The ability to move MongoDB data into a Snowflake Data Warehouse is key to enabling meaningful analytics using a proper SQL interface.
MongoDB addresses specific use cases where developers are building scalable applications with evolving data schemas. It is often used to host modern applications' operational data, where data storage and access patterns are highly optimized for fast write and retrieval, and many other factors like the availability and durability of data. To enable that functionality, MongoDB has its own recommended data model and access patterns which are not always as flexible as standard SQL for analytics purposes.
While coming to analyzing the data, most users prefer a system with a proper SQL interface as almost all analysts are familiar with SQL and almost all existing reporting or visualization tools require a SQL interface to extract data.
This is one of the key reasons that generate demand for replicating MongoDB data into a Snowflake data warehouse where data can be easily analyzed with proper SQL support. Other operational but relational databases such as SQL Server or PostgreSQL are sometimes used to store both transactional data and reporting data (in a separate schema) fulfilling the role of the data warehouse as well up to a certain limit. However with MongoDB's NoSQL schemaless nature, very early on it becomes important to move the data to Snowflake for meaningful analysis where data can not only be analyzed via SQL but also easily combined and modeled with other data sources. This type of analytics is crucial for application developers and product teams as they try to understand the usage patterns of their applications and how those could be improved to increase user satisfaction and conversion rates.
For many organizations using MongoDB to store critical information such as their own product usage, it becomes increasingly important to get this data replicated in a near-real-time fashion. Change Data Capture (CDC) is a design pattern to determine, track, capture, and deliver changes made to transactional databases such as MongoDB. CDC is an extremely efficient method to enable near real-time data replication to ensure analytics are done on fresh data. Other benefits of CDC include a reduced load on the operational database engine as well as the ability to replicate deleted records that cannot be replicated using standard batch SQL extraction methods.
Given this need, we'll use Rivery's platform to rapidly build a data pipeline to continuously migrate data from MongoDB to Snowflake. The primary method demonstrated in this quickstart is using MongoDB Change Streams - the MongoDB capability that powers CDC for MongoDB. If you'd like to move MongoDB data to Snowflake using SQL-based extractions, that option is possible as well and will be pointed out where applicable.
Prerequisites:
- Access to a Snowflake Account
- Access to a MongoDB database. You can either:
- Use a MongoDB trial
- Use your own MongoDB database
What You'll Learn:
In this guide, you will learn how to set up a data pipeline that migrates MongoDB data to Snowflake using CDC Data Replication in Rivery's SaaS ELT Platform. In this process, you will learn:
- How to use Snowflake partner connect to launch a Rivery account
- How to create a source to target data pipeline to load any data source into Snowflake
- How to configure standard SQL extraction or CDC database data replication into Snowflake
- How to enforce your Snowflake masking policy on ingested data
- How to automate data source to snowflake data pipeline execution and track the pipeline current status and overall performance
**If you already have a Rivery account you can skip this step.
The easiest way to start a Rivery account with an established connection to your Snowflake account is to utilize Snowflake's Partner Connect. Within Snowsite this can be found under Admin > Partner Connect > Search for Rivery.
This will set up both your Rivery account and Snowflake Target connection within Rivery.
If you'd like to set up a Rivery account separately, you can do so by navigating to Rivery's website and clicking ‘Start for Free'. You can also use this link to find more information.**
**If you've utilized Snowflake's Partner Connect to create your Rivery account you can skip to Step 4.
You can configure your Snowflake connection in Rivery. This will be needed later on as we point our MongoDB data (our Source) into Snowflake (our Target). Navigate to your Rivery account. From here, you can go to Connections > New Connection > Snowflake, fill in the connection details, and test the connection. More information can be found here.
