Snowflakeへようこそデータベースおよびデータウェアハウスの管理者およびアーキテクト向けに作成されたこのエントリーレベルガイドでは、Snowflakeインターフェイスの操作方法について説明すると共に、Snowflakeのコア機能をいくつかご紹介します。Snowflakeの30日間の無料トライアルに登録し、このラボ演習を進めてください。基本事項を学習したら、自社のデータを処理したり、Snowflakeのより高度な機能をプロのように使いこなしたりできるようになります。
無料のバーチャルハンズオンラボ
このSnowflakeガイドは、インストラクター主導の無料のバーチャルハンズオンラボとしてご利用いただけます。今すぐVHOLに登録してください。
前提条件:
- Snowflakeの30日間無料トライアル環境の使用
- SQL、データベース構想、オブジェクトについての基本知識
- CSVカンマ区切りのファイルおよびJSON半構造化データに精通していること
学習する内容:
- ステージ、データベース、テーブル、ビュー、仮想ウェアハウスの作成方法。
- 構造化データおよび半構造化データのロード方法。
- テーブル間の結合を含む、Snowflake内のデータに対する分析クエリの実行方法。
- オブジェクトのクローン方法。
- タイムトラベルを使用してユーザーエラーを元に戻す方法。
- ロールおよびユーザーを作成し、権限を付与する方法。
- 他のアカウントと安全かつ簡単にデータを共有する方法。
- Snowflakeマーケットプレイスでデータセットを利用する方法。
まだSnowflakeの30日間無料トライアルに登録していない方は、登録してください。このラボの残りのセクションでは、トライアルに登録することによって作成した新しいSnowflakeアカウントの使用を前提としています。
このラボで使用するSnowflakeエディション(標準、エンタープライズ、ビジネスクリティカルなど)、クラウドプロバイダー(AWS、Azure、GCP)、リージョン(米国東部、EUなど)は、どれでも構いません。ただし、物理的に最も近いリージョンを選択し、Snowflakeエディションとして最も人気のあるエンタープライズを選択することをお勧めします。
登録後、アクティベーションリンクとSnowflakeアカウントにアクセスするためのURLが記載されたメールが届きます。
Snowflakeユーザーインターフェイス(UI)へのログイン
ブラウザウィンドウを開き、登録メールと合わせて送信されたSnowflakeの30日間トライアル環境のURLを入力します。
以下のログインダイアログが表示されます。登録時に指定したユーザー名とパスワードを入力します。
Snowflake UIを実際に操作してみる
Snowflakeの使い方に慣れていきましょう。このセクションでは、ユーザーインターフェイスの基本コンポーネントについて説明します。左側の余白を上から下へ見ていきましょう。
ワークシート
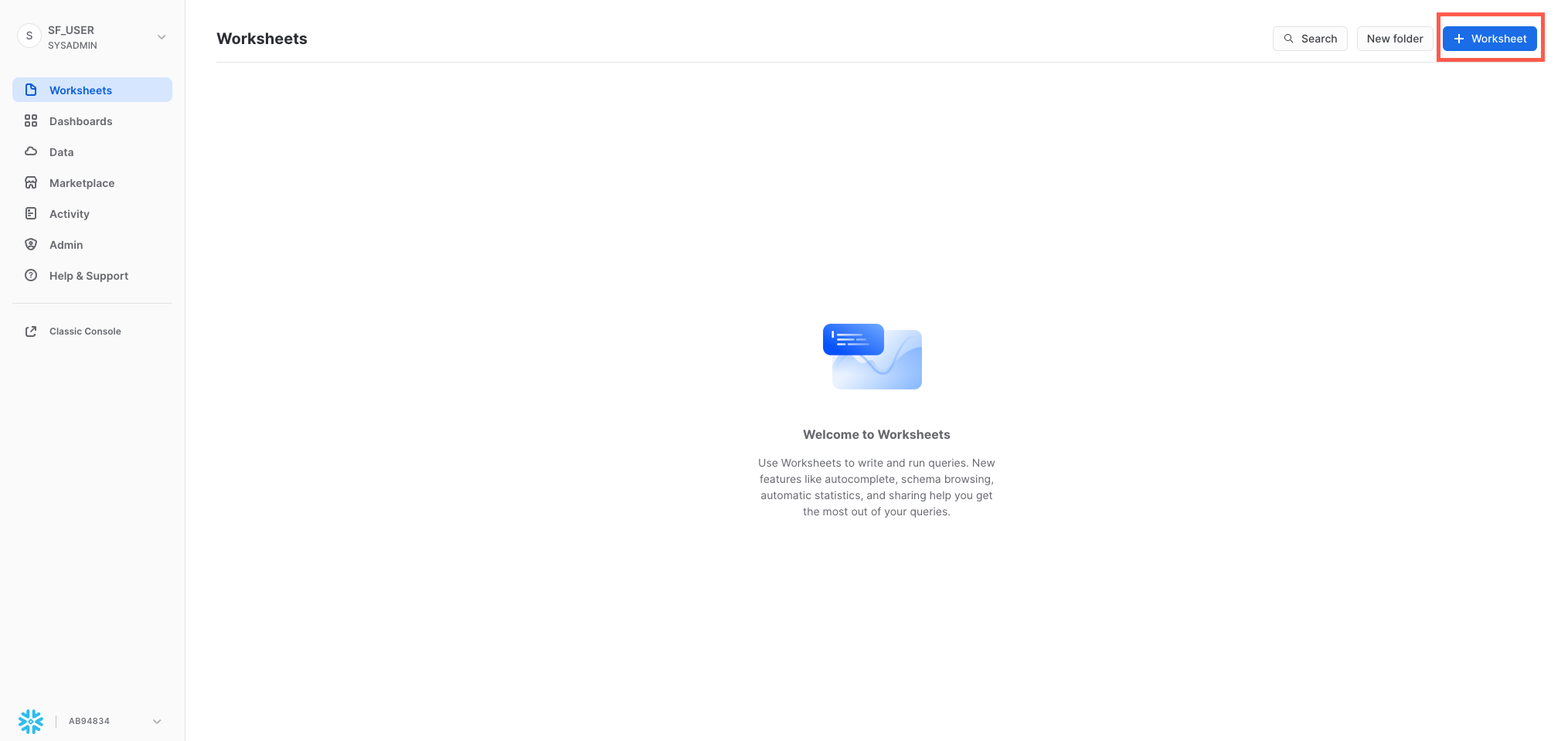
「ワークシート」タブには、SQLクエリの送信、DDLおよびDML操作の実行、クエリまたは操作の完了時の結果表示のためのインターフェイスが用意されています。新規ワークシートは、右上の「+ワークシート」をクリックして作成します。
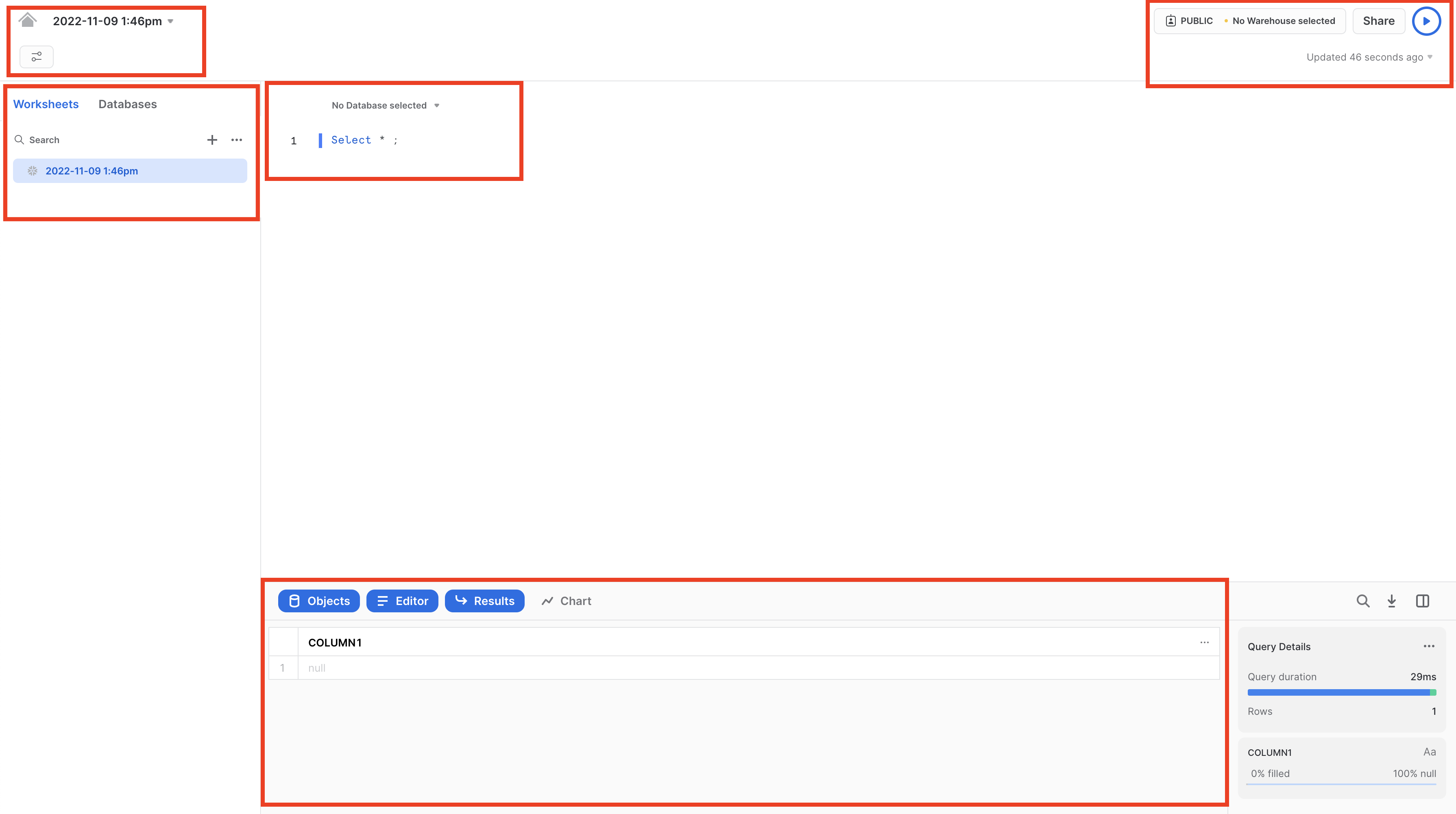
左上には次の項目があります。
- ホームアイコン:メインコンソールに戻ったり、ワークシートを閉じたりするときに使用します。
- Worksheet_nameドロップダウン:デフォルトの名前は、ワークシート作成時のタイムスタンプとなります。ワークシート名を編集するには、タイムスタンプをクリックしてください。ドロップダウンには、ワークシートに対して実行できる追加の操作も表示されます。
- 「**フィルターの管理」**ボタン:カスタムフィルターは、サブクエリまたは値のリストとして解決される特別なキーワードです。
右上には次の項目があります。
- 「**コンテキスト」**ボックス:これにより、Snowflakeがこのセッションで使用するロールとウェアハウスを把握できます。UIまたはSQLコマンドで変更できます。
- 「**共有」**ボタン:共有メニューを開いて他のユーザーに共有するか、ワークシートへリンクをコピーします。
- 「再生/実行」ボタン:現在カーソルを合わせているSQLステートメント、または選択された複数のSQLステートメントを実行します。
中央のペインには次の項目があります。
- 上部にある、ワークシートのデータベース/スキーマ/オブジェクトコンテキストを設定するためのドロップダウン。
- クエリおよびその他のSQLステートメントを入力および実行する一般的な作業領域。
中段左のパネルには次の項目があります。
- 「ワークシート」タブ:このタブを使用すると、異なるワークシートを素早く選択して切り替えることができます。
- 「データベース」タブ:このタブを使用すると、現在のロールが使用できるすべてのデータベースオブジェクトを確認できます。
- 検索バー:ワークシートで現在使用されているロールがアクセスできるすべてのデータベース、スキーマ、テーブル、ビューを探索できるデータベースオブジェクトブラウザです。
最下部のペインには、クエリやその他の操作の結果が表示されます。さらに、4つのオプション(「オブジェクト」、「クエリ」、「結果」、「チャート」)もあります。これらはUI上の該当するパネルを開閉します。「**チャート」**を選択すると、返された結果を視覚化するパネルが開きます。これについては、後で詳しく説明します。
このページの各種ペインは、スライダーを調整することでサイズを変更できます。ワークシート内に余裕が必要な場合は、左のパネルのデータベースオブジェクトブラウザを折りたたんでください。本ガイドのスクリーンショットの多くは、このパネルを閉じた状態となっています。
ダッシュボード
「ダッシュボード」タブでは、1つ以上のチャートの柔軟な表示を作成できます(並べ替え可能なタイル形式で)。タイルとウィジェットは、ワークシートに結果を返すSQLクエリを実行することによって生成されます。ダッシュボードは、最小限の構成においてさまざまなサイズで機能します。
データベース
「データ」の下の「**データベース」**タブには、自分が作成したデータベースやアクセス権限のあるデータベースに関する情報が表示されます。データベースの作成、クローン、ドロップ、または所有権の譲渡を行ったり、UIのデータをロードしたりできます。自分の環境にデータベースがすでに存在していることに注意してください。ただし、それをこのラボで使用することはありません。
プライベート共有データ
また、「**データ」**の下の「プライベート共有データ」タブでは、データのコピーを作成することなく、個別のSnowflakeアカウント間または外部ユーザー間でSnowflakeテーブルを簡単かつ安全に共有するためのデータシェアリングを設定できます。データシェアリングについてはセクション10で取り上げます。
マーケットプレイス
「マーケットプレイス」タブでは、すべてのSnowflakeユーザーが、プロバイダーが提供するデータセットを閲覧および利用することができます。共有データには2つのタイプがあります。公開データとパーソナライズされたデータです。公開データとは、即時クエリに利用できる無料のデータセットです。パーソナライズされたデータの場合は、データのプロバイダーに連絡し、データ共有の承認を得る必要があります。
クエリ履歴
「**アクティビティ」**の下には、「クエリ履歴」と「**コピー履歴」**という2つのタブがあります。
- 「**クエリ履歴」**には、過去のクエリと、結果を絞り込むために使用できるフィルター(ユーザー、ウェアハウス、ステータス、クエリタグなど)が表示されます。過去14日間に自分のSnowflakeアカウントから実行されたすべてのクエリの詳細が表示されます。クエリIDをクリックすると、詳細情報を見ることができます。
- 「コピー履歴」には、データをSnowflakeに取り込むために実行されたコピーコマンドのステータスが表示されます。
ウェアハウス
「管理」の下の「**ウェアハウス」**タブでは、Snowflakeでデータをロードまたはクエリするための、仮想ウェアハウスと呼ばれるコンピューティングリソースを設定および管理します。COMPUTE_WHと呼ばれるウェアハウスが、お使いの環境内にすでに存在しています。
リソースモニター
