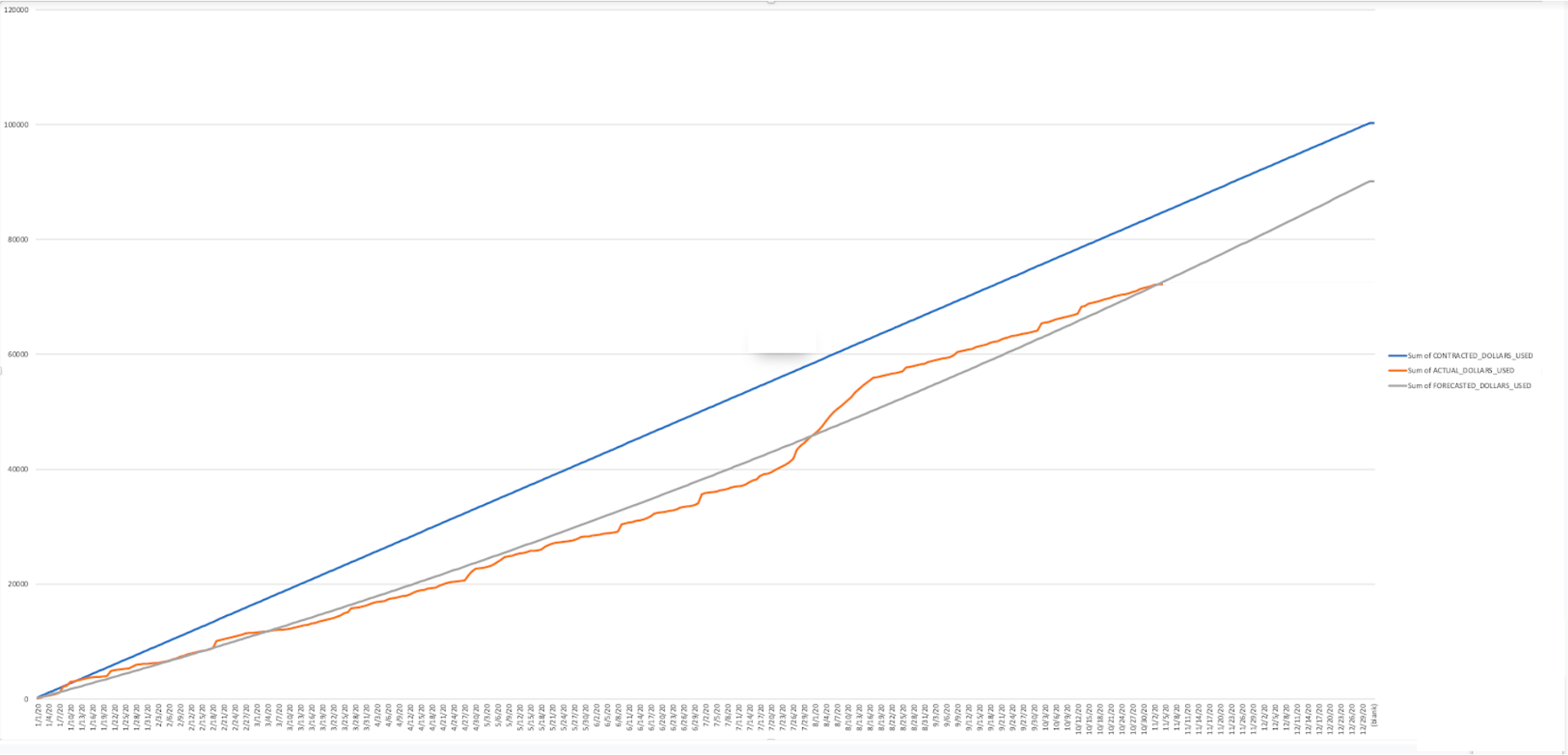
Tier 1
설명:
어떤 Snowflake 파트너 도구/솔루션(BI, ETL 등)이 가장 많은 크레딧을 소비하는지 식별합니다.
결과 해석 방법:
예측한 것보다 더 많은 크레딧을 소비하는 특정 파트너 솔루션이 있나요? 이러한 현상의 원인은 무엇인가요?