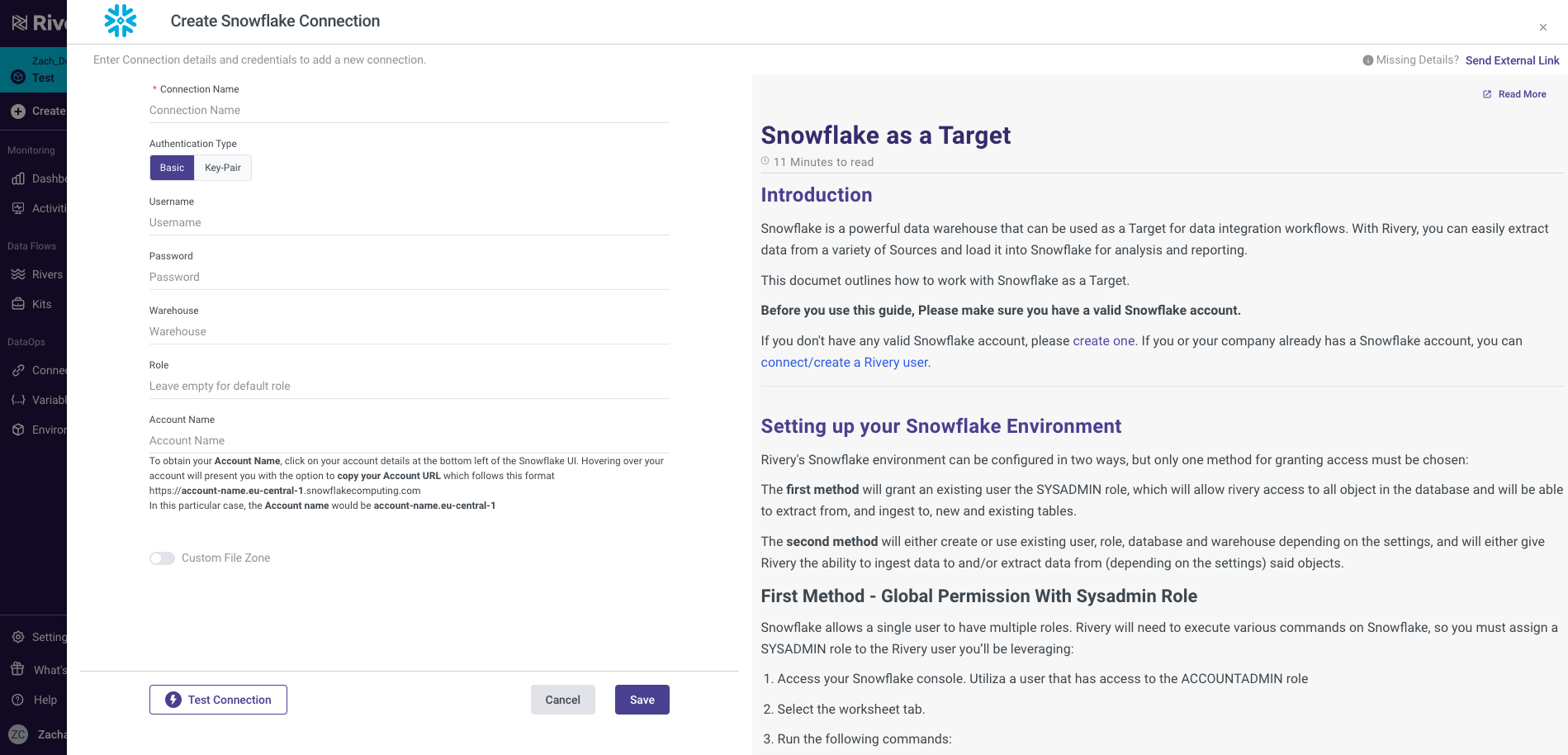
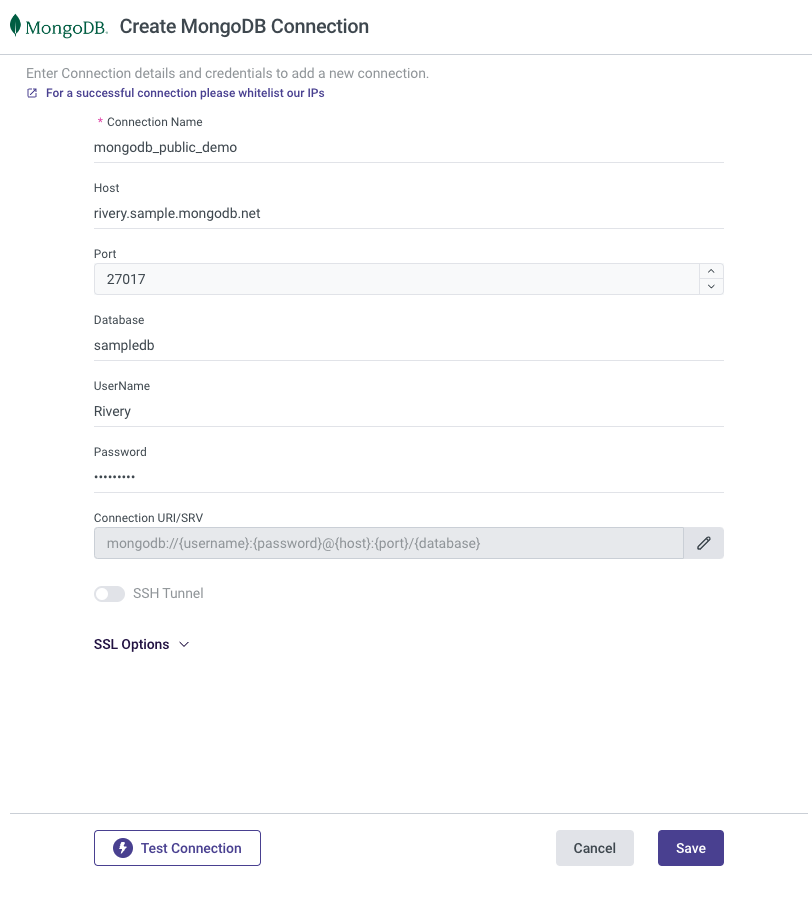
To configure Source Connection within Rivery, you'll want to navigate to your Rivery account. From here, you can go to Connections > New Connection > MongoDB, fill in the connection details, and test the connection. More information can be found here.
Note Rivery offers a few different methods to ensure a secured connection to MongoDB including SSH, Reverse SSH, VPN, AWS PrivateLink, and Azure Private Link. If you are using a trial instance of MongoDB, it may be sufficient to only whitelist Rivery's IPs. If you are connecting to your own MongoDB instance, you may want to use one of the methods mentioned above per your organization's preferences.
Configure MongoDB for Change Streams
If you are using MongoDB versions 4.0 or 4.1 you will need to make sure your MongoDB instance "Read Preference" is set to Primary as detailed here. If you are using version 4.2 or above this step isn't required.