「**管理」**の下の「**リソースモニター」**タブには、仮想ウェアハウスが消費するクレジット数を制御するために作成されたすべてのリソースモニターが表示されます。各リソースモニターについて、クレジットクォータ、監視のタイプ、スケジュール、および仮想ウェアハウスがクレジット上限に達したときに実行されるアクションが表示されます。
ロール
「**管理」**の下の「ユーザーとロール」タブのサブタブである「**ロール」**には、ロールのリストとその階層が表示されます。このタブでは、ロールの作成、再編成、およびユーザーへの付与を実行できます。「**テーブル」**サブタブを選択すると、ロールを表形式/リスト形式でも表示できます。
ユーザー
「**管理」**タブの下の「ユーザーとロール」タブのサブタブである「ユーザー」には、そのアカウント内のユーザーのリストと、デフォルトのロールおよびユーザーの所有者が表示されます。新規アカウントでは、追加のロールが作成されていないため、レコードは表示されません。現在のロールを通じて付与された権限により、このタブに表示される情報が決まります。このタブで利用できるすべての情報を表示するには、ロールをアカウント管理者に切り替えてください。
UIの右上にあるユーザー名をクリックすると、パスワード、ロール、環境設定を変更できます。Snowflakeには、システム定義のロールがいくつかあります。現在のロールはデフォルトのSYSADMINであり、このラボではほぼこのロールのままとなります。
ラボストーリー
このラボは、米国のニューヨーク市に実在する市全域の自転車シェアリングシステムであるCiti Bikeの分析チームをベースとしています。このチームは、自社の自転車利用者についての理解を深め、利用者に最高のサービスを提供する方法を知るために、社内のトランザクションシステムからのデータについて分析を実行したいと考えています。
まず私たちは、自転車利用者のトランザクションから得られた構造化された.csvデータをSnowflakeにロードします。その後、オープンソースの半構造化JSON気象データを利用して、自転車の利用回数と天候に相関関係があるかを判断していきます。
構造化されたCiti Bike利用者のトランザクションデータをSnowflakeにロードする準備から始めましょう。
このセクションでは、以下の手順を、順を追って説明していきます。
- データベースとテーブルを作成する。
- 外部ステージを作成する。
- データのファイル形式を作成する。
使用するデータは、Citi Bike(NYC)によって提供された自転車シェアのデータです。データは、米国西部リージョンのAmazon AWS S3バケットにエクスポートされ、事前設定されています。データは、走行時間、ロケーション、ユーザータイプ、性別、年齢などの情報で構成されています。AWS S3上では、このデータは6,150万行、377個のオブジェクト、圧縮サイズ1.9GBで表されています。
以下は、Citi Bike(CSV)データファイルのスニペットです。
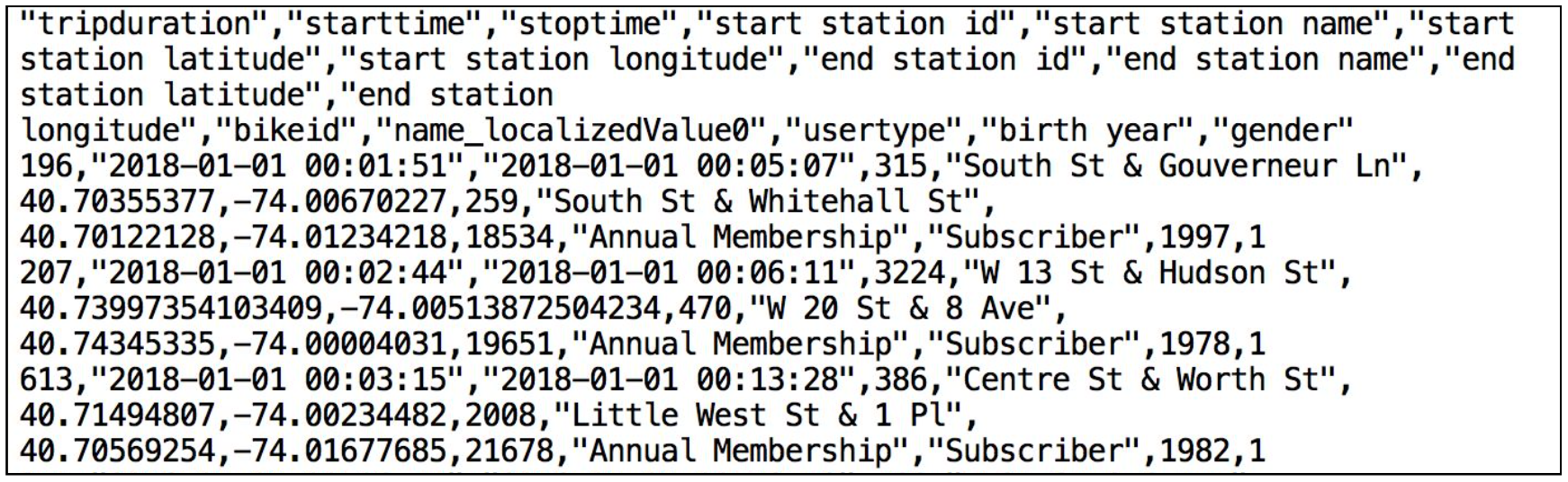
このカンマ区切り形式のファイルには、単一のヘッダーラインがあり、ヘッダーラインに含まれるフィールドの見出しを含め、すべての文字列値がダブルクォーテーションで囲まれています。これは、このセクションの後半で、このデータを格納するSnowflakeテーブルを構成する際に重要になります。
データベースとテーブルを作成する
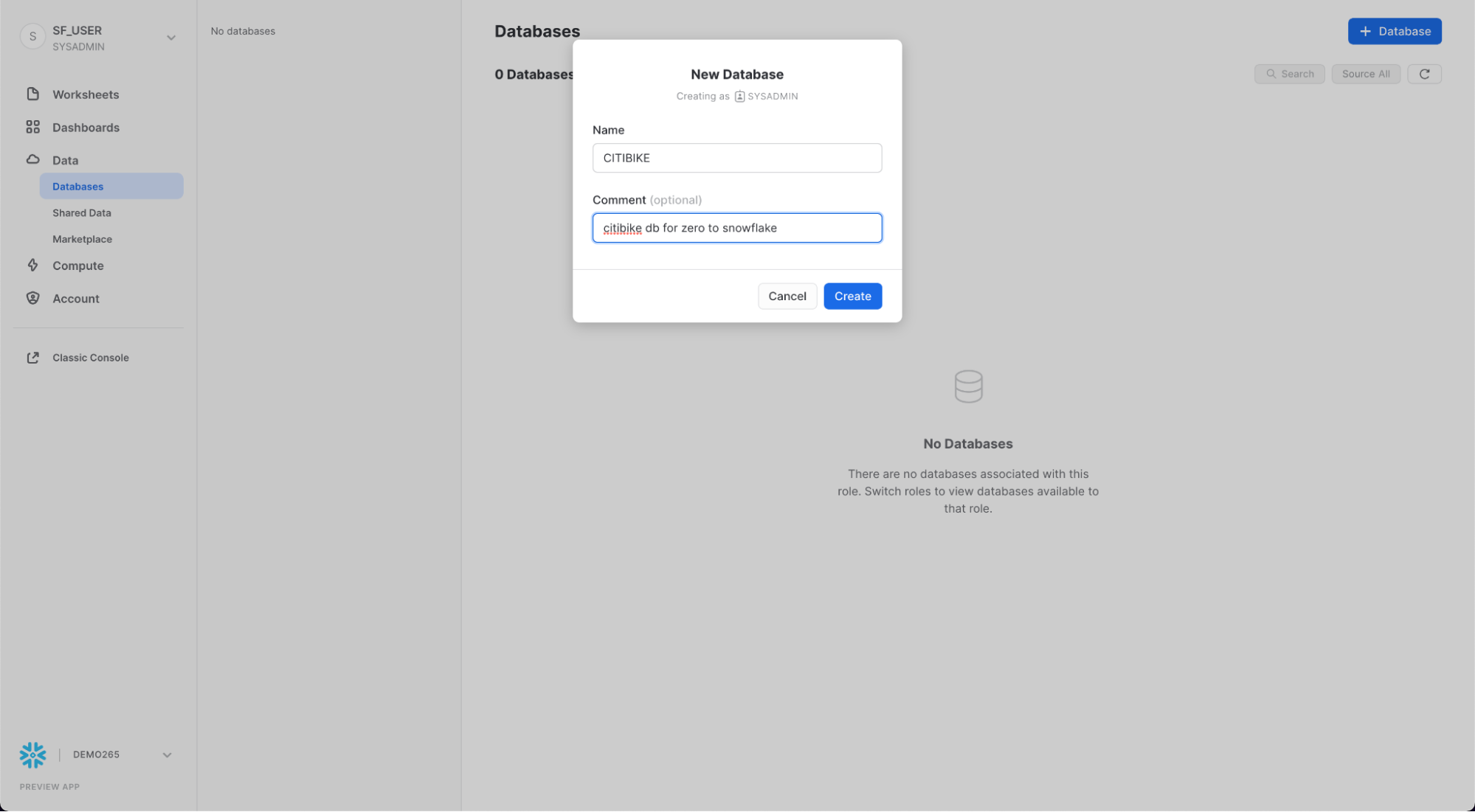
まず、構造化データのロードに使用するCITIBIKEという名前のデータベースを作成しましょう。
左上の「ロールの切り替え」 > 「SYSADMIN」で自分の名前を選択し、現在SYSADMINロールを使用していることを確認してください。
「**データベース」**タブに移動します。「作成」をクリックし、データベースにCITIBIKEという名前を付けて「作成」をクリックします。
「ワークシート」タブに移動します。ステップ3で作成したワークシートが表示されます。
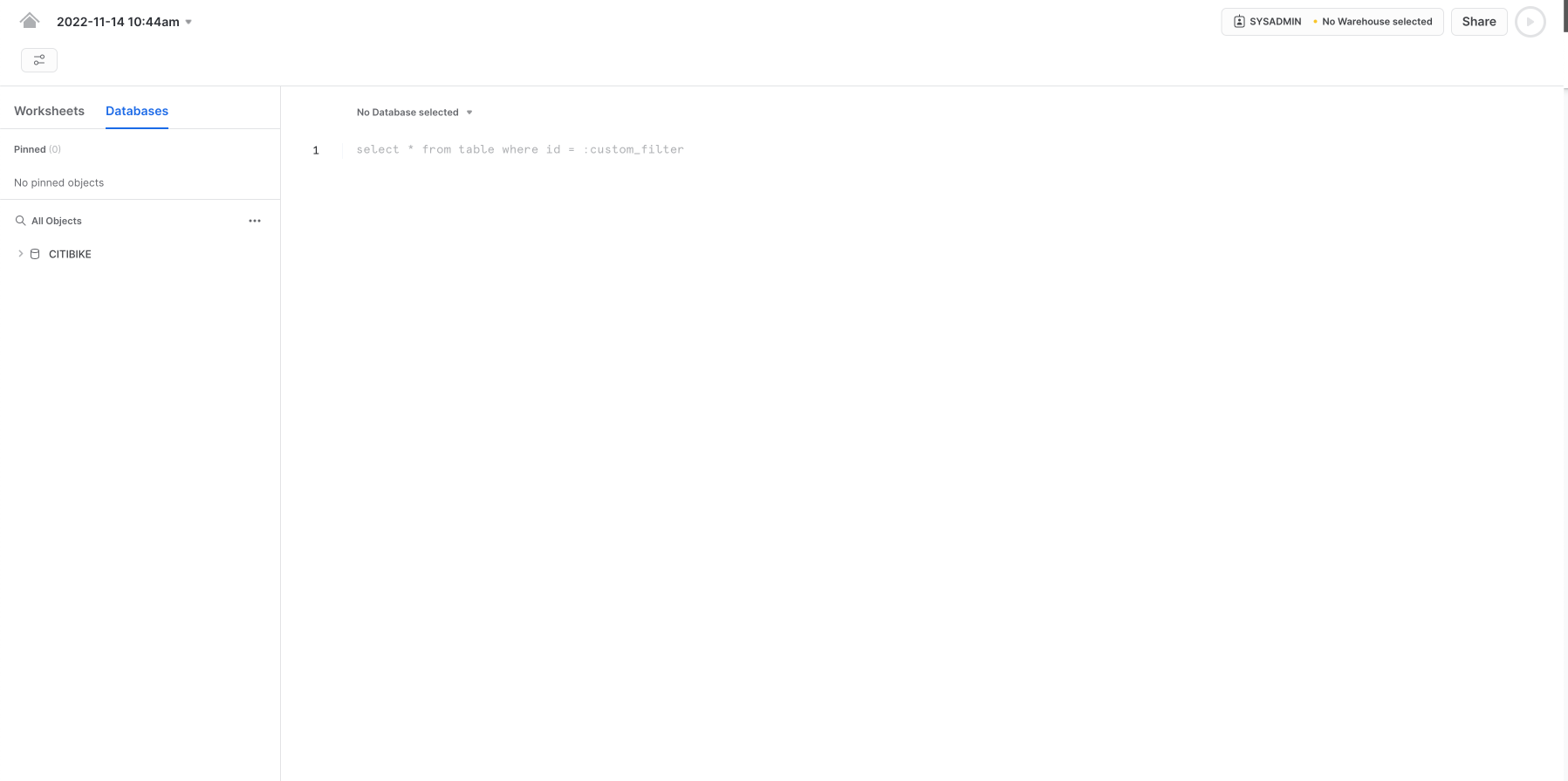
ワークシート内のコンテキストを適切に設定する必要があります。ワークシートの右上隅で、「**共有」**ボタンの左のボックスをクリックし、コンテキストメニューを表示します。ここで、各ワークシートから表示および実行できるエレメントを制御します。ここでは、UIを使用してコンテキストを設定します。このラボの後半では、ワークシート内のSQLコマンドを使用して同じことを実行します。
以下のコンテキスト設定を選択します。
ロール:SYSADMINウェアハウス:COMPUTE_WH
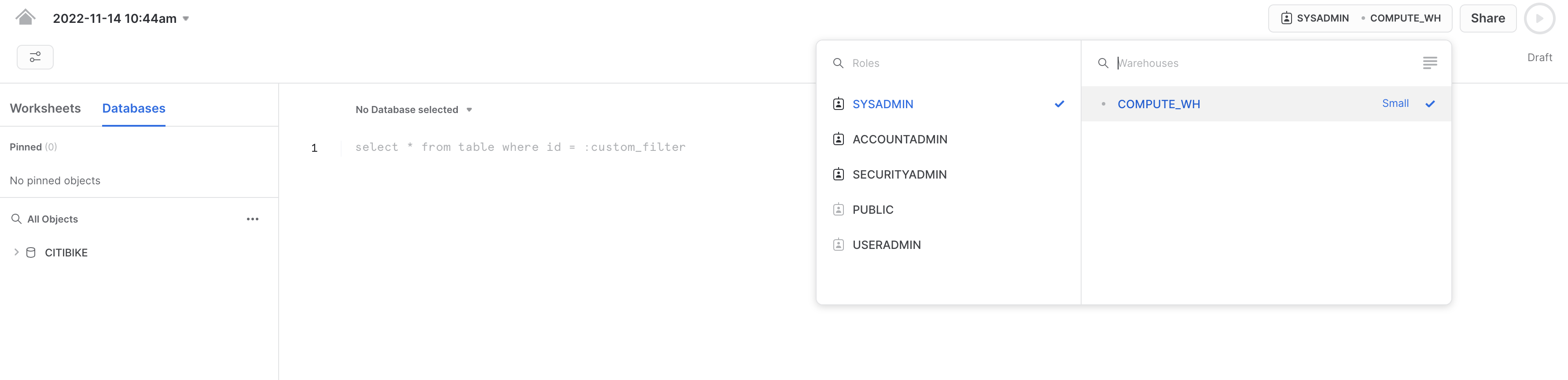
次に、データベースのドロップダウンで、以下のコンテキスト設定を選択します。
データベース:CITIBIKE スキーマ = PUBLIC
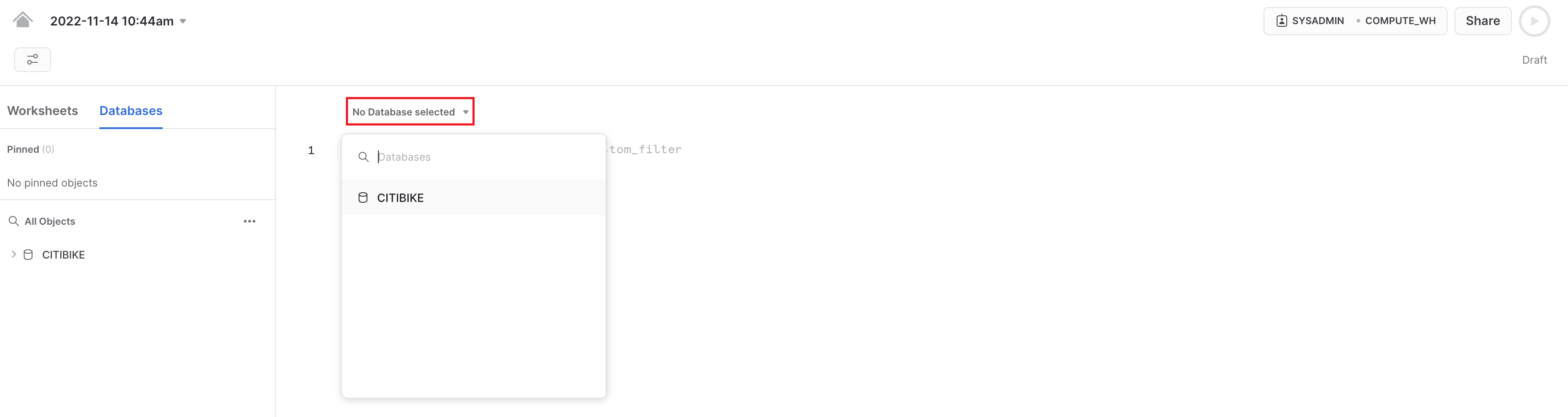
ワークシートでの作業をしやすくするために、名前を変更しましょう。左上隅で、ワークシート名(これはワークシート作成時のタイムスタンプです)をダブルクリックし、CITIBIKE_ZERO_TO_SNOWFLAKEに変更します。
次に、カンマ区切りのデータのロードに使用するTRIPSという名前のテーブルを作成します。UIを使用する代わりに、ワークシートを使用してテーブルを作成するDDLを実行します。以下のSQLテキストをワークシートにコピーしてください。
create or replace table trips
(tripduration integer,
starttime timestamp,
stoptime timestamp,
start_station_id integer,
start_station_name string,
start_station_latitude float,
start_station_longitude float,
end_station_id integer,
end_station_name string,
end_station_latitude float,
end_station_longitude float,
bikeid integer,
membership_type string,
usertype string,
birth_year integer,
gender integer);
SQLテキストの任意の場所にカーソルを合わせ、ワークシートの右上にある青い「再生/実行」ボタンをクリックしてクエリを実行します。または、キーボードショートカットの[Ctrl]/[Cmd]+[Enter]を使用します。
TRIPSテーブルが作成されたことを確認します。ワークシートの下部の「結果」セクションに、「Table TRIPS successfully created(テーブルTRIPSが問題なく作成されました)」というメッセージが表示されます。
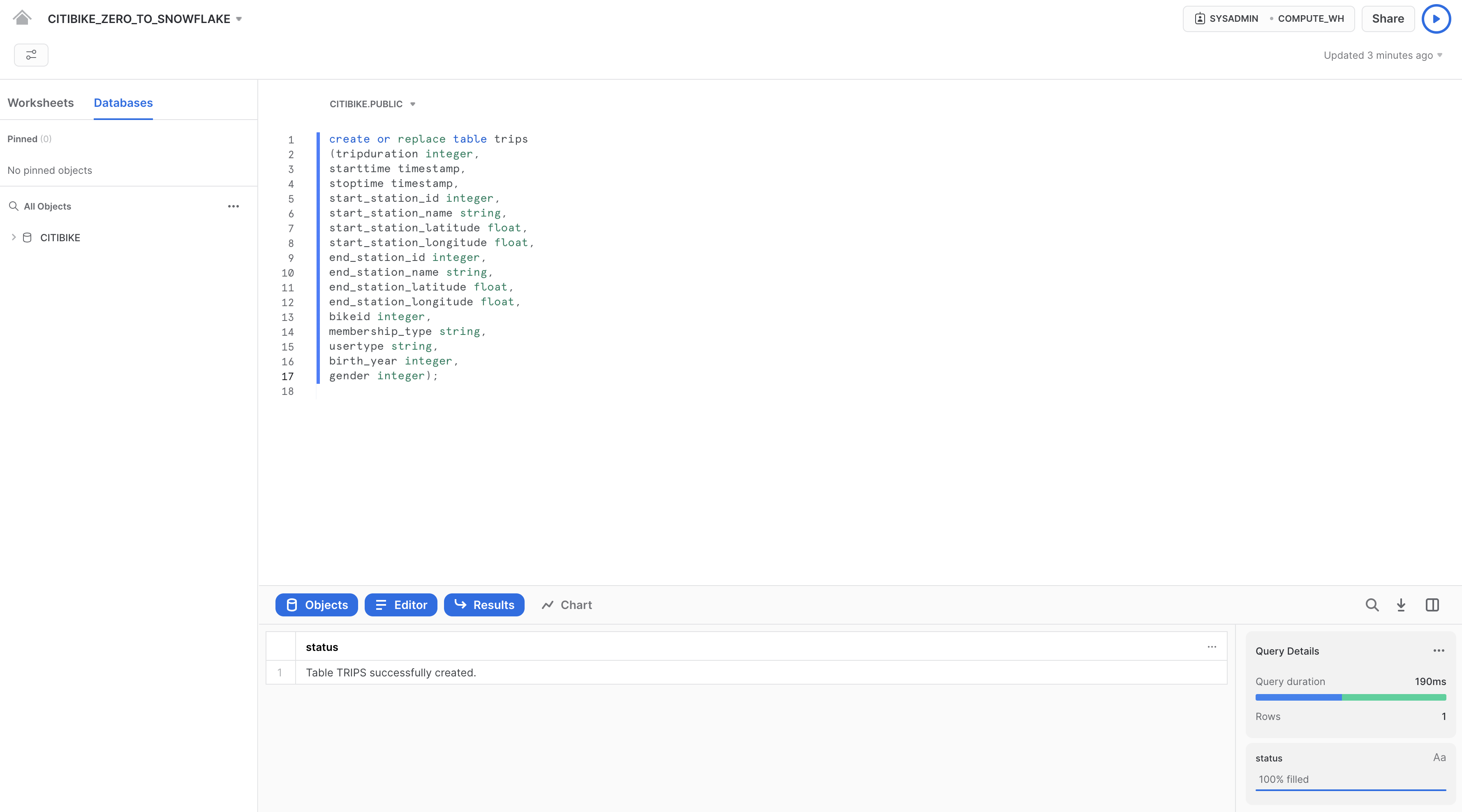
ワークシート左上のホームアイコンをクリックして「データベース」タブに移動します。「データ」、「**データベース」**の順にクリックします。データベースリストで、CITIBIKE、PUBLIC、「**テーブル」**の順にクリックすると、新たに作成したTRIPSテーブルが表示されます。左側にデータベースが表示されない場合は、データベースが隠れている場合がありますので、ブラウザを拡大してください。
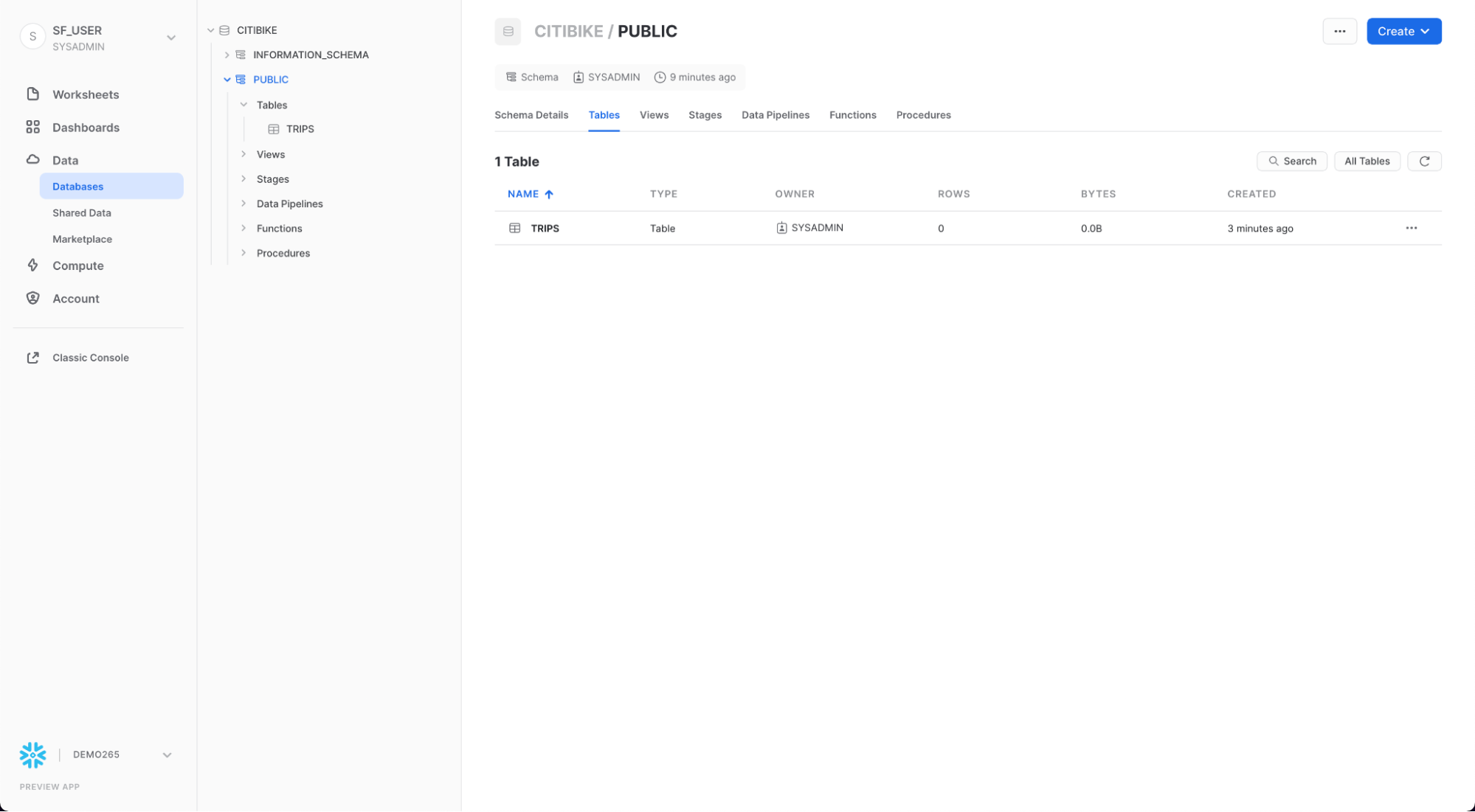
TRIPSと「列」タブをクリックすると、先ほど作成したテーブル構造が表示されます。
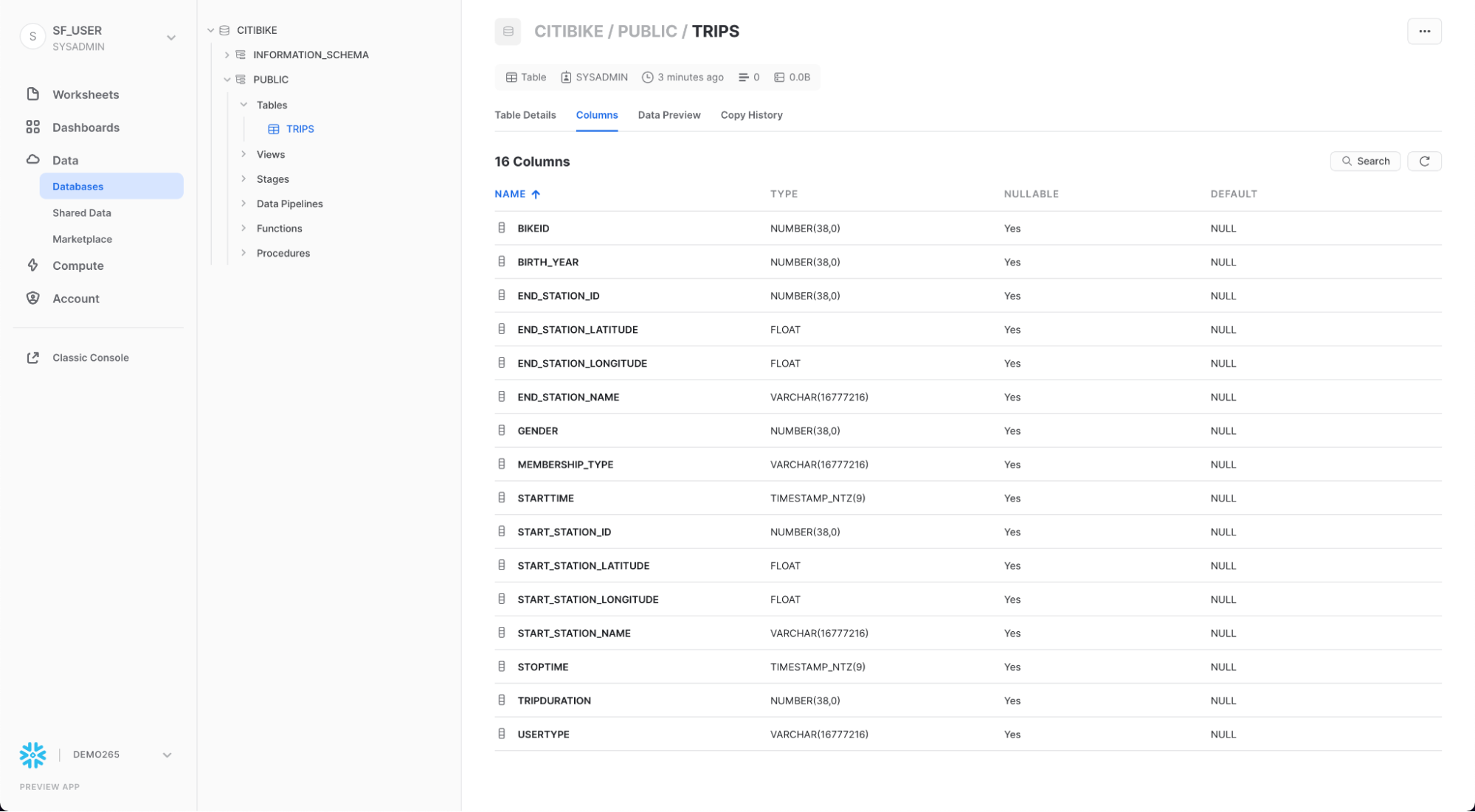
外部ステージを作成する
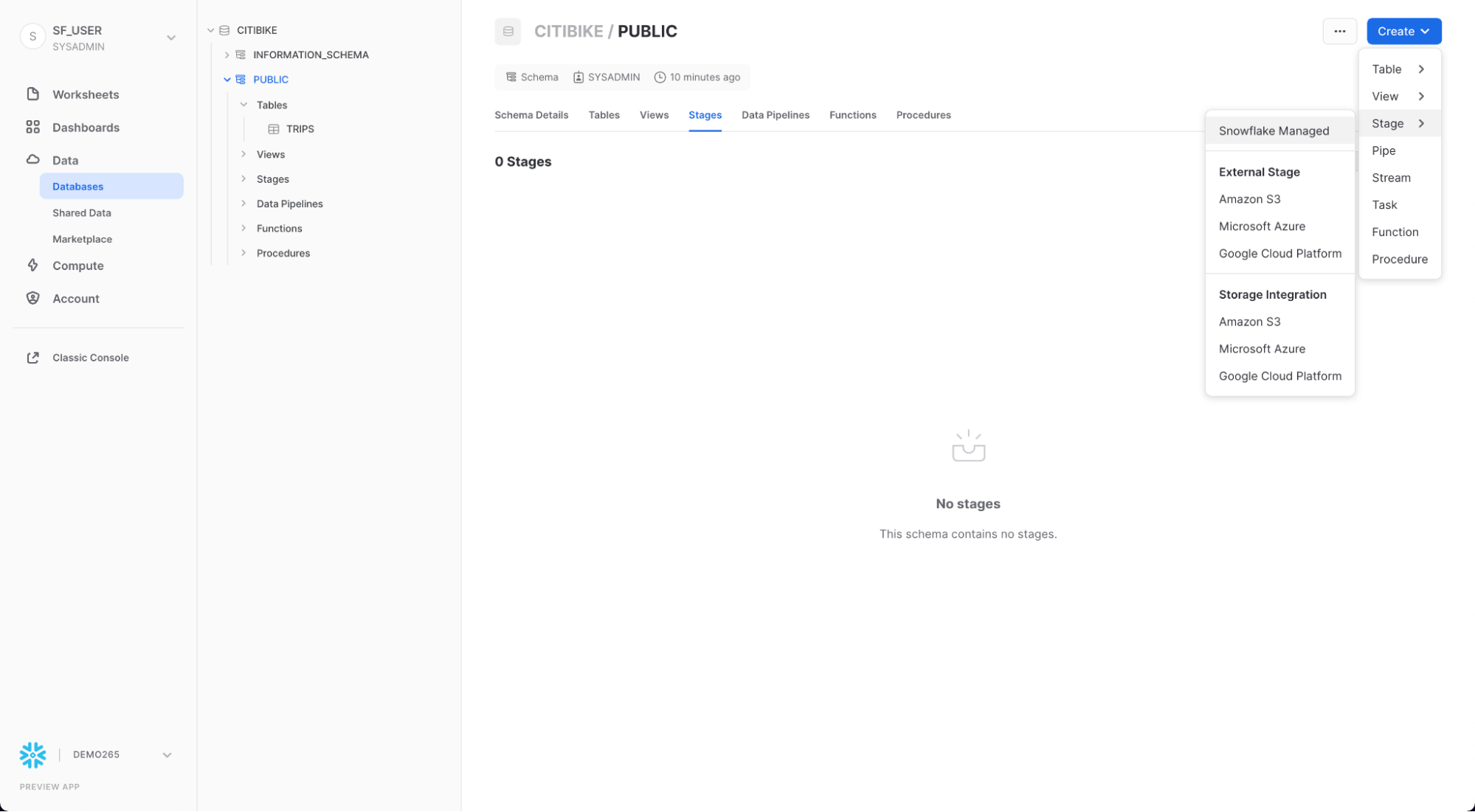
ここでは、公開された外部のS3バケット内ですでにステージングされている、構造化されたカンマ区切りのデータを扱います。このデータを使用する前に、まず外部バケットのロケーションを指定するステージを作成する必要があります。
「データベース」タブから、CITIBIKEデータベースとPUBLICスキーマをクリックします。「**作成」**ボタンをクリックし、その後、「Stage」、「Amazon S3」の順にクリックします。
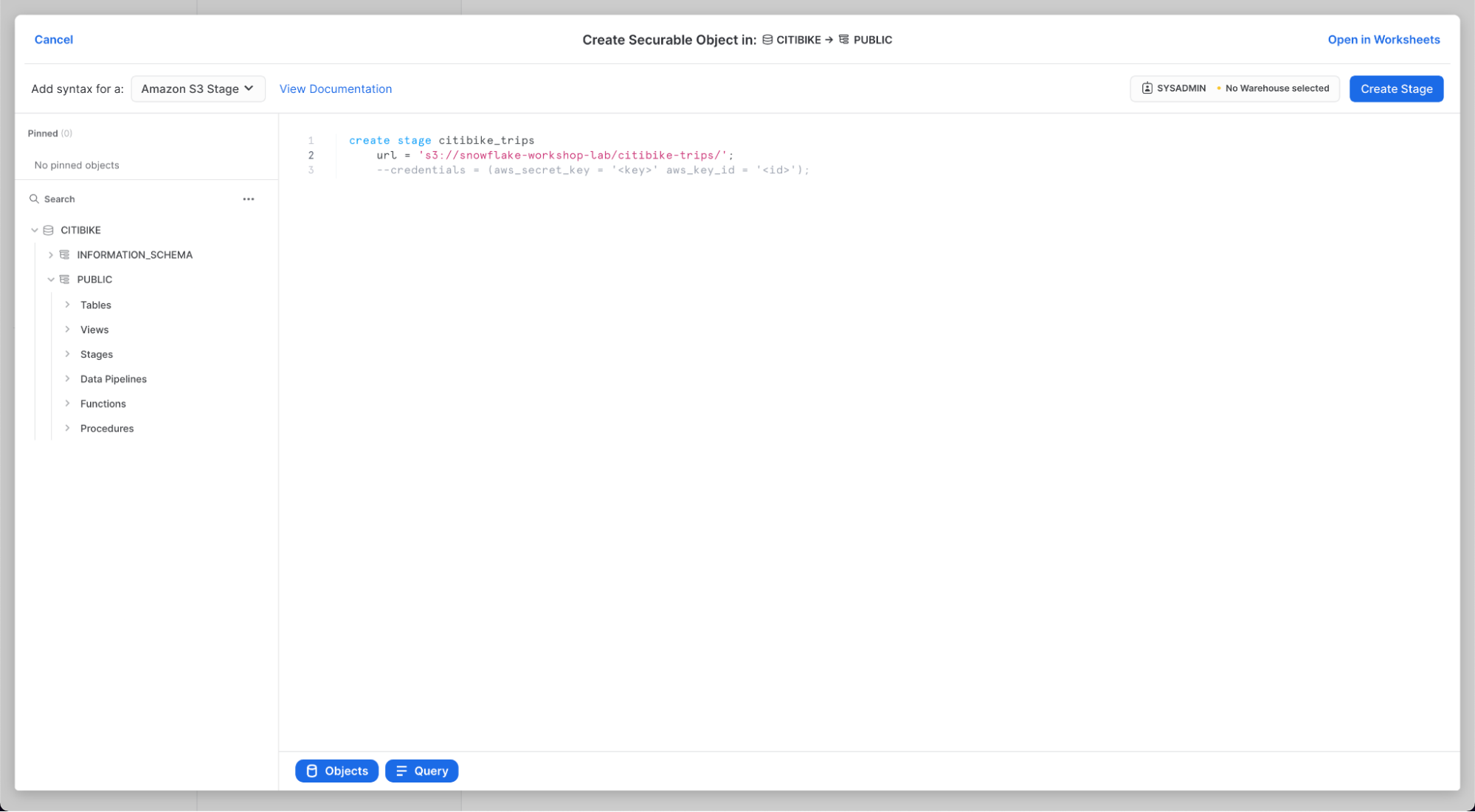
開いた「セキュリティ保護可能なオブジェクトの作成」ダイアログで、SQLステートメントの以下の値を置き換えます。
citibike_trips
