Ce guide va vous permettre d'essayer Snowpark for Python depuis l'interface utilisateur Snowflake. À la fin de ce guide, vous saurez comment exécuter les principales tâches de Data Engineering à l'aide de Snowpark dans une feuille de calcul Python de Snowflake.
Qu'est-ce que Snowpark ?
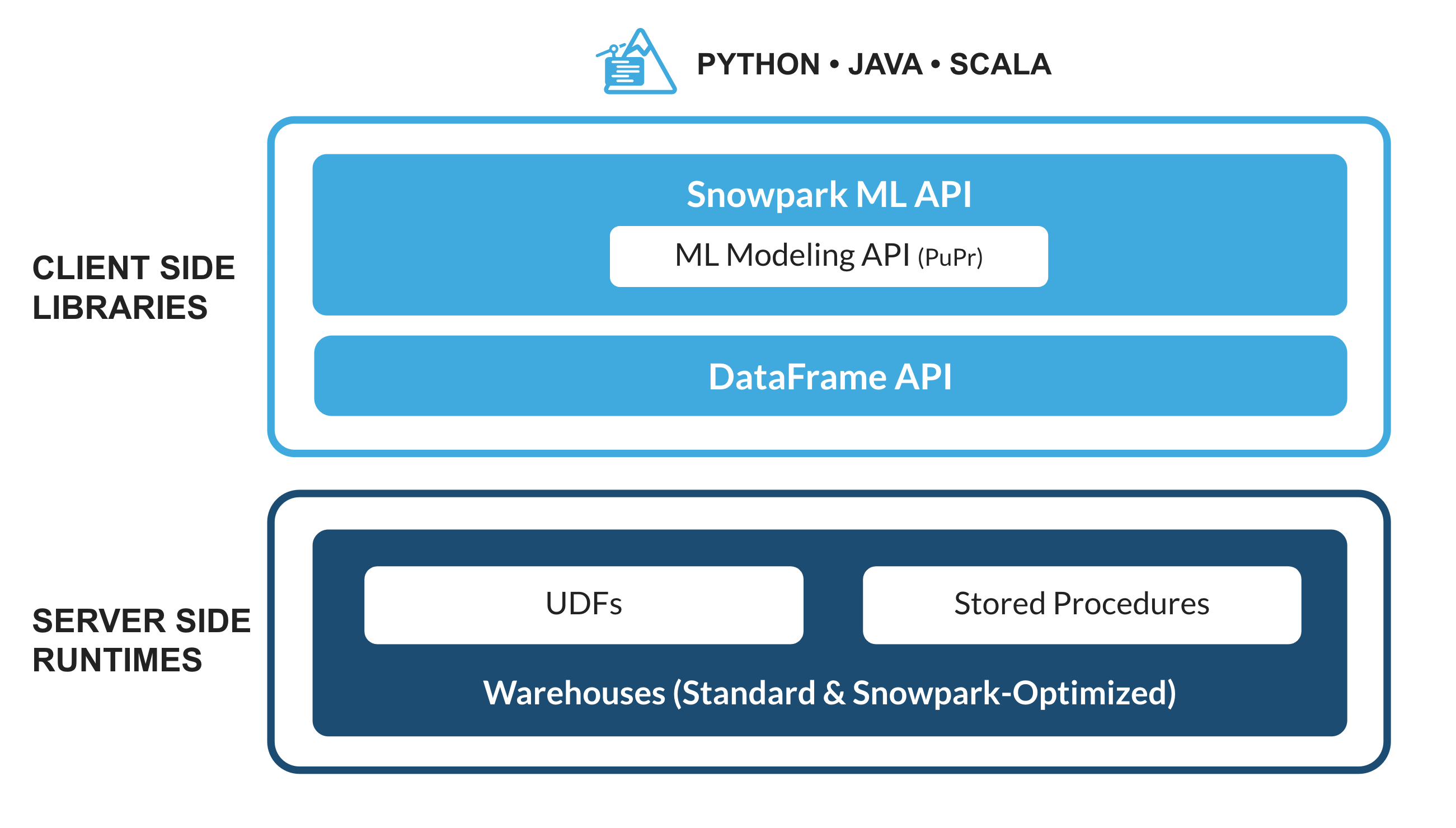
Il s'agit d'un ensemble de bibliothèques et d'environnements d'exécution dans Snowflake qui garantit un déploiement et un traitement sécurisé de tout code non-SQL (Python, Java et Scala, par exemple).