Note only versions 4.0 and higher of MongoDB are supported by Rivery for CDC via Change Streams. If you have an older version of MongoDB or you don't want to use Change Streams you can still replicate your data using Standard Extraction (SQL-based). In that case, choose Standard Extraction instead of Change Streams under step 5.
Once your connections are set up, you'll want to create your replication data pipeline (River). On the navigation menu, click on Create River > Source to Target River.
From here, you'll want to select MongoDB as your Source.
Once selected, you can then select your created MongoDB connection from the Source Connection drop-down.
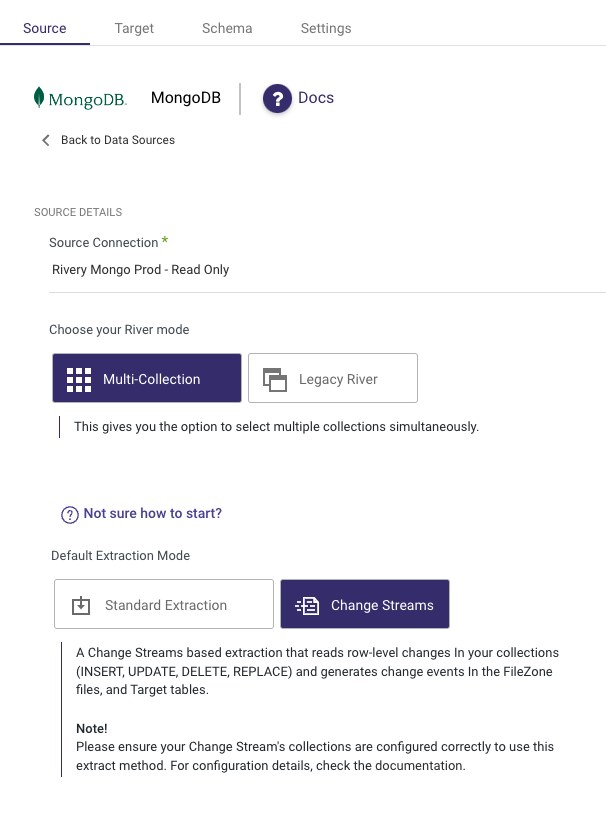
You can also add additional configurations like options to run ‘Multi-Collection' (Multi Table) or ‘Legacy River' (Single Table). You'll want to then select ‘Change Streams' as your Default Extraction Mode.
As mentioned above, you can also use ‘Standard Extraction' if you've decided to not enable ‘Change Streams'.
