Through this quickstart guide, you will get an introduction to Snowflake for Machine Learning. You will set up your Snowflake and Python environments and build an ML development workflow from feature engineering to model training and batch inference with Snowflake ML all from a set of unified Python APIs.
What is Snowflake ML?
Snowflake ML is the integrated set of capabilities for end-to-end machine learning in a single platform on top of your governed data. Data scientists and ML engineers can easily and securely develop and productionize scalable features and models without any data movement, silos or governance tradeoffs.
Capabilities for model development and inference include:
- Snowflake Notebooks on Container Runtime for a familiar notebook interface that runs on scalable compute optimized for efficient data loading and distributed model training and hyperparameter tuning over multiple CPUs or GPUs.
- Snowflake ML APIs for distributed feature engineering, distributed training, and distributed hyperparameter optimization
- Snowflake Feature Store for continuous, automated refreshes on batch or streaming data
- ML Jobs to easily deploy and orchestrate ML pipelines over Snowflake data from any IDE of choice
- Snowflake Model Registry to manage models and their metadata, with model serving for inference with CPUs or GPUs
- ML Lineage to trace end-to-end feature and model lineage
- ML Explainability to better understand the features the model considers most impactful when generating predictions
- ML Observability to monitor performance metrics for models running inference in Snowflake
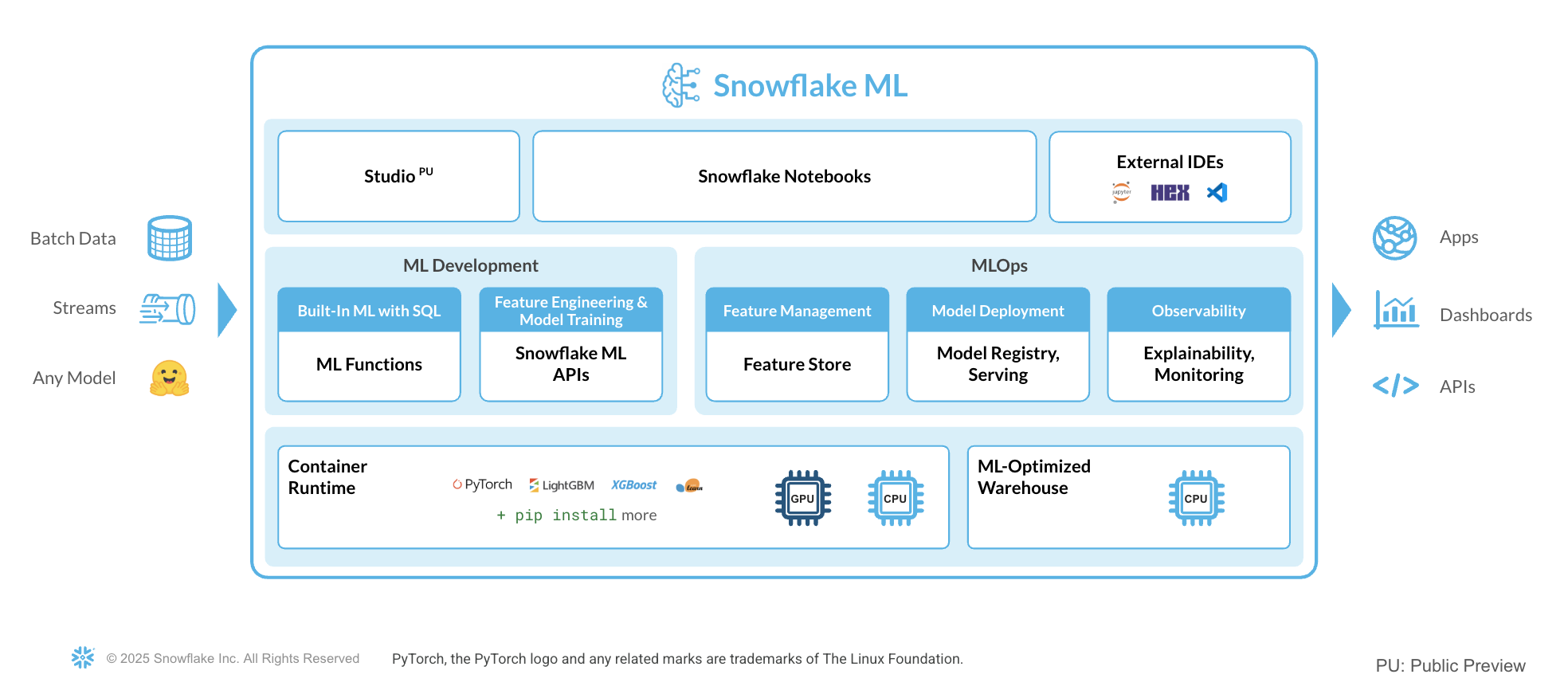
To get started with Snowflake ML, developers can use the Python APIs from the Snowflake ML library, directly from Snowflake Notebooks.