s3://snowflake-workshop-lab/japan/citibike-trips/
**注意:**URLの最後には、必ずフォワードスラッシュ(/)を入れてください。これを入れておかなければ、後でバケットからデータを読み込む際にエラーが発生します。また、必要のない「credentials = (...)」ステートメントが削除されていることを確認してください。下図のように「–」を使用してコメントアウトすることもできます。create stageコマンドは、下図のようになります。あるいは、3行目を含めないでください。
ではcitibike_tripsステージのコンテンツを見ていきましょう。「**ワークシート」**タブに戻り、作成した「CITIBIKE_ZERO_TO_SNOWFLAKE」ワークシートを開いて、下図のように、先ほどのコードの下に以下のSQLステートメントを追加して実行します。
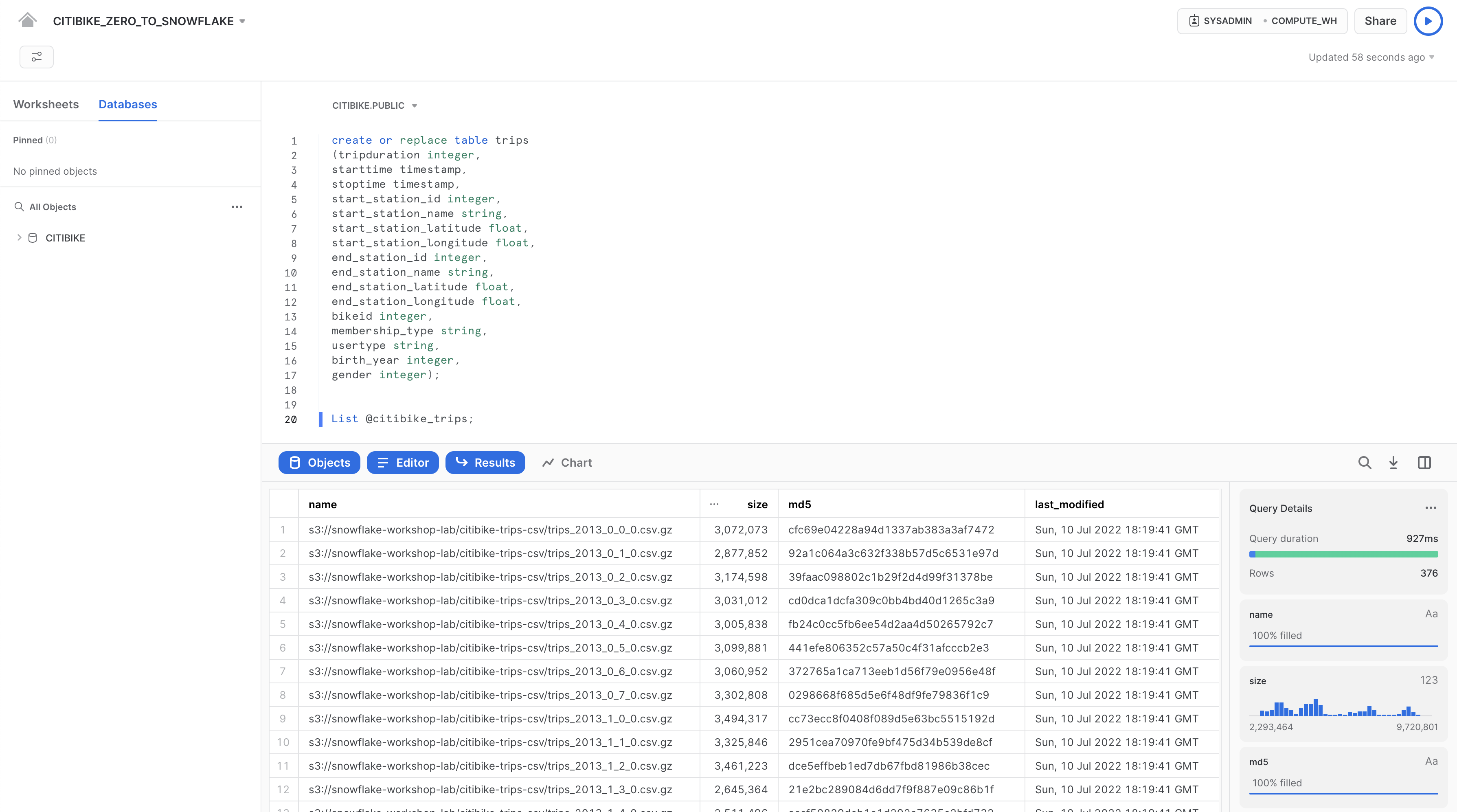
list @citibike_trips;
最下部のペインの結果に、ステージ内のファイルのリストが表示されます。
ファイル形式を作成する
Snowflakeにデータをロードする前に、データ構造に合うファイル形式を作成する必要があります。
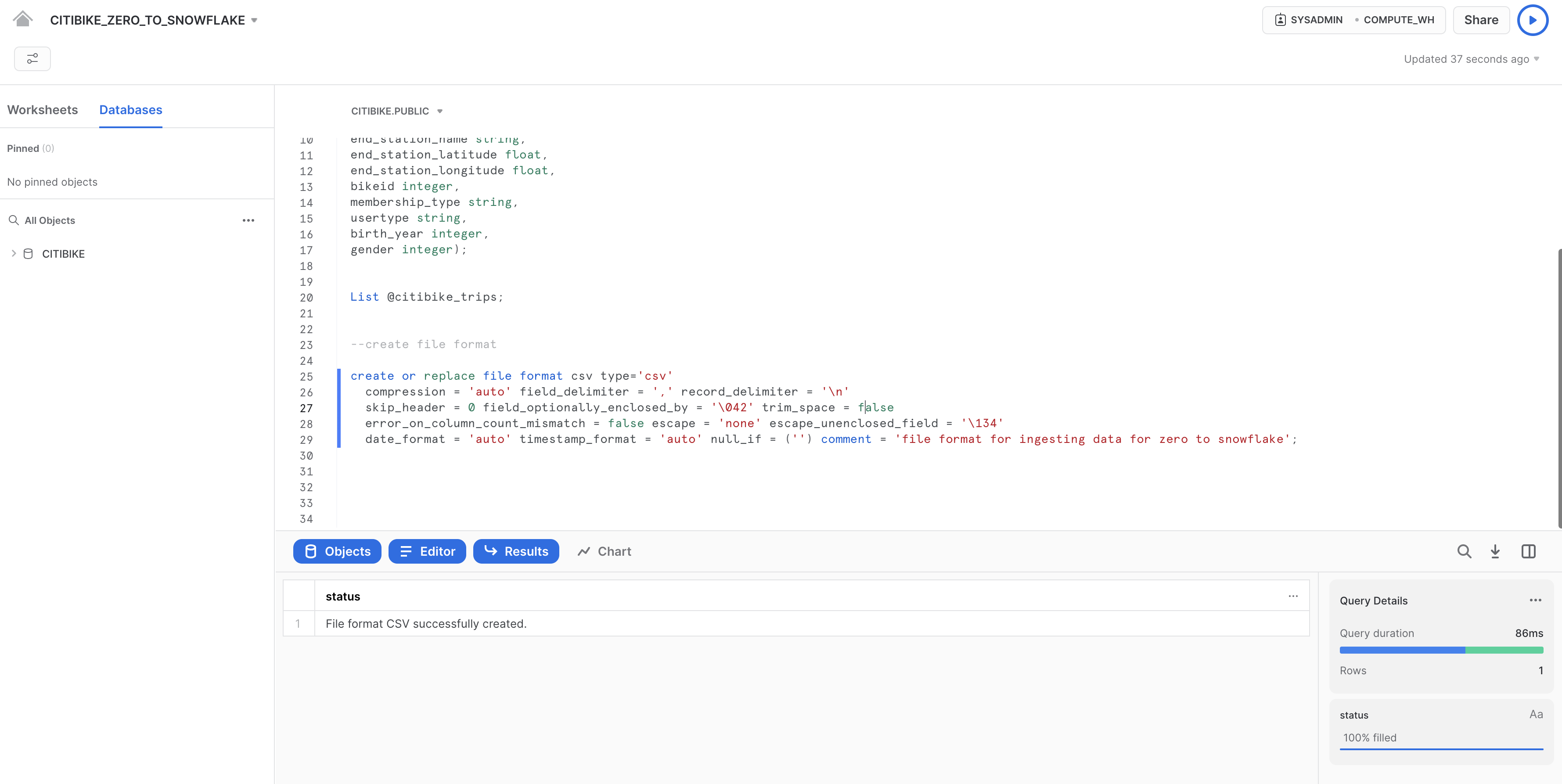
ワークシートで、以下のコマンドをそれ以外のコードの下に追加して実行し、ファイル形式を作成します。
--create file format
create or replace file format csv type='csv'
compression = 'auto' field_delimiter = ',' record_delimiter = '\n'
skip_header = 0 field_optionally_enclosed_by = '\042' trim_space = false
error_on_column_count_mismatch = false escape = 'none' escape_unenclosed_field = '\134'
date_format = 'auto' timestamp_format = 'auto' null_if = ('') comment = 'file format for ingesting data for zero to snowflake';
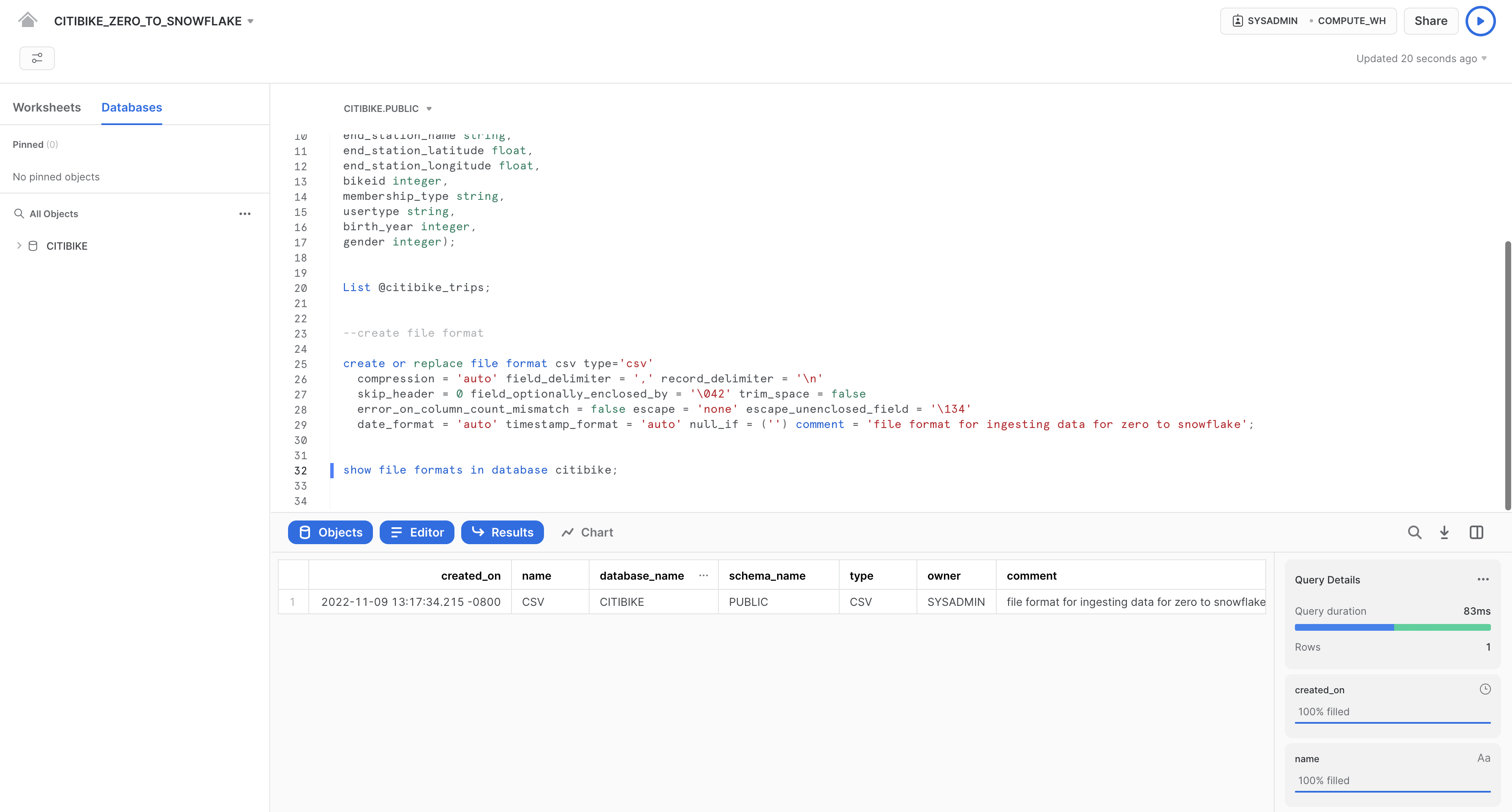
次のコマンドを実行することにより、ファイル形式が正しい設定で作成されていることを確認します。
--verify file format is created
show file formats in database citibike;
作成されたファイル形式が結果にリスト表示されます。
このセクションでは、仮想ウェアハウスとCOPYコマンドを使用して、前のセクションで作成したSnowflakeテーブルへの構造化データの一括ロードを開始します。
データロードのためのウェアハウスのサイズ変更と使用
データをロードするにはコンピューティングリソースが必要です。Snowflakeコンピュートノードは仮想ウェアハウスと呼ばれ、データのロード、クエリの実行、DML操作の実行のいずれであっても、ワークロードに応じて動的にサイズを変更できます。それぞれのワークロードは独自のウェアハウスを持つことができるため、リソースの競合はありません。
「ウェアハウス」タブへ移動します(「**管理」**の下)。ここでは、既存のウェアハウスをすべて表示できるほか、使用状況トレンドの分析も可能です。
右上にある「**+ウェアハウス」**に注意してください。ここで新しいウェアハウスを素早く追加できます。ただし、ここでは30日間のトライアル環境に含まれる既存のウェアハウスであるCOMPUTE_WHを使用します。
COMPUTE_WHウェアハウスの行をクリックします。その後、右上にある**...**(3つのドット)をクリックすると、ウェアハウス上で実行できるアクションが表示されます。このウェアハウスを使用して、AWS S3からデータをロードします。
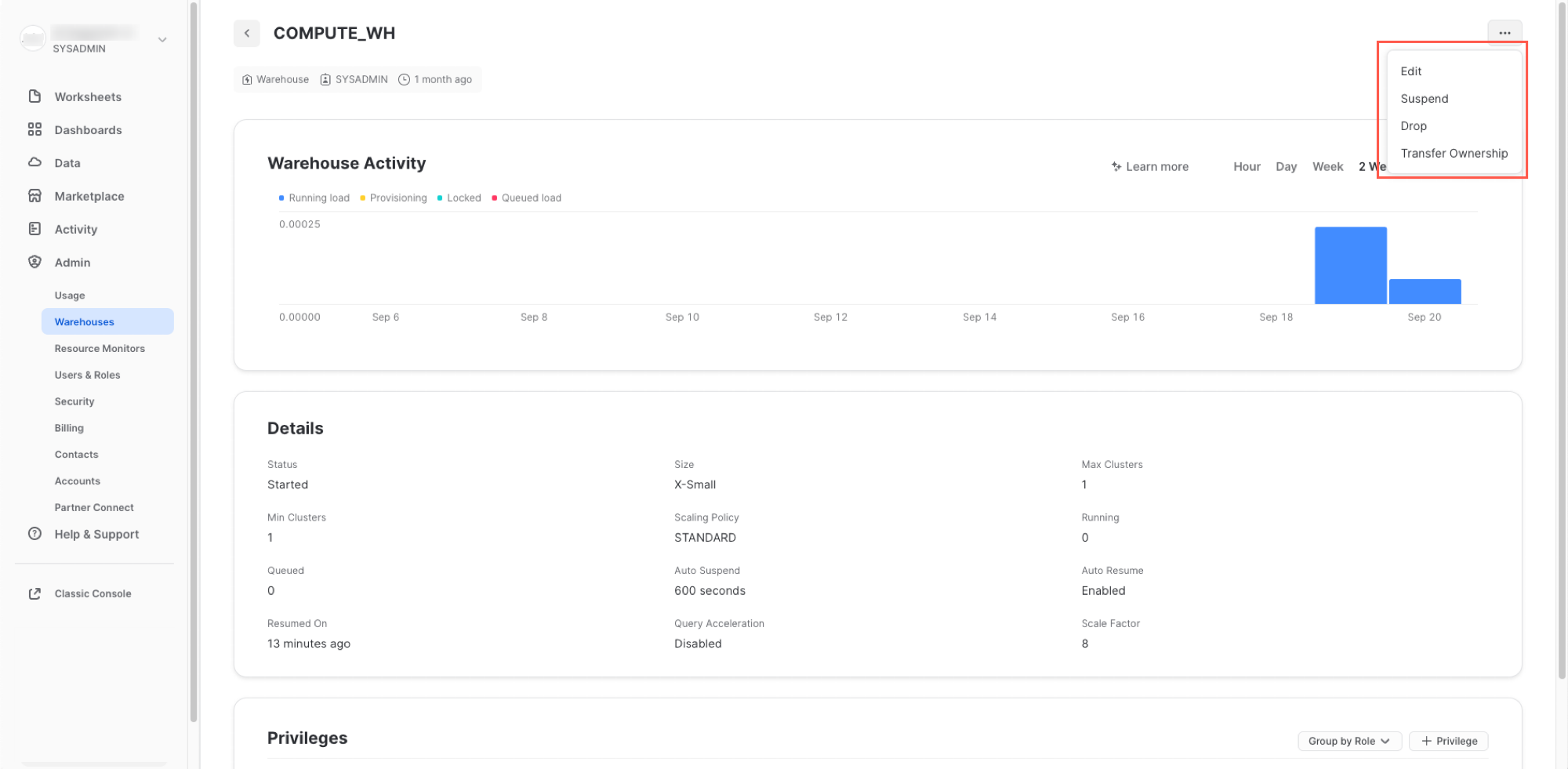
「**編集」**をクリックし、このウェアハウスのオプションとSnowflakeのユニークな機能の一部を実際に確認してみてください。
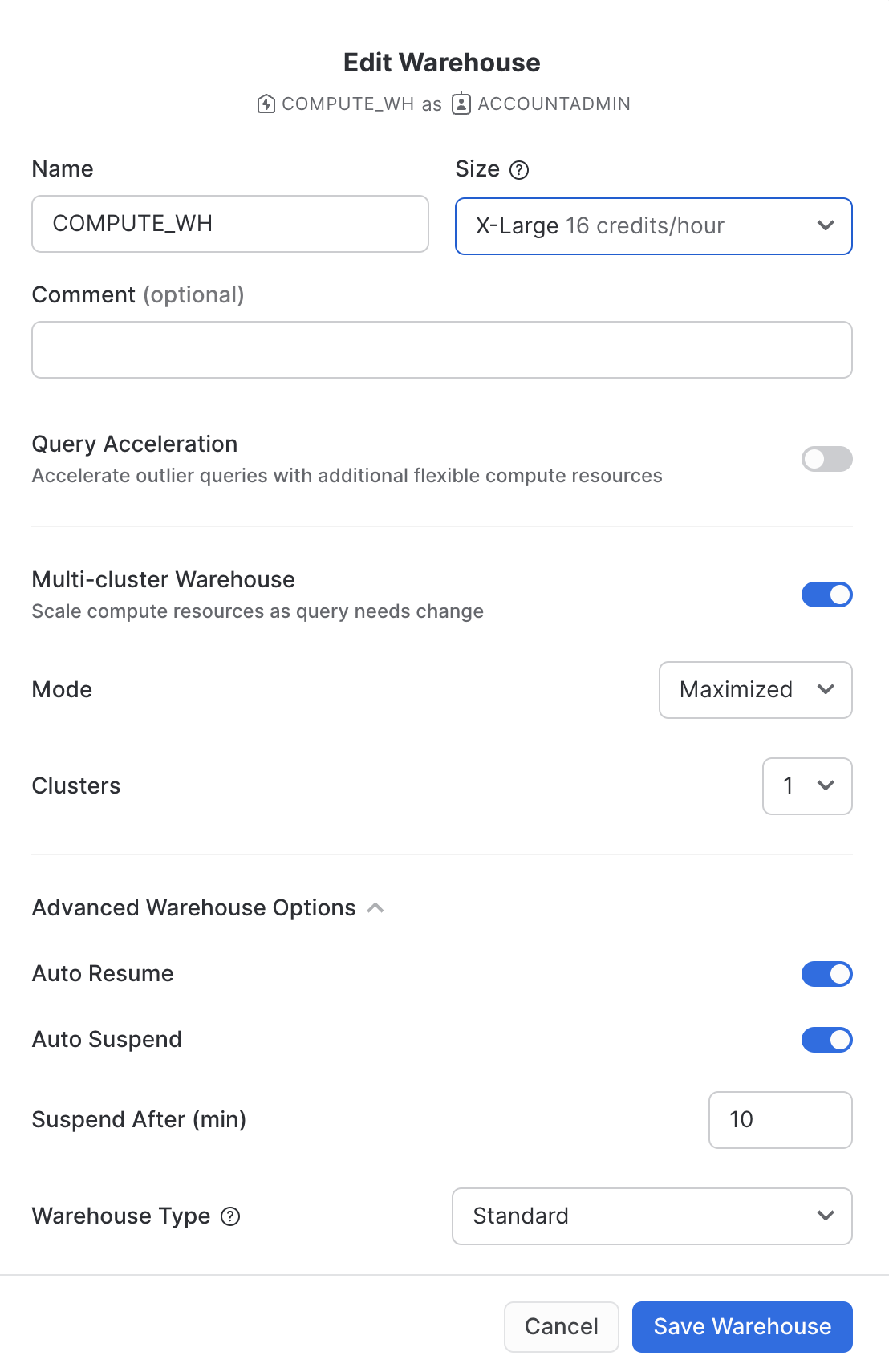
- 「**サイズ」**ドロップダウンでウェアハウスの容量を選択します。大規模なデータロード処理やコンピュートインテンシブなクエリの場合は、より大規模なウェアハウスが推奨されます。サイズは、Snowflakeアカウントがホストされているクラウドプロバイダー(AWS、Azure、またはGCP)からプロビジョニングされる基礎となるコンピューティングリソースの量に直結します。また、ウェアハウスが1時間稼働するごとに消費するクレジット数もこのサイズによって決まります。サイズが大きくなればなるほど、クラウドプロバイダーからウェアハウスに割り当てられるコンピューティングリソースの量とウェアハウスが消費するクレジットの数が多くなります。たとえば、
4X-Large設定では、1時間ごとに128クレジットが消費されます。このサイズ設定は、いつでもワンクリックで変更できます。 - Snowflakeエンタープライズエディション(またはそれ以上)を使用している場合は、「クエリアクセラレーション」オプションを使用できます。このオプションをウェアハウスに対して有効にすると、通常のクエリよりも多くのリソースを使用する外れ値クエリの影響を減らすことで、ウェアハウス全体のパフォーマンスを向上させることができます。これは無効のままにしておきます。
- Snowflakeエンタープライズエディション(またはそれ以上)を使用しており、「**マルチクラスターウェアハウス」**オプションが有効になっている場合、追加のオプションが表示されます。ここでは、ウェアハウスがコンピューティングリソースのクラスターを複数(最大10クラスター)使用するように設定できます。たとえば、
4X-Largeマルチクラスターウェアハウスに最大クラスターサイズの10が割り当てられた場合、そのウェアハウスは基礎となるコンピューティングリソースの10倍までスケールアウトできます(しかも数秒で!)。ただし、この場合、10クラスターすべてが1時間フル稼働すると、ウェアハウスが消費するクレジット数は1280に増えることに注意してください(128クレジット/時間 x 10クラスター)。マルチクラスターは、多くのビジネスアナリストが同じウェアハウスを使用してさまざまなクエリを同時に実行するような同時実行シナリオに最適です。このユースケースでは、さまざまなクエリが高速に実行されるように複数のクラスターに割り当てられます。 - 「詳細ウェアハウスオプション」では、使用していないウェアハウスを自動的に一時停止し、クレジットを無駄に消費しないようにするオプションがあります。一時停止されたウェアハウスを自動的に再開するオプションもあります。このオプションが有効な場合、新しいワークロードがウェアハウスに送信されると、自動的に再開されます。この機能によって、Snowflakeの効率的な「従量課金」モデルが可能となり、リソースが必要になったときにスケールアップし、不要になったときに自動的にスケールダウンするかオフにすることができるため、アイドリング状態のリソースをほぼ完全に排除できます。さらに、ウェアハウスのタイプを標準からSnowpark用に最適化されたものに変更するオプションもあります。Snowpark用に最適化されたウェアハウスは、ノードあたり16倍のメモリを提供し、単一の仮想ウェアハウスノードでストアドプロシージャを使用するMLトレーニングのユースケースなど、大規模なメモリ要件を持つワークロードに推奨されます。ここでは、タイプを標準のままにしておきます
**警告 - 支出に注意してください。**このラボ中またはその終了後に、正当な理由なく以下の操作を実行しないよう注意してください。これらの操作を行うと、400ドルの無料クレジットを必要以上に早く使い切ってしまう可能性があります。
- 自動サスペンドを無効にしないでください。自動サスペンドが無効化されていると、ウェアハウスは使用されていなくても稼働し続け、クレジットを消費し続けます。
- ワークロードを考慮し、過剰なウェアハウスサイズを使用しないでください。ウェアハウスが大きいほど、消費されるクレジットが多くなります。
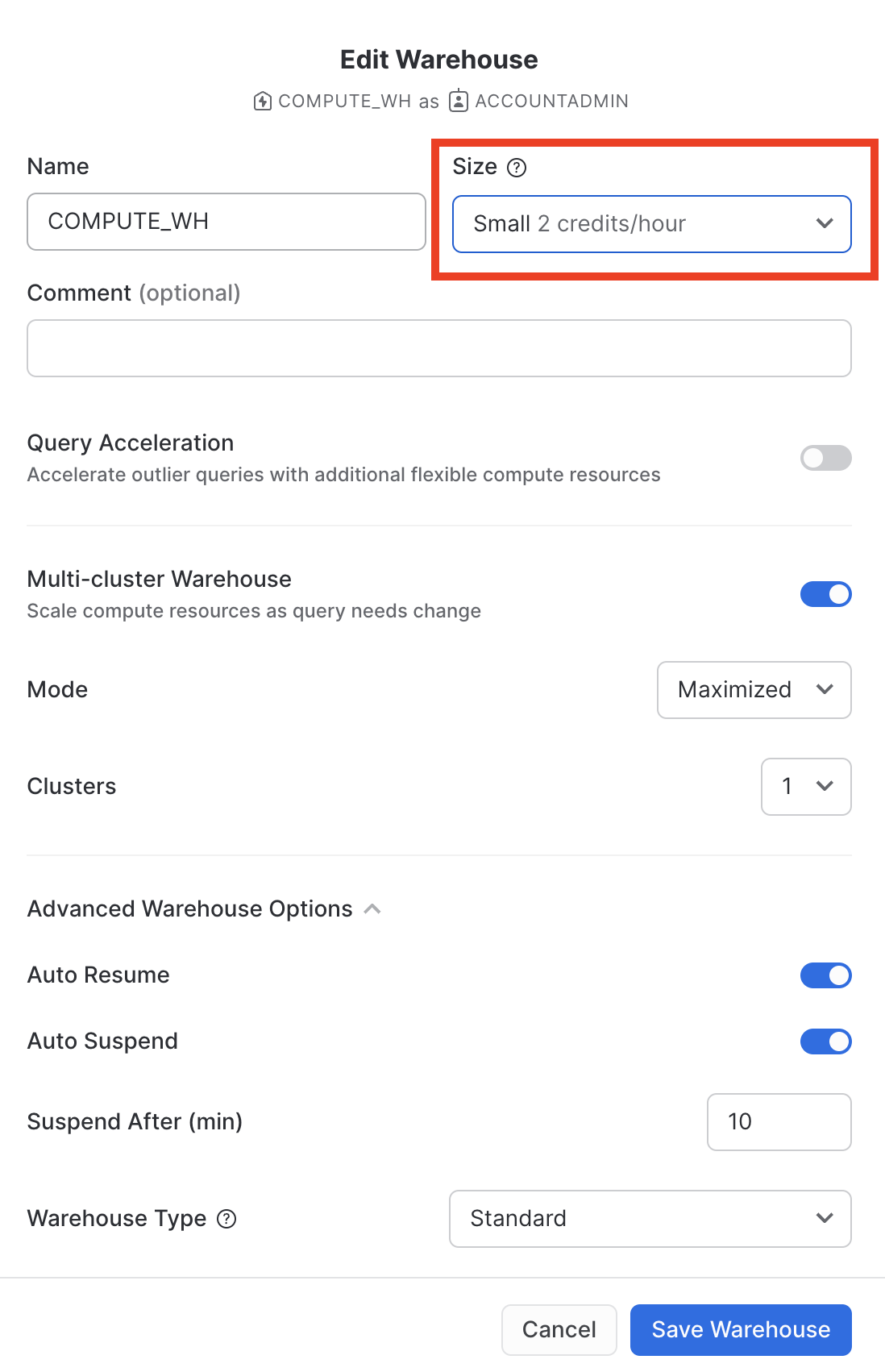
