This guide provides the instructions for building a Streamlit application using Snowpark for Python and data from the Snowflake Marketplace.
What You Will Build
A Streamlit application that loads and visualizes daily stock performance and foreign exchange (FX) rate data loaded from the Snowflake Marketplace using Snowpark for Python.
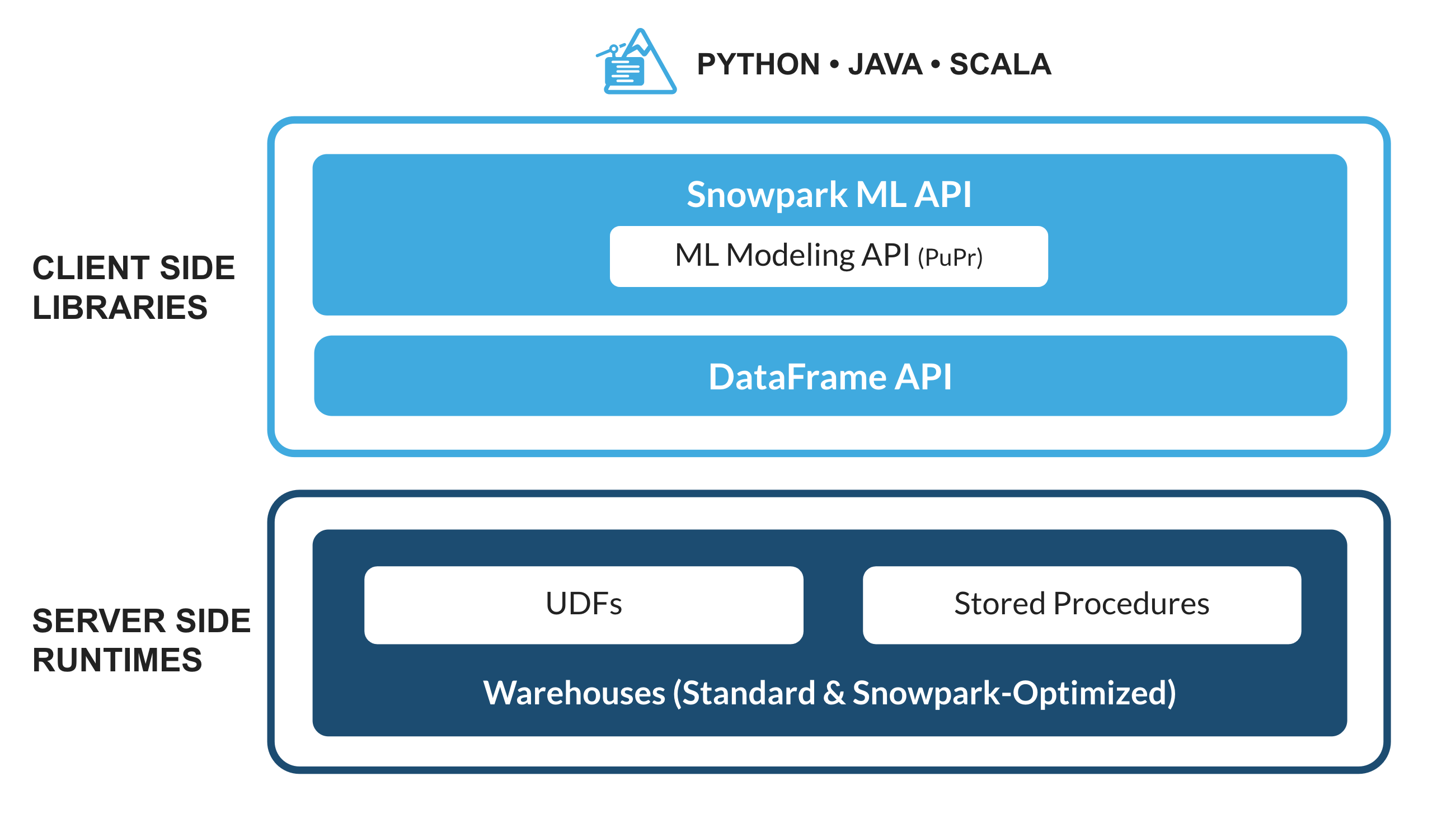
What is Snowpark?