Bibliothèques familières côté client : Snowpark apporte une programmation de type DataFrame profondément intégrée et des API compatibles OSS aux langages privilégiés par les professionnels des données. Snowpark prend également en charge des API ML, dont ML Modeling (public preview) et ML Operations (private preview), qui garantissent un développement et un déploiement plus efficaces des modèles.
Constructions d'exécution flexibles : Snowpark fournit des constructions d'exécution flexibles qui permettent aux utilisateurs d'ajouter et d'exécuter une logique personnalisée. Les développeurs peuvent créer facilement des pipelines de données, des modèles de ML et des applications de données avec des fonctions définies par l'utilisateur et des procédures stockées.
Pour en savoir plus sur Snowpark, cliquez ici.
Que sont les feuilles de calcul Python ?
Les feuilles de calcul Python sont un nouveau type de feuille de calcul dans Snowsight qui vous permettent de prendre en main Snowpark plus rapidement. Les utilisateurs peuvent développer des pipelines de données, des modèles de ML et des applications directement dans Snowflake, sans avoir à déployer, configurer et tenir à jour des EDI (interface utilisateur de développement) supplémentaires pour Python. Il est également possible de convertir ces feuilles de calcul en procédures pour planifier vos applications Snowpark.
Vous allez apprendre :
- Comment charger des données de tables Snowflake dans des DataFrames Snowpark
- Comment effectuer une analyse exploratoire des données sur les DataFrames Snowpark
- Comment faire pivoter et associer les données de plusieurs tables à l'aide de DataFrames Snowpark
- Comment enregistrer les données transformées dans une table Snowflake
- Comment déployer une feuille de calcul Python en tant que procédure stockée
Vous allez créer :
Un ensemble de données préparé pouvant être utilisé dans des applications et analyses en aval. Par exemple, entraîner un modèle de machine learning.
Créer un compte d'essai Snowflake
Inscrivez-vous et profitez d'un essai gratuit de 30 jours en cliquant ici (vous serez redirigé vers la page de configuration du compte d'essai intitulée Premiers pas avec Snowpark dans les feuilles de calcul Python de Snowflake). Nous vous recommandons de choisir la région la plus proche de vous. Nous vous recommandons de choisir l'édition la plus populaire, Enterprise, mais toutes les éditions fonctionneront pour cet atelier.
Se connecter et configurer l'atelier
Connectez-vous à votre compte Snowflake. Pour accéder à cet atelier et configurer des exemples de données et de code, assurez-vous de cliquer sur le lien suivant.
Le bouton de configuration de l'environnement de l'atelier ci-dessus vous redirigera vers la page intitulée Premiers pas avec Snowpark dans les feuilles de calcul Python de Snowflake. Vous serez invité à cliquer sur Setup Lab (Configurer l'atelier). Ce processus prendra moins d'une minute et configurera des données et des exemples de code Python, et vous fournira quelques explications.
==================================================================================================

Commençons par importer la bibliothèque Snowpark Python.
# Importez Snowpark for Python
import snowflake.snowpark as snowpark
Charger les données agrégées relatives aux dépenses de campagne et aux revenus
La table des dépenses de campagne regroupe les données de clics publicitaires qui ont été rassemblées afin de montrer les dépenses quotidiennes sur tous nos canaux publicitaires numériques, y compris les moteurs de recherche, les réseaux sociaux, les e-mails et les vidéos. La table des revenus contient les données relatives aux revenus sur une période de 10 ans.
Dans cet exemple, nous allons utiliser le code suivant pour charger les données des tables campaign_spend et monthly_revenue.
snow_df_spend = session.table('campaign_spend')
snow_df_revenue = session.table('monthly_revenue')
Voici d'autres façons de charger des données dans des DataFrames Snowpark.
- session.sql("select col1, col2... from tableName")
- session.read.options({"field_delimiter": ",", "skip_header": 1}).schema(user_schema).csv("@mystage/testCSV.csv")
- session.read.parquet("@stageName/path/to/file")
- session.create_dataframe([1,2,3], schema=["col1"])
CONSEIL : pour en savoir plus sur les DataFrames Snowpark, cliquez ici.
