このガイドを完了すると、未加工データから、組織が広告予算の割り当てを最適化するのに役立つ双方向アプリケーションに移行できるようになります。
このクイックスタートに従って、各ステップで次のような概要を学ぶことができます。
- 環境の設定:ステージとテーブルを使用して、S3からSnowflakeに未加工データを取り込み、整理します。
- データエンジニアリング:Snowpark for Python DataFramesを活用して、グループ化、集約、ピボット、結合などのデータ変換を実行し、下流のアプリケーション用のデータを準備します。
- データパイプライン:Snowflakeタスクを使用して、データパイプラインコードを、統合された監視を備えた運用パイプラインに変換します。
- 機械学習:データを準備し、SnowflakeでSnowpark MLを使用してMLトレーニングを実行し、Snowparkユーザー定義関数(UDF)としてモデルを展開します。
- Streamlitアプリケーション:Pythonを使用してインタラクティブなアプリケーションを構築し(ウェブ開発の経験は不要)、さまざまな広告費予算のROIの可視化を支援します。
上記のテクノロジーについて初めて知る方のために、ドキュメントへのリンクを含む簡単な要約を以下に示します。
Snowparkとは
Python、Java、Scalaなどの非SQLコードを安全にデプロイして処理するSnowflakeのライブラリとランタイムのセットです。
使い慣れたクライアント側ライブラリ - Snowparkは、高度に統合されたDataFrame型のプログラミングとOSS互換のAPIをデータ実務者の好みの言語で利用できるようにします。より効率的なMLモデリング(公開プレビュー)とML運用(プライベートプレビュー)のためのSnowpark ML APIも含まれています。
柔軟なランタイムコンストラクト - Snowparkは、ユーザーがカスタムロジックを取り込んで実行できるようにする柔軟なランタイムコンストラクトを提供します。開発者は、ユーザー定義関数とストアドプロシージャを使用して、データパイプライン、MLモデル、データアプリケーションをシームレスに構築できます。
詳しくは、Snowparkをご覧ください。
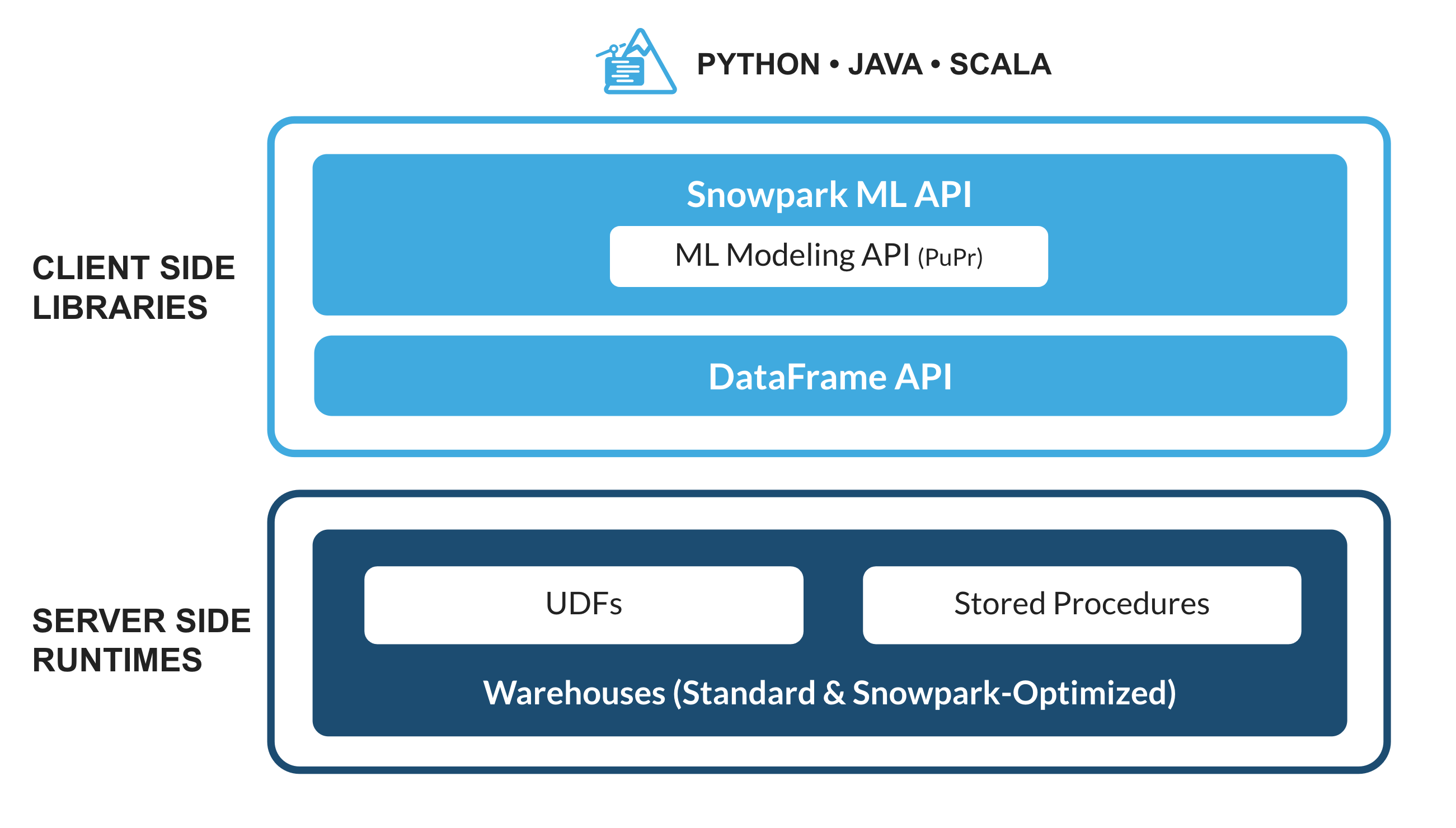
Snowpark MLとは
Snowpark MLは、Snowflakeでより高速かつ直感的なエンドツーエンドのML開発を行うための新しいライブラリです。Snowpark MLには、モデル開発用のSnowpark MLモデリング(公開プレビュー)とモデル展開用のSnowpark ML運用(プライベートプレビュー)の2つのAPIがあります。
このクイックスタートでは、特徴量エンジニアリングをスケールアウトし、SnowflakeでのMLトレーニングの実行を簡素化するSnowpark MLモデリングAPIに焦点を当てます。
Streamlitとは
Streamlitは、開発者がデータアプリケーションをすばやく簡単に作成、共有、デプロイできるようにする、純粋なPythonのオープンソースアプリケーションフレームワークです。詳しくは、Streamlitをご覧ください。
学習する内容
- Snowpark DataFramesとAPIを利用してデータを分析し、データエンジニアリングタスクを実行する方法
- 厳選されたSnowflake AnacondaチャネルからオープンソースのPythonライブラリを使用する方法
- SnowflakeでSnowpark MLを使用してMLモデルをトレーニングする方法
- オンライン推論とオフライン推論のそれぞれに、スカラーおよびベクトル化されたSnowpark Pythonユーザー定義関数(UDF)を作成する方法
- Snowflakeタスクを作成してデータパイプラインを自動化する方法
- ユーザー入力に基づく推論にスカラーUDFを使用するStreamlitウェブアプリケーションを作成する方法