The set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java and Scala.
Familiar Client Side Libraries - Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use. It also includes the Snowpark ML API for more efficient ML modeling (public preview) and ML operations (private preview).
Flexible Runtime Constructs - Snowpark provides flexible runtime constructs that allow users to bring in and run custom logic. Developers can seamlessly build data pipelines, ML models, and data applications with User-Defined Functions and Stored Procedures.
Learn more about Snowpark.
What is Streamlit?
Streamlit enables data scientists and Python developers to combine Streamlit's component-rich, open-source Python library with the scale, performance, and security of the Snowflake platform.
Learn more about Streamlit.
What You Will Learn
- How to access current Session object in Streamlit
- How to load data from the Snowflake Marketplace
- How to create Snowpark DataFrames and perform transformations
- How to create and display interactive charts in Streamlit
- How to run Streamlit in Snowflake
Prerequisites
- A Snowflake account
- Access to the Snowflake Public Data (Free) dataset
- In the Snowflake Marketplace, click on Get Data and follow the instructions to gain access. In particular, we will use data from tables STOCK_PRICE_TIMESERIES and FX_RATES_TIMESERIES.
Follow these steps to start building Streamlit application in Snowsight.
Step 1. Click on Streamlit on the left navigation menu
Step 2. Click on + Streamlit App on the top right
Step 3. Enter App name
Step 4. Select Warehouse (X-Small) and App location (Database and Schema) where you'd like to create the Streamlit applicaton
Step 5. Click on Create
- At this point, you will be provided code for an example Streamlit application
Step 6. Replace sample application code displayed in the code editor on the left by following instructions in the subsequent steps
Delete existing sample application code in the code editor on the left and add the following code snippet at the very top.
# Import libraries
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.functions import sum, col, when, max, lag
from snowflake.snowpark import Window
from datetime import timedelta
import altair as alt
import streamlit as st
import pandas as pd
# Set page config
st.set_page_config(layout="wide")
# Get current session
session = get_active_session()
In the above code snippet, we're importing the required libraries, setting the application's page config to use full width of the browser window, and gaining access to the current session.
Now add the following Python function that loads and caches data from the SNOWFLAKE_PUBLIC_DATA_FREE.PUBLIC_DATA_FREE.STOCK_PRICE_TIMESERIES and SNOWFLAKE_PUBLIC_DATA_FREE.PUBLIC_DATA_FREE.FX_RATES_TIMESERIES tables.
@st.cache_data()
def load_data():
# Load and transform daily stock price data.
snow_df_stocks = (
session.table("SNOWFLAKE_PUBLIC_DATA_FREE.PUBLIC_DATA_FREE.STOCK_PRICE_TIMESERIES")
.filter(
(col('TICKER').isin('AAPL', 'MSFT', 'AMZN', 'GOOGL', 'META', 'TSLA', 'NVDA')) &
(col('VARIABLE_NAME').isin('Nasdaq Volume', 'Post-Market Close')))
.groupBy("TICKER", "DATE")
.agg(
max(when(col("VARIABLE_NAME") == "Nasdaq Volume", col("VALUE"))).alias("NASDAQ_VOLUME"),
max(when(col("VARIABLE_NAME") == "Post-Market Close", col("VALUE"))).alias("POSTMARKET_CLOSE")
)
)
# Adding the Day over Day Post-market Close Change calculation
window_spec = Window.partitionBy("TICKER").orderBy("DATE")
snow_df_stocks_transformed = snow_df_stocks.withColumn("DAY_OVER_DAY_CHANGE",
(col("POSTMARKET_CLOSE") - lag(col("POSTMARKET_CLOSE"), 1).over(window_spec)) /
lag(col("POSTMARKET_CLOSE"), 1).over(window_spec)
)
# Load foreign exchange (FX) rates data.
snow_df_fx = session.table("SNOWFLAKE_PUBLIC_DATA_FREE.PUBLIC_DATA_FREE.FX_RATES_TIMESERIES").filter(
(col('BASE_CURRENCY_ID') == 'EUR') & (col('DATE') >= '2019-01-01')).with_column_renamed('VARIABLE_NAME','EXCHANGE_RATE')
return snow_df_stocks_transformed.to_pandas(), snow_df_fx.to_pandas()
# Load and cache data
df_stocks, df_fx = load_data()
In the above code snippet, we're leveraging several Snowpark DataFrame functions to load and transform data. For example, filter(), group_by(), agg(), sum(), alias() and isin().