この仮想ウェアハウスを使用して、CSVファイルの構造化データ(AWS S3バケットに格納)をSnowflakeにロードすることになります。しかし、まずウェアハウスのサイズを変更して、使用するコンピューティングリソースを増やすことにします。ロード後、所要時間を記録してください。このセクションの後のステップで、さらに大きなウェアハウスで同じロード操作を再実行し、ロード時間が短縮していることを確認します。
このデータウェアハウスのサイズをX-SmallからSmallへ変更し、その後「ウェアハウスを保存」ボタンをクリックします。
データのロード
これで、COPYコマンドを実行し、先ほど作成したTRIPSテーブルにデータをロードできるようになりました。
「ワークシート」タブでCITIBIKE_ZERO_TO_SNOWFLAKEワークシートに戻ります。ワークシートのコンテキストが以下のように正しく設定されていることを確認してください。
ロール:SYSADMIN ウェアハウス:COMPUTE_WH データベース:CITIBIKE スキーマ = PUBLIC
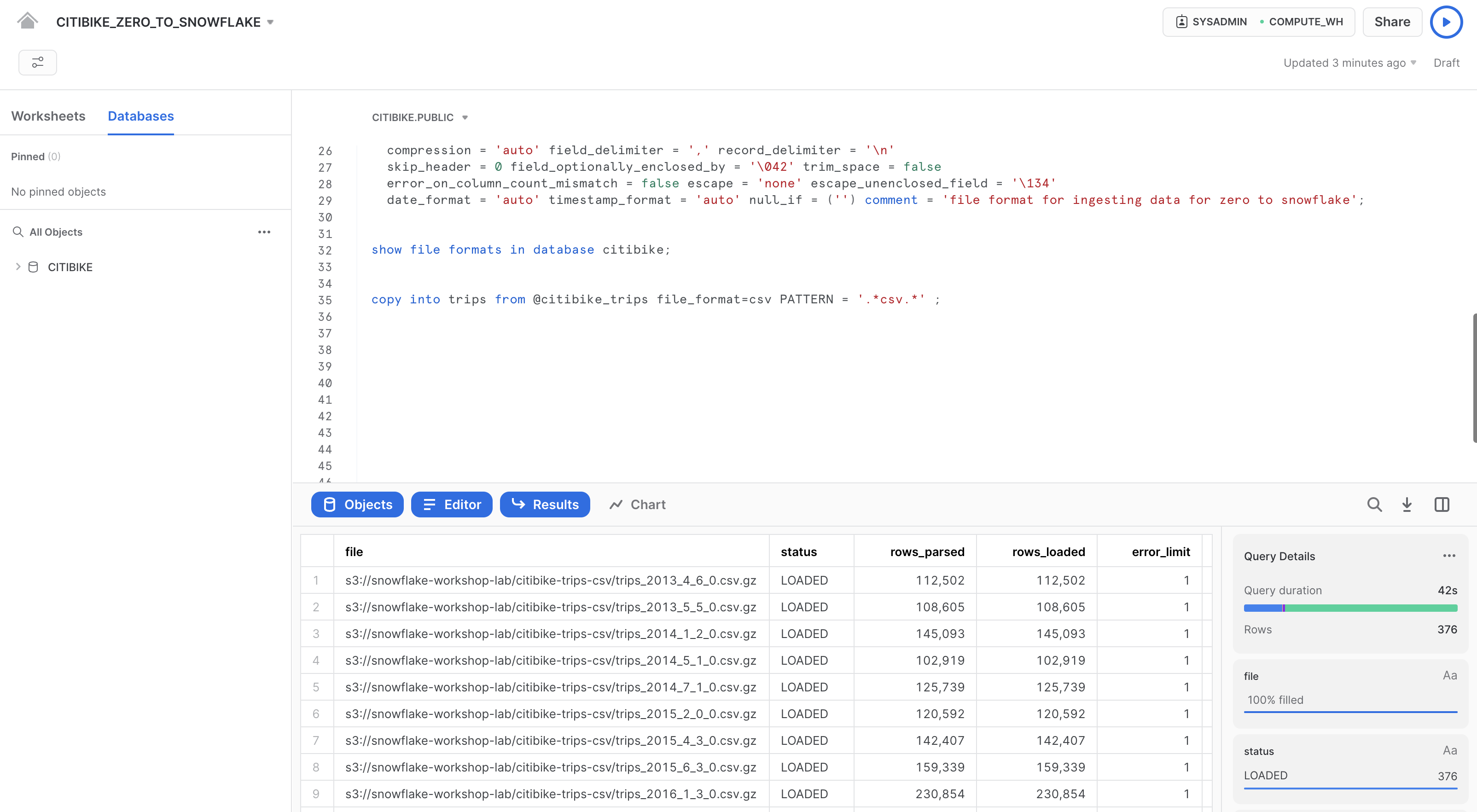
ワークシートで以下のステートメントを実行し、ステージングされたデータをテーブルにロードします。これには30秒ほどかかる場合があります。
copy into trips from @citibike_trips file_format=csv PATTERN = '.*csv.*' ;
結果ペインに、ロードされた各ファイルのステータスが表示されます。ロードが完了すると、右下の「クエリの詳細」ペインをスクロールして、最後に実行されたステートメントのさまざまなステータス、エラー統計、および視覚化を確認できるようになります。
次に、ホームアイコンをクリックしてから、「アクティビティ」、「クエリ履歴」の順にクリックして、「クエリ履歴」タブに移動します。リストの一番上にあるクエリを選択します。これは、最後に実行されたCOPY INTOステートメントです。「**クエリプロファイル」**タブを選択し、クエリ実行時のステップ、クエリの詳細、最もコストの高いノード、およびその他の統計情報を記録します。
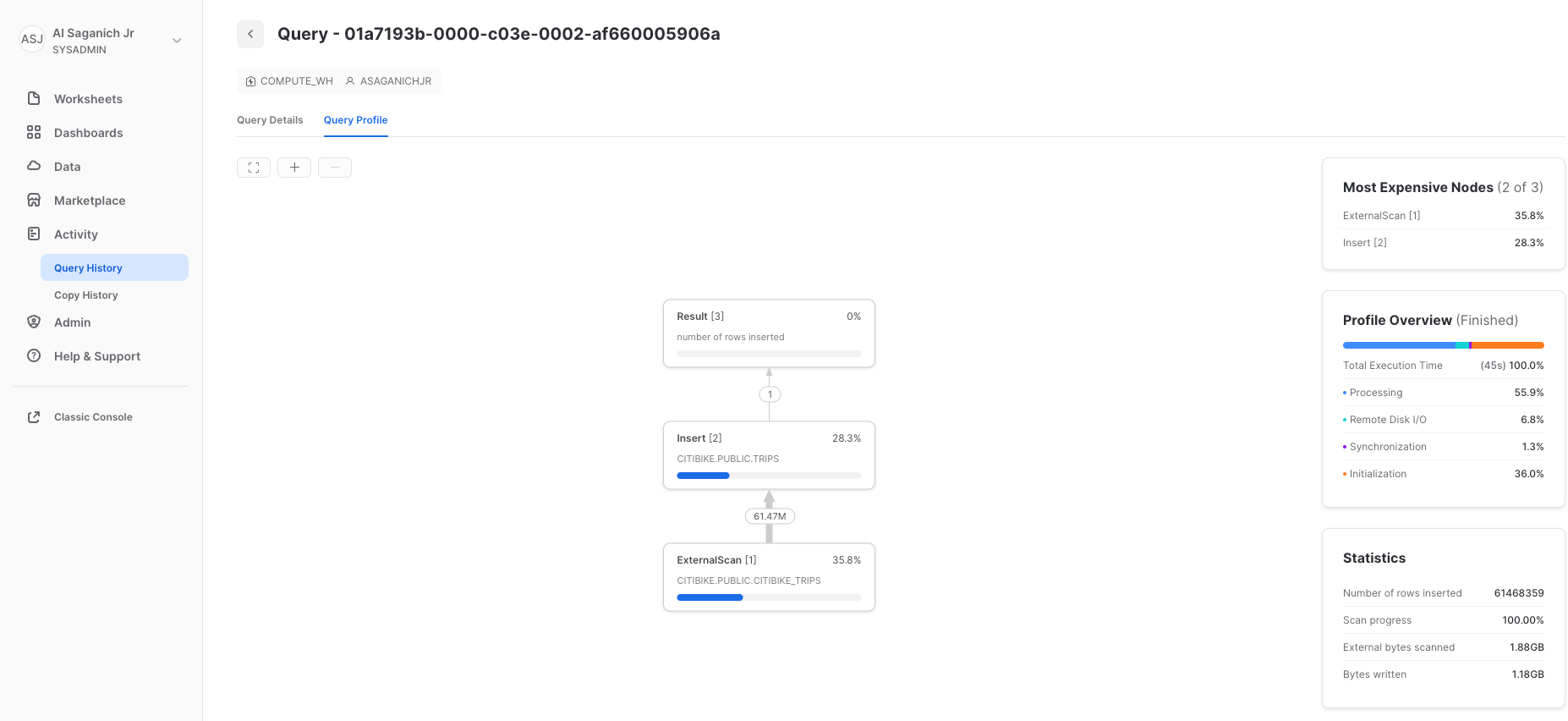
次に、より大きなウェアハウスでTRIPSテーブルをリロードし、追加されたコンピューティングリソースがロード時間に与える影響を見てみましょう。
ワークシートに戻り、TRUNCATE TABLEコマンドを使用して、テーブルからすべてのデータとメタデータを消去します。
truncate table trips;
以下のコマンドを実行して、テーブルが空になったことを確認します。
--verify table is clear
select * from trips limit 10;
結果には「Query produced no results(クエリで結果が生成されませんでした)」と表示されます。
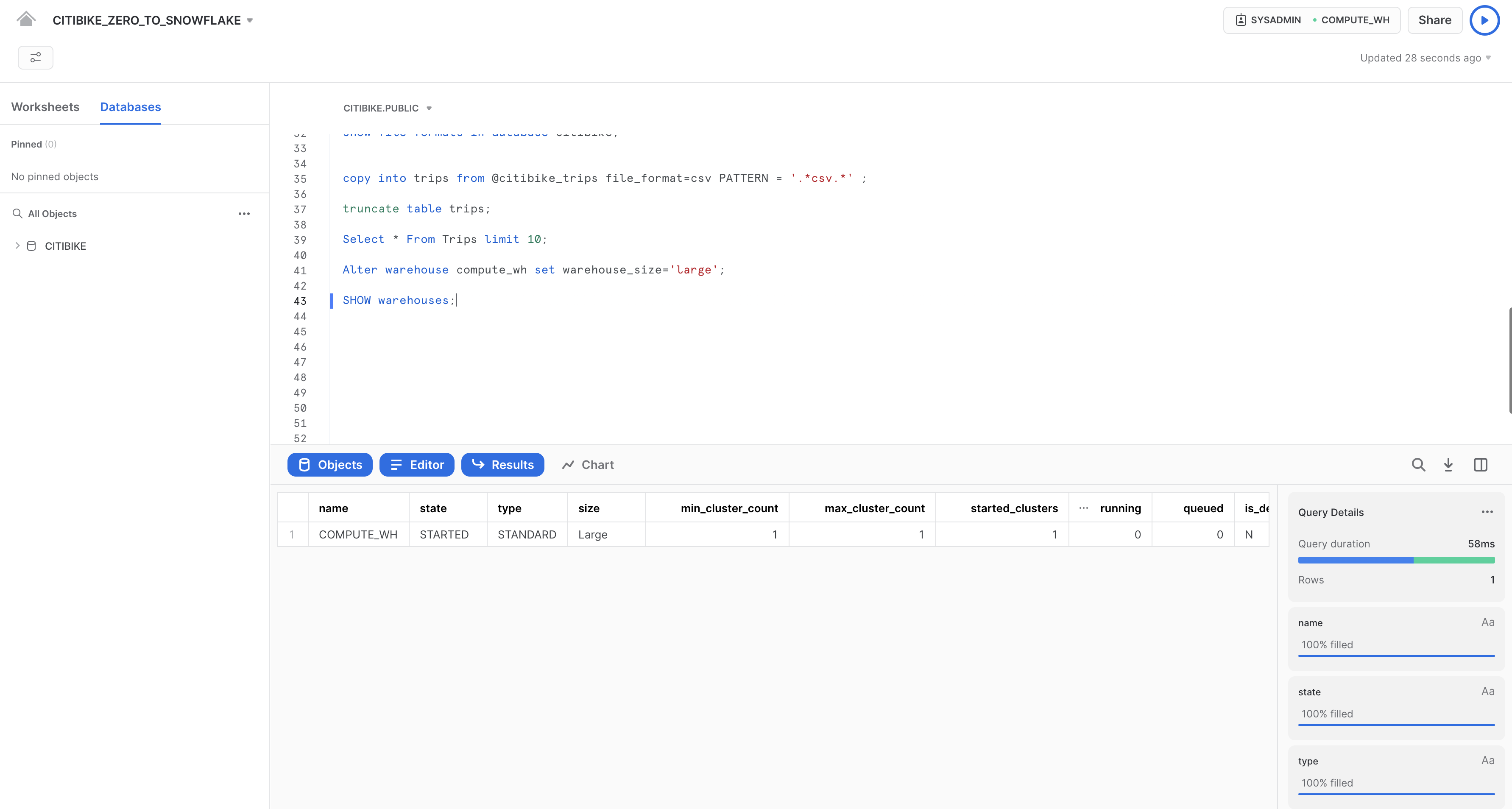
次のALTER WAREHOUSEを使用してウェアハウスのサイズをlargeに変更します。
--change warehouse size from small to large (4x)
alter warehouse compute_wh set warehouse_size='large';
次のSHOW WAREHOUSESを使用して変更を確認します。
--load data with large warehouse
show warehouses;
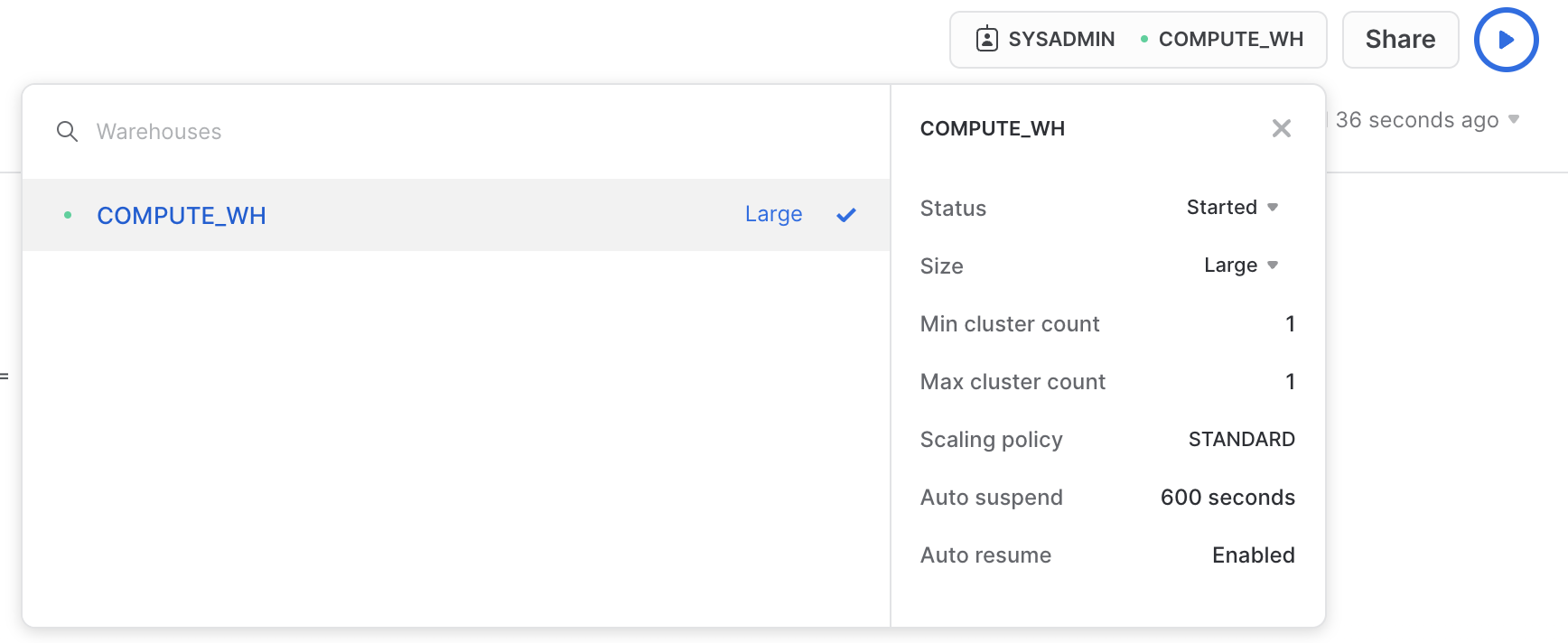
サイズはUIを使用して変更することもできます。その場合は、ワークシートコンテキストボックスをクリックし、コンテキストボックスの右横にある設定(3本線)アイコンをクリックし、「**サイズ」**ドロップダウンでSmallからLargeに変更します。
先ほどと同じCOPY INTOステートメントを実行し、同じデータを再度ロードします。
copy into trips from @citibike_trips
file_format=CSV;
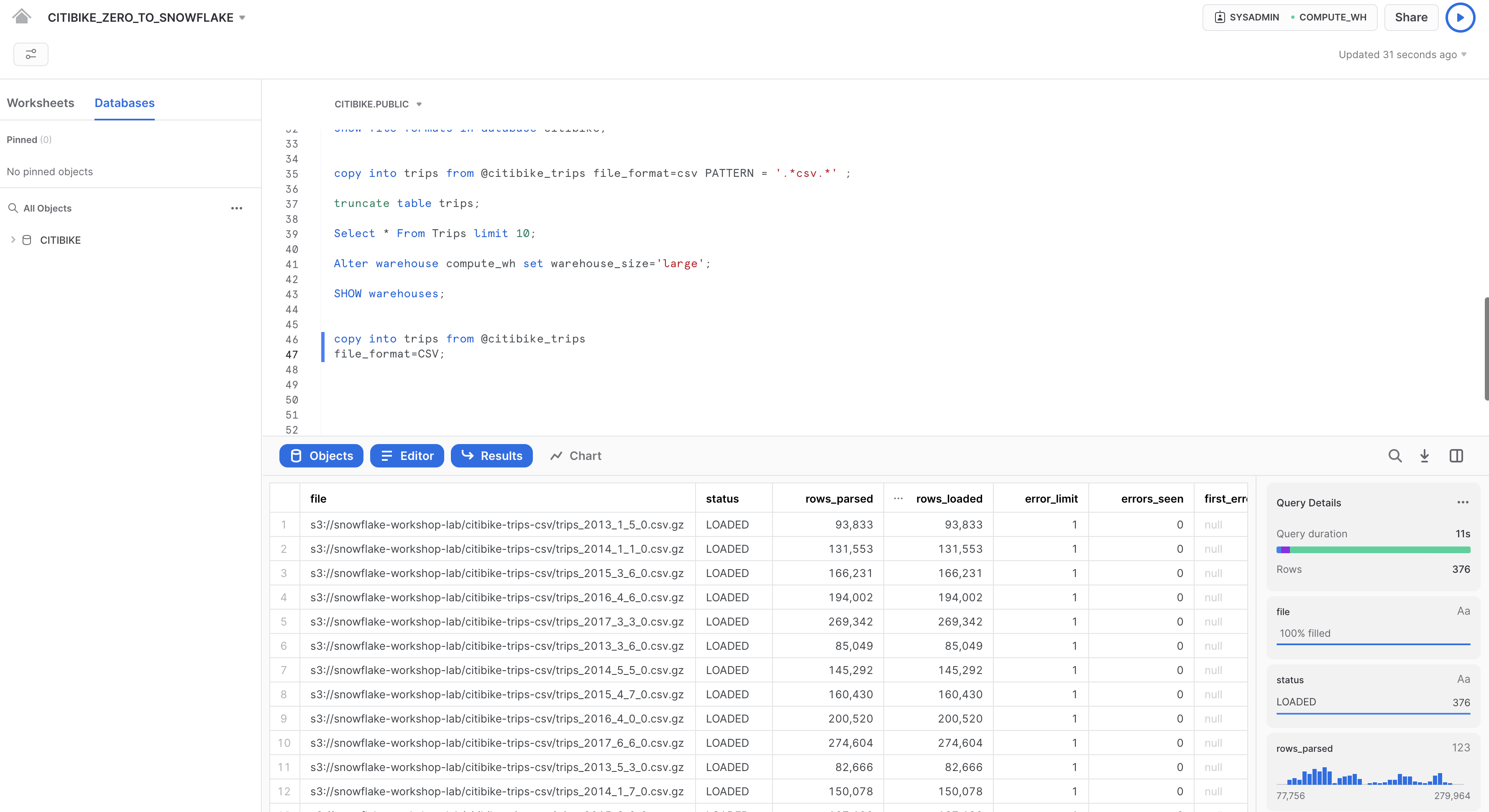
ロードが完了したら、「**クエリ」**ページに戻ります(ホームアイコン、「アクティビティ」、「**クエリ履歴」**の順にクリック)。2つのCOPY INTOコマンドの時間を比較します。Largeウェアハウスを使用してロードするほうが大幅に速いことが分かります。
データアナリティクス用の新しいウェアハウスの作成
ラボストーリーに戻り、Citi Bikeチームがデータロード/ETLワークロードと、BIツールを使用してSnowflakeをクエリする分析エンドユーザーの間でリソースの競合が発生しないようにしたいと考えているとしましょう。前述したように、Snowflakeでは、適切なサイズのさまざまなウェアハウスを各種ワークロードに割り当てることで、これを簡単に実現できます。Citi Bikeには、すでにデータロード用のウェアハウスがあるため、分析を実行するエンドユーザー用に新しいウェアハウスを作成しましょう。次のセクションでは、このウェアハウスを使用して分析を実行します。
「管理」から「ウェアハウス」タブへ進み、「+ウェアハウス」をクリックして新しいウェアハウスの名前を``とし、サイズをLargeに設定します。
Snowflakeエンタープライズエディション(またはそれ以上)を使用しており、「マルチクラスターウェアハウス」が有効になっている場合、追加の設定が表示されます。
- 「最大クラスター」が
1に設定されていることを確認します。 - その他の設定はすべてデフォルトのままにしておきます。
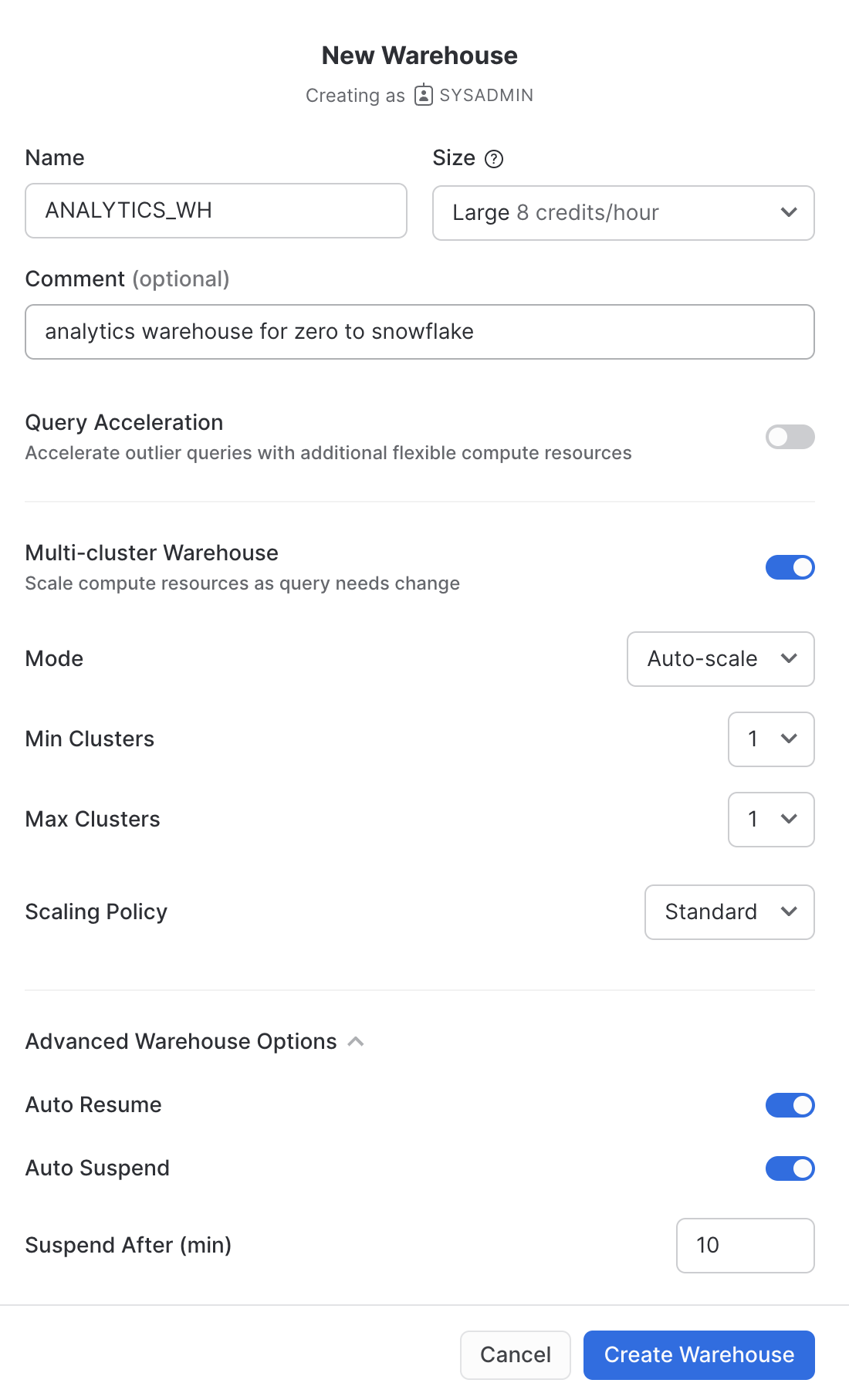
「**ウェアハウスの作成」**ボタンをクリックし、ウェアハウスを作成します。
前の演習では、SnowflakeのCOPY一括ローダーコマンドとCOMPUTE_WH仮想ウェアハウスを使用して、2つのテーブルにデータをロードしました。今回は、Citi Bikeのアナリティクスユーザーとして、ワークシートと2つ目のウェアハウスANALYTICS_WHを使用して、これらのテーブルのデータをクエリします。
クエリの実行
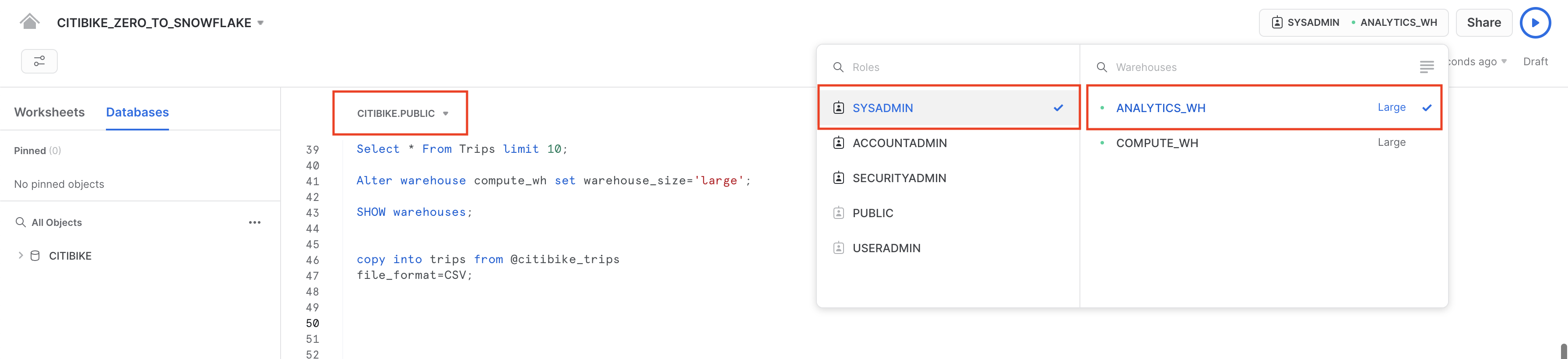
CITIBIKE_ZERO_TO_SNOWFLAKEワークシートに移動し、前のセクションで作成した新しいウェアハウスを使用するよう、ウェアハウスを変更します。ワークシートのコンテキストは次のようになっているはずです。
ロール:SYSADMIN ウェアハウス:ANALYTICS_WH (L) データベース:CITIBIKE スキーマ = PUBLIC
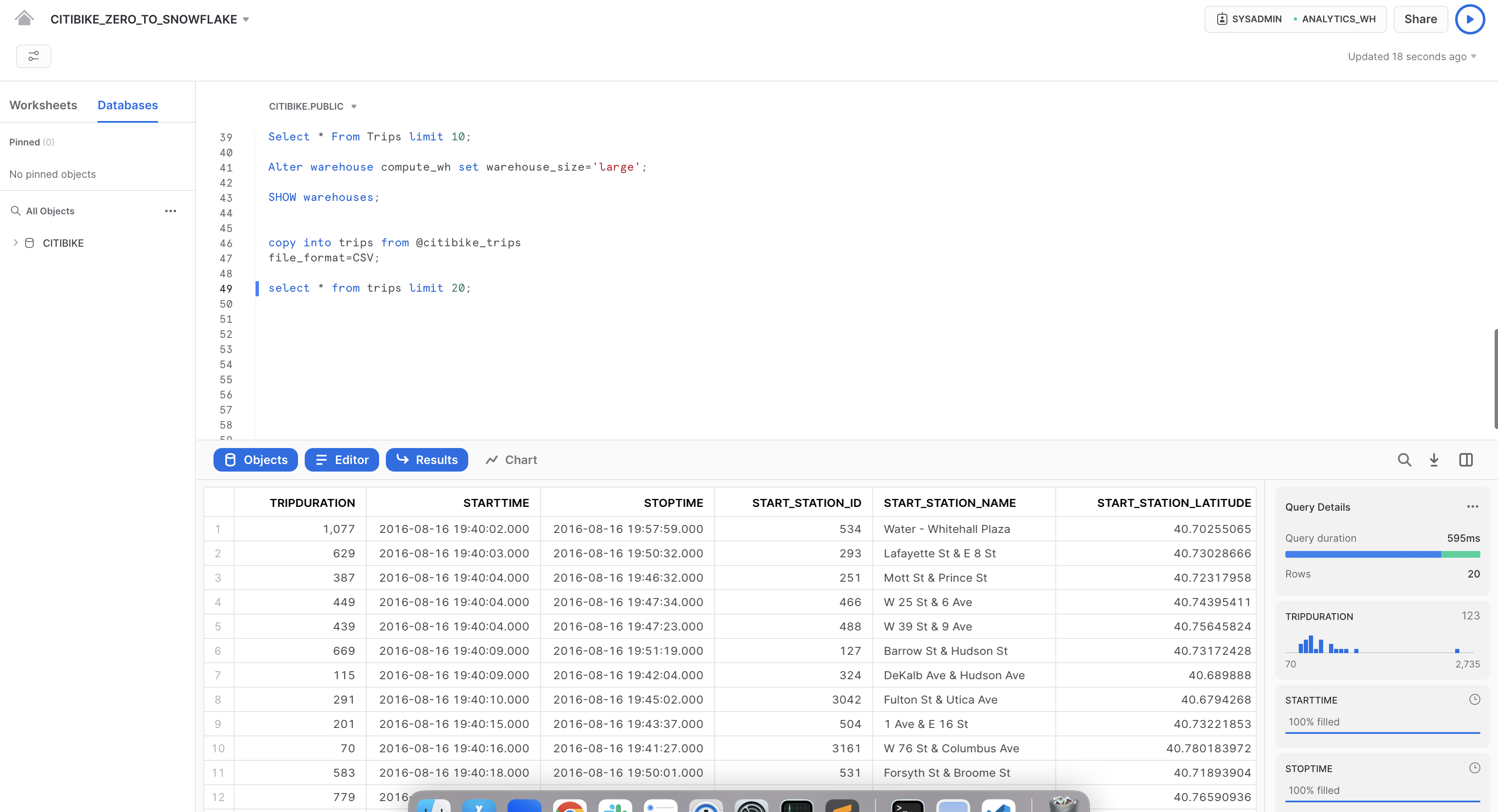
以下のクエリを実行し、tripsデータのサンプルを表示します。
select * from trips limit 20;
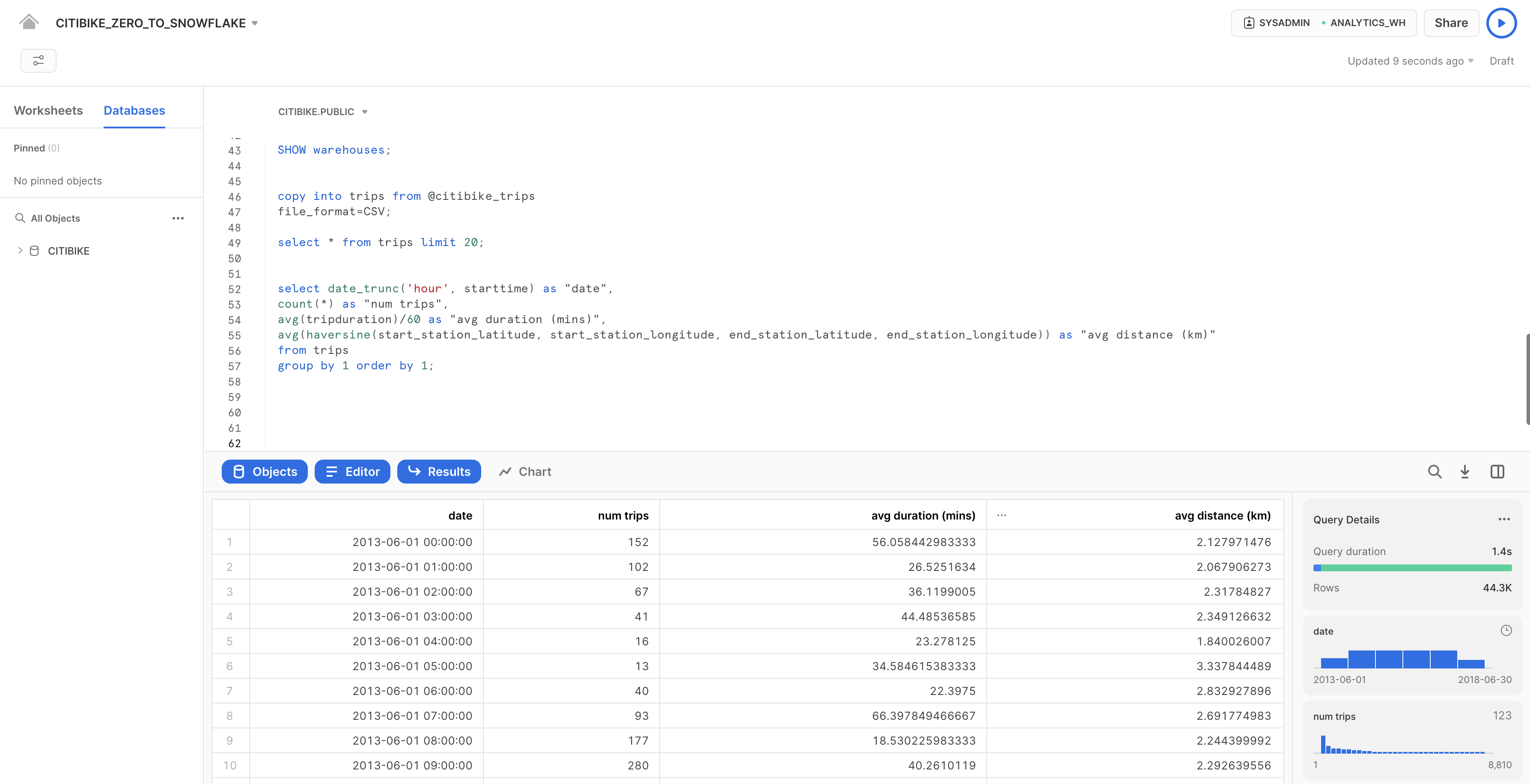
では、Citi Bikeの利用状況に関する基本的な時間別統計をいくつか見ていきましょう。ワークシートで以下のクエリを実行します。それぞれの時間の走行回数、平均走行時間、平均走行距離が表示されます。
select date_trunc('hour', starttime) as "date",
count(*) as "num trips",
avg(tripduration)/60 as "avg duration (mins)",
avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude, end_station_longitude)) as "avg distance (km)"
from trips
group by 1 order by 1;
結果キャッシュの使用
Snowflakeには、過去24時間に実行されたすべてのクエリの結果を保持する結果キャッシュがあります。これはウェアハウスをまたいで利用可能であるため、あるユーザーに返されたクエリ結果を、基礎データが変更されていない限り、同じクエリを実行したシステム上の他のどのユーザーでも利用することができます。このようにクエリ結果を繰り返し返すことで、クエリの実行が非常に高速になるだけでなく、コンピュートクレジットの消費も回避できます。
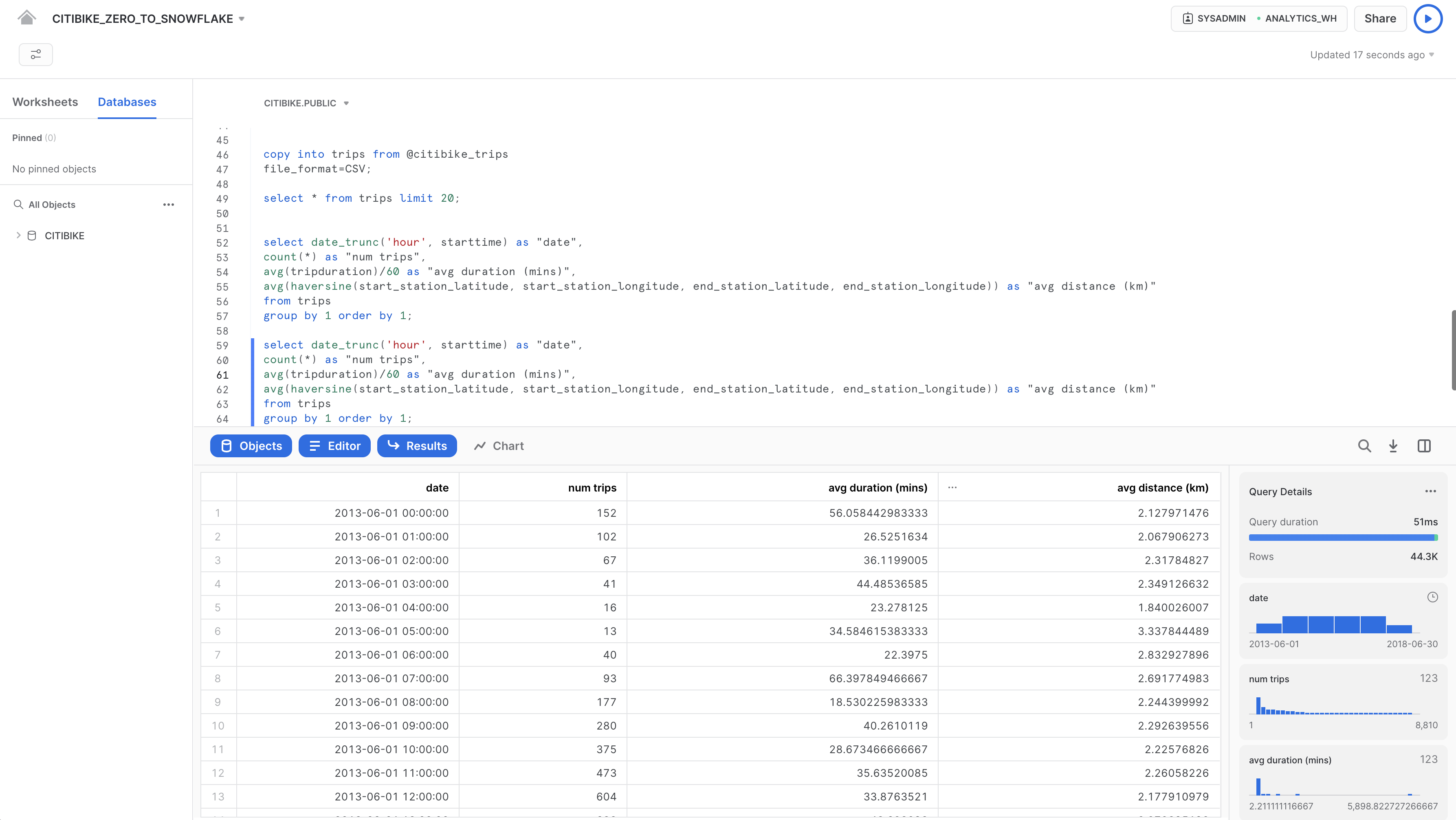