Snowflake ML provides the following advantages:
- Transform your data and train your models using open-source Python ML frameworks such as scikit-learn and xgboost
- Streamline model management and batch inference with built-in versioning support and role-based access control catering to both Python and SQL users
- Keep your ML pipeline running within Snowflake's security and governance perimeters
- Take advantage of the performance and scalability of Snowflake's scalable computing platform.
Learn more about model development with Snowflake ML APIs and deployment with the Snowflake Model Registry.
What you will learn
This quickstart will focus on building a custom ML workflow using the following features:
- Snowflake Notebooks, which comes pre-integrated with Snowflake ML capabilities.
- Snowflake ML APIs for distributed feature engineering and model training.
- Snowflake Model Registry, which provides scalable and secure model management of ML models - whether you trained them in Snowflake or another ML platform. Using these features, you can build and operationalize a complete ML workflow, taking advantage of Snowflake's scale and security features. It also includes an explainability function based on Shapley values.
Prerequisites
- Git installed
- A Snowflake Account. Sign up for a 30-day free trial account, if required.
What You'll Build
- A set of Snowflake Notebook on Container Runtime:
- to load and clean data
- to perform features transformations on the data
- to train an XGBoost ML model
- to log models and execute batch inference in Snowflake
- to apply a built-in explainability function to understand model performance
To get started using Snowflake Notebooks, first login to Snowsight and run the following setup.sql in a SQL worksheet. Sign up for a 30-day free trial account, if required. This will connect to the git repo where all the Snowflake Notebooks are stored and create them for you in your Snowflake environment.
USE ROLE ACCOUNTADMIN;
SET USERNAME = (SELECT CURRENT_USER());
SELECT $USERNAME;
-- Using ACCOUNTADMIN, create a new role for this exercise and grant to applicable users
CREATE OR REPLACE ROLE ML_MODEL_HOL_USER;
GRANT ROLE ML_MODEL_HOL_USER to USER identifier($USERNAME);
GRANT CREATE DATABASE ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT BIND SERVICE ENDPOINT ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT CREATE ROLE ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT CREATE WAREHOUSE ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT MANAGE GRANTS ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT CREATE INTEGRATION ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT CREATE APPLICATION PACKAGE ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT CREATE APPLICATION ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
GRANT IMPORT SHARE ON ACCOUNT TO ROLE ML_MODEL_HOL_USER;
USE ROLE ML_MODEL_HOL_USER;
CREATE OR REPLACE WAREHOUSE ML_HOL_WH; --by default, this creates an XS Standard Warehouse
CREATE OR REPLACE DATABASE ML_HOL_DB;
CREATE OR REPLACE SCHEMA ML_HOL_SCHEMA;
CREATE OR REPLACE STAGE ML_HOL_ASSETS; --to store model assets
-- create csv format
CREATE FILE FORMAT IF NOT EXISTS ML_HOL_DB.ML_HOL_SCHEMA.CSVFORMAT
SKIP_HEADER = 1
TYPE = 'CSV';
-- create external stage with the csv format to stage the diamonds dataset
CREATE STAGE IF NOT EXISTS ML_HOL_DB.ML_HOL_SCHEMA.DIAMONDS_ASSETS
FILE_FORMAT = ML_HOL_DB.ML_HOL_SCHEMA.CSVFORMAT
URL = 's3://sfquickstarts/intro-to-machine-learning-with-snowpark-ml-for-python/diamonds.csv';
-- create network rule to allow all external access from Notebook
CREATE OR REPLACE NETWORK RULE allow_all_rule
TYPE = 'HOST_PORT'
MODE= 'EGRESS'
VALUE_LIST = ('0.0.0.0:443','0.0.0.0:80');
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION allow_all_integration
ALLOWED_NETWORK_RULES = (allow_all_rule)
ENABLED = true;
GRANT USAGE ON INTEGRATION allow_all_integration TO ROLE ML_MODEL_HOL_USER;
-- create an API integration with Github
CREATE OR REPLACE API INTEGRATION GITHUB_INTEGRATION_ML_HOL
api_provider = git_https_api
api_allowed_prefixes = ('https://github.com/')
enabled = true
comment='Git integration with Snowflake Demo Github Repository.';
-- create the integration with the Github demo repository
CREATE OR REPLACE GIT REPOSITORY GITHUB_INTEGRATION_ML_HOL
ORIGIN = 'https://github.com/Snowflake-Labs/sfguide-intro-to-machine-learning-with-snowflake-ml-for-python.git'