Now add the following Python function that displays daily stock performance. Create selection dropdowns for date, stock ticker, and metric to be visualized.
def stock_prices():
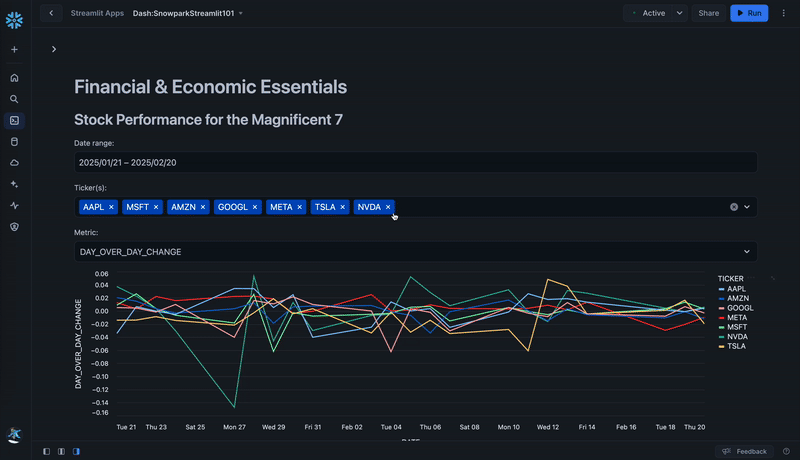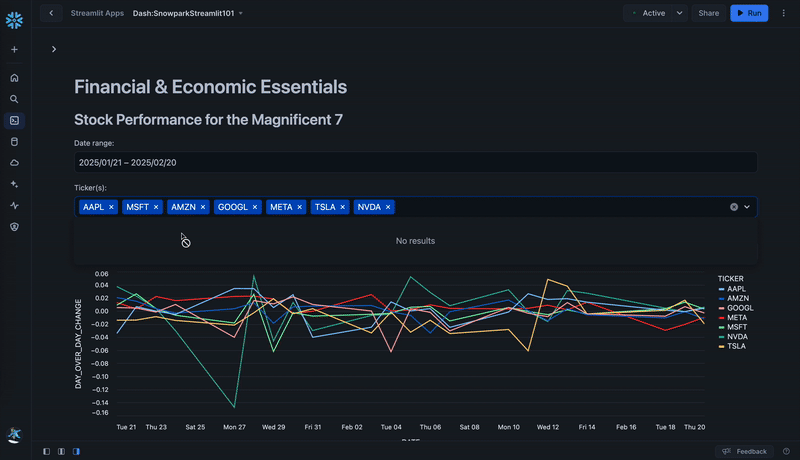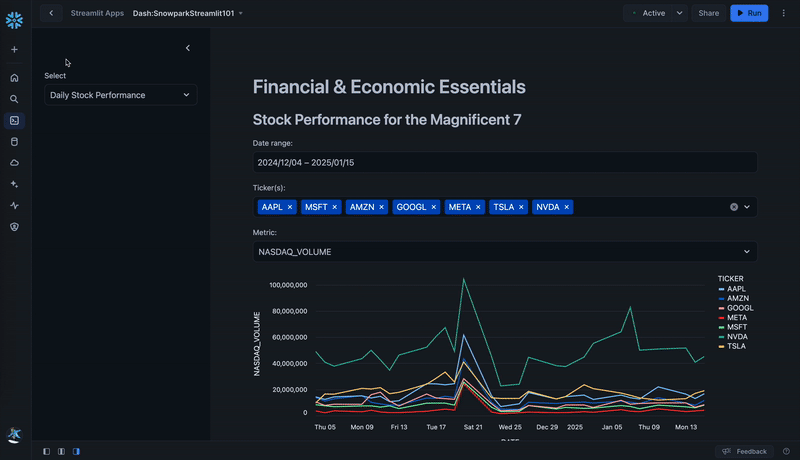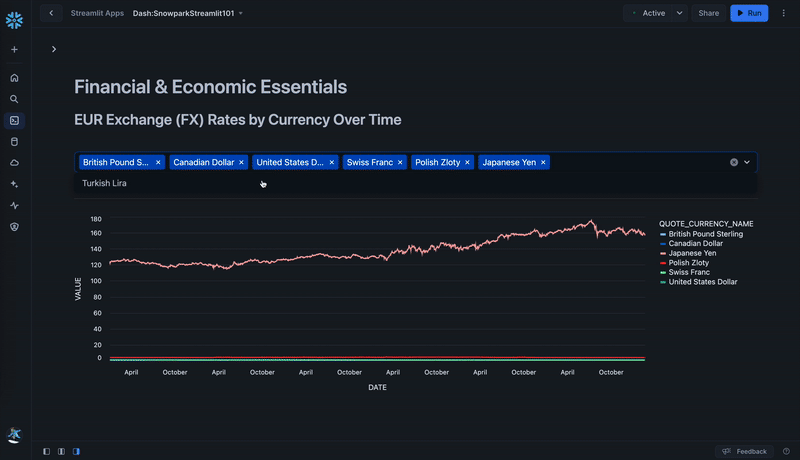
st.subheader('Stock Performance on the Nasdaq for the Magnificent 7')
df_stocks['DATE'] = pd.to_datetime(df_stocks['DATE'])
max_date = df_stocks['DATE'].max() # Most recent date
min_date = df_stocks['DATE'].min() # Earliest date
# Default start date as 30 days before the most recent date
default_start_date = max_date - timedelta(days=30)
# Use the adjusted default start date in the 'date_input' widget
start_date, end_date = st.date_input("Date range:", [default_start_date, max_date], min_value=min_date, max_value=max_date, key='date_range')
start_date_ts = pd.to_datetime(start_date)
end_date_ts = pd.to_datetime(end_date)
# Filter DataFrame based on the selected date range
df_filtered = df_stocks[(df_stocks['DATE'] >= start_date_ts) & (df_stocks['DATE'] <= end_date_ts)]
# Ticker filter with multi-selection and default values
unique_tickers = df_filtered['TICKER'].unique().tolist()
default_tickers = [ticker for ticker in ['AAPL', 'MSFT', 'AMZN', 'GOOGL', 'META', 'TSLA', 'NVDA'] if ticker in unique_tickers]
selected_tickers = st.multiselect('Ticker(s):', unique_tickers, default=default_tickers)
df_filtered = df_filtered[df_filtered['TICKER'].isin(selected_tickers)]
# Metric selection
metric = st.selectbox('Metric:',('DAY_OVER_DAY_CHANGE','POSTMARKET_CLOSE','NASDAQ_VOLUME'), index=0) # Default to DAY_OVER_DAY_CHANGE
# Generate and display line chart for selected ticker(s) and metric
line_chart = alt.Chart(df_filtered).mark_line().encode(
x='DATE',
y=alt.Y(metric, title=metric),
color='TICKER',
tooltip=['TICKER','DATE',metric]
).interactive()
st.altair_chart(line_chart, use_container_width=True)
In the above code snippet, a line chart is constructed which takes a dataframe as one of the parameters. In our case, that is a subset of the df_stocks dataframe filtered by ticker, date, and metric using Streamlit's built in components. This enhances the customizability of the visualization.