前提条件
- Gitがインストールされていること
- Python 3.9がインストールされていること
- 開始ステップでは、Python環境をPython 3.9で作成することに注意してください。
- ORGADMINによって有効化されたAnacondaパッケージを持つSnowflakeアカウント。Snowflakeアカウントをお持ちでない場合は、無料トライアルアカウントに登録できます。
- アカウント管理者の役割を持つSnowflakeアカウントのログイン。環境にこの役割がある場合は、それを使用できます。それ以外の場合は、1)無料トライアルに登録する、2)データベース、スキーマ、テーブル、ステージ、タスク、ユーザー定義関数、ストアドプロシージャを作成できる別の役割を使用する、または3)上記のオブジェクトを作成できる既存のデータベースとスキーマを使用する必要があります。
重要:続行する前に、こちらで説明されているように、ORGADMINによってAnacondaパッケージが有効化されているSnowflakeアカウントがあることを確認してください。
テーブルを作成し、データを読み込み、ステージを設定する
認証情報を使用してSnowsightにログインしてテーブルを作成し、Amazon S3からデータを読み込み、Snowflake内部ステージを設定します。
重要:
- このセクションで作成したオブジェクトに別の名前を使用する場合は、それに応じて次のセクションのスクリプトとコードを更新してください。
- 以下の各SQLスクリプトブロックについて、ブロック内のすべてのステートメントを選択し、上から順に実行します。
次のSQLコマンドを実行して、ウェアハウス、データベース、スキーマを作成します。
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE WAREHOUSE DASH_L;
CREATE OR REPLACE DATABASE DASH_DB;
CREATE OR REPLACE SCHEMA DASH_SCHEMA;
USE DASH_DB.DASH_SCHEMA;
次のSQLコマンドを実行し、公的にアクセス可能なS3バケットにホストされているデータからテーブルCAMPAIGN_SPENDを作成します。
CREATE or REPLACE file format csvformat
skip_header = 1
type = 'CSV';
CREATE or REPLACE stage campaign_data_stage
file_format = csvformat
url = 's3://sfquickstarts/ad-spend-roi-snowpark-python-scikit-learn-streamlit/campaign_spend/';
CREATE or REPLACE TABLE CAMPAIGN_SPEND (
CAMPAIGN VARCHAR(60),
CHANNEL VARCHAR(60),
DATE DATE,
TOTAL_CLICKS NUMBER(38,0),
TOTAL_COST NUMBER(38,0),
ADS_SERVED NUMBER(38,0)
);
COPY into CAMPAIGN_SPEND
from @campaign_data_stage;
次のSQLコマンドを実行し、公的にアクセス可能なS3バケットにホストされているデータからテーブルMONTHLY_REVENUEを作成します。
CREATE or REPLACE stage monthly_revenue_data_stage
file_format = csvformat
url = 's3://sfquickstarts/ad-spend-roi-snowpark-python-scikit-learn-streamlit/monthly_revenue/';
CREATE or REPLACE TABLE MONTHLY_REVENUE (