Dans cette section, nous allons effectuer un ensemble de transformations (agrégation et association de deux dataframes, par exemple).
Commençons par importer toutes les fonctions dont nous allons avoir besoin.
from snowflake.snowpark.functions import month,year,col,sum
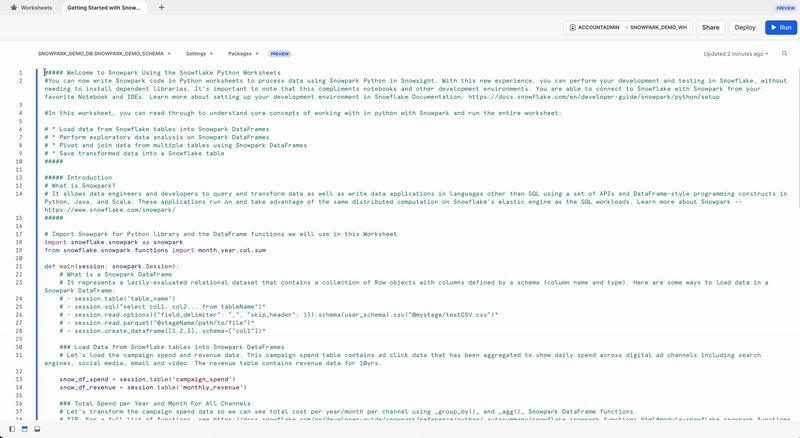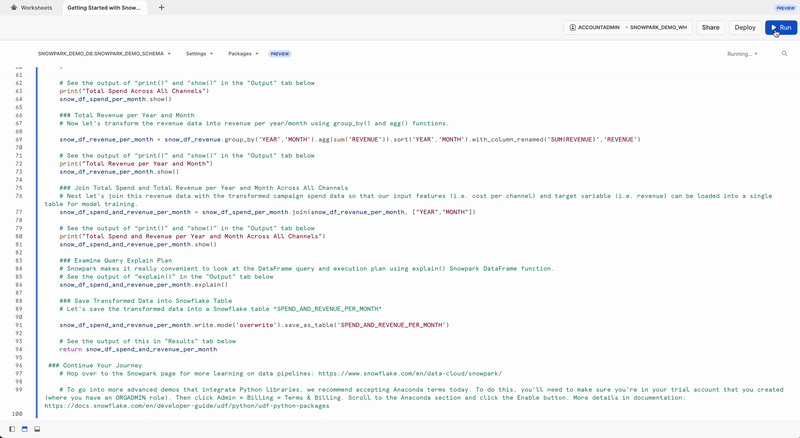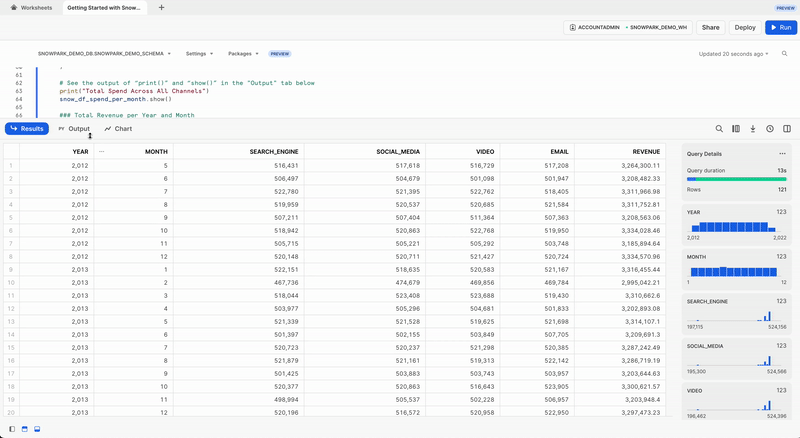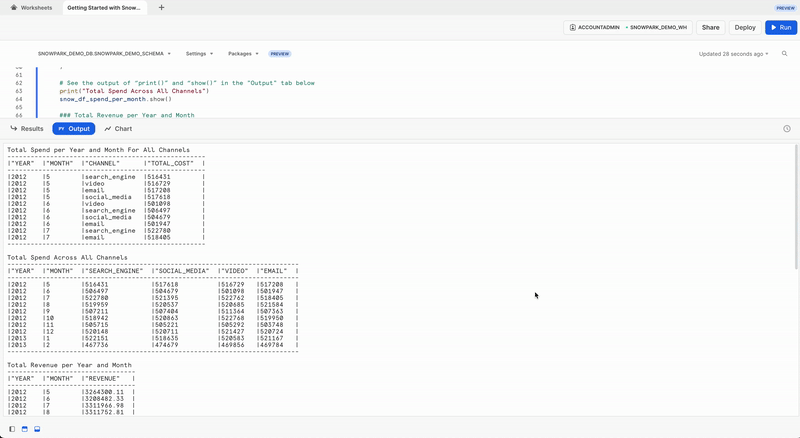
Dépenses totales par an et par mois pour tous les canaux
Transformons les données pour voir le coût total par an/mois par canal à l'aide des fonctions DataFrame Snowpark group_by() et agg().
