Getting started with AI on enterprise data can seem overwhelming. Between getting familiar with LLMs, how to perform custom prompt engineering, fine-tuning an existing foundation model and how to get a wide range of LLMs deployed/integrated to run multiple tests all while keeping that valuable enterprise data secure. Well, a lot of these complexities are being abstracted away for you in Snowflake Cortex AI.
In this quickstart we will specifically show you how to use Llama 3.1 405B and Llama 3 8B but you can follow the same steps with other LLMs available in Snowflake Cortex AI.
What is Snowflake Cortex AI?
Snowflake Cortex AI is an intelligent, fully managed service that provides access to industry-leading large language models (LLMs) and chat with your data services. Cortex AI capabilities include:
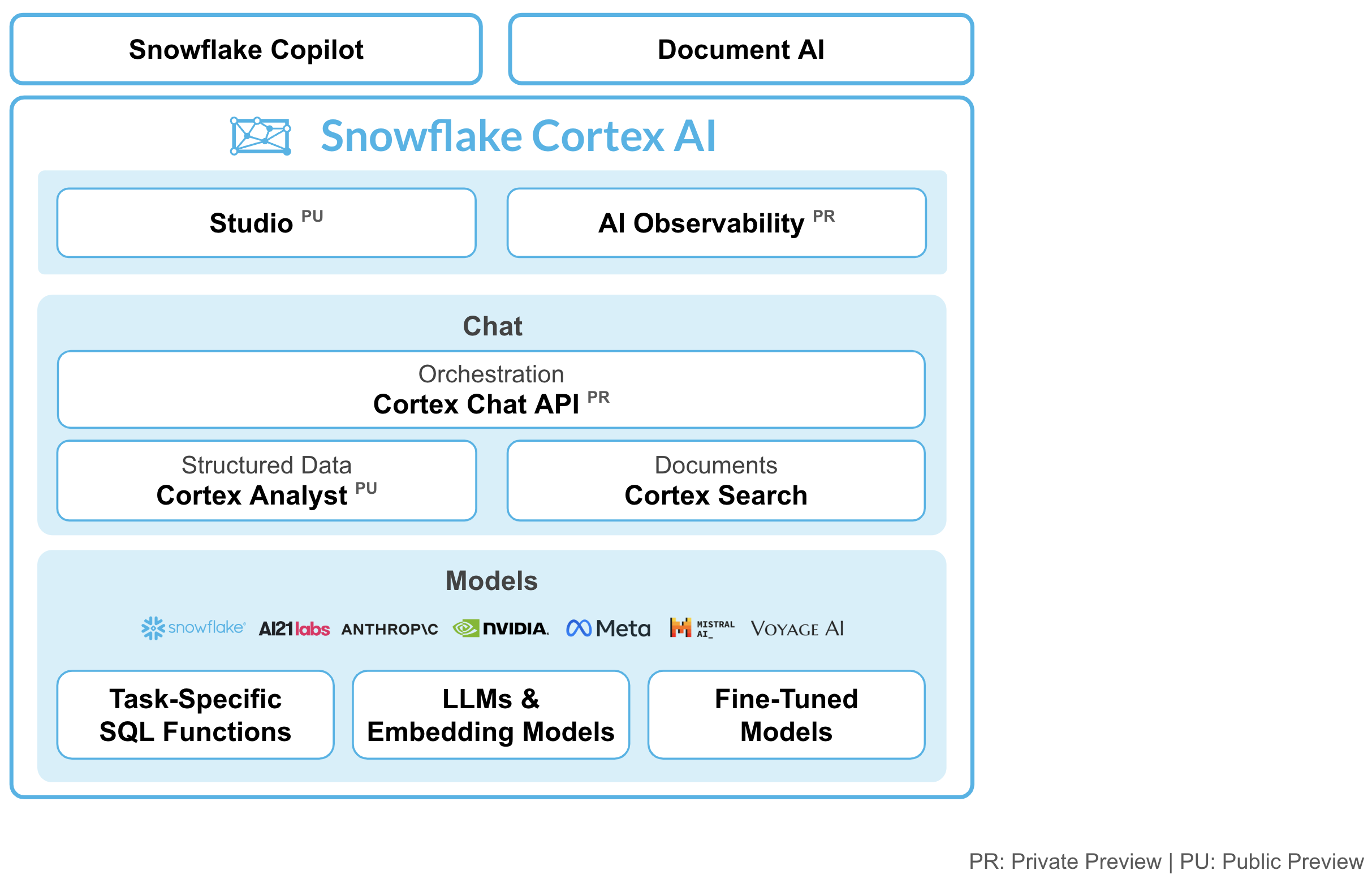
Models: Access to tasks specific functions such as sentiment analysis, translation as well as Foundation Models from Snowflake, Meta, Mistral AI. Leading models from Meta and Mistral AI are available for serverless fine-tuning (public preview).