Click on the ‘Target' tab to configure your Target.
Select Snowflake from the list of sources and select your Snowflake connection from the Target Connection Dropdown.
Set the Database, Schema Name, Table Prefix, and Loading Mode in which you'd like to load your data.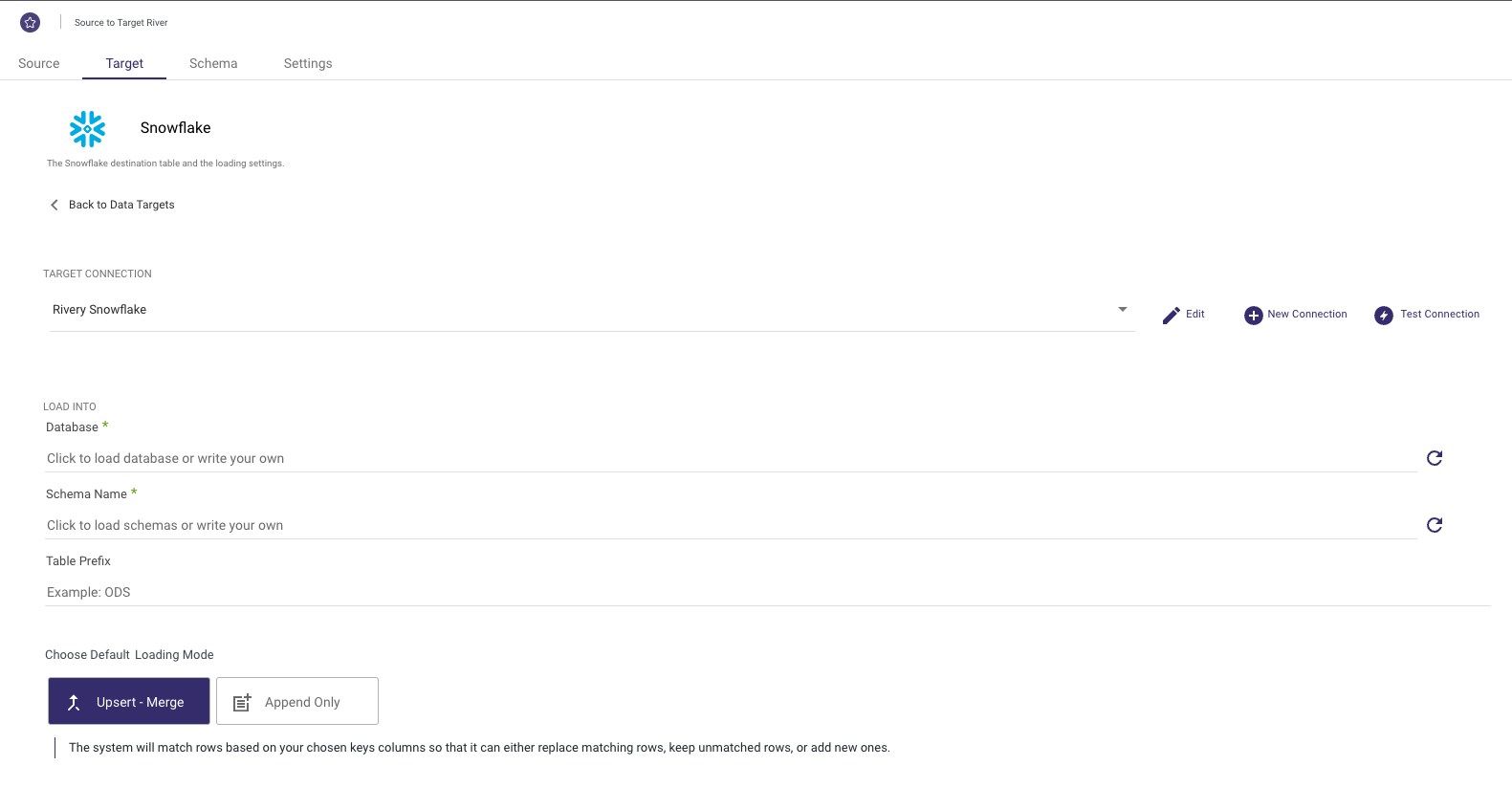
These will be the default values for each of the collections you select in the next step.
Rivery supports loading your data via 3 different modes including Upsert-Merge, Append, and Overwrite.