snow_df_spend_per_channel = snow_df_spend.group_by(year('DATE'), month('DATE'),'CHANNEL').agg(sum('TOTAL_COST').as_('TOTAL_COST')).with_column_renamed('"YEAR(DATE)"',"YEAR").with_column_renamed('"MONTH(DATE)"',"MONTH").sort('YEAR','MONTH')
CONSEIL : pour voir la liste complète des fonctions, cliquez ici.
Afin de voir le résultat de cette transformation, nous pouvons utiliser la fonction DataFrame Snowpark show(), qui affichera la sortie sous l'onglet Output (Sortie).
print("Total Spend per Year and Month For All Channels")
snow_df_spend_per_channel.show()
Dépenses totales sur tous les canaux
Transformons encore davantage les données relatives aux dépenses de campagne afin que chaque ligne représente le coût total par an/mois sur tous les canaux à l'aide des fonctions DataFrame Snowpark pivot() et sum().
Cette transformation nous permettra d'associer ces données à la table des revenus. Ainsi, nos fonctionnalités d'entrée et notre variable cible figureront dans une seule table à des fins d'entraînement de modèles.
snow_df_spend_per_month = snow_df_spend_per_channel.pivot('CHANNEL',['search_engine','social_media','video','email']).sum('TOTAL_COST').sort('YEAR','MONTH')
snow_df_spend_per_month = snow_df_spend_per_month.select(
col("YEAR"),
col("MONTH"),
col("'search_engine'").as_("SEARCH_ENGINE"),
col("'social_media'").as_("SOCIAL_MEDIA"),
col("'video'").as_("VIDEO"),
col("'email'").as_("EMAIL")
)
Afin de voir le résultat de cette transformation, nous pouvons utiliser la fonction DataFrame Snowpark show(), qui affichera la sortie sous l'onglet Output (Sortie).
print("Total Spend Across All Channels")
snow_df_spend_per_month.show()
Données relatives aux revenus totaux par an et par mois
Transformons les données relatives aux revenus en revenus par an/mois à l'aide des fonctions group_by() et agg().
snow_df_revenue_per_month = snow_df_revenue.group_by('YEAR','MONTH').agg(sum('REVENUE')).sort('YEAR','MONTH').with_column_renamed('SUM(REVENUE)','REVENUE')
Afin de voir le résultat de cette transformation, nous pouvons utiliser la fonction DataFrame Snowpark show(), qui affichera la sortie sous l'onglet Output (Sortie).
print("Total Revenue per Year and Month")
snow_df_revenue_per_month.show()
Associer les dépenses totales et les revenus totaux par an et par mois sur tous les canaux
Associons ensuite les données relatives aux revenus aux données transformées des dépenses de campagne pour pouvoir charger nos fonctionnalités d'entrée (coût par canal, par exemple) et notre variable cible (revenus, par exemple) dans une seule et même table à des fins d'analyse ultérieure et d'entraînement de modèles.
snow_df_spend_and_revenue_per_month = snow_df_spend_per_month.join(snow_df_revenue_per_month, ["YEAR","MONTH"])
Afin de voir le résultat de cette transformation, nous pouvons utiliser la fonction DataFrame Snowpark show(), qui affichera la sortie sous l'onglet Output (Sortie).
print("Total Spend and Revenue per Year and Month Across All Channels")
snow_df_spend_and_revenue_per_month.show()
Examiner la requête et expliquer le plan
Snowpark permet d'examiner facilement la requête DataFrame et le plan d'exécution à l'aide de la fonction DataFrame Snowpark explain().
snow_df_spend_and_revenue_per_month.explain()
La sortie de l'instruction ci-dessus figure dans l'onglet Output (Sortie).