Chat Services: Ask questions against unstructured data, such as documents using Cortex Search or ask questions to structured data, such as sales transactions using Cortex Analyst - both coming soon to public preview.
AI & ML Studio: This a no-code development workspace in Snowflake. Specifically for LLMs, Studio lets users quickly try out models, easily fine-tune models, and set up use cases such as search so you can expedite delivery of applications.
In this quickstart, we will go through 2 flows – Use Cortex AI to fine-tune an LLM to categorize customer support tickets for a Telecom provider, and generate custom email/text communications tailored to each customer ticket.
Learn more about Snowflake Cortex.
Custom LLMs for Enterprise Use-cases
Compared to a smaller size model such as llama3-8b, a foundation large language model such as llama3.1-405b can be used to categorize support tickets with higher accuracy. But using a large language model comes with higher inference costs.
Using fine-tuning, organizations can make smaller models really good at specific tasks to deliver results with the accuracy of larger models at just a fraction of the cost.
Fine-tuning requires some labeled data. In many real-world scenarios this data can be hard to come by. This might be a new use-case that did not exist before or the existing data cannot be accessed. LLMs allow us to solve this issue via synthetic data.
What You Will Learn
By the end of this quickstart guide, you will be able to use Snowflake Cortex AI to:
- Generate Synthetic Data: Prompt
llama3.1-405bto generate synthetic customer support tickets. - Prepare: Training dataset for distilling the knowledge from a foundation model into a small custom LLM.
- Distill: The knowledge from the large model to fine-tune model a smaller model and achieve high accuracy at fraction of cost.
- Generate: Custom email/text communications tailored to each support ticket
What You Will Build
- Fine-tuned model used for support ticket categorization
- Email/text generation application
Prerequisites
- A Snowflake account in a region where Snowflake Cortex AI is available. Check availability.
- A Snowflake user created with ACCOUNTADMIN permissions. This user will be used to get things setup in Snowflake.
- Download the Snowflake Notebook from this Git repository for fine-tuning the model.
Let's create a fresh database for this guide. Log into Snowsight using your credentials to get started.
In a new SQL worksheet, run the following SQL commands to create the warehouse, database and schema.
USE ROLE ACCOUNTADMIN;
CREATE WAREHOUSE DASH_S WAREHOUSE_SIZE=SMALL;
CREATE DATABASE DASH_DB;
CREATE SCHEMA DASH_SCHEMA;
USE DASH_DB.DASH_SCHEMA;
USE WAREHOUSE DASH_S;
Define Support Ticket Categories
First, we create a list of categories of support tickets that we want the model to categorize. Run these SQL statements in a SQL worksheet to create support_ticket_category table and load data.
create or replace table support_ticket_category (
category string
);
INSERT INTO support_ticket_category (category) VALUES
('Roaming fees'),
('Slow data speed'),
('Lost phone'),
('Add new line'),
('Closing account');
Prompt Llama 3.1 405b to Generate Synthetic Support Tickets
In this step we prompt the LLM to generate 25 synthetic examples of customer support tickets for every category.
create or replace table support_tickets as (
SELECT
category,
TRY_PARSE_JSON(
SNOWFLAKE.CORTEX.COMPLETE(
'llama3.1-405b',
CONCAT(
'Please provide 25 examples of customer service calls in a telecom company for the following category:', category, '. Provide detailed and realistic scenarios that customer service representatives might encounter. Ensure the examples are diverse and cover various situations within each category. Please put the examples into a JSON list. Each element in JSON list should include the following: {"scenario": <scenario>, "request": <detailed request from the customer, which usually is less than 3 sentences.>}. Only include JSON in output and no other words.'))) as tickets
from support_ticket_category
);
The table support_tickets now contains our synthetic data but the data format is a bit inconvenient as each row contains multiple support tickets. To flatten the data we run
create or replace table flatten_support_tickets as (
select
category,
abs(hash(value:request)) % 10000000 as id,
value:request as request,
value:scenario as scenario
from support_tickets, lateral flatten(input => tickets)
);
We now have a table flatten_support_tickets with one ticket per row. We also generated unique IDs for each ticket.