Clicking on the Schema tab you'll be able to select the specific collections that you want to extract/load.
This can be done by checking the box on the left-hand side of the collection name or by selecting the box next to ‘Source collections' to select all.
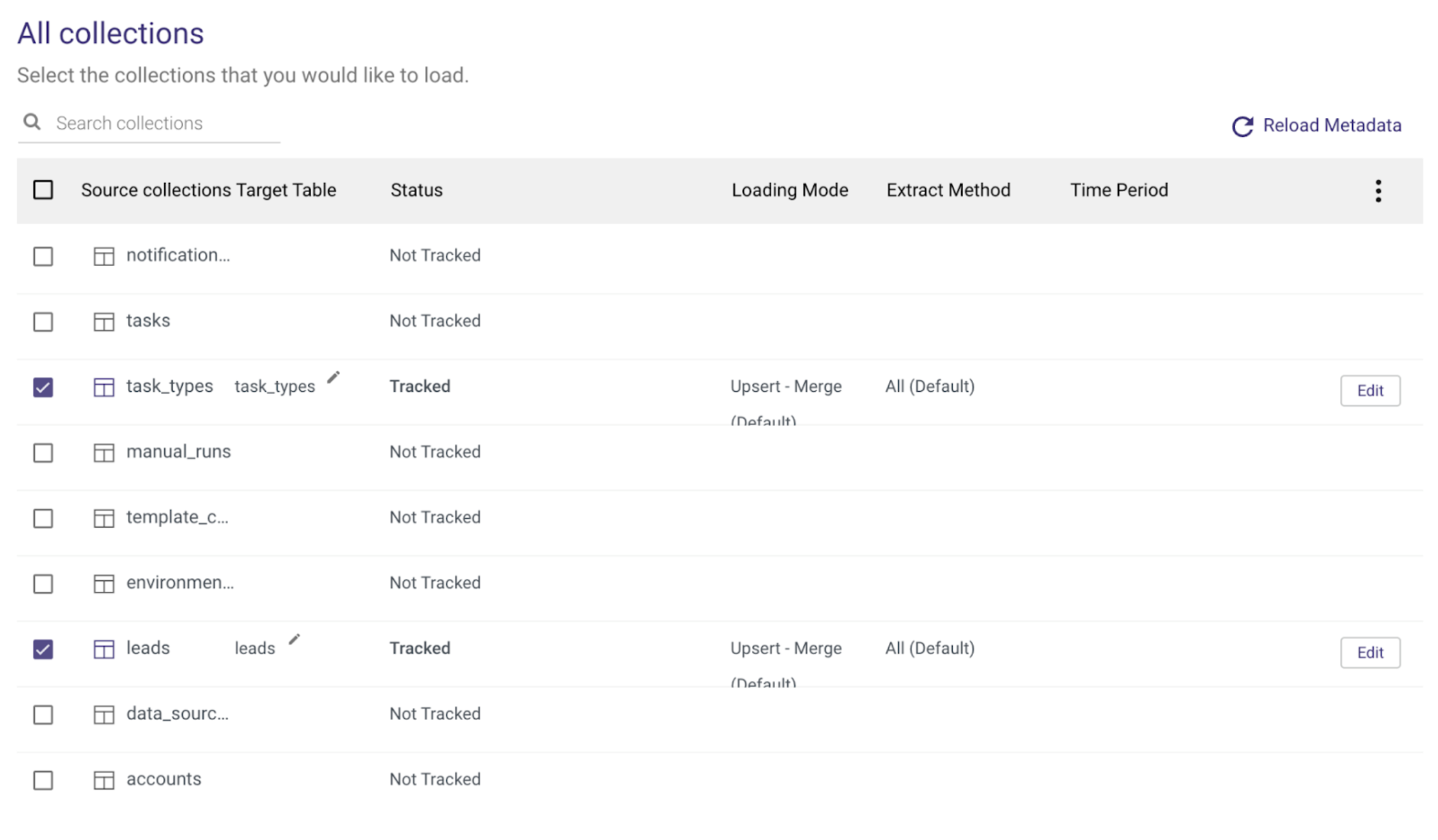
You can also configure each of the Target Table names and additional table settings by selecting the table name and navigating between the Columns and Table Settings tabs.