주요 스키마:
Account_Usage
SQL
--THIS IS APPROXIMATE CREDIT CONSUMPTION BY CLIENT APPLICATION
WITH CLIENT_HOUR_EXECUTION_CTE AS (
SELECT CASE
WHEN CLIENT_APPLICATION_ID LIKE 'Go %' THEN 'Go'
WHEN CLIENT_APPLICATION_ID LIKE 'Snowflake UI %' THEN 'Snowflake UI'
WHEN CLIENT_APPLICATION_ID LIKE 'SnowSQL %' THEN 'SnowSQL'
WHEN CLIENT_APPLICATION_ID LIKE 'JDBC %' THEN 'JDBC'
WHEN CLIENT_APPLICATION_ID LIKE 'PythonConnector %' THEN 'Python'
WHEN CLIENT_APPLICATION_ID LIKE 'ODBC %' THEN 'ODBC'
ELSE 'NOT YET MAPPED: ' || CLIENT_APPLICATION_ID
END AS CLIENT_APPLICATION_NAME
,WAREHOUSE_NAME
,DATE_TRUNC('hour',START_TIME) as START_TIME_HOUR
,SUM(EXECUTION_TIME) as CLIENT_HOUR_EXECUTION_TIME
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY" QH
JOIN "SNOWFLAKE"."ACCOUNT_USAGE"."SESSIONS" SE ON SE.SESSION_ID = QH.SESSION_ID
WHERE WAREHOUSE_NAME IS NOT NULL
AND EXECUTION_TIME > 0
--Change the below filter if you want to look at a longer range than the last 1 month
AND START_TIME > DATEADD(Month,-1,CURRENT_TIMESTAMP())
group by 1,2,3
)
, HOUR_EXECUTION_CTE AS (
SELECT START_TIME_HOUR
,WAREHOUSE_NAME
,SUM(CLIENT_HOUR_EXECUTION_TIME) AS HOUR_EXECUTION_TIME