Onglet Output (Sortie)
Voici à quoi ressemble l'onglet Output (Sortie) une fois la feuille de calcul exécutée.
Enregistrons les données transformées dans une table Snowflake SPEND_AND_REVENUE_PER_MONTH pour pouvoir les utiliser ultérieurement à des fins d'analyse et/ou pour l'entraînement d'un modèle.
snow_df_spend_and_revenue_per_month.write.mode('overwrite').save_as_table('SPEND_AND_REVENUE_PER_MONTH')
L'une des valeurs de retour d'une feuille de calcul Python est de type Table(). Dans notre cas, cela vous permet d'afficher et de renvoyer les données transformées en tant que DataFrame Snowpark.
return snow_df_spend_and_revenue_per_month
La sortie de l'instruction ci-dessus figure dans l'onglet Results (Résultats), comme illustré ci-dessous.
Onglet Results (Résultats)
Voici à quoi ressemble l'onglet Results (Résultats) une fois la feuille de calcul exécutée.
Vous pouvez également déployer cette feuille de calcul en tant que procédure stockée Python pour pouvoir la planifier à l'aide de Snowflake Tasks, par exemple. Pour déployer cette feuille de calcul, cliquez sur le bouton Deploy (Déployer) dans le coin supérieur droit, puis suivez les instructions comme illustré ci-dessous.
==================================================================================================
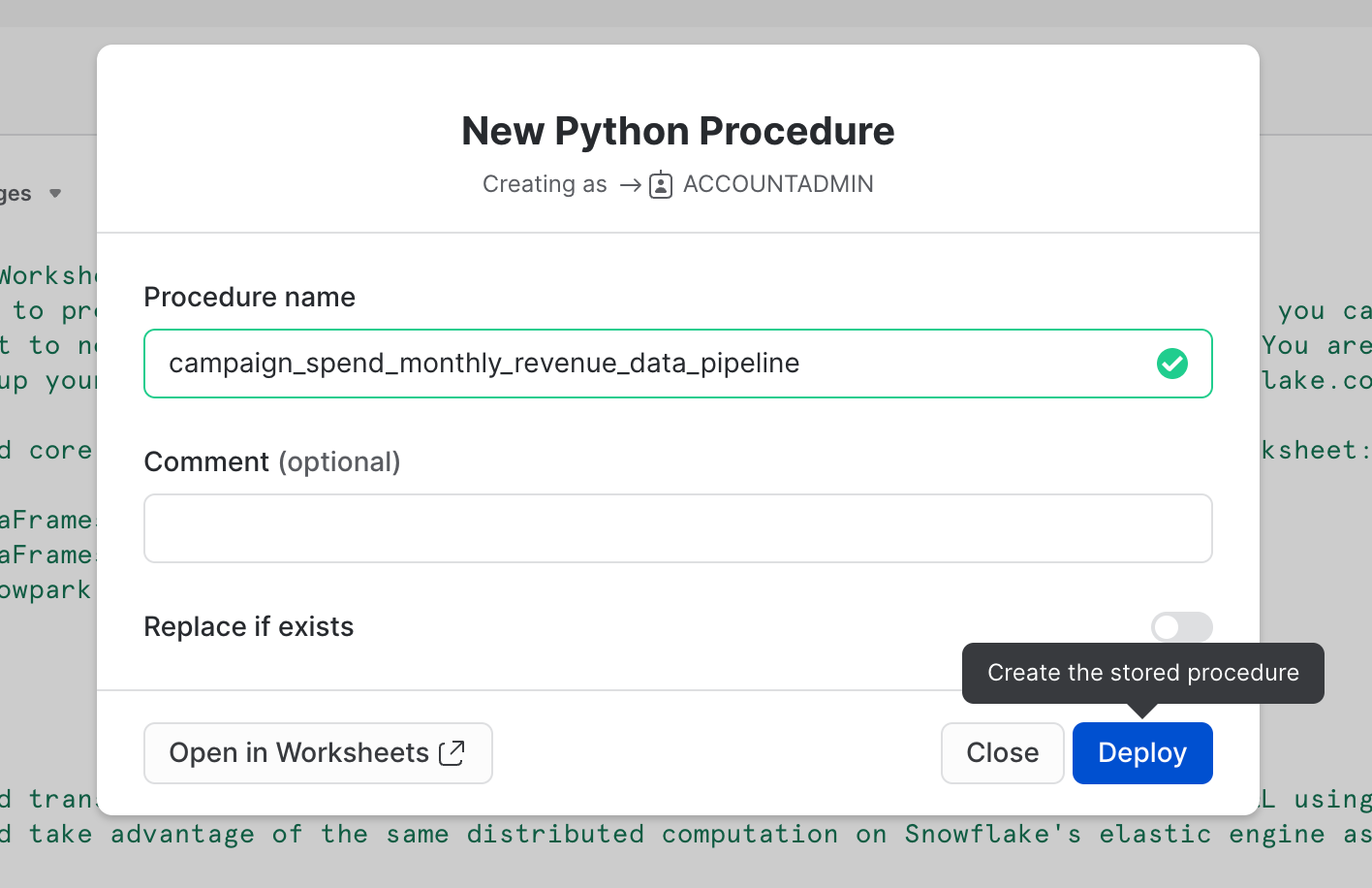
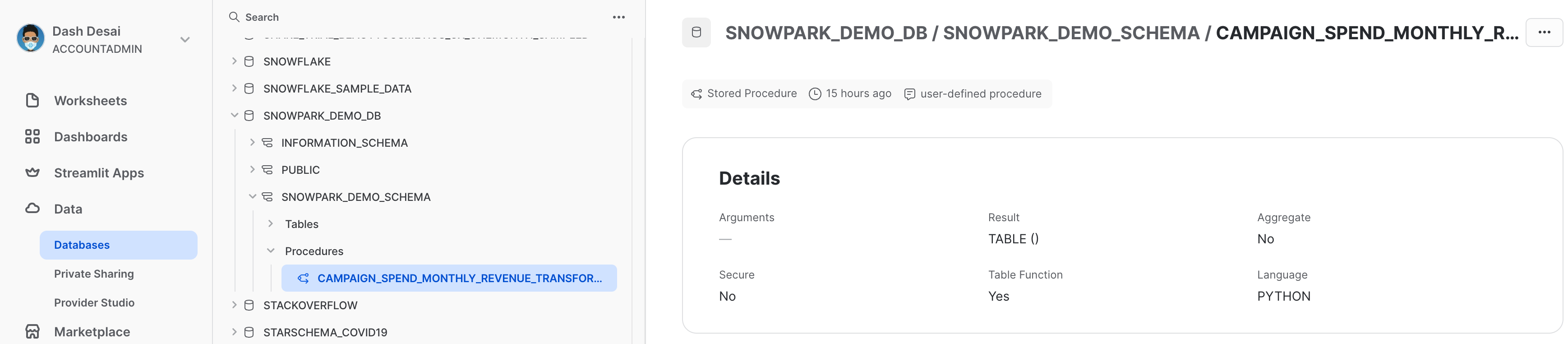