Rating and Filtering Synthetic Data with an LLM as a Judge.
We want to make sure our data is of high quality. Again, we can use an LLM to help us with this task. Instead of prompting the LLM to generate the support tickets, we now ask the LLM to rate the synthetic data for two criteria: We want the tickets to be (1) realistic and (2) valid.
create or replace table rate_support_tickets as (
SELECT category, id, request, scenario, TRY_PARSE_JSON(SNOWFLAKE.CORTEX.COMPLETE('llama3.1-405b', CONCAT('You are a judge to verify if a the support ticket received in a telecom company is realistic, and valid, please give scores from 1 to 5 for each category and give your final recommendation for the given question. Support Ticket: ', request, ' Please give the score in JSON format alone following this example: "{"realistic": 5, "valid": 4}". You can put a reason into the result JSON as "reason": <reason>. Only include JSON in the output and no other words.'))) as rating
from flatten_support_tickets
);
Now we can filter out examples that are below the bar for realistic or valid. We create the filtered_support_tickets table for the next steps.
create or replace table filtered_support_tickets as (
select * from rate_support_tickets where rating['realistic'] >= 4 and rating['valid'] >= 4
);
Test Base Model Performance for Support Ticket Categorization using Cortex AI
First, let's use Snowflake Cortex AI COMPLETE() to categorize the support tickets into our categories – Roaming Fees, Slow data speed, Add new line, Closing account and more.
We can use any Cortex AI supported model under the hood to invoke the COMPLETE() function. In this quickstart, let's use llama3.1-405b and use the following prompt.
CREATE OR REPLACE FUNCTION CATEGORIZE_PROMPT_TEMPLATE(request STRING)
RETURNS STRING
LANGUAGE SQL
AS
$$
CONCAT('You are an agent that helps organize requests that come to our support team.
The request category is the reason why the customer reached out. These are the possible types of request categories:
Roaming fees
Slow data speed
Lost phone
Add new line
Closing account
Try doing it for this request and return only the request category only.
request: ', request)
$$
;
Using a powerful and large language model such as llama3.1-405b might be highly accurate without doing any complex customizations but running llama3.1-405b on millions of support tickets comes with a cost. So, let's try the same COMPLETE() function with the same prompt but this time with a smaller model such as llama3-8b.
SELECT id, SNOWFLAKE.CORTEX.COMPLETE('llama3-8b', CATEGORIZE_PROMPT_TEMPLATE(request)) FROM filtered_support_tickets;
As we can see, the smaller model llama3-8b does not generate results with a consistent structure.
To overcome this, we could fine-tune llama3-8b particularly for this task. This fine-tuned model will be smaller in size and the inference cost is only a fraction of what a larger model would cost.
Prepare the Distillation Data
We now split the data into a training and validation portion. We want to use 20% of the data for validation and the remaining 80% for training. To get a reproducible data split between runs, we use the unique ID we to determine if a ticket is part of the training portion or the validation portion:
create or replace table training_data as (
SELECT * from filtered_support_tickets where ID % 10 < 8
);
create or replace table validation_data as (
SELECT * from filtered_support_tickets where ID % 10 >= 8
);
To fine-tune the language model, we need training data that includes support ticket requests and right category labels for each of them. Annotations for millions of support tickets are not readily available. So we could leverage an existing large language model to create category labels and prepare the dataset for fine-tuning.
Next step is to split the curated dataset into a training and a test set. There are two ways you can fine-tune a large language model.
- Use Snowflake Snowflake AI & ML Studio that allows you to run fine-tuning from the UI. This is currently in PrPr
- Use FINETUNE() Cortex function to run the fine-tune job using SQL queries. This is currently available in PuPr.
Fine-tuning using Snowflake AI & ML Studio
Once we have the training data, we could use Snowflake AI & ML Studio to fine-tune. Cortex AI features a no-code fine-tuning from the UI using the Create Custom LLM option.