まったく同じクエリを再度実行し、結果キャッシュの動作を見てみましょう。
select date_trunc('hour', starttime) as "date",
count(*) as "num trips",
avg(tripduration)/60 as "avg duration (mins)",
avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude, end_station_longitude)) as "avg distance (km)"
from trips
group by 1 order by 1;
右側の「**クエリの詳細」**ペインで、2回目のクエリ実行速度が大幅に向上していることに注意してください。これは、結果がキャッシュされているためです。
別のクエリの実行
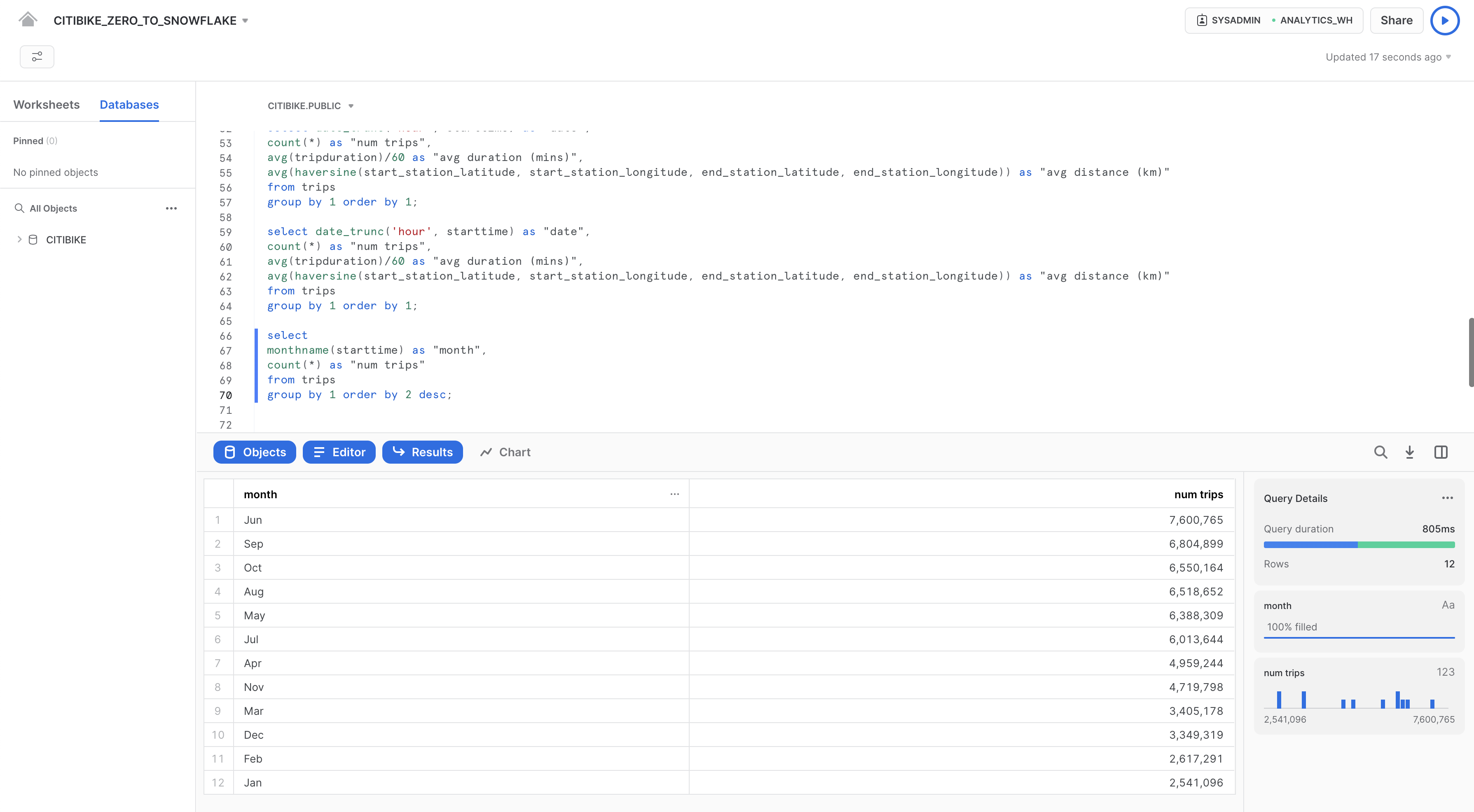
次に、以下のクエリを実行し、どの月が最も忙しいかを確認してみましょう。
select
monthname(starttime) as "month",
count(*) as "num trips"
from trips
group by 1 order by 2 desc;
テーブルの複製
Snowflakeを使用すると、テーブル、スキーマ、およびデータベースのクローンを数秒で作成できます。これは、「ゼロコピークローン」とも呼ばれます。クローンが作成されると、Snowflakeは、ソースオブジェクト内に存在するデータのスナップショットを取得し、クローンオブジェクトでそれを利用できるようにします。クローンオブジェクトは書き込み可能であり、クローン元から独立しています。つまり、ソースオブジェクトまたはクローンオブジェクトのどちらかに加えられた変更は、もう一方のオブジェクトには反映されないということです。
ゼロコピークローニングの一般的なユースケースは、本番環境のクローンを作成し、開発およびテストチームがテストや実験に使用できるようにすることです。こうすることで、本番環境に悪影響が及ぶことがなくなると同時に、2つの別個の環境を設定して管理する必要がなくなります。
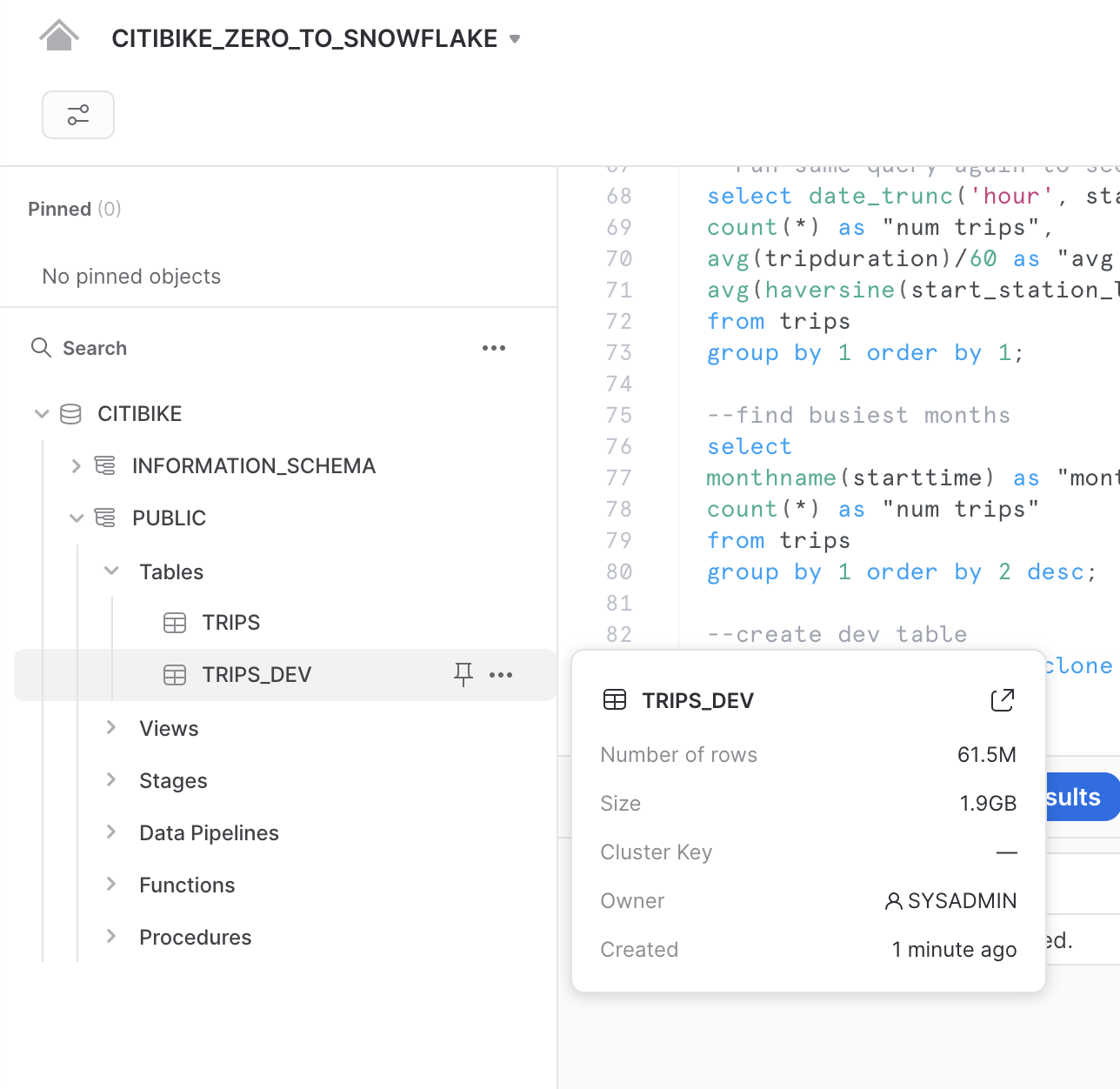
ワークシートで以下のコマンドを実行し、tripsテーブルの開発(dev)テーブルクローンを作成します。
create table trips_dev clone trips;
左のペインで3つの点(...)をクリックし、「**更新」**を選択します。CITIBIKEデータベースの下のオブジェクトツリーを展開し、trips_devという名前の新規テーブルが表示されていることを確認します。これで、開発チームは、tripsテーブルや他のオブジェクトに影響を与えることなく、更新や削除も含め、このテーブルに対してどのような操作でも実行することができるようになります。
ラボの例に戻りましょう。Citi Bikeの分析チームは天候が自転車の利用回数にどのような影響を与えるかを見極めたいと考えています。そのため、このセクションでは次のことを行います。
- 公開されているS3バケットにある半構造化JSON形式の気象データをロードする。
- ビューを作成し、SQLドット表記を使用してJSONデータをクエリする。
- 前にロードした
TRIPSデータにJSONデータを結合するクエリを実行する。 - 気象データと自転車の利用回数データを分析し、それらの関係を見極める。
JSONデータは、MeteoStatによって提供される気象情報で構成されており、2016年7月5日から2019年6月25日までのニューヨーク市の歴史的条件を詳細に示しています。また、AWS S3上でステージングされており、データは75000行、36個のオブジェクトで構成され、1.1MBに圧縮されています。テキストエディタで見ると、GZファイルの未加工JSONは以下のようになります。

データ用に新しいデータベースとテーブルを作成する
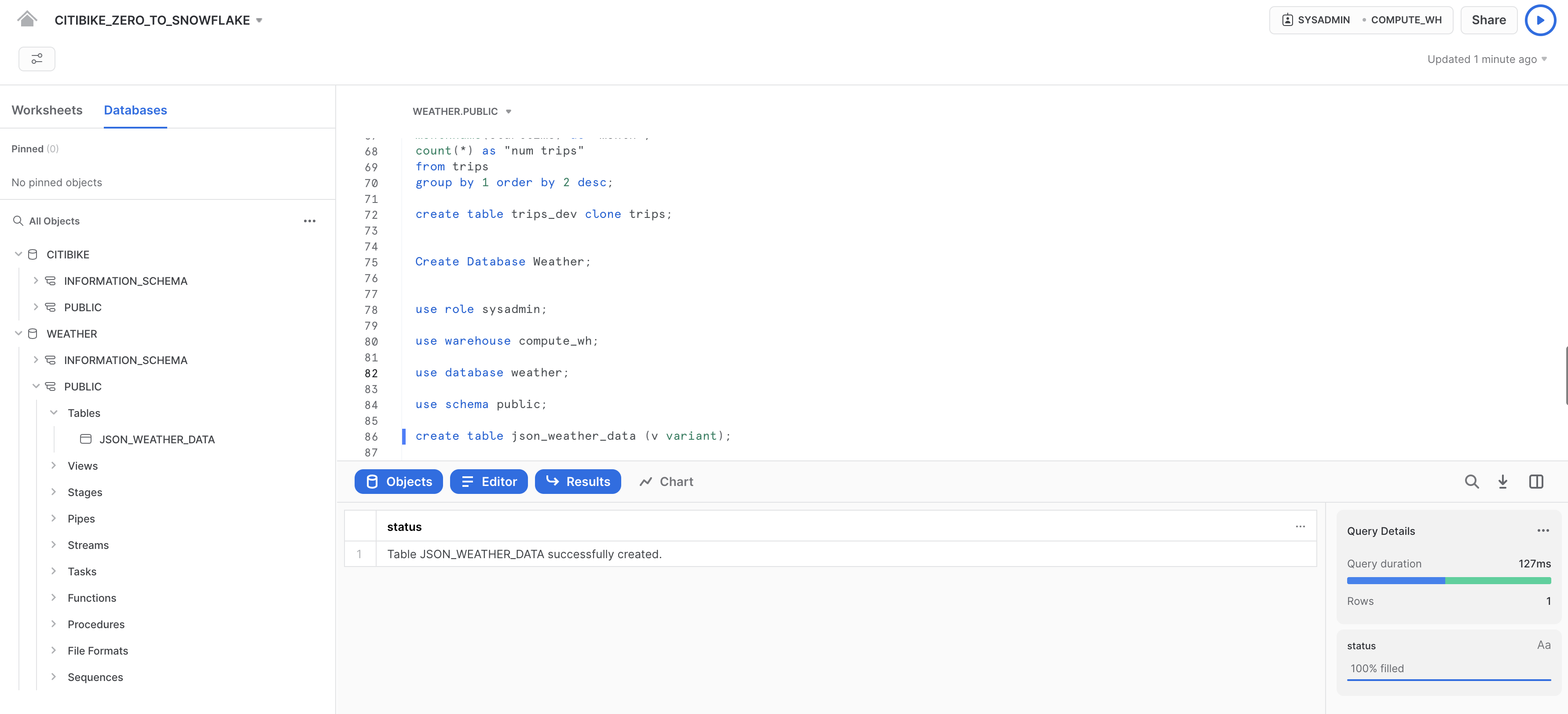
まず、ワークシートで、半構造化JSONデータの格納に使用するWEATHERという名前のデータベースを作成しましょう。
create database weather;
以下のUSEコマンドを実行し、ワークシートのコンテキストを適切に設定します。
use role sysadmin;
use warehouse compute_wh;
use database weather;
use schema public;
次に、JSONデータのロードに使用するJSON_WEATHER_DATAという名前のテーブルを作成しましょう。ワークシートで、次のCREATE TABLEコマンドを実行します。
create table json_weather_data (v variant);
なお、Snowflakeには、JSONオブジェクト全体を単一の行として格納し、最終的にオブジェクトを直接クエリできるようにする、VARIANTという名前の特殊な列データ型があります。
ワークシート下部の結果ペインで、テーブルJSON_WEATHER_DATAが作成されていることを確認します。
別の外部ステージの作成
CITIBIKE_ZERO_TO_SNOWFLAKEワークシートで、以下のコマンドを使用して、半構造化JSONデータがAWS S3に保存されているバケットをポイントするステージを作成します。
create stage nyc_weather
url = 's3://snowflake-workshop-lab/zero-weather-nyc';
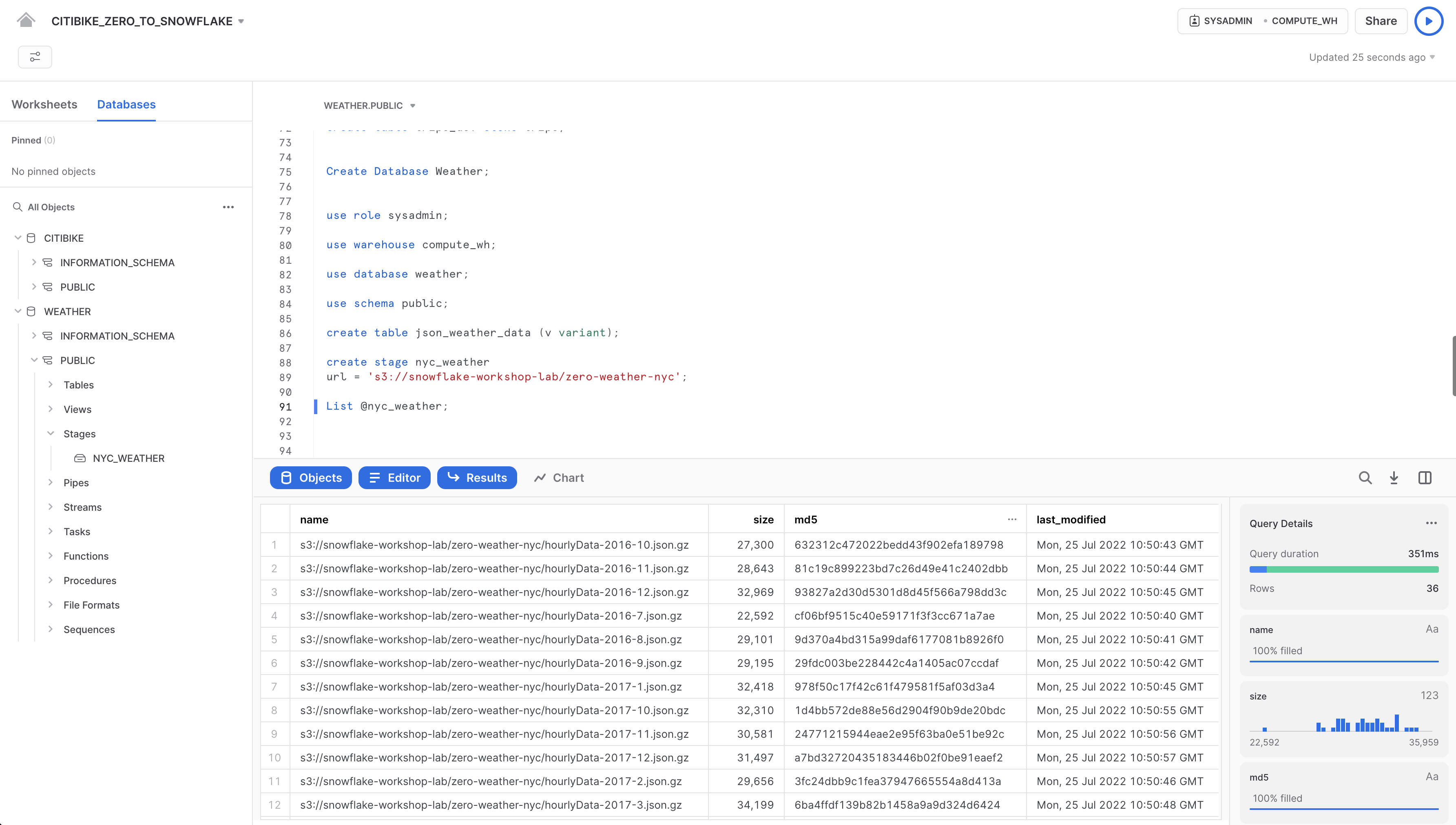
ではnyc_weatherステージのコンテンツを見ていきましょう。以下のLISTコマンドを実行して、ファイルのリストを表示します。
list @nyc_weather;
結果ペインにS3からの.gzファイルのリストが表示されます。
半構造化データのロードと検証
このセクションでは、ウェアハウスを使用して、S3バケットからのデータを先ほど作成したJSON_WEATHER_DATAテーブルにロードします。
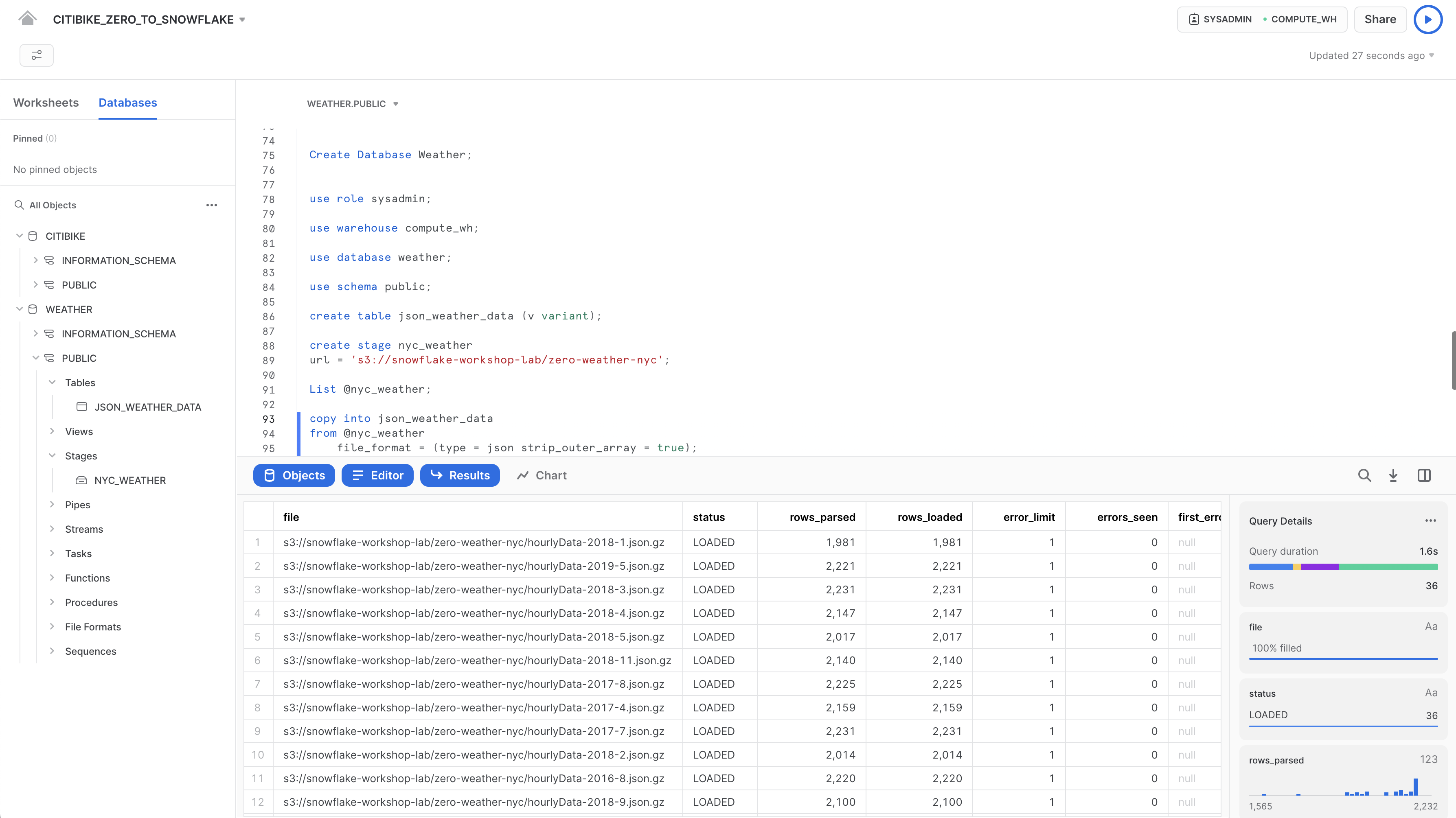
CITIBIKE_ZERO_TO_SNOWFLAKEワークシートで、以下のCOPYコマンドを実行し、データをロードします。
なお、FILE FORMATオブジェクトはコマンド内のインラインで指定できます。構造化データをCSV形式でロードした前のセクションでは、CSV構造に対応するファイル形式を定義する必要がありました。ここでのJSONデータは整形式であるため、JSONタイプを指定するだけで、すべてのデフォルト設定を使用することができます。
copy into json_weather_data
from @nyc_weather
file_format = (type = json strip_outer_array = true);
各ファイルのステータスがLOADEDとなっていること確認します。
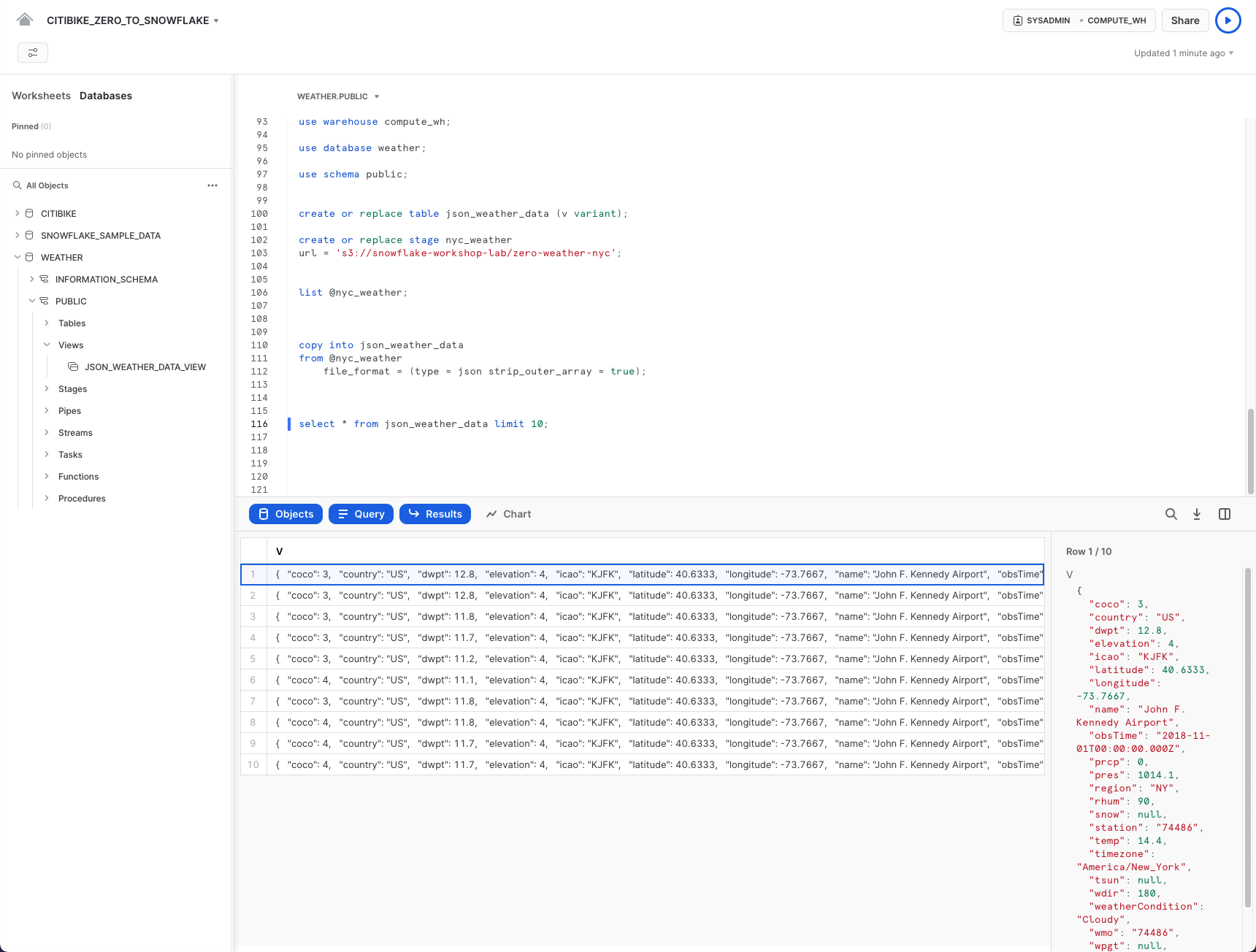
では、ロードされたデータを見ていきましょう。
select * from json_weather_data limit 10;
いずれかの行をクリックすると、右側のパネルにフォーマットされたJSONが表示されます。
パネル内の表示を閉じてクエリの詳細を再度表示するには、パネルの右隅にカーソルを合わせると表示されるX(閉じる)ボタンをクリックします。
ビューの作成と半構造化データのクエリ
次に、Snowflakeでビューを作成し、SQLを使用してJSONデータを直接クエリする方法を見ていきましょう。
以下のコマンドを実行して、半構造化JSON気象データの列ビューを作成します。こうすることで、アナリストによるデータの理解とクエリの実行が容易になります。station_idの72502という値は、ニューアーク空港に対応しています。ここは、全期間の気象条件を有する最も近いステーションです。
// create a view that will put structure onto the semi-structured data
create or replace view json_weather_data_view as
select
v:obsTime::timestamp as observation_time,
v:station::string as station_id,
v:name::string as city_name,