Afficher une procédure stockée
Une fois le déploiement terminé, les détails de la procédure stockée sont disponibles sous Data » Databases » SNOWPARK_DEMO_SCHEMA » Procedures (Données » Bases de données » SNOWPARK_DEMO_2SCHEMA » Procédures).
Félicitations ! Vous avez réalisé les tâches de Data Engineering à l'aide de Snowpark dans des feuilles de calcul Python de Snowflake.
N'hésitez pas à nous faire part de vos commentaires sur ce guide Quickstart ! Envoyez-nous vos commentaires à l'aide de ce formulaire de commentaires.
Vous avez appris :
- Comment charger des données de tables Snowflake dans des DataFrames Snowpark
- Comment effectuer une analyse exploratoire des données sur les DataFrames Snowpark
- Comment faire pivoter et associer les données de plusieurs tables à l'aide de DataFrames Snowpark
- Comment enregistrer les données transformées dans une table Snowflake
- Comment déployer une feuille de calcul Python en tant que procédure stockée
Prochaines étapes
Pour découvrir comme traiter des données de manière incrémentielle, orchestrer des pipelines de données à l'aide de tâches Snowflake Tasks, les déployer via un pipeline CI/CD et utiliser le nouvel outil CLI de Snowflake destiné aux développeurs ainsi que l'extension Visual Studio Code, consultez le guide Quickstart Pipelines de Data Engineering avec Snowpark Python.