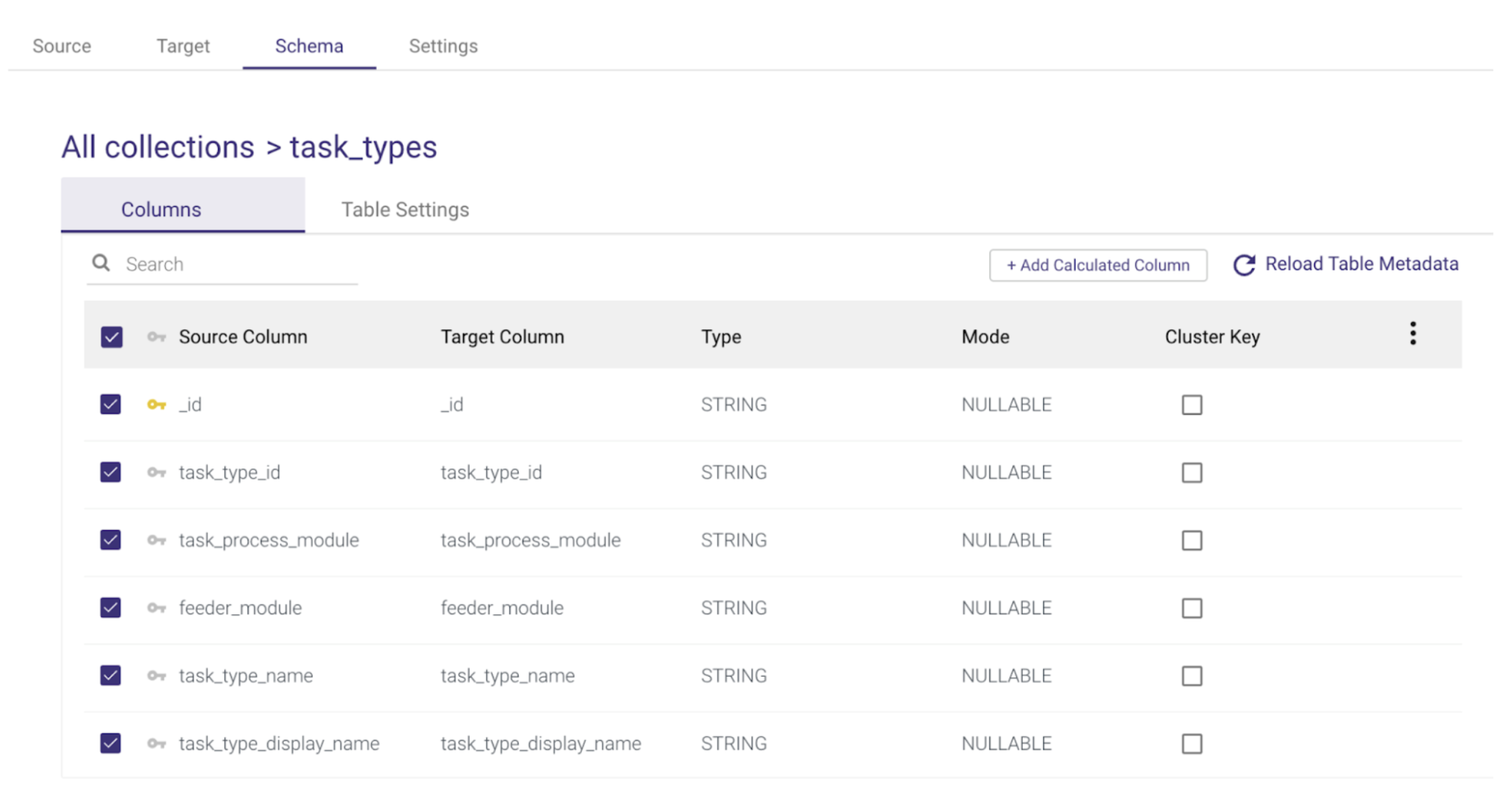
Specifically, under the Table Settings tab, you will find Advanced Options to filter logical key duplication and enforce a masking policy if you want to respect a data masking policy already defined in Snowflake.

Once your setup is complete you can click on the Enable Stream toggle.

This will make sure that you have everything set up and will give you the option to Schedule your River run.
If you choose Standard Extraction under step 5, you can schedule your pipeline under the Settings tab.
Regardless of your replication method, under the Settings tab, you can add any additional alerts. Lastly, all you have to do is save your River and click Run to execute it for the first time!