v:country::string as country,
v:latitude::float as city_lat,
v:longitude::float as city_lon,
v:weatherCondition::string as weather_conditions,
v:coco::int as weather_conditions_code,
v:temp::float as temp,
v:prcp::float as rain,
v:tsun::float as tsun,
v:wdir::float as wind_dir,
v:wspd::float as wind_speed,
v:dwpt::float as dew_point,
v:rhum::float as relative_humidity,
v:pres::float as pressure
from
json_weather_data
where
station_id = '72502';
このコマンドでは、SQLドット表記であるv:tempを使用してJSONオブジェクト階層内の下位レベルの値を取得します。これにより、各フィールドをリレーショナルテーブルの列のように扱うことができます。
新しいビューは、オブジェクトブラウザの左側のWEATHER > PUBLIC > 「ビュー」の下にJSON_WEATHER_DATAとして表示されます。このビューを表示するには、オブジェクトブラウザの展開または更新が必要になる場合があります。
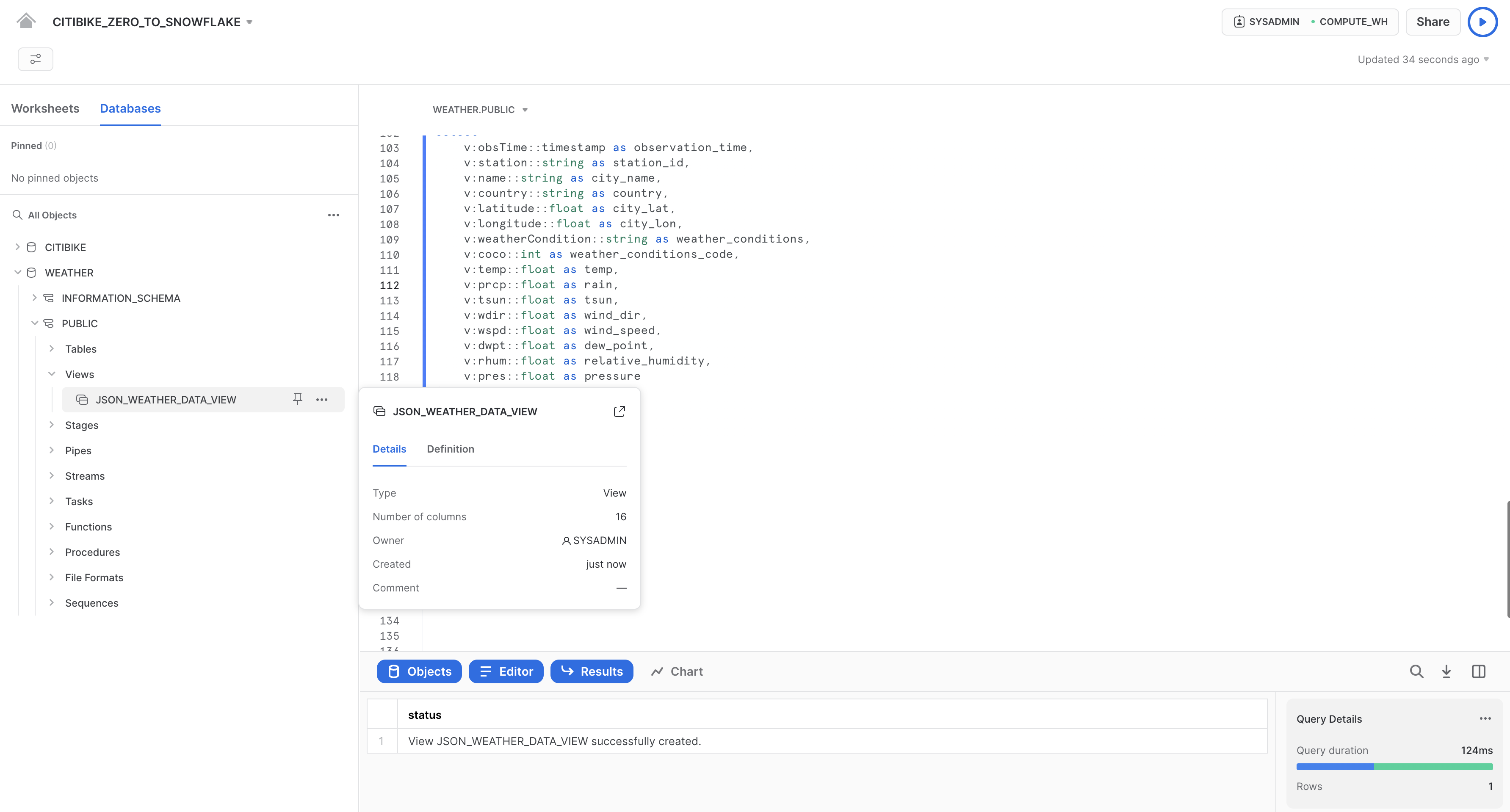
以下のクエリでビューを確認します。
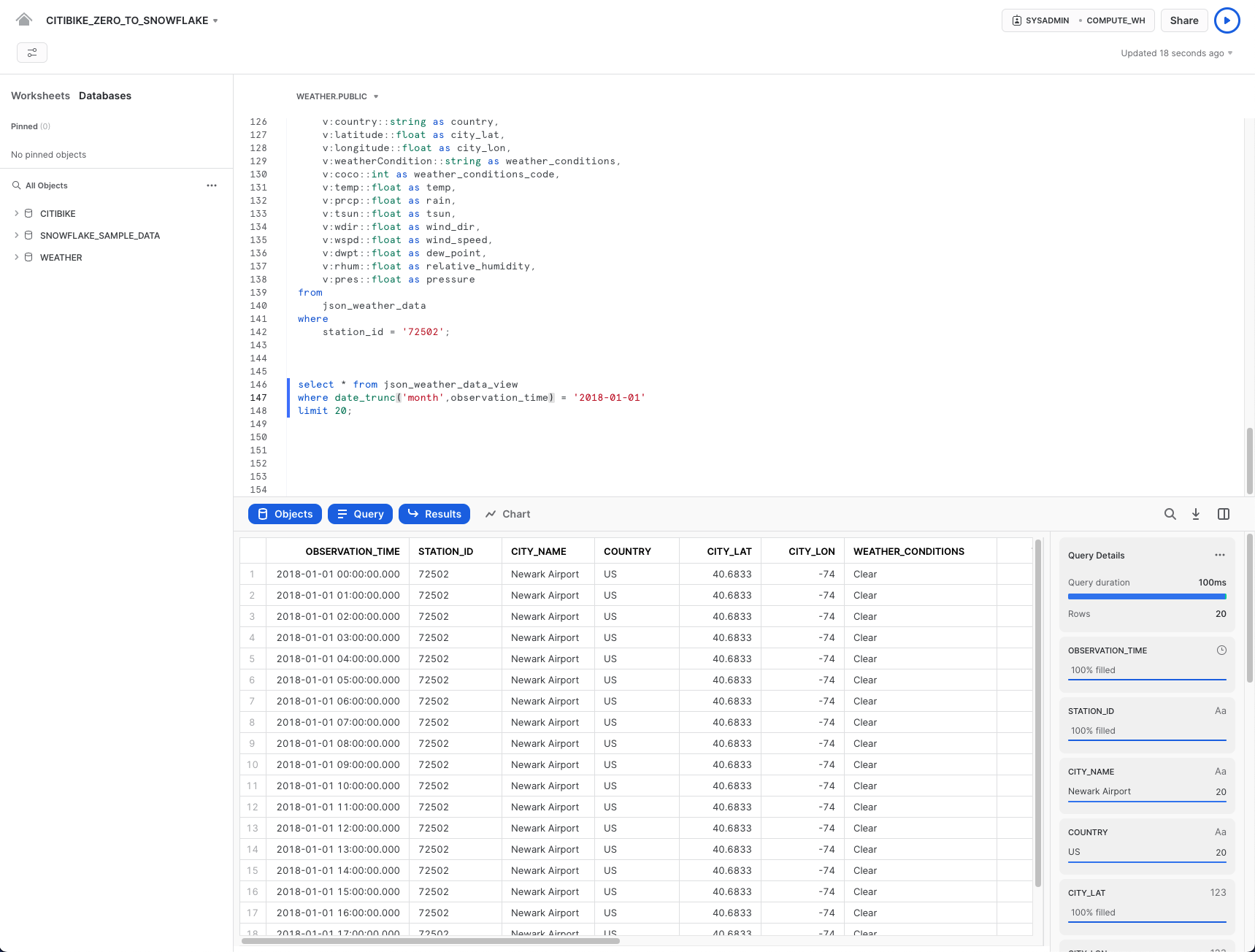
select * from json_weather_data_view
where date_trunc('month',observation_time) = '2018-01-01'
limit 20;
結果は、通常の構造化データソースと同じように見えることに注意してください。皆さんの結果セットではobservation_timeの値が異なる場合があります。
結合操作を使用してデータセットに対して相関させる
ここで、天候が自転車の利用回数にどのような影響を与えるかという当初の質問に答えるために、JSON気象データをCITIBIKE.PUBLIC.TRIPSデータに結合します。
以下のクエリを実行して、WEATHERをTRIPSに結合し、特定の天候条件に関連する走行回数をカウントします。
select weather_conditions as conditions
,count(*) as num_trips
from citibike.public.trips
left outer join json_weather_data_view
on date_trunc('hour', observation_time) = date_trunc('hour', starttime)
where conditions is not null
group by 1 order by 2 desc;
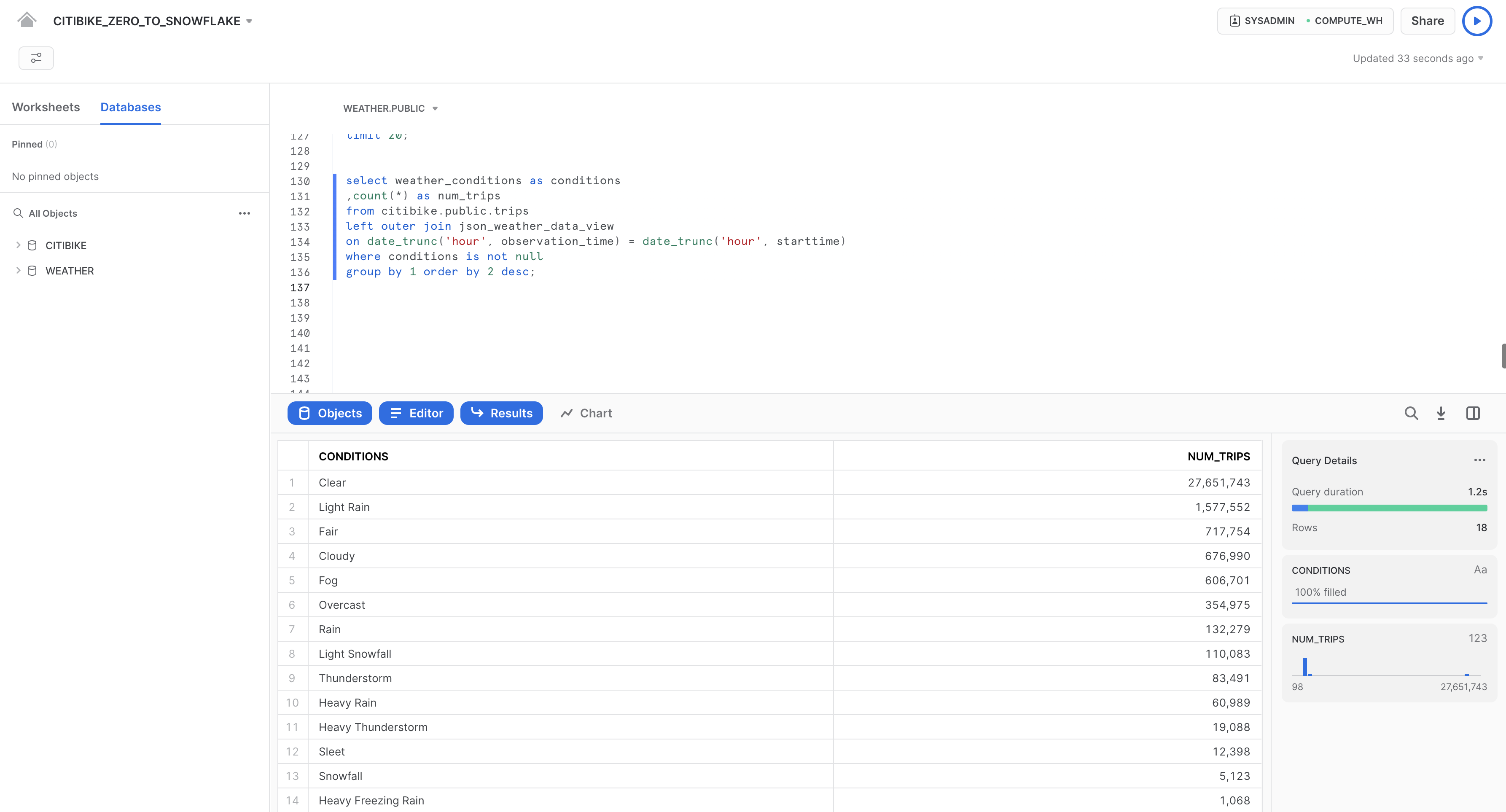
当初の目標は、自転車の利用者数データと気象データの両方を分析することで、自転車に乗る回数と天候の間に何らかの相関関係があるかどうかを判断することでした。上記の結果から、明確な答えが得られました。想像のとおり、天候が良好であれば走行回数はかなり多くなっています。
Snowflakeの強力なタイムトラベル機能を使用すると、履歴データや、データを格納するオブジェクトに、一定期間内の任意の時点でアクセスすることができます。デフォルトの期間の幅は24時間ですが、Snowflakeエンタープライズエディションを使用している場合は、最大90日間まで増やすことができます。ほとんどのデータウェアハウスではこの機能が提供されていませんが、Snowflakeではこれを簡単に実行できます。
次に、便利な適用例をいくつかご紹介します。
- 削除されたデータ関連オブジェクト(テーブル、スキーマ、データベースなど)を復元する。
- 過去の重要な時点のデータを複製し、バックアップする。
- 特定の期間におけるデータの使用状況および操作を分析する。
テーブルのドロップとドロップ解除
まず、誤って、または意図的に削除されたデータオブジェクトを復元する方法を見てみましょう。
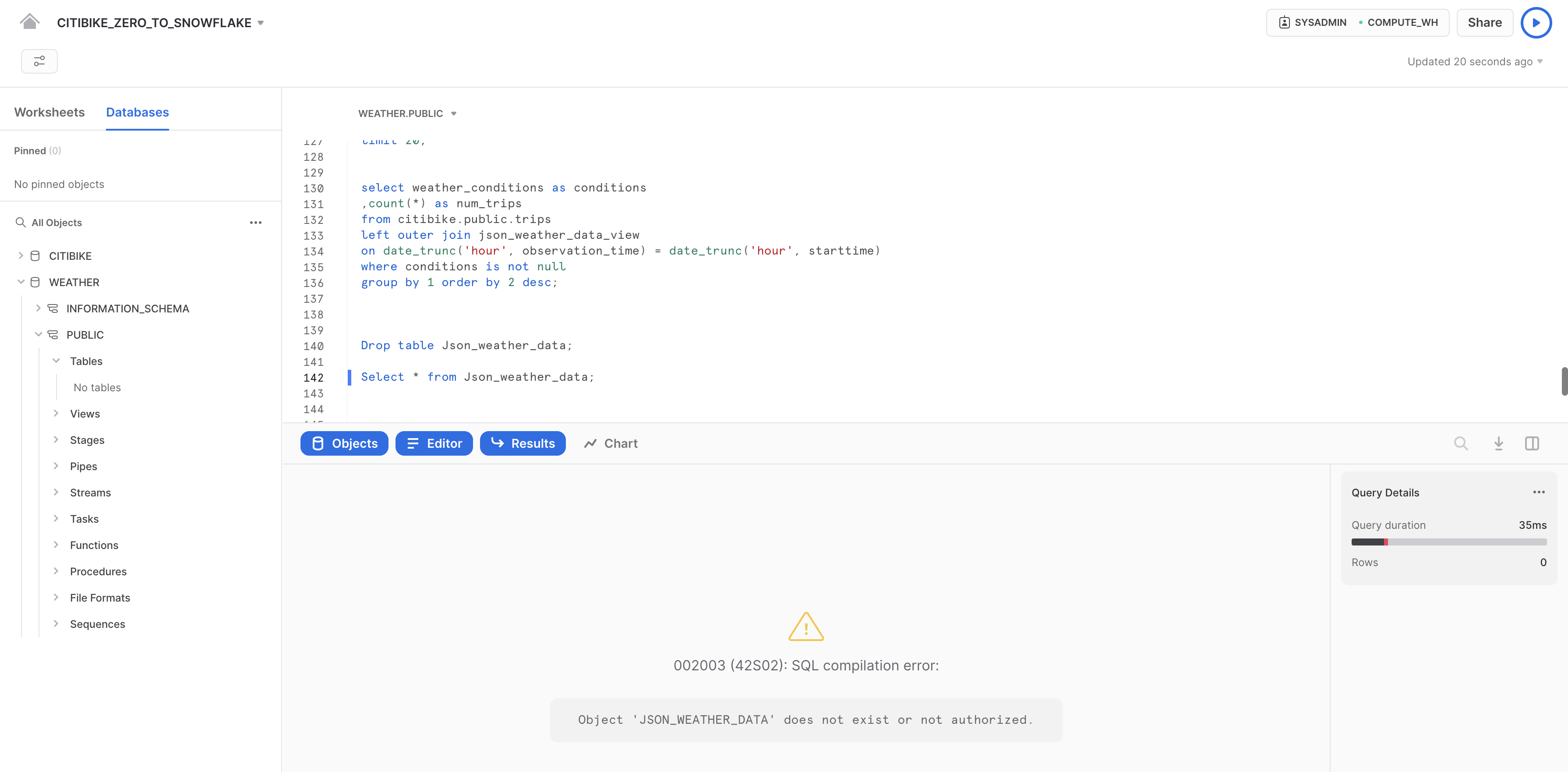
CITIBIKE_ZERO_TO_SNOWFLAKEワークシートで、以下のDROPコマンドを実行し、JSON_WEATHER_DATAテーブルを削除します。
drop table json_weather_data;
テーブルに対してクエリを実行します。
select * from json_weather_data limit 10;
基礎テーブルがドロップされているため、下部の結果ペインにはエラーが表示されます。
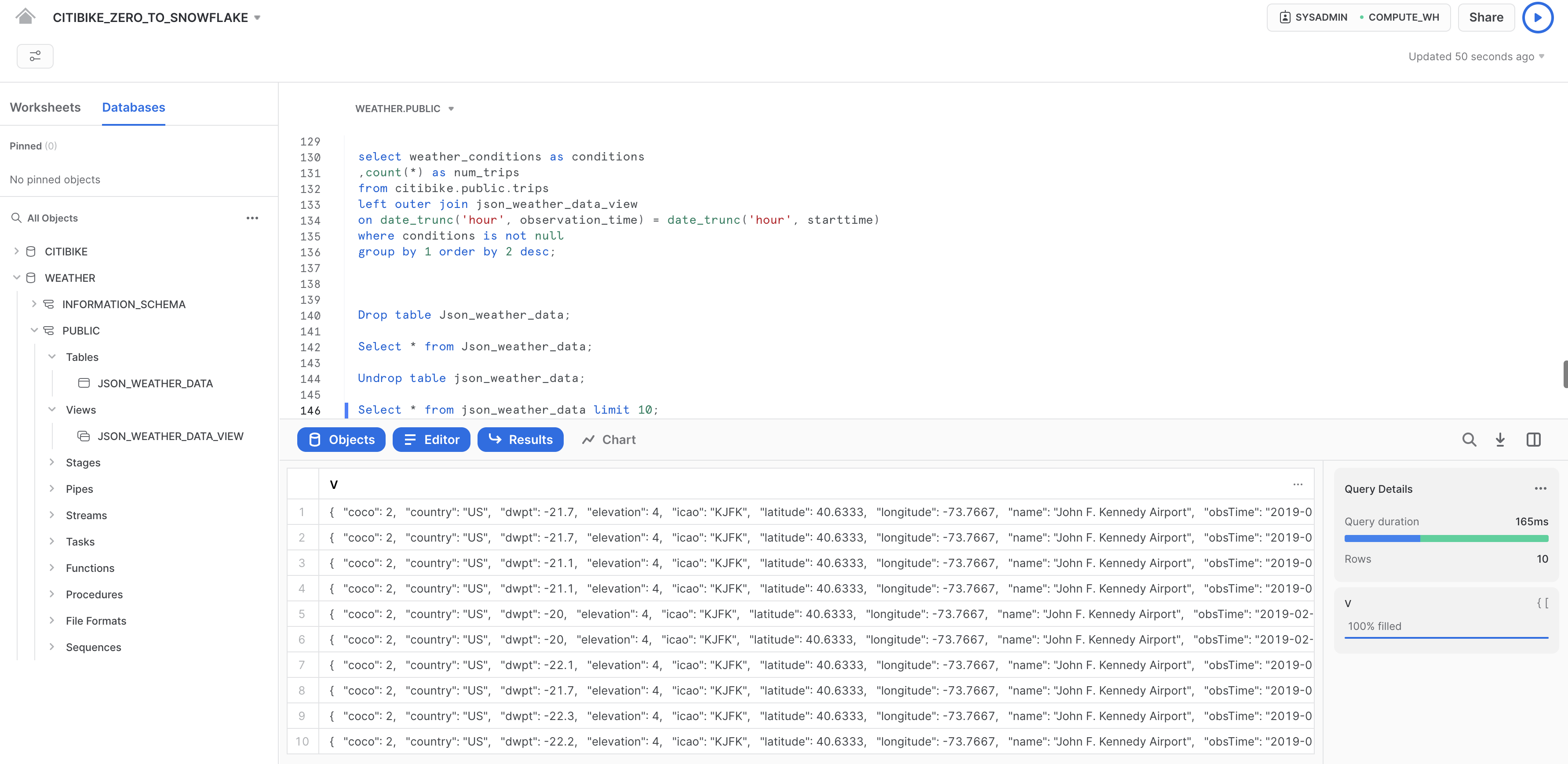
次に、テーブルを復元します。
undrop table json_weather_data;
json_weather_dataテーブルが復元されたはずです。以下のクエリを実行して確認してください。
--verify table is undropped
select * from json_weather_data limit 10;
テーブルのロールバック
CITIBIKEデータベース内のTRIPSテーブルを以前の状態にロールバックし、テーブル内のステーション名をすべて「oops」という単語に置き換えてしまう、意図しないDMLエラーを修正してみましょう。
まず、以下のSQLステートメントを実行し、ワークシートを正しいコンテキストに切り替えます。
use role sysadmin;
use warehouse compute_wh;
use database citibike;
use schema public;
以下のコマンドを実行し、テーブル内のすべての駅名を「oops」という単語に置き換えます。
update trips set start_station_name = 'oops';
次に、自転車の利用回数の上位20ステーションを返すクエリを実行します。ステーション名の結果に1行しか含まれていないことに注意してください。
select
start_station_name as "station",
count(*) as "rides"
from trips
group by 1
order by 2 desc
limit 20;
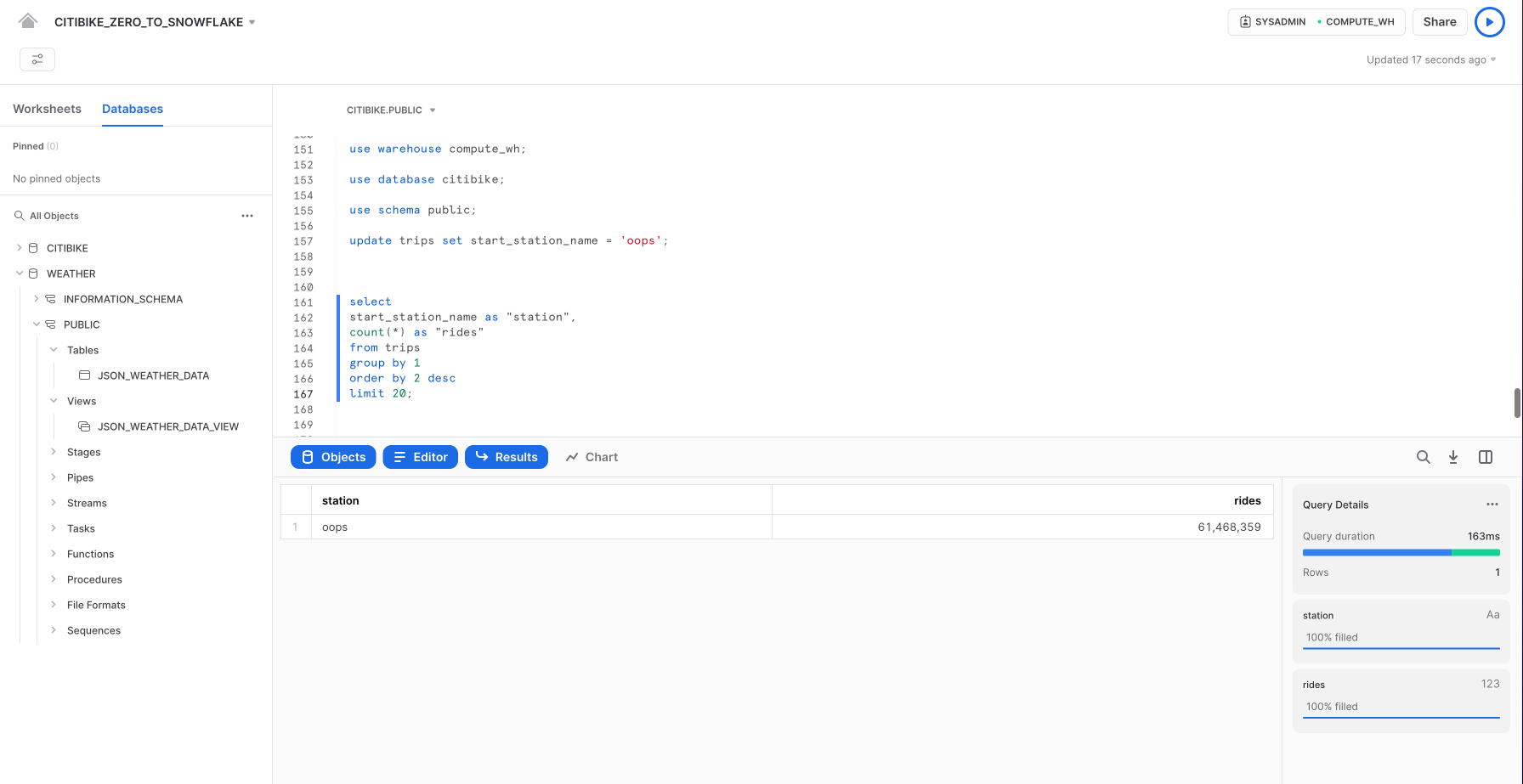
通常であれば、バックアップがあることを祈りながらあれこれ奔走するところです。
Snowflakeでは、1つのコマンドを実行するだけで、直近のUPDATEコマンドのクエリIDを見つけ、それを$QUERY_IDという名前の変数に格納することができます。
set query_id =
(select query_id from table(information_schema.query_history_by_session (result_limit=>5))
where query_text like 'update%' order by start_time desc limit 1);
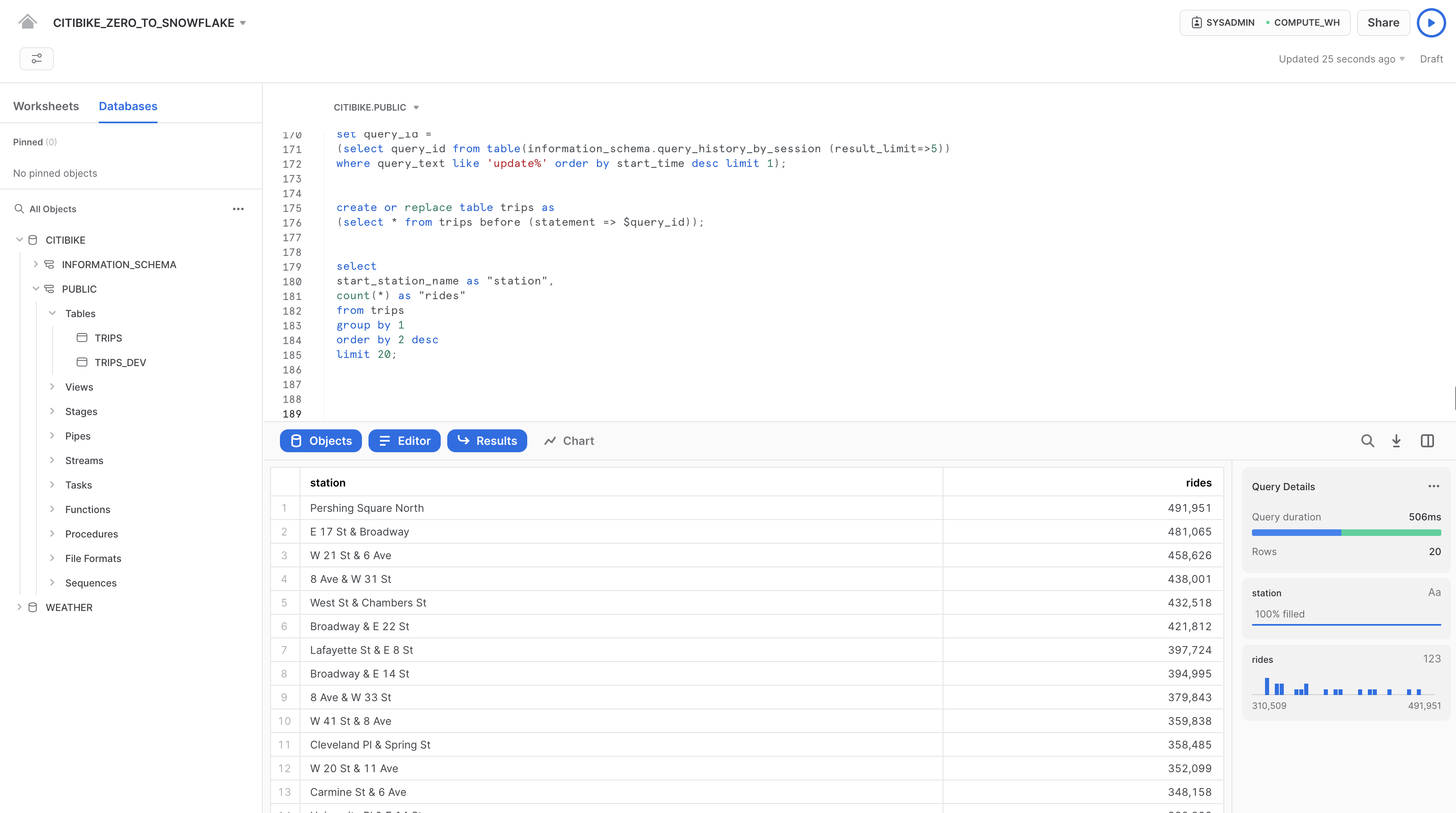
タイムトラベルを使用して、正しいステーション名でテーブルを作り直します。
create or replace table trips as
(select * from trips before (statement => $query_id));
前のクエリを再度実行し、ステーション名が復元されていることを確認します。
select
start_station_name as "station",
count(*) as "rides"
from trips
group by 1
order by 2 desc
limit 20;
このセクションでは、ロールの作成やロールへの特定の権限の付与など、Snowflakeのアクセス制御セキュリティモデルについて説明します。また、ラボの前半で簡単に紹介したACCOUNTADMIN(アカウント管理者)ロールのその他の用途についても検討します。
ラボストーリーを続けます。ここでは、ある若手のDBAがCiti Bikeに入社し、システム定義のデフォルトロールであるSYSADMINよりも権限の少ない新しいロールを作成するとしましょう。