FROM CLIENT_HOUR_EXECUTION_CTE
group by 1,2
)
, APPROXIMATE_CREDITS AS (
SELECT
A.CLIENT_APPLICATION_NAME
,C.WAREHOUSE_NAME
,(A.CLIENT_HOUR_EXECUTION_TIME/B.HOUR_EXECUTION_TIME)*C.CREDITS_USED AS APPROXIMATE_CREDITS_USED
FROM CLIENT_HOUR_EXECUTION_CTE A
JOIN HOUR_EXECUTION_CTE B ON A.START_TIME_HOUR = B.START_TIME_HOUR and B.WAREHOUSE_NAME = A.WAREHOUSE_NAME
JOIN "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_METERING_HISTORY" C ON C.WAREHOUSE_NAME = A.WAREHOUSE_NAME AND C.START_TIME = A.START_TIME_HOUR
)
SELECT
CLIENT_APPLICATION_NAME
,WAREHOUSE_NAME
,SUM(APPROXIMATE_CREDITS_USED) AS APPROXIMATE_CREDITS_USED
FROM APPROXIMATE_CREDITS
GROUP BY 1,2
ORDER BY 3 DESC
;
스크린샷
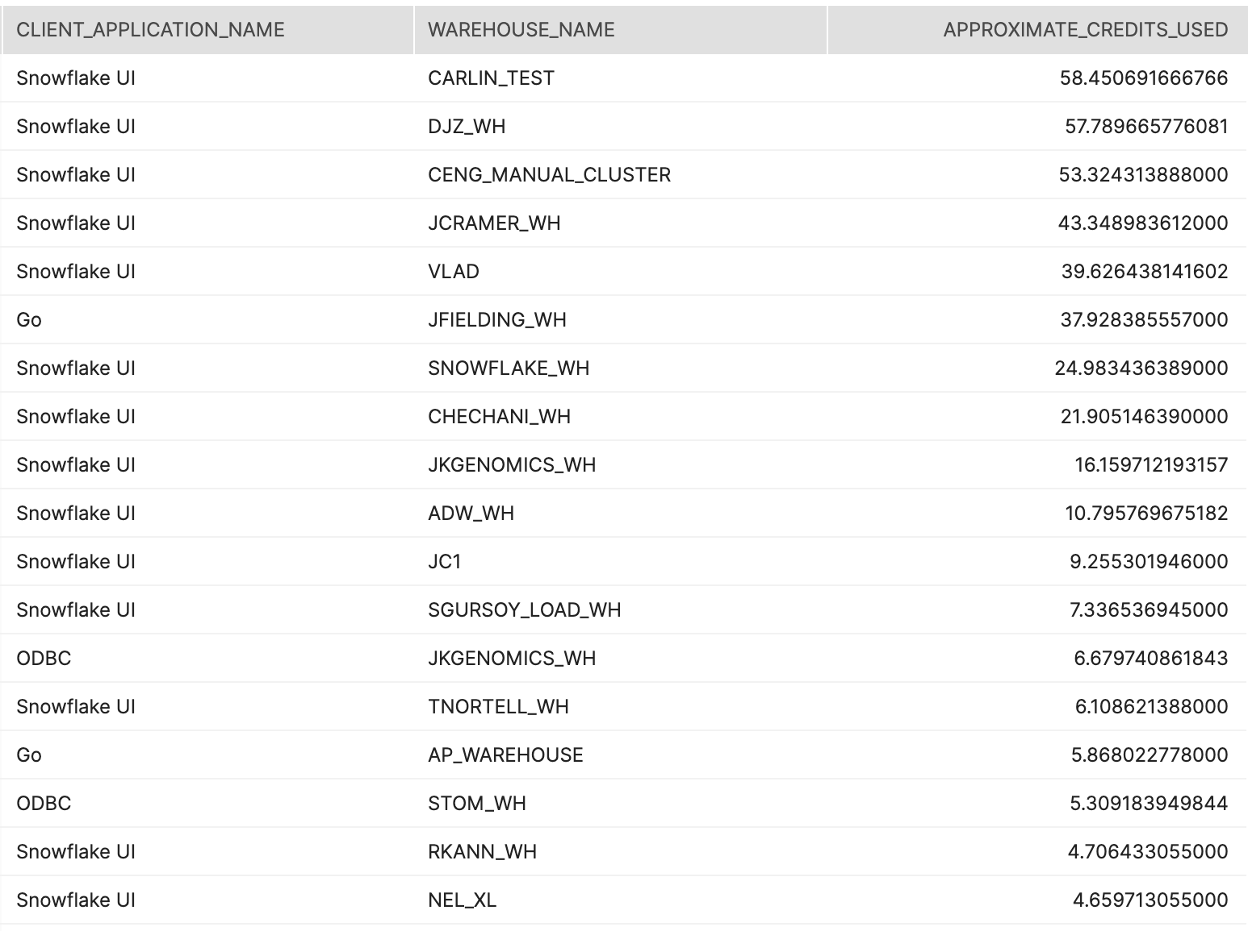
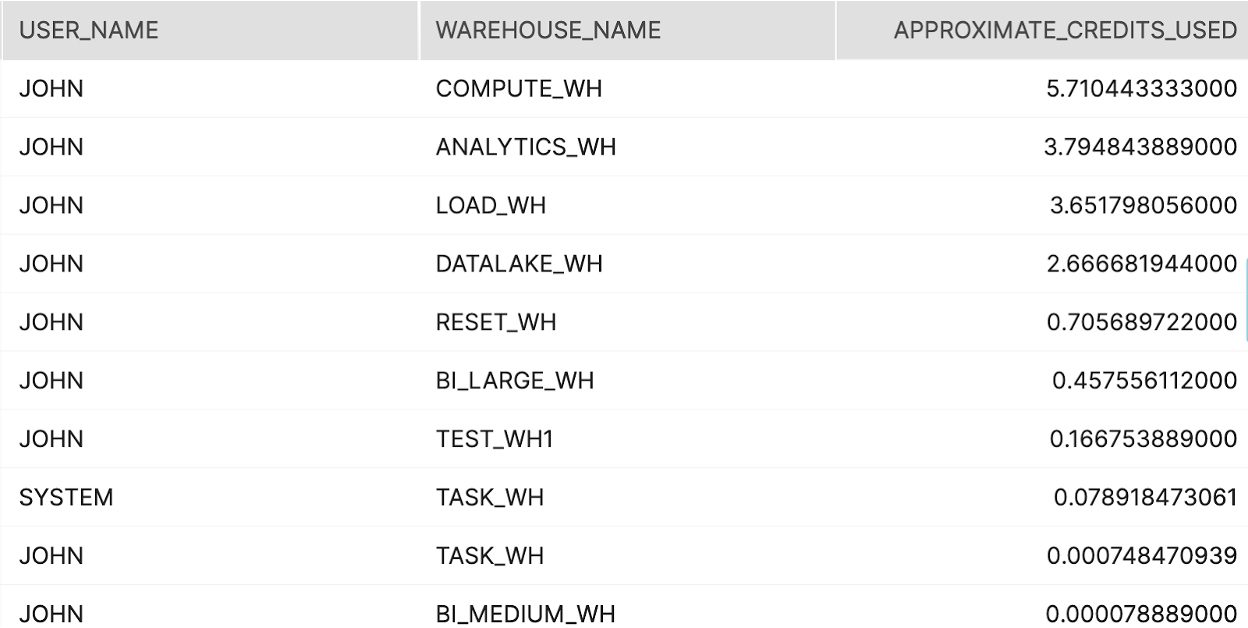
Tier 1
설명:
어떤 사용자가 여러분의 Snowflake 환경 내에서 가장 많은 크레딧을 소비하는지 식별합니다.
결과 해석 방법:
지정된 양보다 더 많은 크레딧을 소비하는 특정 사용자가 있나요? 이러한 추가 사용량의 목적은 무엇인가요?
주요 스키마:
Account_Usage
SQL
--THIS IS APPROXIMATE CREDIT CONSUMPTION BY USER
WITH USER_HOUR_EXECUTION_CTE AS (
SELECT USER_NAME
,WAREHOUSE_NAME
,DATE_TRUNC('hour',START_TIME) as START_TIME_HOUR
,SUM(EXECUTION_TIME) as USER_HOUR_EXECUTION_TIME