YEAR NUMBER(38,0),
MONTH NUMBER(38,0),
REVENUE FLOAT
);
COPY into MONTHLY_REVENUE
from @monthly_revenue_data_stage;
次のSQLコマンドを実行して、過去6か月間の予算割り当てとROIを保持するテーブルBUDGET_ALLOCATIONS_AND_ROIを作成します。
CREATE or REPLACE TABLE BUDGET_ALLOCATIONS_AND_ROI (
MONTH varchar(30),
SEARCHENGINE integer,
SOCIALMEDIA integer,
VIDEO integer,
EMAIL integer,
ROI float
)
COMMENT = '{"origin":"sf_sit-is", "name":"aiml_notebooks_ad_spend_roi", "version":{"major":1, "minor":0}, "attributes":{"is_quickstart":1, "source":"streamlit"}}';
INSERT INTO BUDGET_ALLOCATIONS_AND_ROI (MONTH, SEARCHENGINE, SOCIALMEDIA, VIDEO, EMAIL, ROI)
VALUES
('January',35,50,35,85,8.22),
('February',75,50,35,85,13.90),
('March',15,50,35,15,7.34),
('April',25,80,40,90,13.23),
('May',95,95,10,95,6.246),
('June',35,50,35,85,8.22);
次のコマンドを実行して、ストアドプロシージャ、UDF、MLモデルファイルを格納するためのSnowflake内部ステージを作成します。
CREATE OR REPLACE STAGE dash_sprocs;
CREATE OR REPLACE STAGE dash_models;
CREATE OR REPLACE STAGE dash_udfs;
任意で、Snowsightでsetup.sqlを開き、すべてのSQLステートメントを実行してオブジェクトを作成し、AWS S3からデータを読み込むこともできます。
重要:このセクションで作成したオブジェクトに別の名前を使用する場合は、それに応じて次のセクションのスクリプトとコードを更新してください。
このセクションでは、GitHubレポジトリの複製と、Snowpark for Python環境の設定について説明します。
GitHubレポジトリを複製する
最初のステップは、GitHubレポジトリを複製することです。このレポジトリには、このクイックスタートガイドを正常に完了するために必要なすべてのコードが含まれています。
HTTPSを使用する場合:
git clone https://github.com/Snowflake-Labs/sfguide-getting-started-dataengineering-ml-snowpark-python.git
または、SSHを使用する場合:
git clone git@github.com:Snowflake-Labs/sfguide-getting-started-dataengineering-ml-snowpark-python.git
Snowpark for Python
データエンジニアリングと機械学習のステップを完了するには、以下の説明に従って、すべてをローカルにインストールする(オプション1)か、Hexを使用する(オプション2)を選択します。
重要:Streamlitアプリケーションを実行するには、Python環境を作成し、「ローカルインストール」の説明に従って、Snowpark for Pythonとその他のライブラリをローカルにインストールする必要があります。