新しいロールの作成とユーザーの追加
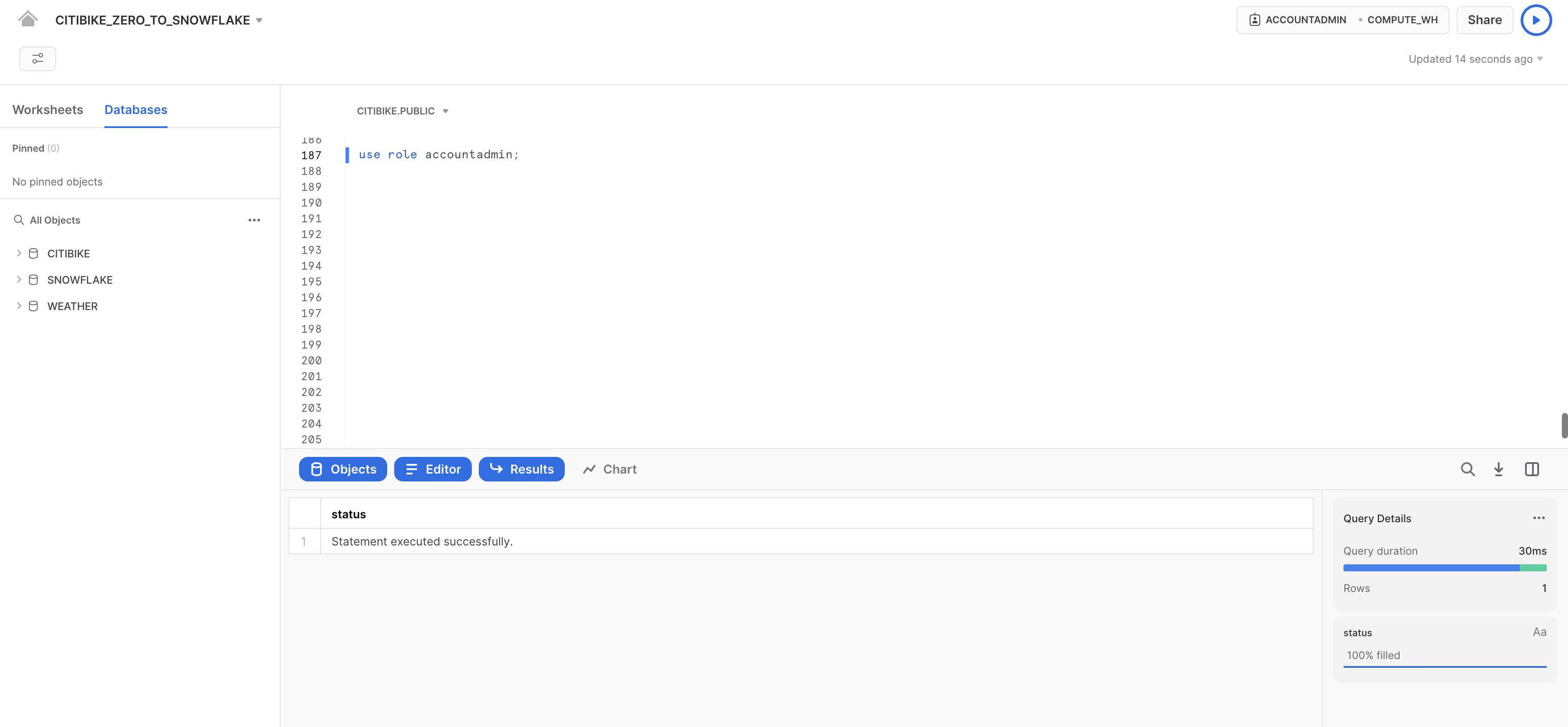
CITIBIKE_ZERO_TO_SNOWFLAKEワークシートでACCOUNTADMINロールに切り替え、新しいロールを作成します。ACCOUNTADMINは、SYSADMINとSECURITYADMINのシステム定義ロールをカプセル化したものです。これはアカウントの最上位のロールであり、限られた数のユーザーにのみ付与する必要があります。
CITIBIKE_ZERO_TO_SNOWFLAKEワークシートで以下のコマンドを実行します。
use role accountadmin;
ワークシートの右上で、コンテキストがACCOUNTADMINに変更されていることに注意してください。
ロールをアクセス制御で使用できるようにするには、少なくとも1人のユーザーがそのロールに割り当てられている必要があります。では、JUNIOR_DBAという名前の新しいロールを作成し、Snowflakeユーザーに割り当ててみましょう。このタスクを完了するには、ユーザー名を把握している必要があります。ユーザー名は、自分がUIにログインするときに使用した名前です。
以下のコマンドを使用して、ロールを作成し、それを自分に割り当てます。GRANT ROLEコマンドを実行する前に、YOUR_USERNAME_GOES_HEREを自分のユーザー名に置き換えてください。
create role junior_dba;
grant role junior_dba to user YOUR_USERNAME_GOES_HERE;
ワークシートのコンテキストを、新しいJUNIOR_DBAロールに変更します。
use role junior_dba;
ワークシートの右上で、コンテキストが変更され、JUNIOR_DBAロールが反映されていることに注意してください。
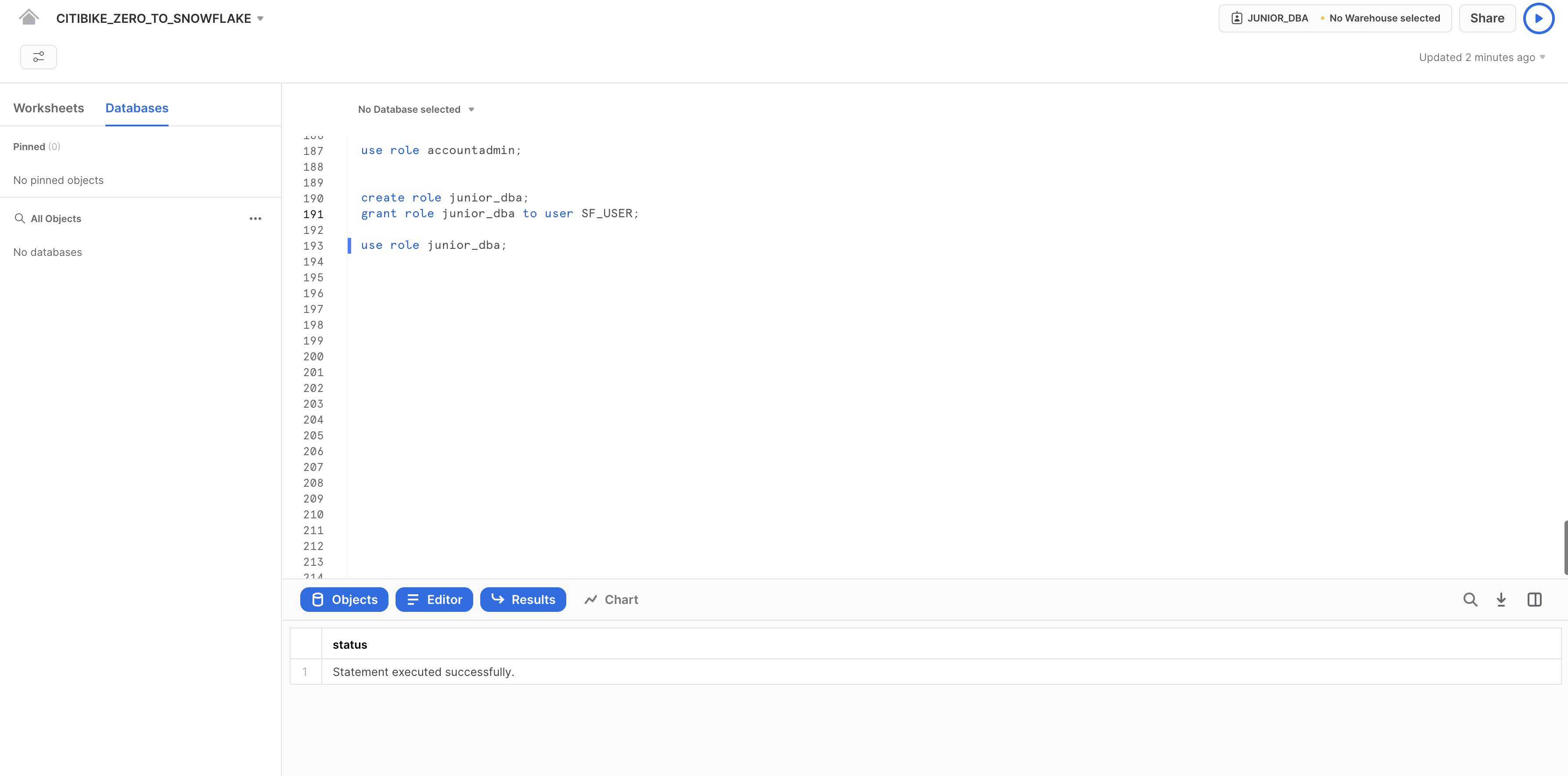
また、新しく作成されたロールにはウェアハウスの使用権限がないため、ウェアハウスは選択されていません。ADMINロールに戻し、COMPUTE_WHウェアハウスの使用権限を付与することで、この問題を解決しましょう。
use role accountadmin;
grant usage on warehouse compute_wh to role junior_dba;
JUNIOR_DBAロールに戻します。これでCOMPUTE_WHを使用できるようになりました。
use role junior_dba;
use warehouse compute_wh;
最後に、左のデータベースオブジェクトブラウザパネルにデータベース、CITIBIKEとWEATHERが表示されなくなったことに気付くでしょう。これは、JUNIOR_DBAロールにはそれらにアクセスする権限がないためです。
ACCOUNTADMINロールに再度切り替えて、データベースCITIBIKEおよびWEATHERを表示し使用するために必要な使用権限をJUNIOR_DBAに付与します。
use role accountadmin;
grant usage on database citibike to role junior_dba;
grant usage on database weather to role junior_dba;
JUNIOR_DBAロールに切り替えます。
use role junior_dba;
これで、左のデータベースオブジェクトブラウザにデータベースCITIBIKEおよびWEATHERが表示されるようになりました。表示されない場合は、パネルの**...**をクリックし、その後「**更新**」をクリックしてみてください。
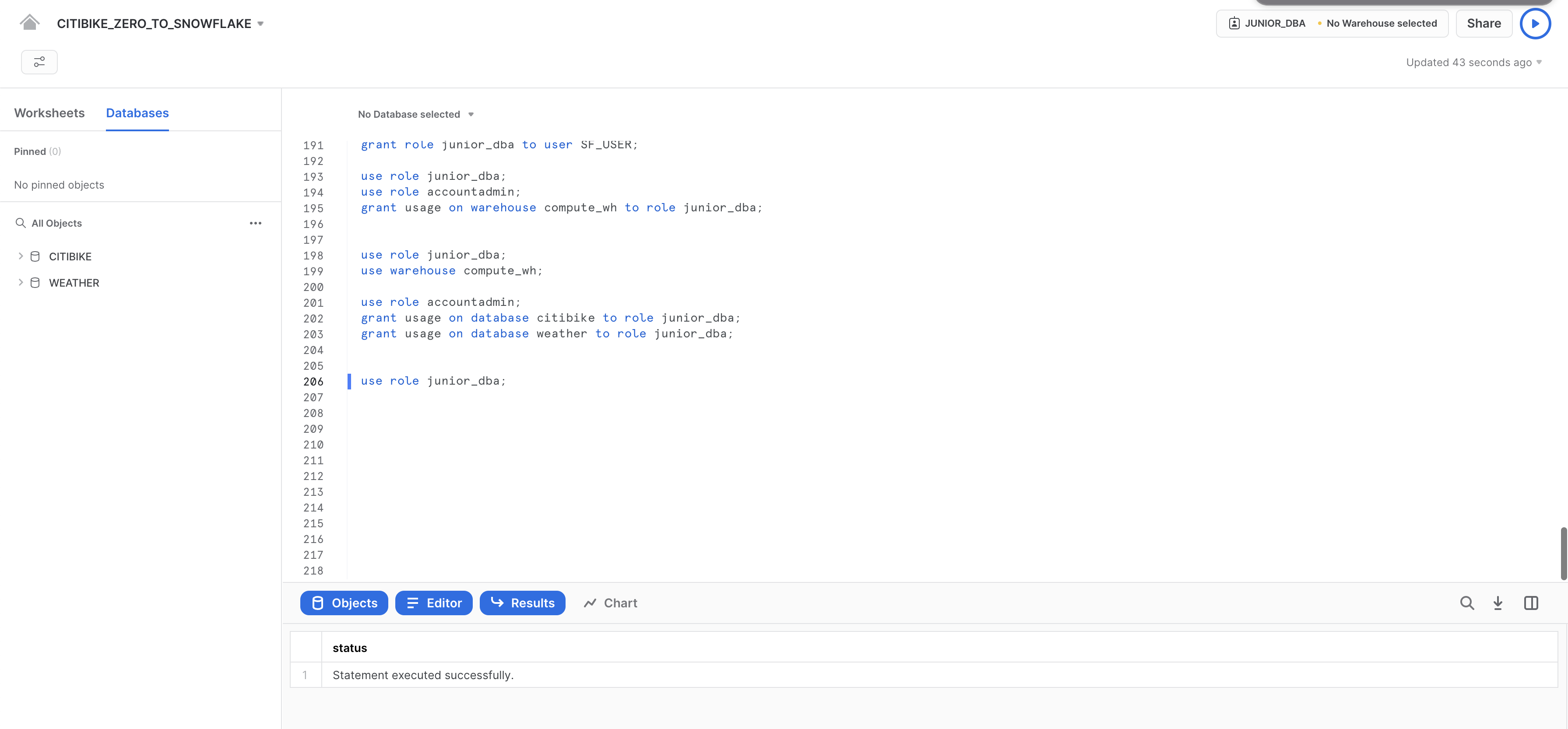
アカウント管理者UIの表示
では、このロールのみがアクセスできるUIのその他の領域を確認するために、アクセス制御ロールをACCOUNTADMINに戻してみましょう。ただし、このタスクの実行には、ワークシートではなくUIを使用します。
まず、ワークシート左上のホームアイコンをクリックします。次に、UIの左上にある自分の名前をクリックし、ユーザー設定メニューを表示します。メニューで「ロールの切り替え」へ進み、ACCOUNTADMINを選択します。
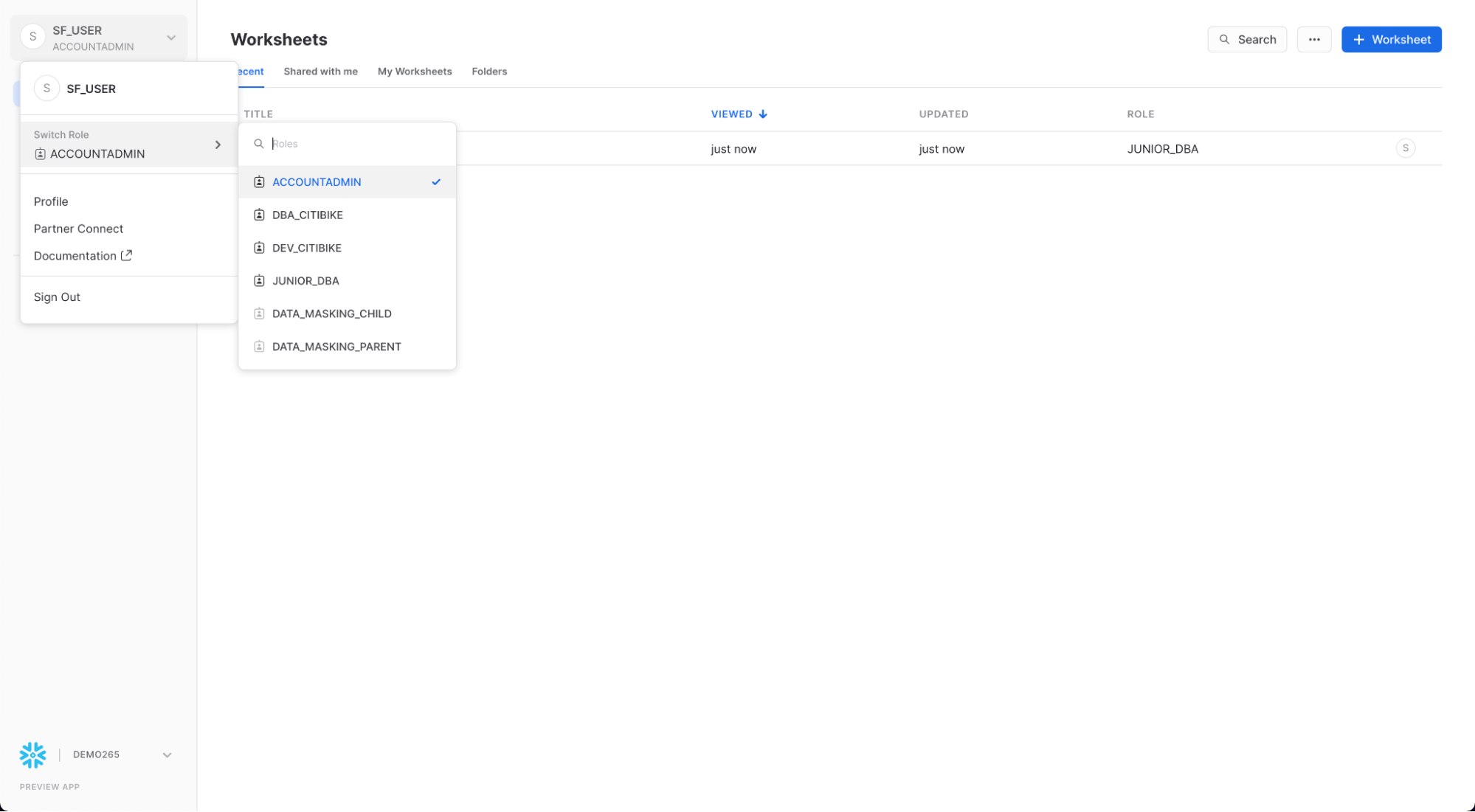
UIセッションをACCOUNTADMINロールに切り替えると、「管理」の下で新しいタブが利用できるようになることに注意してください。
使用状況
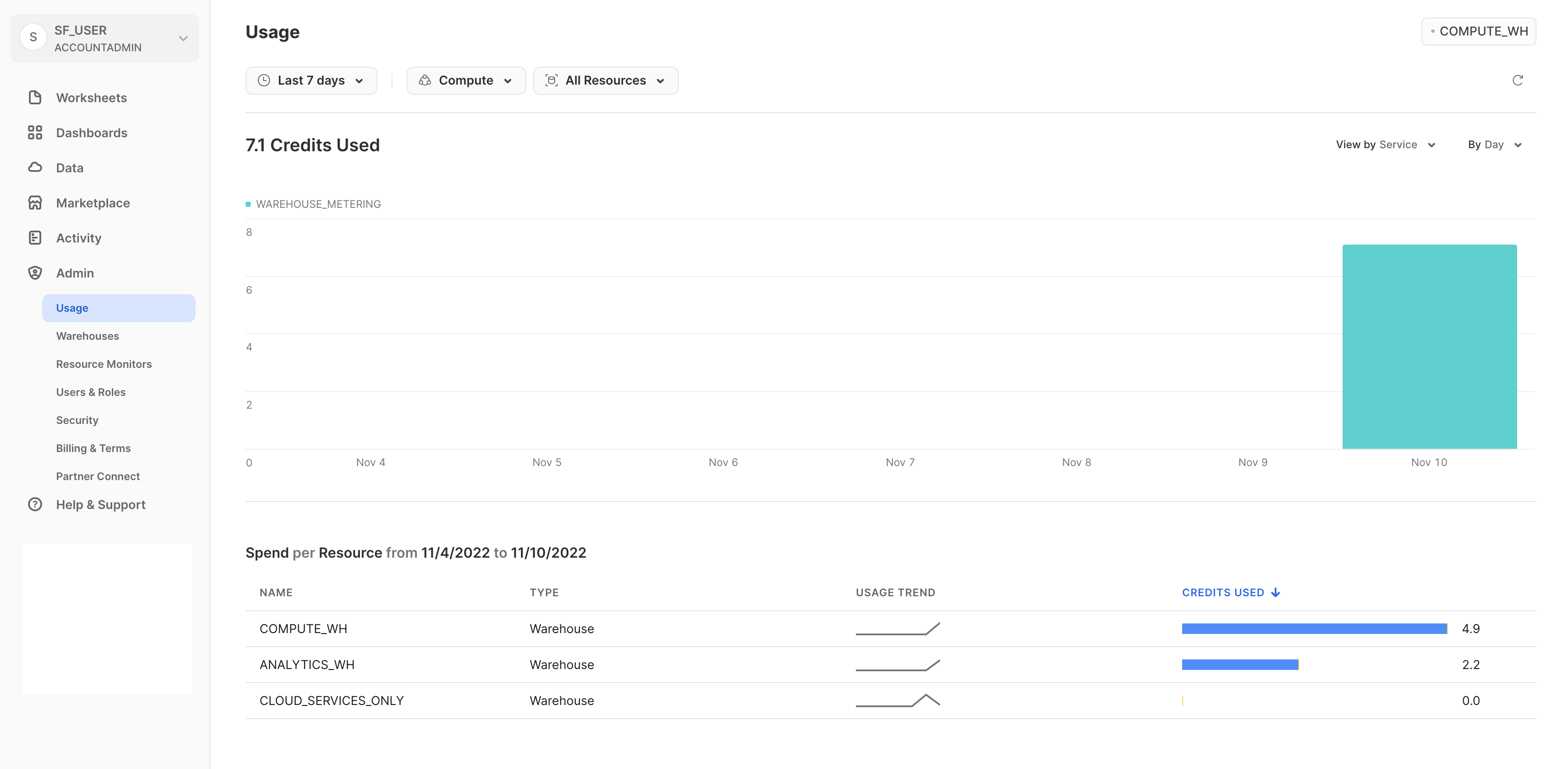
「使用状況」タブには以下の項目が表示され、それぞれに独自のページが用意されています。
- 組織:組織内の全アカウントのクレジット使用状況です。
- 消費:現在のアカウントの仮想ウェアハウスによって消費されたクレジットです。
- ストレージ:現在のアカウントのすべてのデータベース、内部ステージ、Snowflake Failsafeに格納されている過去1か月の平均データ量です。
- 転送:過去1か月に(現在のアカウントの)リージョンから他のリージョンに転送された平均データ量です。
各ページの右上にあるフィルターを使用すると、使用状況/消費量/その他の視覚化をさまざまな尺度で細分化することができます。
セキュリティ
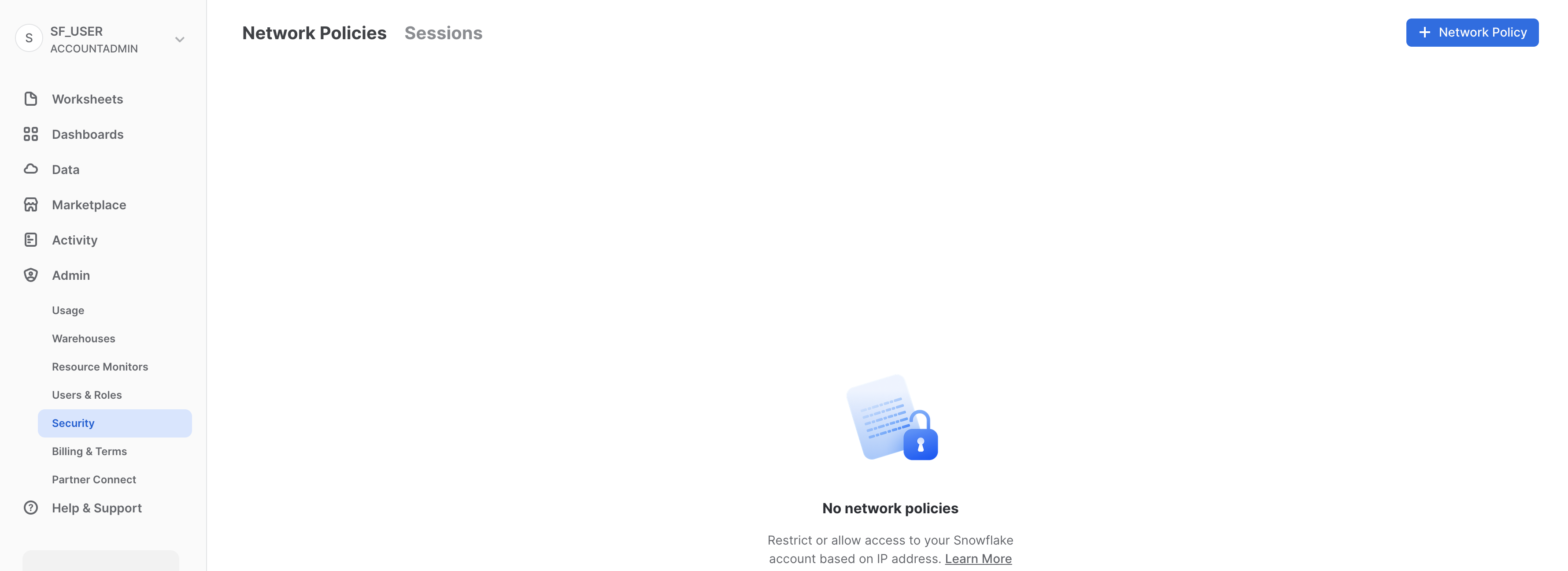
「セキュリティ」タブには、Snowflakeアカウント用に作成されたネットワークポリシーが含まれています。新しいネットワークポリシーは、ページの右上にある「+ネットワークポリシー」を選択して作成できます。
請求
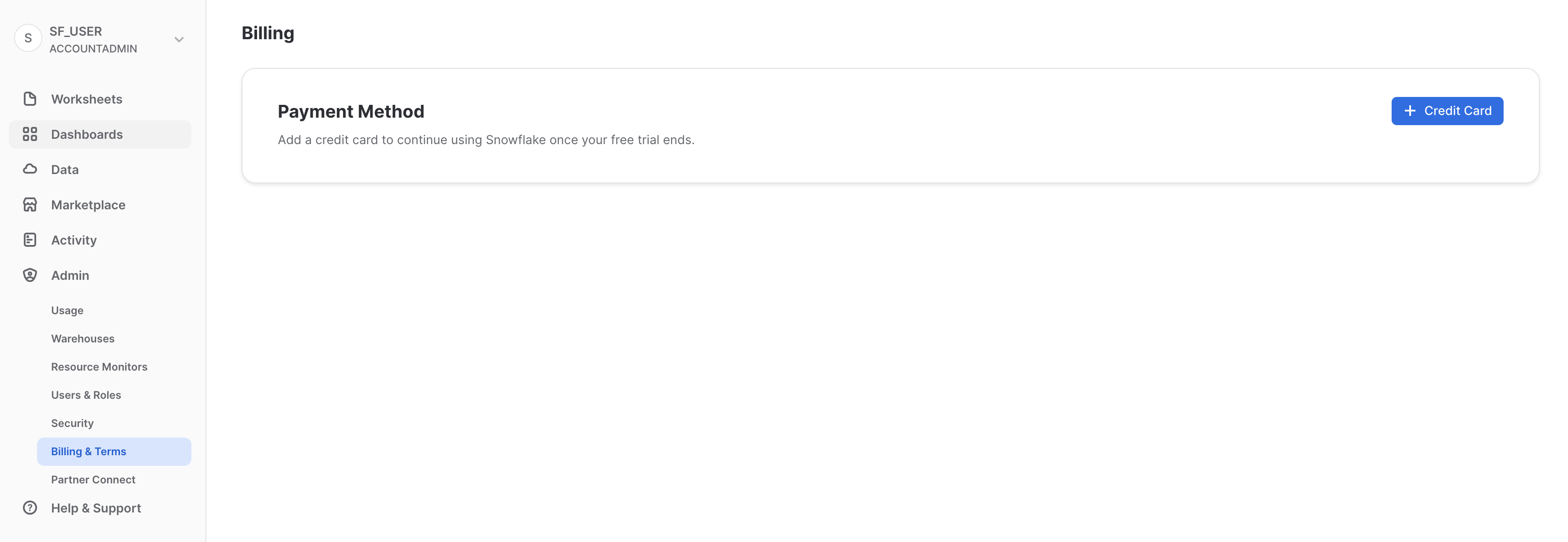
「請求」タブには、アカウントの支払い方法が含まれています。
- Snowflakeのご契約ユーザーの場合は、このタブに契約情報に関連付けられたお名前が表示されます。
- オンデマンドのSnowflakeユーザーで、月々のお支払いに使用するクレジットカード情報が登録されている場合は、このタブにそのクレジットカード情報が表示されます。クレジットカードが登録されていない場合、トライアル終了時にクレジットカード情報を追加することで、引き続きSnowflakeをご利用いただくことができます。
次のセクションのために、UIセッションはACCOUNTADMINロールのままにしておきます。
Snowflakeは、安全なデータシェアリング機能を通じて、アカウント間でのデータアクセスを実現します。共有は、データプロバイダーによって作成され、データコンシューマーにより、自身のSnowflakeアカウントまたはプロビジョニングされたSnowflakeリーダーアカウントを通じてインポートされます。コンシューマーは、外部エンティティの場合もあれば、独自のSnowflakeアカウントを持つ必要がある社内の部門である場合もあります。
安全なデータシェアリングについて:
- データプロバイダーのアカウントに存在するデータのコピーは1つのみ。
- 共有データは常にライブのリアルタイムであり、コンシューマーが即時に利用可能。
- プロバイダーは、共有に対する取り消し可能なきめ細かいアクセスを設定可能。
- データシェアリングは特に旧式のデータシェアリング方法と比較した場合にシンプルで安全。旧式の方法は一般に、インターネットを介した大容量の
.csvファイルの転送など、手動で安全でない。
Snowflakeは、安全なデータシェアリングを使用して、アカウント使用状況データおよびサンプルデータセットをすべてのSnowflakeアカウントに提供します。この機能において、Snowflakeはデータプロバイダーとして機能し、他のすべてのアカウントはコンシューマーとして機能します。
安全なデータシェアリングはSnowflakeマーケットプレイスの原動力でもあります。Snowflakeマーケットプレイスは、すべてのSnowflakeユーザーが利用できるものであり、多数のデータプロバイダーやSaaSベンダーからサードパーティのデータセットを見つけ、それらにアクセスすることができます。このデータシェアリングモデルでも、データはプロバイダーのアカウントから移動することはなく、データセットを変換なしで利用することができます。
既存の共有を表示
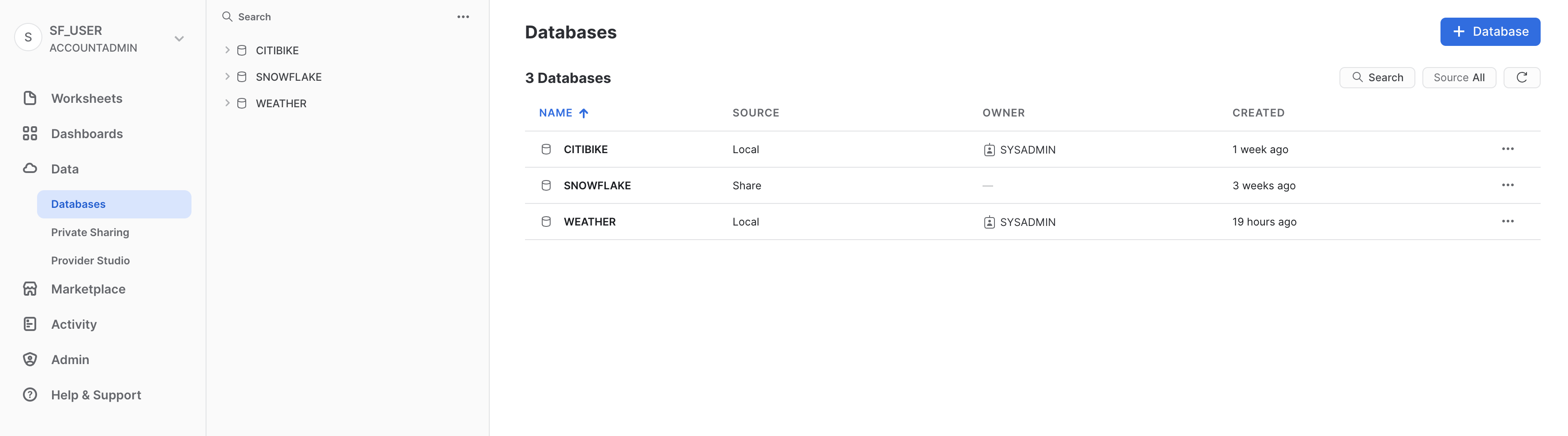