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY"
WHERE WAREHOUSE_NAME IS NOT NULL
AND EXECUTION_TIME > 0
--Change the below filter if you want to look at a longer range than the last 1 month
AND START_TIME > DATEADD(Month,-1,CURRENT_TIMESTAMP())
group by 1,2,3
)
, HOUR_EXECUTION_CTE AS (
SELECT START_TIME_HOUR
,WAREHOUSE_NAME
,SUM(USER_HOUR_EXECUTION_TIME) AS HOUR_EXECUTION_TIME
FROM USER_HOUR_EXECUTION_CTE
group by 1,2
)
, APPROXIMATE_CREDITS AS (
SELECT
A.USER_NAME
,C.WAREHOUSE_NAME
,(A.USER_HOUR_EXECUTION_TIME/B.HOUR_EXECUTION_TIME)*C.CREDITS_USED AS APPROXIMATE_CREDITS_USED
FROM USER_HOUR_EXECUTION_CTE A
JOIN HOUR_EXECUTION_CTE B ON A.START_TIME_HOUR = B.START_TIME_HOUR and B.WAREHOUSE_NAME = A.WAREHOUSE_NAME
JOIN "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_METERING_HISTORY" C ON C.WAREHOUSE_NAME = A.WAREHOUSE_NAME AND C.START_TIME = A.START_TIME_HOUR
)
SELECT
USER_NAME
,WAREHOUSE_NAME
,SUM(APPROXIMATE_CREDITS_USED) AS APPROXIMATE_CREDITS_USED
FROM APPROXIMATE_CREDITS
GROUP BY 1,2
ORDER BY 3 DESC
;
스크린샷
Tier 2
설명:
매우 자주 실행되는 쿼리가 있나요?? 실행 시간을 얼마나 차지하나요?
결과 해석 방법:
테이블로 결과 세트를 구체화할 기회일까요?