Next, add the following Python function that displays a currency selection dropdown and a chart to visualize euro exchange rates over time for the selected quote currencies.
def fx_rates():
st.subheader('EUR Exchange (FX) Rates by Currency Over Time')
# GBP, CAD, USD, JPY, PLN, TRY, CHF
currencies = ['British Pound Sterling','Canadian Dollar','United States Dollar','Japanese Yen','Polish Zloty','Turkish Lira','Swiss Franc']
selected_currencies = st.multiselect('', currencies, default = ['British Pound Sterling','Canadian Dollar','United States Dollar','Swiss Franc','Polish Zloty'])
st.markdown("___")
# Display an interactive chart to visualize exchange rates over time by the selected currencies
with st.container():
currencies_list = currencies if len(selected_currencies) == 0 else selected_currencies
df_fx_filtered = df_fx[df_fx['QUOTE_CURRENCY_NAME'].isin(currencies_list)]
line_chart = alt.Chart(df_fx_filtered).mark_line(
color="lightblue",
line=True,
).encode(
x='DATE',
y='VALUE',
color='QUOTE_CURRENCY_NAME',
tooltip=['QUOTE_CURRENCY_NAME','DATE','VALUE']
)
st.altair_chart(line_chart, use_container_width=True)
In the above code snippet, a line chart is constructed which takes a dataframe as one of the parameters. In our case, that is a subset of the df_fx dataframe filtered by the currencies selected via Streamlit's multiselect() user input component.
Add the following code snippet to display application header, create a sidebar, and map stock_prices() and fx_rates() functions to Daily Stock Performance and Exchange (FX) Rates options respectively in the sidebar.
# Display header
st.header("Financial & Economic Essentials")
# Create sidebar and load the first page
page_names_to_funcs = {
"Daily Stock Performance": stock_prices,
"Exchange (FX) Rates": fx_rates
}
selected_page = st.sidebar.selectbox("Select", page_names_to_funcs.keys())
page_names_to_funcs[selected_page]()
The fun part! Assuming your code is free of syntax and other errors, you're ready to run the Streamlit application.
Code
Here's what the entire application code should look like.
# Import libraries
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.functions import sum, col, when, max, lag
from snowflake.snowpark import Window
from datetime import timedelta
import altair as alt
import streamlit as st
import pandas as pd
# Set page config
st.set_page_config(layout="wide")
# Get current session
session = get_active_session()
@st.cache_data()
def load_data():
# Load and transform daily stock price data.
snow_df_stocks = (
session.table("SNOWFLAKE_PUBLIC_DATA_FREE.PUBLIC_DATA_FREE.STOCK_PRICE_TIMESERIES")
.filter(
(col('TICKER').isin('AAPL', 'MSFT', 'AMZN', 'GOOGL', 'META', 'TSLA', 'NVDA')) &
(col('VARIABLE_NAME').isin('Nasdaq Volume', 'Post-Market Close')))
.groupBy("TICKER", "DATE")
.agg(
max(when(col("VARIABLE_NAME") == "Nasdaq Volume", col("VALUE"))).alias("NASDAQ_VOLUME"),
max(when(col("VARIABLE_NAME") == "Post-Market Close", col("VALUE"))).alias("POSTMARKET_CLOSE")
)
)
# Adding the Day over Day Post-market Close Change calculation
window_spec = Window.partitionBy("TICKER").orderBy("DATE")
snow_df_stocks_transformed = snow_df_stocks.withColumn("DAY_OVER_DAY_CHANGE",
(col("POSTMARKET_CLOSE") - lag(col("POSTMARKET_CLOSE"), 1).over(window_spec)) /
lag(col("POSTMARKET_CLOSE"), 1).over(window_spec)
)