ホームページで、「データ」、「**データベース」**の順に進みます。データベースのリストで、SOURCE列を調べます。この列にLocalと表示されている2つのデータベースがあります。これらは、ラボで先に作成していた2つのデータベースです。もう1つのデータベース、SNOWFLAKEには列にShareの表示がありますが、これは、プロバイダーから共有されていることを示しています。
アウトバウンド共有の作成
Citi Bikeのストーリーに戻りましょう。ここでは、私たちがCiti BikeのSnowflakeアカウント管理者であると想定します。私たちには、ほぼリアルタイムでTRIPSデータベースのデータを分析することを希望している信頼できるパートナーがいます。このパートナーは、私たちのアカウントと同じリージョンに自社のSnowflakeアカウントを持っています。では、安全なデータシェアリングを使って、このパートナーがこの情報にアクセスできるようにしていきましょう。
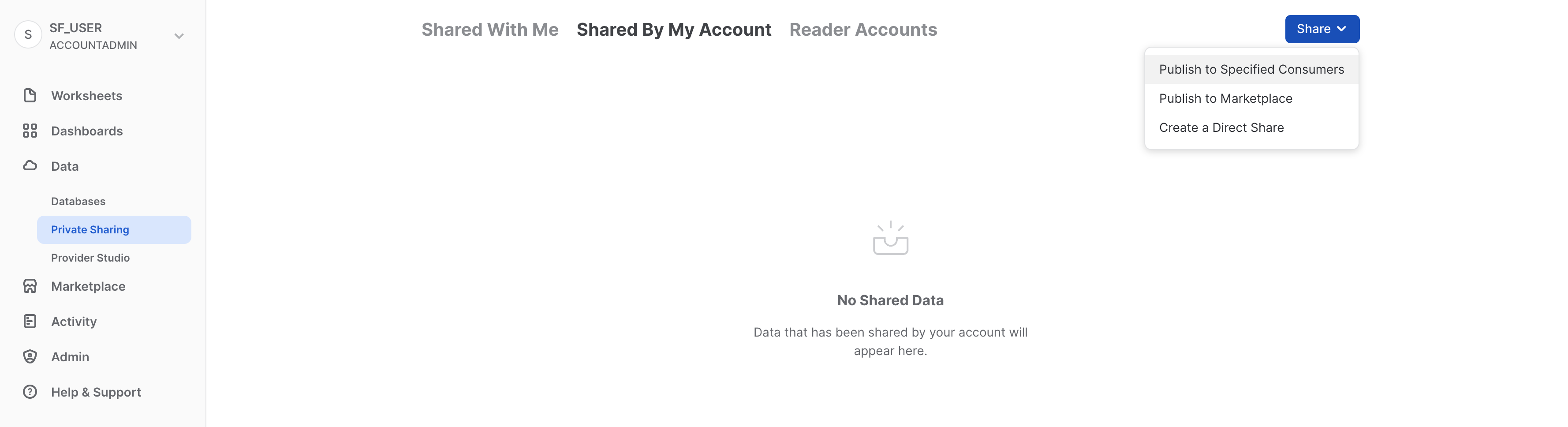
「データ」、「プライベートシェアリング」の順に進み、タブの上部の「マイアカウントで共有」をクリックします。右上の「共有」ボタンをクリックし、「直接共有の作成」を選択します。
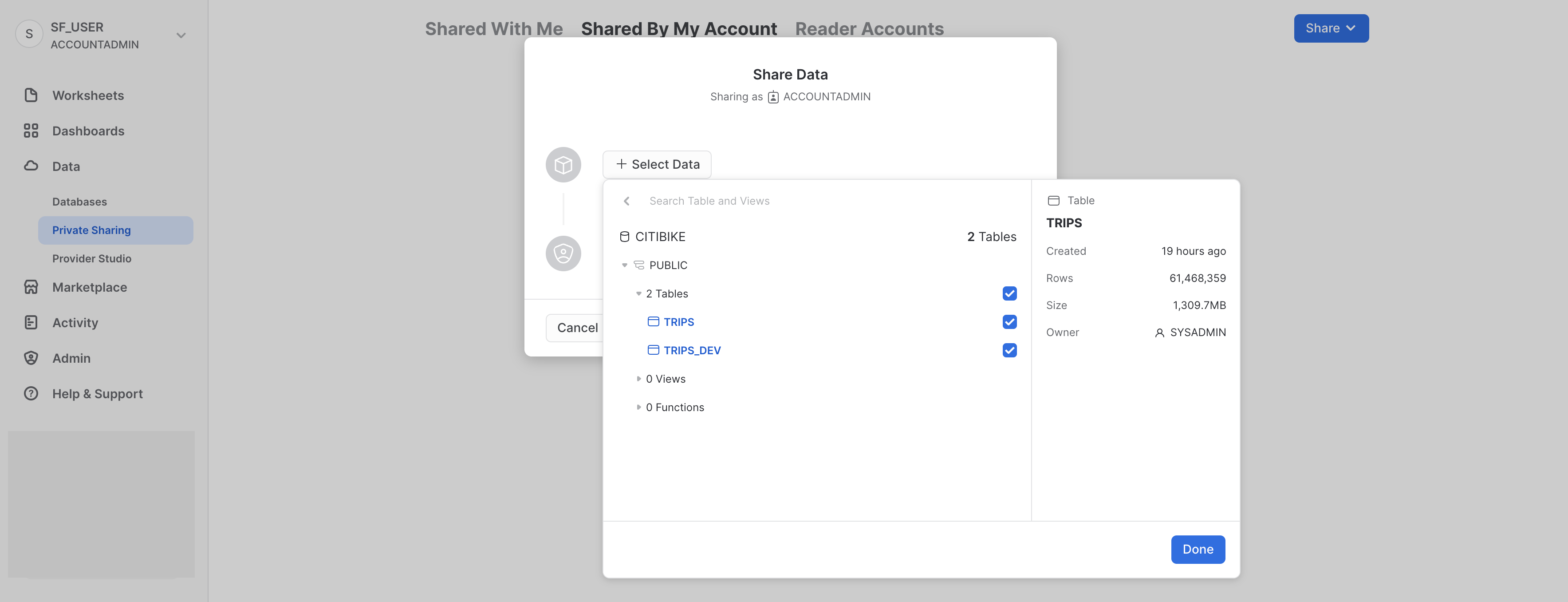
「+データの選択」をクリックし、CITIBIKEデータベースとPUBLICスキーマに移動します。スキーマで作成済みの2つのテーブルを選択し、「完了」ボタンをクリックします。
共有のデフォルト名は、ランダムな数値を付加した一般的な名前となっています。デフォルト名を編集し、将来的に共有を識別するのに役立つわかりやすい名前に変更します(ZERO_TO_SNOWFLAKE_SHARED_DATAなど)。コメントを追加することもできます。
実際のシナリオでは、次に、Citi Bikeのアカウント管理者が1つ以上のコンシューマーアカウントを共有に追加することになると思いますが、今回のラボではそこまでは実行しません。
ダイアログの下部にある「共有の作成」ボタンをクリックします。
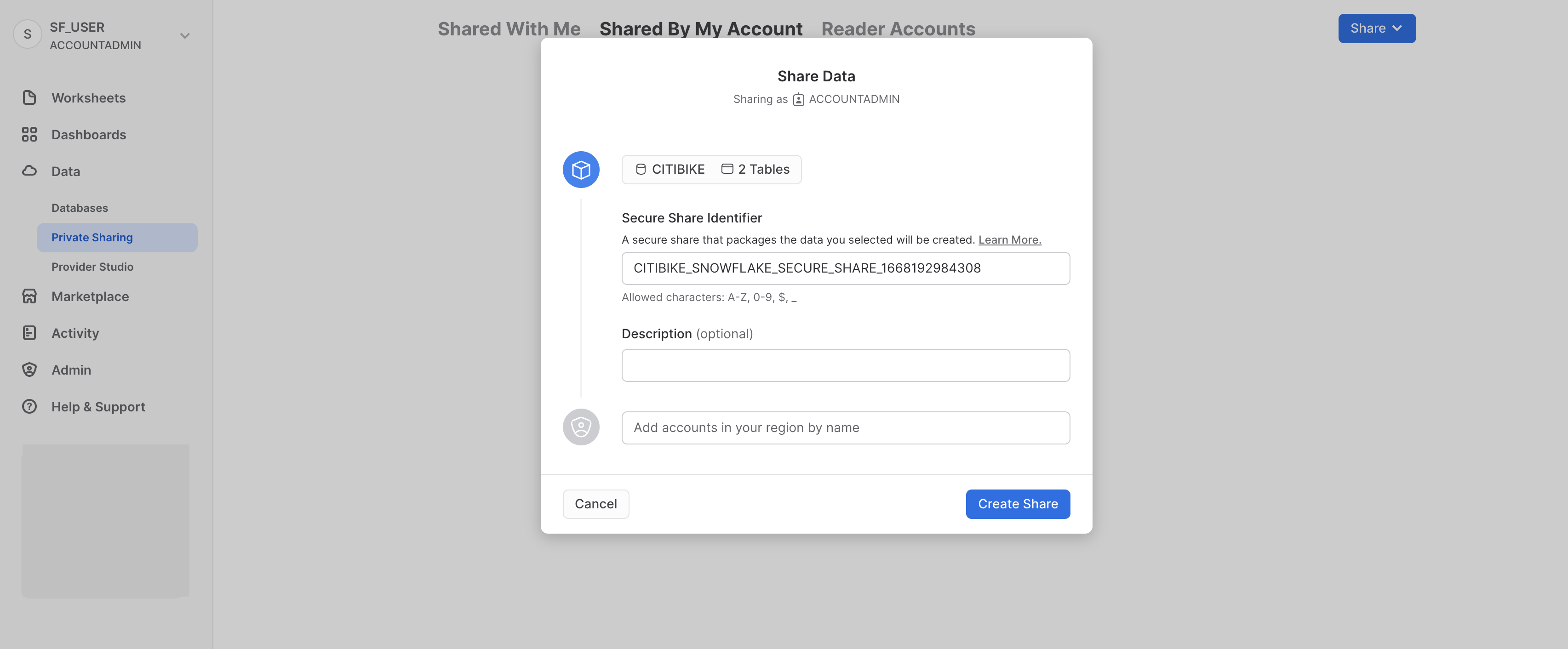
ダイアログが閉じ、作成した安全な共有がページに表示されます。
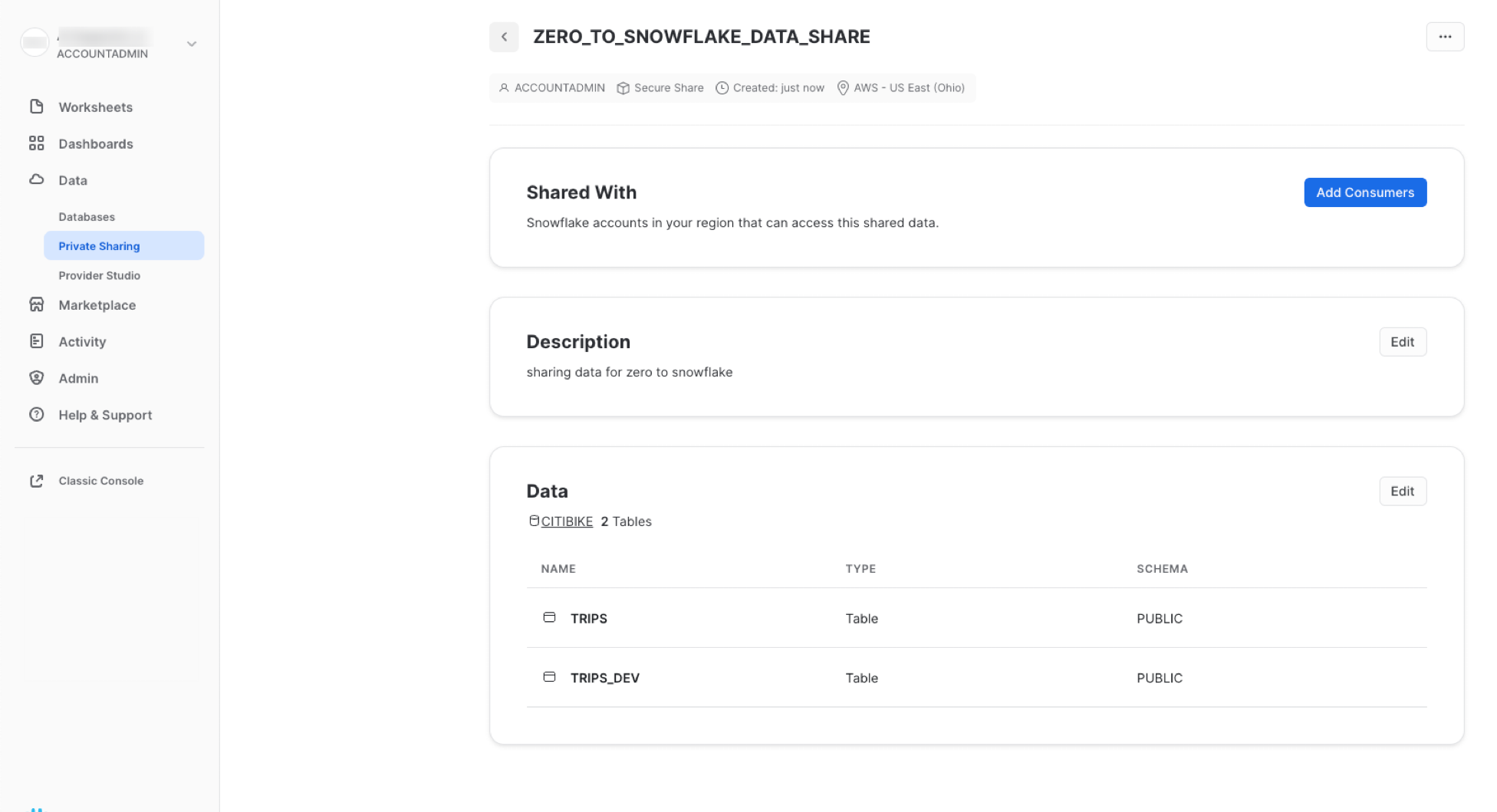
コンシューマーの追加、説明の追加/変更、共有内のオブジェクトの編集はいつでも実行できます。このページで共有名の隣にある**<**ボタンをクリックすると、「**他のアカウントと共有**」ページに戻ります。
ここでは、自分のSnowflakeアカウントのデータへのアクセスを、データのコピーや転送を必要としない安全な方法で他のアカウントにほんの数秒で付与できることを示しました。
Snowflakeは、機密性を損なうことなくデータを安全に共有する方法をいくつか提供しています。テーブルに加えて、安全なビュー、安全なUDF(ユーザー定義関数)、その他の安全なオブジェクトを共有できます。これらの方法を使用して機密情報へのアクセスを防ぎながらデータを共有することについての詳細は、Snowflakeドキュメントを参照してください。
Snowflakeマーケットプレイス
自分がACCOUNTADMINロールを使用していることを確認したうえで、マーケットプレイスに移動します。
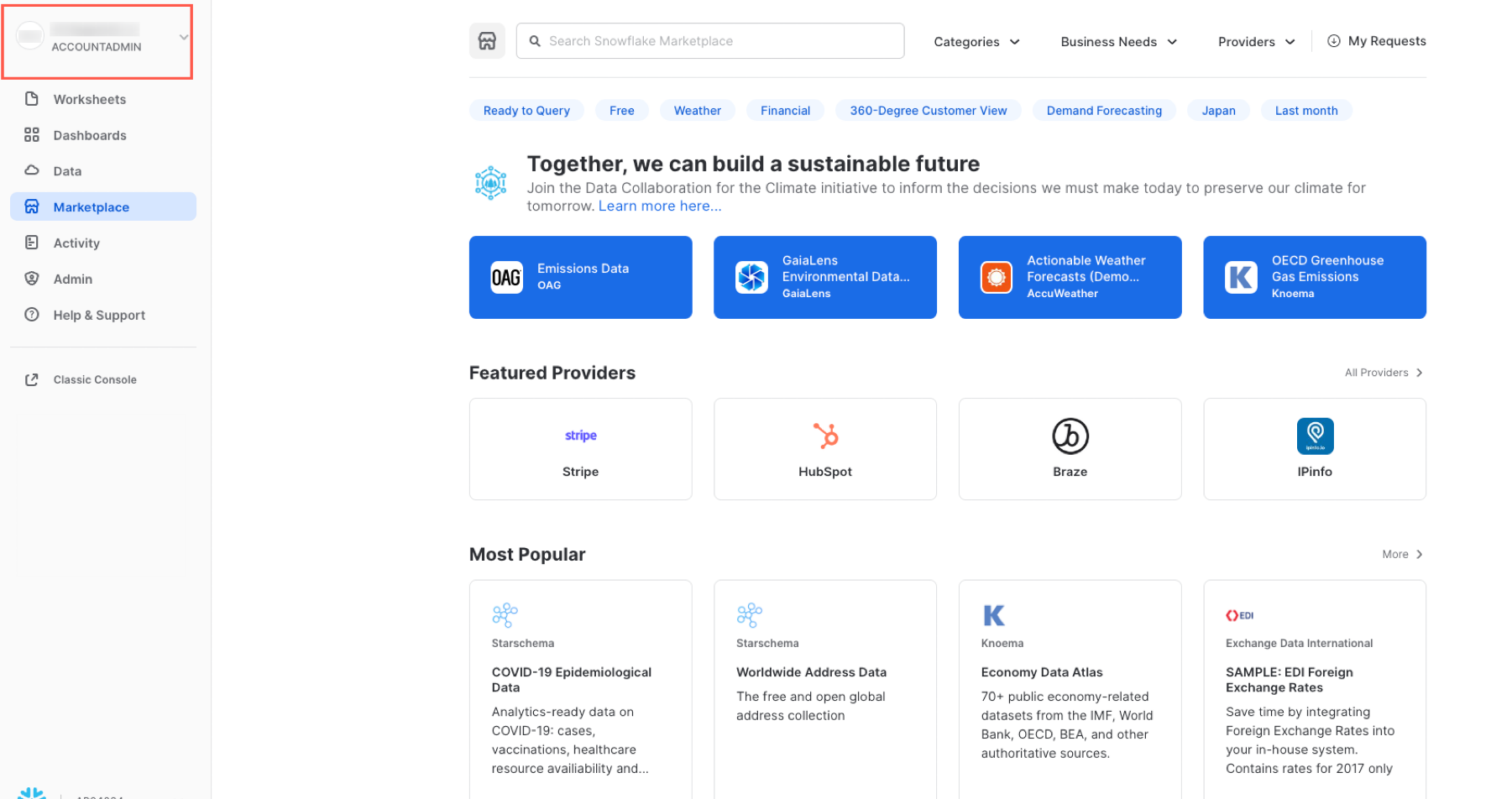
リスティングの検索
上部の検索ボックスでリスティングを検索できます。検索ボックスの右にあるドロップダウンリストを使用すると、プロバイダー、ビジネスニーズ、カテゴリーでデータリスティングをフィルタリングできます。
検索ボックスに「COVID」と入力し、結果をスクロールしてCOVID-19疫学データ(提供:Starschema)を選択します。
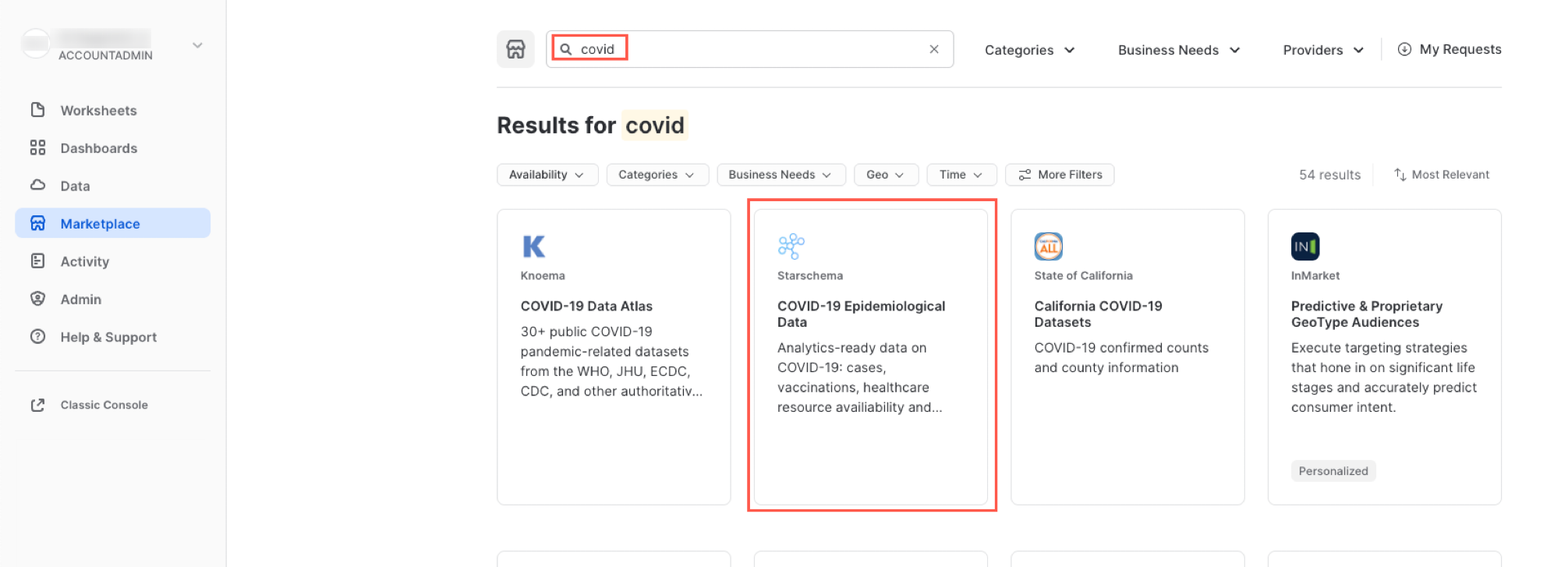
COVID-19疫学データのページでは、データセットの詳細や、クエリの使用例を見ることができます。準備ができたら、「取得」ボタンをクリックします。そうすることで、この情報を自分のSnowflakeアカウント内で利用できるようになります。
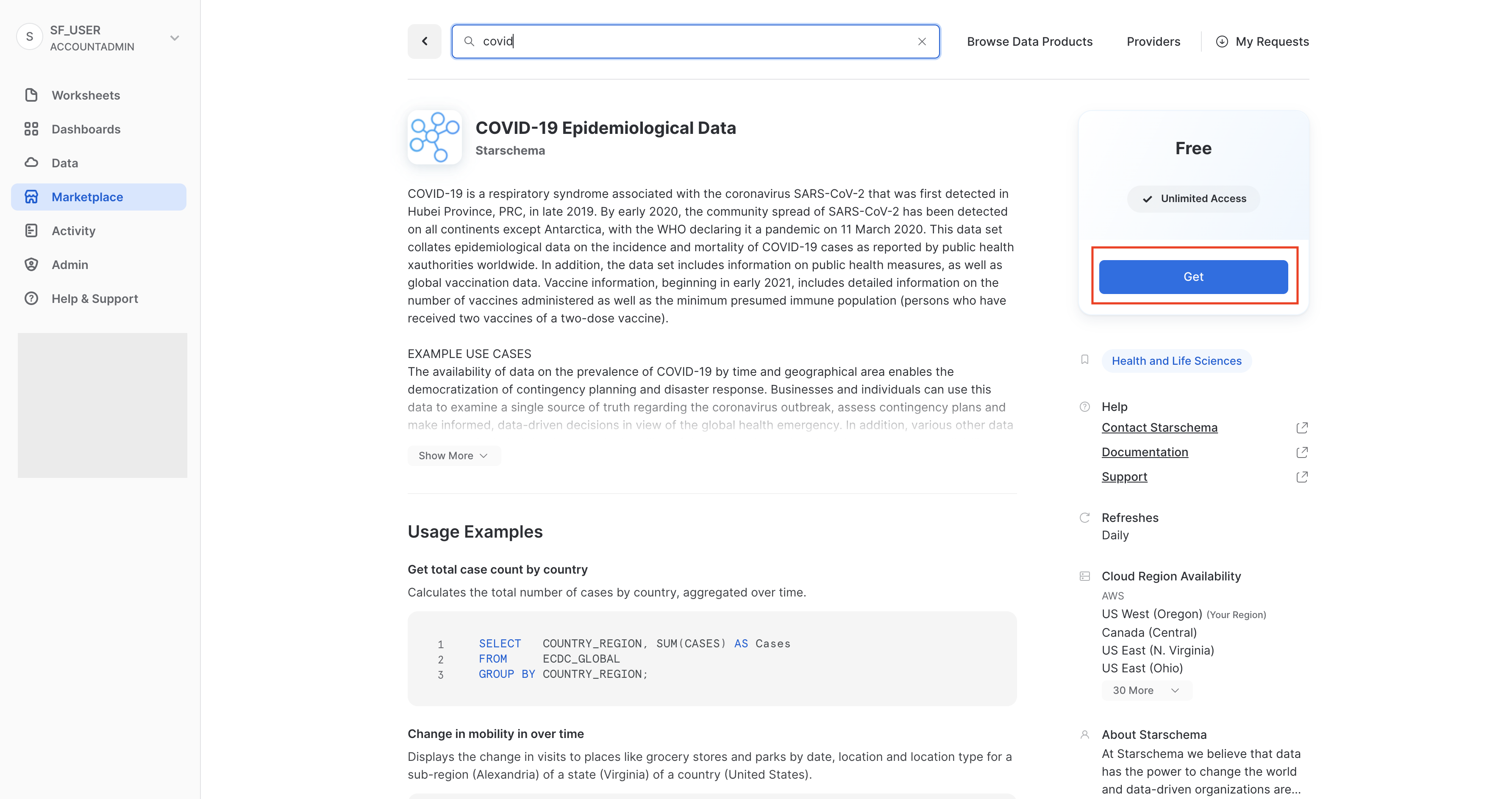
ダイアログで情報を確認し、再度「取得」をクリックします。
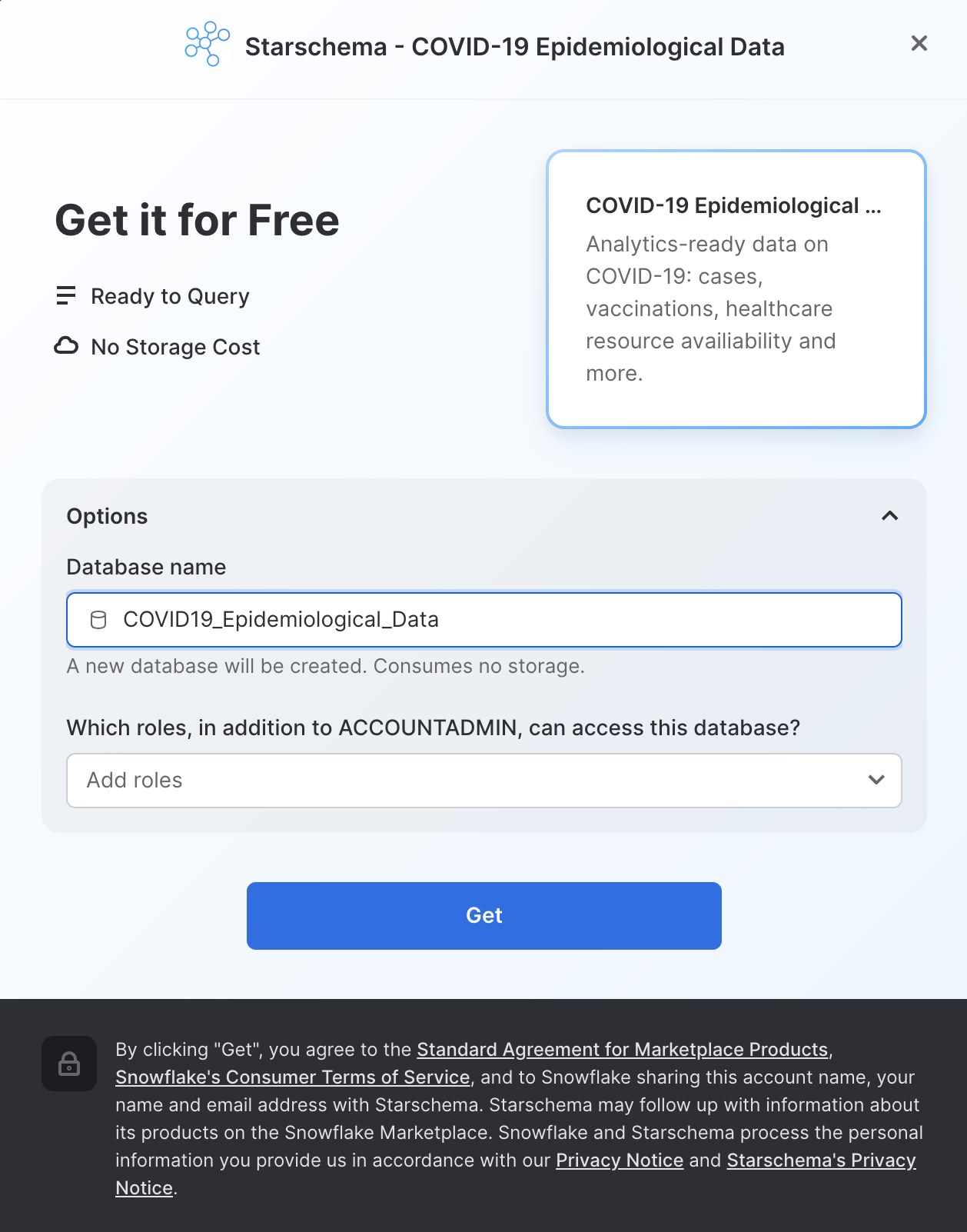
ここで「完了」をクリックしても構いません。あるいは、Starschemaが提供するサンプルクエリを実行することもできます。
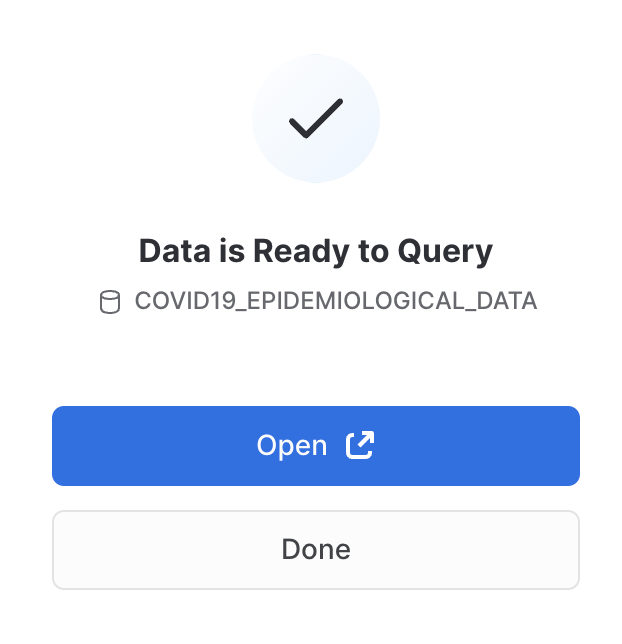
「開く」を選択すると、新しいブラウザタブ/ウィンドウで新規ワークシートが開きます。
- コンテキストの設定
- 実行したいクエリを選択します(または、クエリテキストにカーソルを合わせます)。
- 「実行/再生」ボタンをクリックします(または、キーボードのショートカットを使用します)。
- 最下部のペインでデータ結果を確認できます。
- サンプルクエリの実行が完了したら、左上のホームアイコンをクリックします。
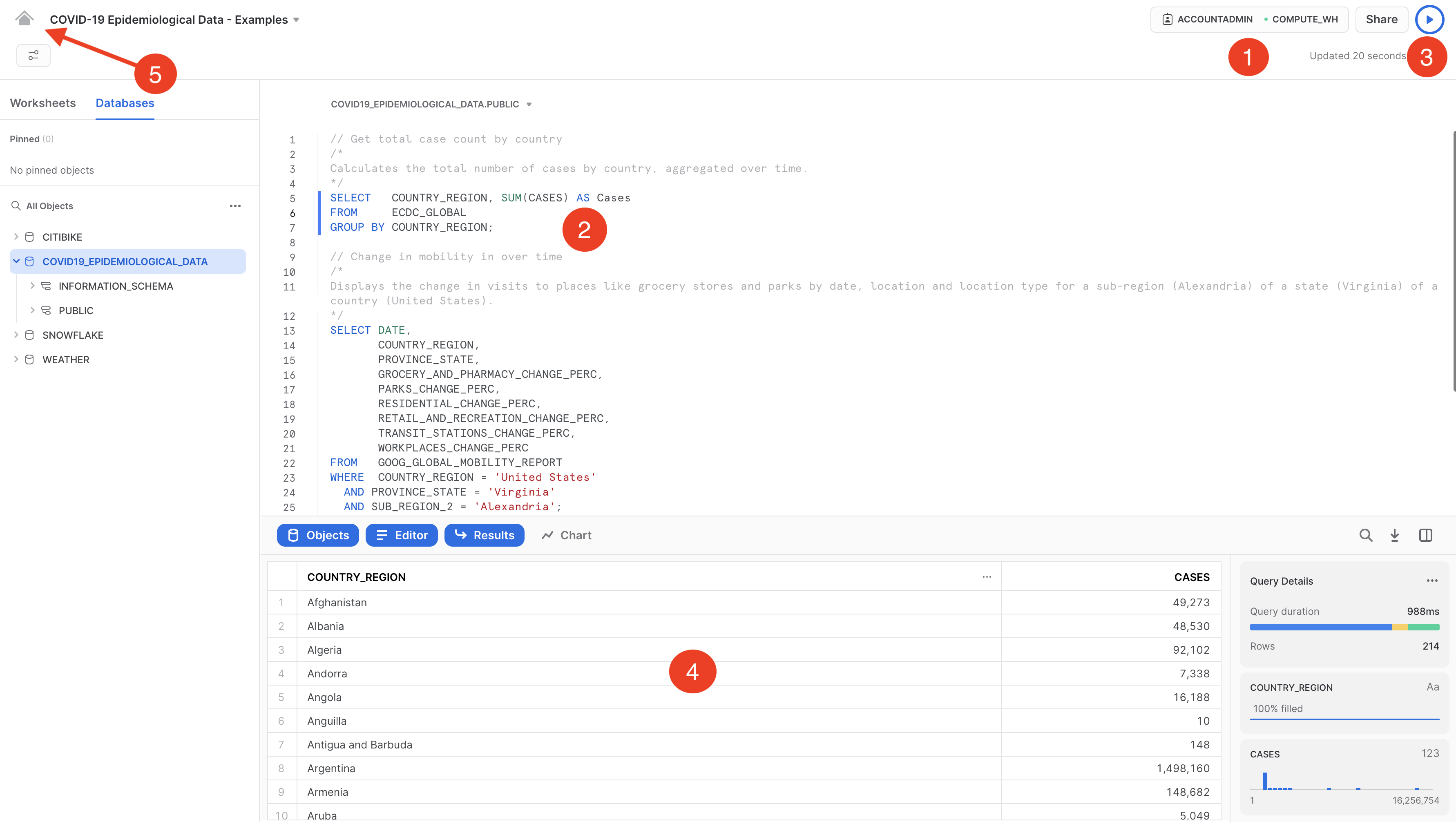
次:
- 「データ」、「**データベース」**の順にクリックします。
COVID19_BY_STARSCHEMA_DMデータベースをクリックします。- クエリできるスキーマ、テーブル、ビューの詳細を確認できます。
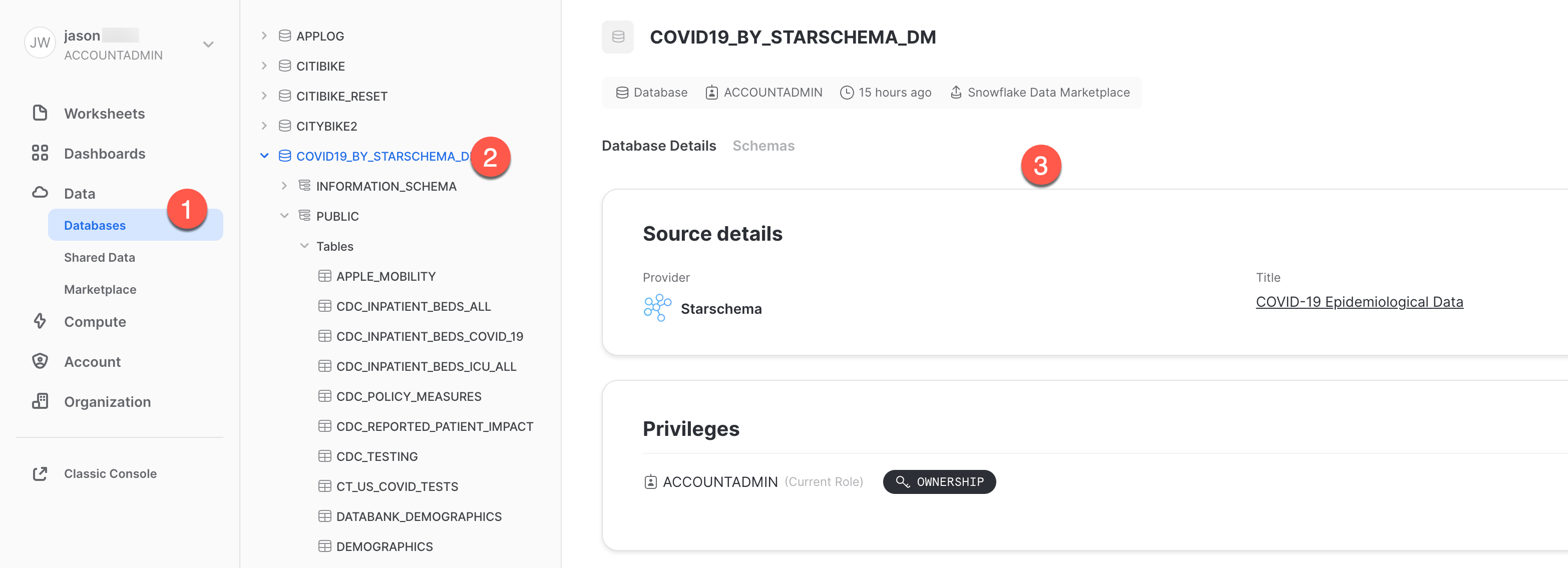
これで完了です。これで、Starschema提供のCOVID-19データセットのサブスクライブが問題なく完了しました。このデータセットは、世界的なCOVIDのデータにより毎日更新されます。データベース、テーブル、ビュー、ETLプロセスを作成する必要がなかったことに注意してください。Snowflakeマーケットプレイスの共有データを検索し、アクセスするだけでした。
新しいワークシートインターフェイスの使い方について詳しくは、Snowsightドキュメントを参照してください
このラボの一環として作成したオブジェクトをすべて削除して環境をリセットしたい場合は、ワークシートでSQLステートメントを実行します。
まず、ワークシートで自分がACCOUNTADMINロールを使用していることを確認してください。
use role accountadmin;
次に、以下のSQLコマンドを実行して、ラボで作成したすべてのオブジェクトをドロップします。
drop share if exists zero_to_snowflake_shared_data;
-- If necessary, replace "zero_to_snowflake-shared_data" with the name you used for the share
drop database if exists citibike;
drop database if exists weather;
drop warehouse if exists analytics_wh;
drop role if exists junior_dba;
おめでとうございます。導入ラボ実習が終了しました。これで、Snowflakeの基礎はマスターできましたので、学んだ基礎を自分のデータに適用することができます。おさらいが必要な場合は、このガイドを参照するようにしてください。
無料トライアルを続行し、自分のサンプルデータまたは本番データをロードして、このラボで扱っていないSnowflakeのより高度な機能を試してみることをお勧めします。
関連リソース:
- Snowsightドキュメントの詳細を確認する。
- 無料トライアルを最大限に活用するための決定版ガイドを読む。
- Snowflakeのバーチャルイベントまたは対面イベントに参加し、当社の機能や顧客についてさらに詳しい情報を得る。
- Snowflake Communityに参加する。
- Snowflake Universityに登録する。
- 詳細を当社セールスチームに問い合わせる。
ここまで学んだ内容:
- ステージ、データベース、テーブル、ビュー、仮想ウェアハウスの作成方法。
- 構造化データおよび半構造化データのロード方法。
- テーブル間の結合を含む、Snowflake内のデータに対する分析クエリの実行方法。
- オブジェクトのクローン方法。
- タイムトラベルを使用してユーザーエラーを元に戻す方法。
- ロールおよびユーザーを作成し、権限を付与する方法。
- 他のアカウントと安全かつ簡単にデータを共有する方法。
- Snowflakeマーケットプレイスでデータセットを利用する方法。