주요 스키마:
Account_Usage
SQL
SELECT
QUERY_TEXT
,count(*) as number_of_queries
,sum(TOTAL_ELAPSED_TIME)/1000 as execution_seconds
,sum(TOTAL_ELAPSED_TIME)/(1000*60) as execution_minutes
,sum(TOTAL_ELAPSED_TIME)/(1000*60*60) as execution_hours
from SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY Q
where 1=1
and TO_DATE(Q.START_TIME) > DATEADD(month,-1,TO_DATE(CURRENT_TIMESTAMP()))
and TOTAL_ELAPSED_TIME > 0 --only get queries that actually used compute
group by 1
having count(*) >= 10 --configurable/minimal threshold
order by 2 desc
limit 100 --configurable upper bound threshold
;
Tier 2
설명:
패턴이 있는지 확인하기 위해 가장 오래 실행된 쿼리 50개를 확인합니다
결과 해석 방법:
웨어하우스 클러스터링 또는 확장으로 최적화할 기회가 있나요?
주요 스키마:
Account_Usage
SQL
select
QUERY_ID
--reconfigure the url if your account is not in AWS US-West
,'https://'||CURRENT_ACCOUNT()||'.snowflakecomputing.com/console#/monitoring/queries/detail?queryId='||Q.QUERY_ID as QUERY_PROFILE_URL
,ROW_NUMBER() OVER(ORDER BY PARTITIONS_SCANNED DESC) as QUERY_ID_INT
,QUERY_TEXT
,TOTAL_ELAPSED_TIME/1000 AS QUERY_EXECUTION_TIME_SECONDS
,PARTITIONS_SCANNED
,PARTITIONS_TOTAL
from SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY Q
where 1=1
and TO_DATE(Q.START_TIME) > DATEADD(month,-1,TO_DATE(CURRENT_TIMESTAMP()))
and TOTAL_ELAPSED_TIME > 0 --only get queries that actually used compute
and ERROR_CODE iS NULL
and PARTITIONS_SCANNED is not null
order by TOTAL_ELAPSED_TIME desc
LIMIT 50
;
Tier 2
설명:
가장 많은 마이크로 파티션을 스캔한 상위 쿼리 50개를 확인합니다
결과 해석 방법:
웨어하우스 클러스터링 또는 확장으로 최적화할 기회가 있나요?
주요 스키마:
Account_Usage
SQL
select
QUERY_ID
--reconfigure the url if your account is not in AWS US-West
,'https://'||CURRENT_ACCOUNT()||'.snowflakecomputing.com/console#/monitoring/queries/detail?queryId='||Q.QUERY_ID as QUERY_PROFILE_URL