# Load foreign exchange (FX) rates data.
snow_df_fx = session.table("SNOWFLAKE_PUBLIC_DATA_FREE.PUBLIC_DATA_FREE.FX_RATES_TIMESERIES").filter(
(col('BASE_CURRENCY_ID') == 'EUR') & (col('DATE') >= '2019-01-01')).with_column_renamed('VARIABLE_NAME','EXCHANGE_RATE')
return snow_df_stocks_transformed.to_pandas(), snow_df_fx.to_pandas()
# Load and cache data
df_stocks, df_fx = load_data()
def stock_prices():
st.subheader('Stock Performance for the Magnificent 7')
df_stocks['DATE'] = pd.to_datetime(df_stocks['DATE'])
max_date = df_stocks['DATE'].max() # Most recent date
min_date = df_stocks['DATE'].min() # Earliest date
# Default start date as 30 days before the most recent date
default_start_date = max_date - timedelta(days=30)
# Use the adjusted default start date in the 'date_input' widget
start_date, end_date = st.date_input("Date range:", [default_start_date, max_date], min_value=min_date, max_value=max_date, key='date_range')
start_date_ts = pd.to_datetime(start_date)
end_date_ts = pd.to_datetime(end_date)
# Filter DataFrame based on the selected date range
df_filtered = df_stocks[(df_stocks['DATE'] >= start_date_ts) & (df_stocks['DATE'] <= end_date_ts)]
# Ticker filter with multi-selection and default values
unique_tickers = df_filtered['TICKER'].unique().tolist()
default_tickers = [ticker for ticker in ['AAPL', 'MSFT', 'AMZN', 'GOOGL', 'META', 'TSLA', 'NVDA'] if ticker in unique_tickers]
selected_tickers = st.multiselect('Ticker(s):', unique_tickers, default=default_tickers)
df_filtered = df_filtered[df_filtered['TICKER'].isin(selected_tickers)]
# Metric selection
metric = st.selectbox('Metric:',('DAY_OVER_DAY_CHANGE','POSTMARKET_CLOSE','NASDAQ_VOLUME'), index=0) # Default to DAY_OVER_DAY_CHANGE
# Generate and display line chart for selected ticker(s) and metric
line_chart = alt.Chart(df_filtered).mark_line().encode(
x='DATE',
y=alt.Y(metric, title=metric),
color='TICKER',
tooltip=['TICKER','DATE',metric]
).interactive()
st.altair_chart(line_chart, use_container_width=True)
def fx_rates():
st.subheader('EUR Exchange (FX) Rates by Currency Over Time')
# GBP, CAD, USD, JPY, PLN, TRY, CHF
currencies = ['British Pound Sterling','Canadian Dollar','United States Dollar','Japanese Yen','Polish Zloty','Turkish Lira','Swiss Franc']
selected_currencies = st.multiselect('', currencies, default = ['British Pound Sterling','Canadian Dollar','United States Dollar','Swiss Franc','Polish Zloty'])
st.markdown("___")
# Display an interactive chart to visualize exchange rates over time by the selected currencies
with st.container():
currencies_list = currencies if len(selected_currencies) == 0 else selected_currencies
df_fx_filtered = df_fx[df_fx['QUOTE_CURRENCY_NAME'].isin(currencies_list)]
line_chart = alt.Chart(df_fx_filtered).mark_line(
color="lightblue",
line=True,
).encode(
x='DATE',
y='VALUE',
color='QUOTE_CURRENCY_NAME',
tooltip=['QUOTE_CURRENCY_NAME','DATE','VALUE']
)
st.altair_chart(line_chart, use_container_width=True)
# Display header
st.header("Finance & Economics")
# Create sidebar and load the first page
page_names_to_funcs = {
"Daily Stock Performance": stock_prices,
"Exchange (FX) Rates": fx_rates
}
selected_page = st.sidebar.selectbox("Select", page_names_to_funcs.keys())
page_names_to_funcs[selected_page]()
Run
To run the application, click on Run button located at the top right corner. If all goes well, you should see the application running as shown below.
In the application:
- Select Daily Stock Performance Data or Exchange (FX) Rates option from the sidebar.
- Select or unselect currencies to visualize euro exchange rates over time for select currencies.
- Select a different stock price metric and date range to visualize additional metrics for stock performance evaluation.
Congratulations! You've successfully completed the Getting Started with Snowpark for Python and Streamlit with data from the Snowflake Marketplace.
What You Learned
- How to access current Session object in Streamlit
- How to load data from the Snowflake Marketplace
- How to create Snowpark DataFrames and perform transformations
- How to create and display interactive charts in Streamlit
- How to run Streamlit in Snowflake