オプション1 – ローカルインストール
このオプションを使用すると、このクイックスタートガイドのすべてのステップを完了できます。
ステップ1:https://conda.io/miniconda.htmlからminicondaインストーラーをダウンロードしてインストールします*(または、Python 3.9では、virtualenvなどの他のPython環境を使用することもできます)*。
**ステップ2:**新しいターミナルウィンドウを開き、同じターミナルウィンドウで次のコマンドを実行します。
**ステップ3:**同じターミナルウィンドウで次のコマンドを実行して、snowpark-de-mlというPython 3.9 conda環境を作成します。
conda create --name snowpark-de-ml -c https://repo.anaconda.com/pkgs/snowflake python=3.9
ステップ4:同じターミナルウィンドウで次のコマンドを実行して、conda環境snowpark-de-mlをアクティブ化します。
conda activate snowpark-de-ml
ステップ5:同じターミナルウィンドウで次のコマンドを実行して、Snowflake AnacondaチャンネルからSnowpark Pythonとその他のライブラリをconda環境snowpark-de-mlにインストールします。
conda install -c https://repo.anaconda.com/pkgs/snowflake snowflake-snowpark-python pandas notebook scikit-learn cachetools
ステップ6:同じターミナルウィンドウで次のコマンドを実行して、Streamlitライブラリをconda環境snowpark-de-mlにインストールします。
pip install streamlit
ステップ7:同じターミナルウィンドウで次のコマンドを実行して、Snowpark MLライブラリをconda環境snowpark-de-mlにインストールします。
pip install snowflake-ml-python
**ステップ9:**Snowflakeアカウントの詳細と認証情報でconnection.jsonを更新します。
以下は、環境の設定ステップで説明したオブジェクト名に基づくconnection.jsonのサンプルです。
{
"account" : "<your_account_identifier_goes_here>",
"user" : "<your_username_goes_here>",
"password" : "<your_password_goes_here>",
"role" : "ACCOUNTADMIN",
"warehouse" : "DASH_L",
"database" : "DASH_DB",
"schema" : "DASH_SCHEMA"
}
注意:上記のaccountパラメータには、アカウント識別子を指定し、snowflakecomputing.comドメイン名は含めないでください。Snowflakeは、接続の作成時にこれを自動的に追加します。詳細については、ドキュメントを参照してください。
オプション2 – Hexの使用
既存のHexアカウントを使用する場合、または30日間の無料トライアルアカウントを作成する場合は、Snowpark for Pythonが組み込まれているため、Python環境を作成し、Snowpark for Pythonを他のライブラリとともにラップトップにローカルにインストールする必要はありません。これにより、このクイックスタートガイドのデータエンジニアリングと機械学習のステップをHexで直接完了できるようになります。(Hexでデータエンジニアリングと機械学習のノートブックをロードする詳細については、それぞれの手順を参照してください)。