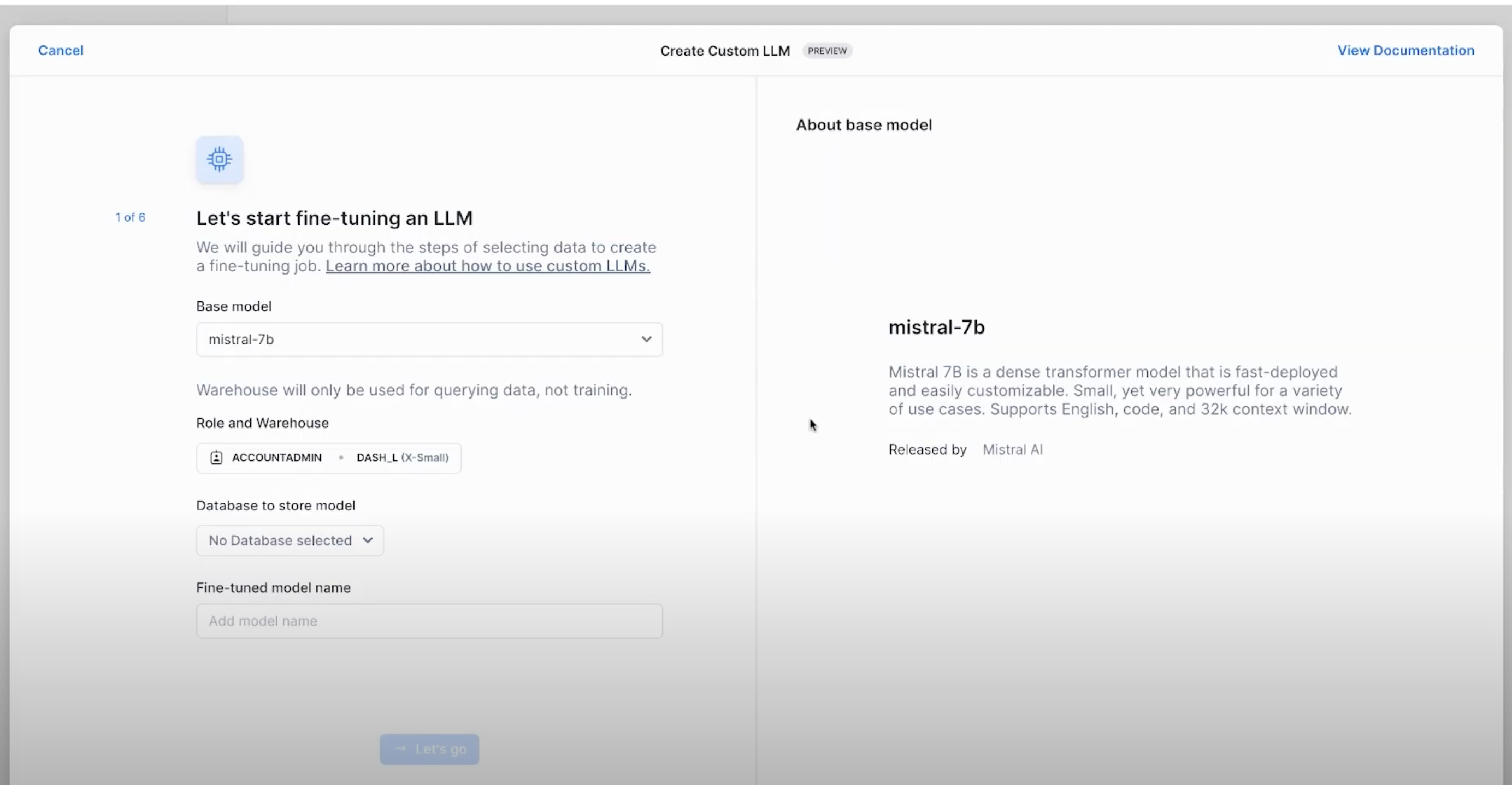
- In the wizard that appears, select the base model for fine-tuning. In this case,
llama3-8b. - Select the appropriate role and warehouse for model fine-tuning.
- Select the right database to store the fine-tuned model as well.