You can then monitor the River run from the Activities page via the navigation menu or by clicking on the River Activities icon on the right-hand side.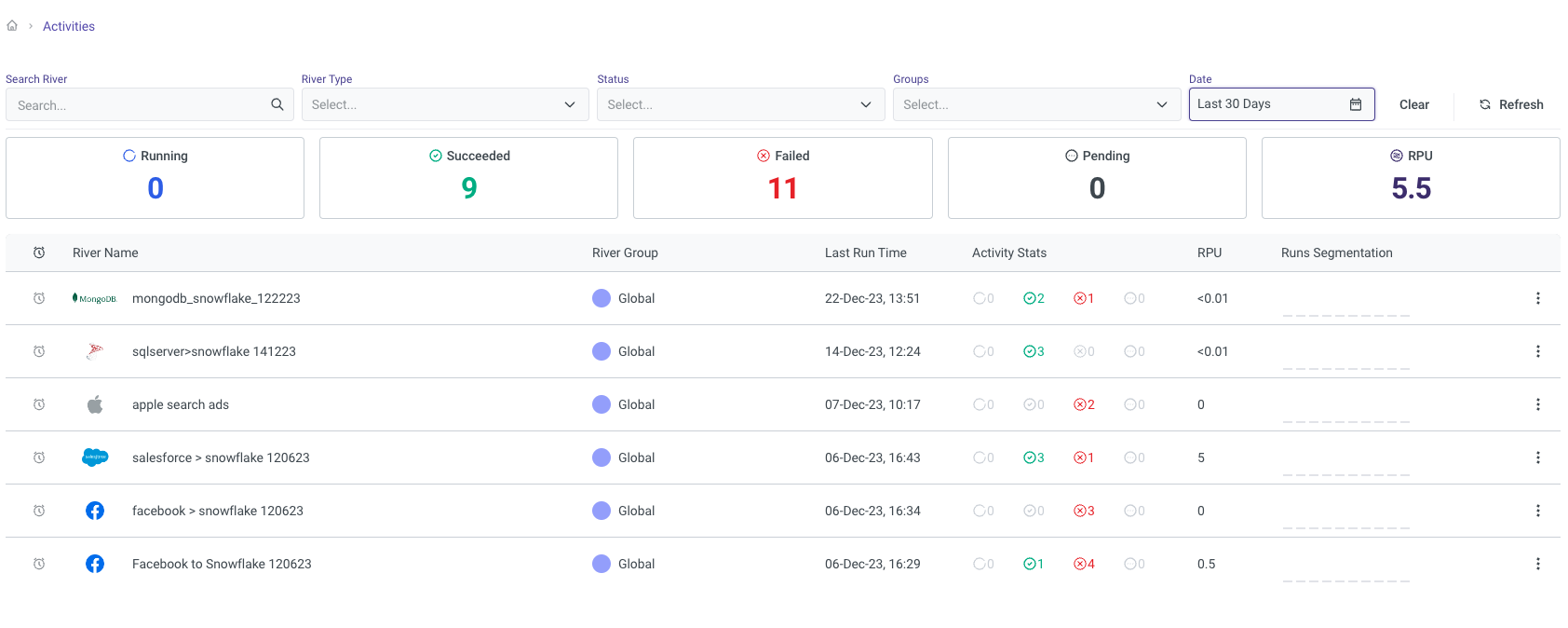
Clicking on any of the Pipelines will also give you granular breakdowns of each of the pipeline runs and tables.
Congratulations! You've now configured a MongoDB to Snowflake data migration pipeline. Depending on your configuration, this may be a one-time extract or schedule to run at a regular interval using CDC or standard SQL extraction. This pipeline should make sure you always get fresh MongoDB data in Snowflake with little effort to set up and code a data pipeline.
We would love your feedback on this QuickStart Guide! Please submit your feedback using this Feedback Form.
What You Learned
- How to use Snowflake partner connect to launch a Rivery account
- How to create a source to target data pipeline to load MongoDB data into Snowflake
- How to configure standard SQL extraction vs. CDC for MongoDB data replication into Snowflake
- How to enforce your Snowflake masking policy on ingested data
- How to automate MongoDB to snowflake data pipeline execution and track the pipeline current status and overall performance
Related Resources
- MongoDB Change Stream Overview
- How to transform data within Snowflake using Rivery
- How to Reverse ETL Snowflake data using Rivery
Get up to speed on other Rivery and Snowflake integrations to simplify your data delivery.