重要:Streamlitアプリケーションを実行するには、Python環境を作成し、上記の「ローカルインストール」の説明に従って、Snowpark for Pythonとその他のライブラリをローカルにインストールする必要があります。
下記リンク先のノートブックでは、次のデータエンジニアリングタスクを説明しています。
- Snowpark PythonからSnowflakeへの安全な接続を確立する
- SnowflakeテーブルからSnowpark DataFramesにデータを読み込む
- Snowpark DataFramesで探索的データ分析を実行する
- Snowpark DataFramesを使用して、複数のテーブルからデータをピボットおよび結合する
- Snowflakeタスクを使用してデータパイプラインタスクを自動化する
JupyterまたはVisual Studio Codeのデータエンジニアリングノートブック
開始するには、次の手順に従います。
- ターミナルウィンドウで、このフォルダを参照し、コマンドラインで
jupyter notebookを実行します(他のツールやVisual Studio CodeなどのIDEを使用することもできます)。 - Snowpark_For_Python_DE.ipynbのセルを開いて実行します。
重要:Jupyterノートブックで、(Python)カーネルがsnowpark-de-mlに設定されていることを確認してください。これは、GitHubレポジトリの複製ステップで作成した環境の名前です。
Hexのデータエンジニアリングノートブック
既存のHexアカウントを使用する場合、または30日間の無料トライアルアカウントを作成する場合は、次の手順に従ってノートブックをロードし、HexからSnowflakeに接続するためのデータ接続を作成します。
- Snowpark_For_Python_DE.ipynbをプロジェクトとしてアカウントにインポートします。インポートの詳細については、ドキュメントを参照してください。
- 次に、Snowflakeへの接続にconnection.jsonを使用する代わりに、以下に示すようにデータ接続を作成し、それをデータエンジニアリングノートブックで使用します。
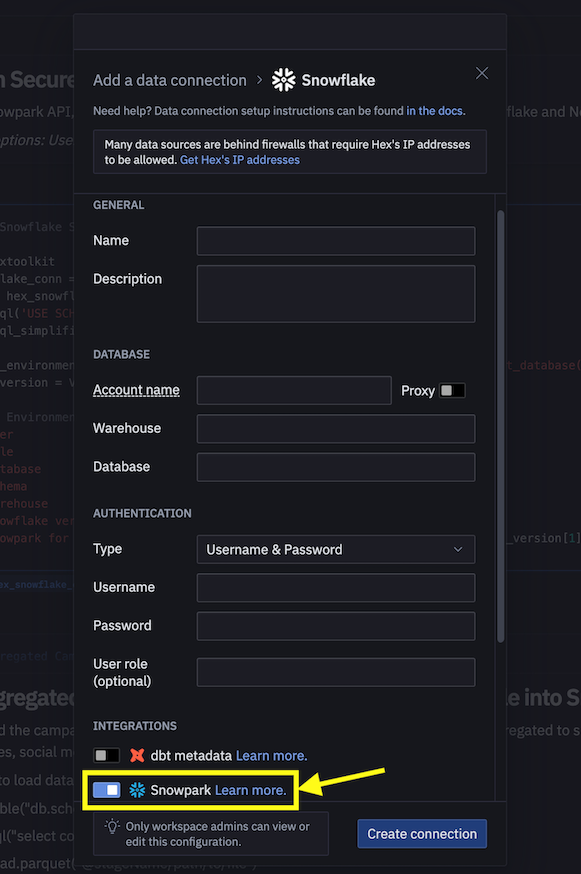
注意:ワークスペース内のプロジェクトやユーザーに対して、共有データ接続を作成することもできます。詳細については、ドキュメントを参照してください。
- ノートブックの次のコードスニペットを置き換えます。
connection_parameters = json.load(open('connection.json'))
session = Session.builder.configs(connection_parameters).create()
以下に置き換えます。
import hextoolkit
hex_snowflake_conn = hextoolkit.get_data_connection('YOUR_DATA_CONNECTION_NAME')
session = hex_snowflake_conn.get_snowpark_session()
session.sql('USE SCHEMA DASH_SCHEMA').collect()
データトランスフォーメーションは、Snowflakeで実行される自動データパイプラインの形式で運用することもできます。
特に、「データエンジニアリングノートブック」には、オプションでデータトランスフォーメーションをSnowflakeタスクとして構築して実行する方法を説明しているセクションがあります。
参考までに、コードスニペットを以下に示します。
ルート/親タスク
このタスクは、キャンペーン支出データのロードとさまざまな変換の実行を自動化します。
def campaign_spend_data_pipeline(session: Session) -> str:
# DATA TRANSFORMATIONS
# Perform the following actions to transform the data
# Load the campaign spend data
snow_df_spend_t = session.table('campaign_spend')
# Transform the data so we can see total cost per year/month per channel using group_by() and agg() Snowpark DataFrame functions
snow_df_spend_per_channel_t = snow_df_spend_t.group_by(year('DATE'), month('DATE'),'CHANNEL').agg(sum('TOTAL_COST').as_('TOTAL_COST')).\
with_column_renamed('"YEAR(DATE)"',"YEAR").with_column_renamed('"MONTH(DATE)"',"MONTH").sort('YEAR','MONTH')
# Transform the data so that each row will represent total cost across all channels per year/month using pivot() and sum() Snowpark DataFrame functions
snow_df_spend_per_month_t = snow_df_spend_per_channel_t.pivot('CHANNEL',['search_engine','social_media','video','email']).sum('TOTAL_COST').sort('YEAR','MONTH')
snow_df_spend_per_month_t = snow_df_spend_per_month_t.select(
col("YEAR"),
col("MONTH"),
col("'search_engine'").as_("SEARCH_ENGINE"),
col("'social_media'").as_("SOCIAL_MEDIA"),
col("'video'").as_("VIDEO"),
col("'email'").as_("EMAIL")
)
# Save transformed data
snow_df_spend_per_month_t.write.mode('overwrite').save_as_table('SPEND_PER_MONTH')
# Register data pipelining function as a Stored Procedure so it can be run as a task
session.sproc.register(
func=campaign_spend_data_pipeline,
name="campaign_spend_data_pipeline",
packages=['snowflake-snowpark-python'],
is_permanent=True,
stage_location="@dash_sprocs",
replace=True)
campaign_spend_data_pipeline_task = """
CREATE OR REPLACE TASK campaign_spend_data_pipeline_task
WAREHOUSE = 'DASH_L'
SCHEDULE = '3 MINUTE'
AS
CALL campaign_spend_data_pipeline()
"""
session.sql(campaign_spend_data_pipeline_task).collect()
子/依存タスク