- Select the training data including the prompt column, and complete column
- In the end, select the validation data for Cortex to evaluate the fine-tuning process too
- Inferencing the fine-tuned model
Fine-tuning using FINETUNE() SQL API
Alternatively, you can also fine-tune the LLM using SQL API FINETUNE(). Learn more about the syntax here.
select snowflake.cortex.finetune(
'CREATE',
'DASH_DB.DASH_SCHEMA.SUPPORT_TICKETS_FINETUNED', 'llama3-8b',
'SELECT request as prompt, category as completion from DASH_DB.DASH_SCHEMA.training_data',
'SELECT request as prompt, category as completion from DASH_DB.DASH_SCHEMA.validation_data'
););
After running the above query, we can keep track of the fine-tuning job using the below command.
select snowflake.cortex.finetune('DESCRIBE', 'CortexFineTuningWorkflow_f4016e33-92ce-45d3-918a-19115c398f10');
Inferencing the Distilled Model
Once the fine-tuning is complete, we could run inference on the model by simply invoking the Cortex AI COMPLETE() with the fine-tuned model name as one of the parameters.
SET fine_tuned_model_name = 'SUPPORT_TICKETS_FINETUNED';
SELECT id, request,
TRIM(SNOWFLAKE.CORTEX.COMPLETE($fine_tuned_model_name, request), '\n') as fine_tuned_model_response
FROM validation_data;
Note that we don't need to provide our prompt template with detailed instructions anymore. The model has learned from the training data how to respond to the input without any instructions.
Automated Generation of Email Responses to support tickets using LLMs
After categorizing the support tickets into different categories based on the reason for the support request, we can also use Cortex AI to auto-generate the email/text responses to these support requests.
The following code snippet creates a nimble steamlit application in a Snowflake Notebook that you can use to iterate through the different prompts while invoking the Complete() function.
st.subheader("Auto-generate custom emails or text messages")
with st.container():
with st.expander("Edit prompt and select LLM", expanded=True):
entered_prompt = st.text_area('Prompt',"""Please write an email or text promoting a new plan that will save customers total costs. If the customer requested to be contacted by text message, write text message response in less than 25 words, otherwise write email response in maximum 100 words.""")
with st.container():
left_col,right_col = st.columns(2)
with left_col:
selected_category = st.selectbox('Select category',('Roaming fees', 'Closing account', 'Add new line', 'Slow data speed'))
with right_col:
selected_llm = st.selectbox('Select LLM',('snowflake-arctic','llama3-8b','llama3.1-405b','mistral-large', 'reka-flash',))
with st.container():
_,mid_col,_ = st.columns([.4,.3,.3])
with mid_col:
generate_template = st.button('Generate messages ⚡',type="primary")
with st.container():
if generate_template:
sql = f"""select s.ticket_id, s.customer_name, concat(IFF(s.contact_preference = 'Email', '📩', '📲'), ' ', s.contact_preference) as contact_preference, snowflake.cortex.complete('{selected_llm}',
concat('{entered_prompt}','Here is the customer information: Name: ',customer_name,', Contact preference: ', contact_preference))
as llm_response from support_tickets as s join support_tickets_train as t on s.ticket_id = t.ticket_id
where t.mistral_large_response = '{selected_category}' limit 10"""
with st.status("In progress...") as status:
df_llm_response = session.sql(sql).to_pandas()
st.subheader("LLM-generated emails and text messages")
for row in df_llm_response.itertuples():
status.caption(f"Ticket ID: `{row.TICKET_ID}`")
status.caption(f"To: {row.CUSTOMER_NAME}")
status.caption(f"Contact through: {row.CONTACT_PREFERENCE}")
status.markdown(row.LLM_RESPONSE.replace("--", ""))
status.divider()
status.update(label="Done!", state="complete", expanded=True)
Depending on the values in the contact_preference column, Cortex AI can generate text or email messages that can be used for customer support responses.
Congratulations! You've successfully generated synthetic data and distilled the knowledge from a big foundation model into a small and specialized fine-tuned model. You can use any of these supported LLMs for fine-tuning with Cortex.
What You Learned
You have learnt how to use Snowflake Cortex AI to:
- Generate Synthetic Data: Prompt
llama3.1-405bto generate synthetic customer support tickets. - Prepare: Training dataset for distilling a the knowledge from a foundation model into a small custom LLM.
- Distill: The knowledge from the large model to fine-tune model a smaller model and achieve high accuracy at fraction of cost.
- Generate: Custom email/text communications tailored to each support ticket