,ROW_NUMBER() OVER(ORDER BY PARTITIONS_SCANNED DESC) as QUERY_ID_INT
,QUERY_TEXT
,TOTAL_ELAPSED_TIME/1000 AS QUERY_EXECUTION_TIME_SECONDS
,PARTITIONS_SCANNED
,PARTITIONS_TOTAL
from SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY Q
where 1=1
and TO_DATE(Q.START_TIME) > DATEADD(month,-1,TO_DATE(CURRENT_TIMESTAMP()))
and TOTAL_ELAPSED_TIME > 0 --only get queries that actually used compute
and ERROR_CODE iS NULL
and PARTITIONS_SCANNED is not null
order by PARTITIONS_SCANNED desc
LIMIT 50
;
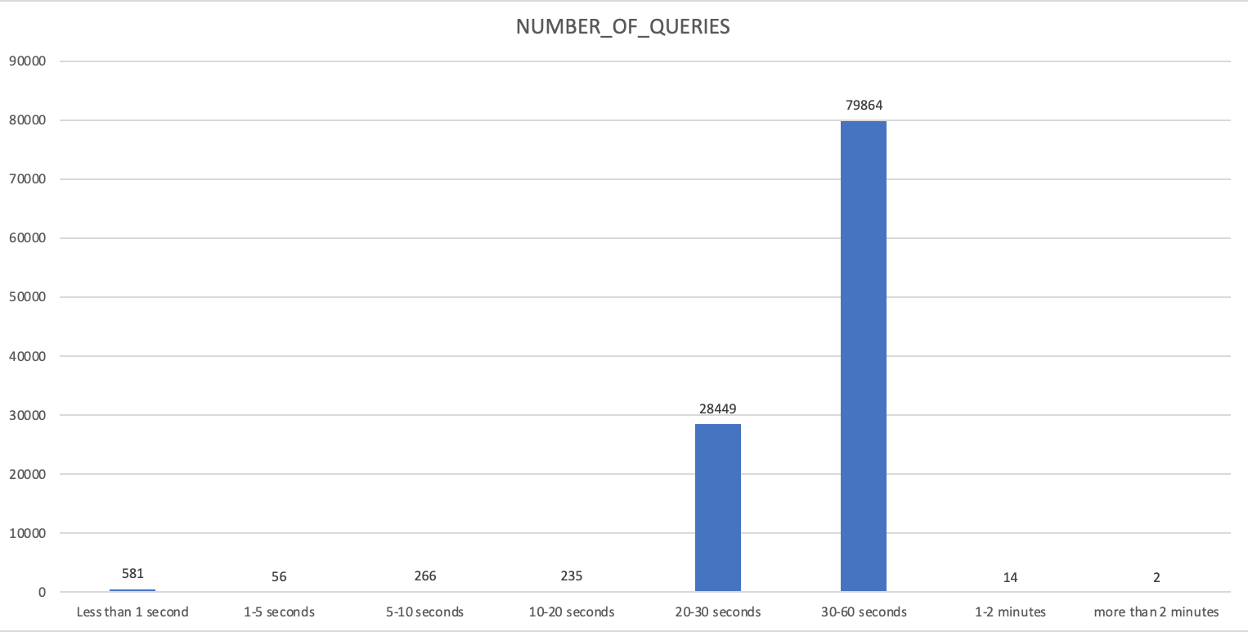
Tier 2
설명:
실행 시간 버킷별로 주어진 웨어하우스를 위해 쿼리를 그룹화합니다
결과 해석 방법:
쿼리 SLA 동향을 확인하고 웨어하우스 축소, 확장 또는 또 다른 웨어하우스로 일부 쿼리를 분리할지를 결정할 수 있는 기회입니다
주요 스키마:
Account_Usage
SQL
WITH BUCKETS AS (
SELECT 'Less than 1 second' as execution_time_bucket, 0 as execution_time_lower_bound, 1000 as execution_time_upper_bound
UNION ALL
SELECT '1-5 seconds' as execution_time_bucket, 1000 as execution_time_lower_bound, 5000 as execution_time_upper_bound
UNION ALL
SELECT '5-10 seconds' as execution_time_bucket, 5000 as execution_time_lower_bound, 10000 as execution_time_upper_bound
UNION ALL
SELECT '10-20 seconds' as execution_time_bucket, 10000 as execution_time_lower_bound, 20000 as execution_time_upper_bound
UNION ALL
SELECT '20-30 seconds' as execution_time_bucket, 20000 as execution_time_lower_bound, 30000 as execution_time_upper_bound
UNION ALL
SELECT '30-60 seconds' as execution_time_bucket, 30000 as execution_time_lower_bound, 60000 as execution_time_upper_bound
UNION ALL
SELECT '1-2 minutes' as execution_time_bucket, 60000 as execution_time_lower_bound, 120000 as execution_time_upper_bound
UNION ALL