このタスクは、月間売上データのロード、さまざまな変換の実行、変換されたキャンペーン支出データとの結合を自動化します。
def monthly_revenue_data_pipeline(session: Session) -> str:
# Load revenue table and transform the data into revenue per year/month using group_by and agg() functions
snow_df_spend_per_month_t = session.table('spend_per_month')
snow_df_revenue_t = session.table('monthly_revenue')
snow_df_revenue_per_month_t = snow_df_revenue_t.group_by('YEAR','MONTH').agg(sum('REVENUE')).sort('YEAR','MONTH').with_column_renamed('SUM(REVENUE)','REVENUE')
# Join revenue data with the transformed campaign spend data so that our input features (i.e. cost per channel) and target variable (i.e. revenue) can be loaded into a single table for model training
snow_df_spend_and_revenue_per_month_t = snow_df_spend_per_month_t.join(snow_df_revenue_per_month_t, ["YEAR","MONTH"])
# SAVE in a new table for the next task
snow_df_spend_and_revenue_per_month_t.write.mode('overwrite').save_as_table('SPEND_AND_REVENUE_PER_MONTH')
# Register data pipelining function as a Stored Procedure so it can be run as a task
session.sproc.register(
func=monthly_revenue_data_pipeline,
name="monthly_revenue_data_pipeline",
packages=['snowflake-snowpark-python'],
is_permanent=True,
stage_location="@dash_sprocs",
replace=True)
monthly_revenue_data_pipeline_task = """
CREATE OR REPLACE TASK monthly_revenue_data_pipeline_task
WAREHOUSE = 'DASH_L'
AFTER campaign_spend_data_pipeline_task
AS
CALL monthly_revenue_data_pipeline()
"""
session.sql(monthly_revenue_data_pipeline_task).collect()
注意:上記のmonthly_revenue_data_pipeline_taskには、AFTER campaign_spend_data_pipeline_task句があり、依存タスクであることに注意してください。
タスクの開始
Snowflakeタスクはデフォルトでは開始されないため、開始/再開するには次のステートメントを実行する必要があります。
session.sql("alter task monthly_revenue_data_pipeline_task resume").collect()