API_INTEGRATION = 'GITHUB_INTEGRATION_ML_HOL'
COMMENT = 'Github Repository';
-- fetch most recent files from Github repository
ALTER GIT REPOSITORY GITHUB_INTEGRATION_ML_HOL FETCH;
-- copy notebooks into Snowflake & configure runtime settings
CREATE OR REPLACE NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_DATA_INGEST
FROM '@ML_HOL_DB.ML_HOL_SCHEMA.GITHUB_INTEGRATION_ML_HOL/branches/main'
MAIN_FILE = 'notebooks/0_start_here.ipynb'
QUERY_WAREHOUSE = ML_HOL_WH
RUNTIME_NAME = 'SYSTEM$BASIC_RUNTIME'
COMPUTE_POOL = 'SYSTEM_COMPUTE_POOL_CPU'
IDLE_AUTO_SHUTDOWN_TIME_SECONDS = 3600;
ALTER NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_DATA_INGEST ADD LIVE VERSION FROM LAST;
ALTER NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_DATA_INGEST SET EXTERNAL_ACCESS_INTEGRATIONS = ('allow_all_integration');
CREATE OR REPLACE NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_FEATURE_TRANSFORM
FROM '@ML_HOL_DB.ML_HOL_SCHEMA.GITHUB_INTEGRATION_ML_HOL/branches/main'
MAIN_FILE = 'notebooks/1_sf_nb_snowflake_ml_feature_transformations.ipynb'
QUERY_WAREHOUSE = ML_HOL_WH
RUNTIME_NAME = 'SYSTEM$BASIC_RUNTIME'
COMPUTE_POOL = 'SYSTEM_COMPUTE_POOL_CPU'
IDLE_AUTO_SHUTDOWN_TIME_SECONDS = 3600;
ALTER NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_FEATURE_TRANSFORM ADD LIVE VERSION FROM LAST;
ALTER NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_FEATURE_TRANSFORM SET EXTERNAL_ACCESS_INTEGRATIONS = ('allow_all_integration');
CREATE OR REPLACE NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_MODELING
FROM '@ML_HOL_DB.ML_HOL_SCHEMA.GITHUB_INTEGRATION_ML_HOL/branches/main'
MAIN_FILE = 'notebooks/2_sf_nb_snowflake_ml_model_training_inference.ipynb'
QUERY_WAREHOUSE = ML_HOL_WH
RUNTIME_NAME = 'SYSTEM$BASIC_RUNTIME'
COMPUTE_POOL = 'SYSTEM_COMPUTE_POOL_CPU'
IDLE_AUTO_SHUTDOWN_TIME_SECONDS = 3600;
ALTER NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_MODELING ADD LIVE VERSION FROM LAST;
ALTER NOTEBOOK ML_HOL_DB.ML_HOL_SCHEMA.ML_HOL_MODELING SET EXTERNAL_ACCESS_INTEGRATIONS = ('allow_all_integration');
-- create Streamlit
CREATE OR REPLACE STREAMLIT ML_HOL_STREAMLIT_APP
FROM '@ML_HOL_DB.ML_HOL_SCHEMA.GITHUB_INTEGRATION_ML_HOL/branches/main/scripts/streamlit/'
MAIN_FILE = 'diamonds_pred_app.py'
QUERY_WAREHOUSE = 'ML_HOL_WH'
TITLE = 'ML_HOL_STREAMLIT_APP'
COMMENT = '{"origin":"sf_sit-is", "name":"e2e_ml_snowparkpython", "version":{"major":1, "minor":0}, "attributes":{"is_quickstart":1, "source":"streamlit"}}';
ALTER STREAMLIT ML_HOL_STREAMLIT_APP ADD LIVE VERSION FROM LAST;
Change role to ML_MODEL_HOL_USER
Navigate to Notebooks > ML_HOL_DATA_INGEST.
Within this notebook, we will clean and ingest the diamonds dataset into a Snowflake table from an external stage. The diamonds dataset has been widely used in data science and machine learning, and we will use it to demonstrate Snowflake's native data science transformers throughout this quickstart.
The overall goal of this ML project is to predict the price of diamonds given different qualitative and quantitative attributes.
Change role to ML_MODEL_HOL_USER
Navigate to Notebooks > ML_HOL_FEATURE_TRANSFORM.
In this notebook, we will walk through a few transformations on the diamonds dataset that are included in the Snowflake ML APIs. We will also build a preprocessing pipeline to be used in the notebook.
Change role to ML_MODEL_HOL_USER
Navigate to Notebooks > ML_HOL_MODELING.
In this notebook, we will illustrate how to train an XGBoost model with the diamonds. We also show how to execute batch inference and model explainability through the Snowflake Model Registry.
Change role to ML_MODEL_HOL_USER
Navigate to Streamlit > ML_HOL_STREAMLIT_APP.
This Streamlit app will execute predictions based on chosen feature values in the sidebar. Make sure not to delete the model before running this app.
Congratulations, you have successfully completed this quickstart! Through this quickstart, we were able to showcase Snowflake for Machine Learning through the introduction of native model development and operations capabilities. Now, you can run data preprocessing, feature engineering, model training, and batch inference in a few lines of code.
For more information, check out the resources below:
Related Resources
- Source Code on GitHub
- Snowflake ML Webpage
- Snowflake ML API Docs
- Quickstart: Build an End-to-End ML Workflow in Snowflake
- Check out other Snowflake ML quickstarts here
- Download Reference Architecture
- Read the Blog
- Watch the Demo