SELECT 'more than 2 minutes' as execution_time_bucket, 120000 as execution_time_lower_bound, NULL as execution_time_upper_bound
)
SELECT
COALESCE(execution_time_bucket,'more than 2 minutes')
,count(Query_ID) as number_of_queries
from SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY Q
FULL OUTER JOIN BUCKETS B ON (Q.TOTAL_ELAPSED_TIME) >= B.execution_time_lower_bound and (Q.TOTAL_ELAPSED_TIME) < B.execution_time_upper_bound
where Q.Query_ID is null
OR (
TO_DATE(Q.START_TIME) >= DATEADD(week,-1,TO_DATE(CURRENT_TIMESTAMP()))
and warehouse_name = <WAREHOUSE_NAME>
and TOTAL_ELAPSED_TIME > 0
)
group by 1,COALESCE(b.execution_time_lower_bound,120000)
order by COALESCE(b.execution_time_lower_bound,120000)
;
스크린샷
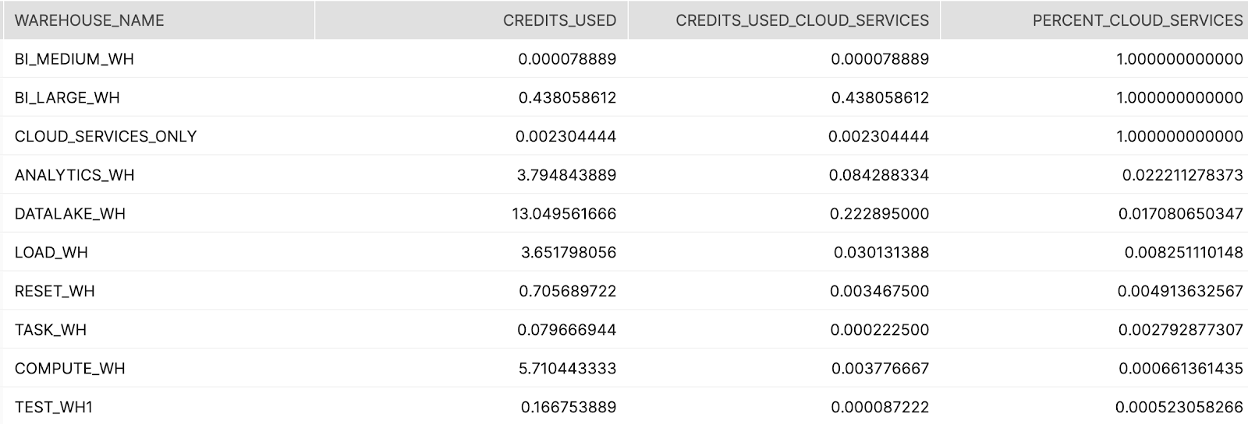
Tier 2
설명:
클라우드 서비스와 총 컴퓨팅의 비율로 정렬된 컴퓨팅의 클라우드 서비스 부분을 다루기 위해 충분한 컴퓨팅을 사용하고 있지 않은 웨어하우스를 보여줍니다
결과 해석 방법:
클라우드 서비스 컴퓨팅의 높은 볼륨과 비율을 사용하는 웨어하우스에 집중합니다. 이를 통해 전반적인 비용(복제, S3에 있는 목록 파일, 파트너 도구 설정 세션 매개 변수 등일 수 있음)이 줄어드는 이유를 조사합니다. 클라우드 서비스 크레딧 소비를 줄이려는 목표는 전반적인 크레딧의 클라우드 서비스 크레딧을 10% 미만으로 줄이는 것입니다. ####주요 스키마: Account_Usage
SQL
select
WAREHOUSE_NAME
,SUM(CREDITS_USED) as CREDITS_USED
,SUM(CREDITS_USED_CLOUD_SERVICES) as CREDITS_USED_CLOUD_SERVICES
,SUM(CREDITS_USED_CLOUD_SERVICES)/SUM(CREDITS_USED) as PERCENT_CLOUD_SERVICES
from "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_METERING_HISTORY"
where TO_DATE(START_TIME) >= DATEADD(month,-1,CURRENT_TIMESTAMP())
and CREDITS_USED_CLOUD_SERVICES > 0
group by 1
order by 4 desc
;
스크린샷
Tier 2
설명:
이 쿼리는 시간당 크레딧 소비와 비교했을 때 웨어하우스가 얼마나 바쁜지를 대략적으로 보여주기 위해 설계되었습니다. 최종 사용자에게 소비된 크레딧 수, 실행된 쿼리 수 및 각 시간 창에서 이러한 쿼리의 총 실행 시간을 보여줄 것입니다.
결과 해석 방법:
이 데이터는 크레딧 소비와 #/쿼리 실행 기간 간의 상관 관계를 도출하기 위해 사용될 수 있습니다. 가장 적은 크레딧 수를 위한 더 많은 쿼리 또는 더 높은 쿼리 기간은 크레딧별로 더 많은 가치를 도출하는 데 도움이 될 수 있습니다.
주요 스키마:
Account_Usage
SQL
SELECT
WMH.WAREHOUSE_NAME
,WMH.START_TIME
,WMH.CREDITS_USED
,SUM(COALESCE(B.EXECUTION_TIME_SECONDS,0)) as TOTAL_EXECUTION_TIME_SECONDS
,SUM(COALESCE(QUERY_COUNT,0)) AS QUERY_COUNT
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
LEFT JOIN (
--QUERIES FULLY EXECUTED WITHIN THE HOUR
SELECT
WMH.WAREHOUSE_NAME
,WMH.START_TIME
,SUM(COALESCE(QH.EXECUTION_TIME,0))/(1000) AS EXECUTION_TIME_SECONDS
,COUNT(DISTINCT QH.QUERY_ID) AS QUERY_COUNT
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
JOIN SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY QH ON QH.WAREHOUSE_NAME = WMH.WAREHOUSE_NAME
AND QH.START_TIME BETWEEN WMH.START_TIME AND WMH.END_TIME
AND QH.END_TIME BETWEEN WMH.START_TIME AND WMH.END_TIME
WHERE TO_DATE(WMH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
AND TO_DATE(QH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
GROUP BY
WMH.WAREHOUSE_NAME
,WMH.START_TIME
UNION ALL
--FRONT part OF QUERIES Executed longer than 1 Hour
SELECT
WMH.WAREHOUSE_NAME
,WMH.START_TIME
,SUM(COALESCE(DATEDIFF(seconds,QH.START_TIME,WMH.END_TIME),0)) AS EXECUTION_TIME_SECONDS
,COUNT(DISTINCT QUERY_ID) AS QUERY_COUNT
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
JOIN SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY QH ON QH.WAREHOUSE_NAME = WMH.WAREHOUSE_NAME
AND QH.START_TIME BETWEEN WMH.START_TIME AND WMH.END_TIME
AND QH.END_TIME > WMH.END_TIME
WHERE TO_DATE(WMH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
AND TO_DATE(QH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
GROUP BY
WMH.WAREHOUSE_NAME
,WMH.START_TIME
UNION ALL
--Back part OF QUERIES Executed longer than 1 Hour
SELECT
WMH.WAREHOUSE_NAME
,WMH.START_TIME
,SUM(COALESCE(DATEDIFF(seconds,WMH.START_TIME,QH.END_TIME),0)) AS EXECUTION_TIME_SECONDS
,COUNT(DISTINCT QUERY_ID) AS QUERY_COUNT
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
JOIN SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY QH ON QH.WAREHOUSE_NAME = WMH.WAREHOUSE_NAME
AND QH.END_TIME BETWEEN WMH.START_TIME AND WMH.END_TIME
AND QH.START_TIME < WMH.START_TIME
WHERE TO_DATE(WMH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
AND TO_DATE(QH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
GROUP BY
WMH.WAREHOUSE_NAME
,WMH.START_TIME
UNION ALL
--Middle part OF QUERIES Executed longer than 1 Hour
SELECT
WMH.WAREHOUSE_NAME
,WMH.START_TIME
,SUM(COALESCE(DATEDIFF(seconds,WMH.START_TIME,WMH.END_TIME),0)) AS EXECUTION_TIME_SECONDS
,COUNT(DISTINCT QUERY_ID) AS QUERY_COUNT
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
JOIN SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY QH ON QH.WAREHOUSE_NAME = WMH.WAREHOUSE_NAME
AND WMH.START_TIME > QH.START_TIME
AND WMH.END_TIME < QH.END_TIME
WHERE TO_DATE(WMH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
AND TO_DATE(QH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
GROUP BY
WMH.WAREHOUSE_NAME
,WMH.START_TIME
) B ON B.WAREHOUSE_NAME = WMH.WAREHOUSE_NAME AND B.START_TIME = WMH.START_TIME
WHERE TO_DATE(WMH.START_TIME) >= DATEADD(week,-1,CURRENT_TIMESTAMP())
GROUP BY
WMH.WAREHOUSE_NAME
,WMH.START_TIME
,WMH.CREDITS_USED
;
스크린샷