session.sql("alter task campaign_spend_data_pipeline_task resume").collect()
タスクの中断
上記のタスクを再開する場合は、不要なリソース使用を回避するため、次のコマンドを実行してタスクを一時停止してください。
session.sql("alter task campaign_spend_data_pipeline_task suspend").collect()
session.sql("alter task monthly_revenue_data_pipeline_task suspend").collect()
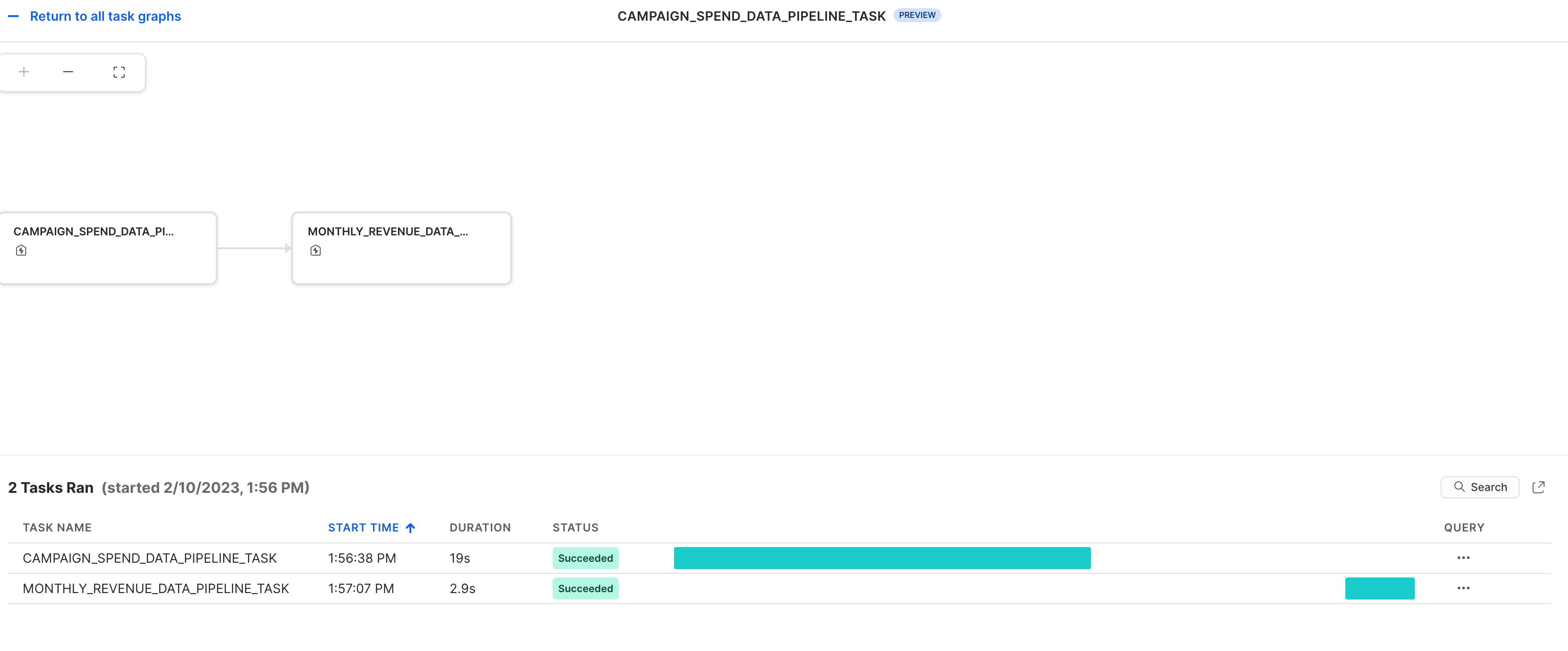
タスクの監視
これらのタスクとそのDAGは、Snowsightで次のように表示できます。
タスクのエラー通知
タスクの実行中にエラーが発生したときに、クラウドメッセージングサービスへのプッシュ通知を有効にすることもできます。詳細については、ドキュメントを参照してください。
前提条件:Snowpark_For_Python_DE.ipynbで説明されているデータエンジニアリングの手順が正常に完了していること。
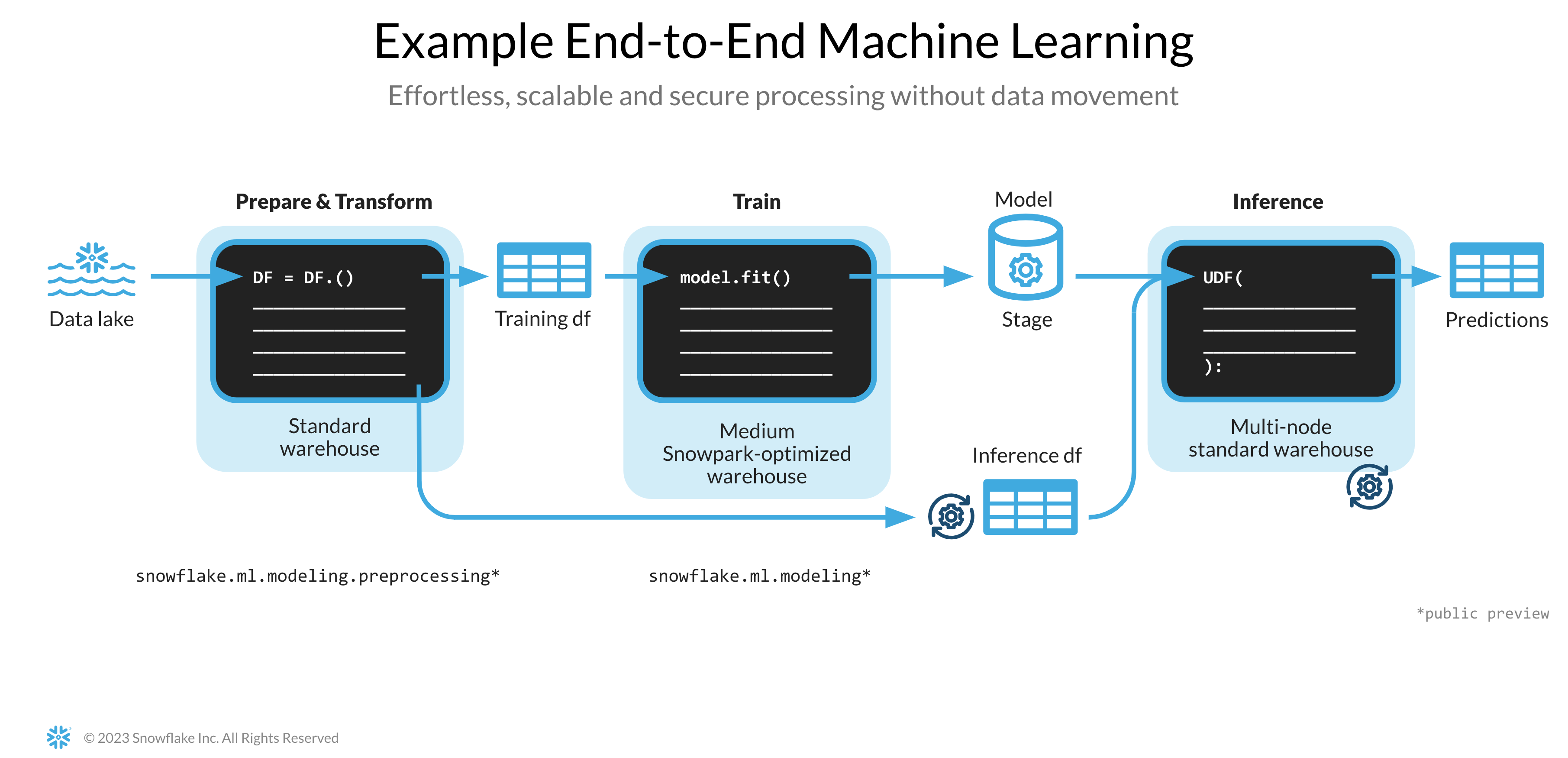
下記リンク先のノートブックでは、次の機械学習タスクを説明しています。
- Snowpark PythonからSnowflakeへの安全な接続を確立する
- SnowflakeテーブルからSnowpark DataFramesに機能とターゲットを読み込む
- モデルトレーニングのための機能を準備する
- SnowflakeでSnowpark MLを使用してMLモデルをトレーニングする
- オンライン推論とオフライン推論のそれぞれに、新しいデータポイントに対する推論用のスカラーおよびベクトル化された(別名バッチ)Pythonユーザー定義関数(UDF)を作成する
JupyterまたはVisual Studio Codeの機械学習ノートブック
開始するには、次の手順に従います。
- ターミナルウィンドウで、このフォルダを参照し、コマンドラインで
jupyter notebookを実行します(他のツールやVisual Studio CodeなどのIDEを使用することもできます)。 - Snowpark_For_Python_ML.ipynbを開いて実行します。
重要:Jupyterノートブックで、(Python)カーネルがsnowpark-de-mlに設定されていることを確認してください。これは、GitHubレポジトリの複製ステップで作成した環境の名前です。
Hexの機械学習ノートブック
既存のHexアカウントを使用する場合、または30日間の無料トライアルアカウントを作成する場合は、次の手順に従ってノートブックをロードし、HexからSnowflakeに接続するためのデータ接続を作成します。
- Snowpark_For_Python_ML.ipynbをプロジェクトとしてアカウントにインポートします。インポートの詳細については、ドキュメントを参照してください。
- 次に、Snowflakeへの接続にconnection.jsonを使用する代わりに、以下に示すようにデータ接続を作成し、それを機械学習ノートブックで使用します。
注意:ワークスペース内のプロジェクトやユーザーに対して、共有データ接続を作成することもできます。詳細については、ドキュメントを参照してください。
- ノートブックの次のコードスニペットを置き換えます。
connection_parameters = json.load(open('connection.json'))
session = Session.builder.configs(connection_parameters).create()
以下に置き換えます。
import hextoolkit
hex_snowflake_conn = hextoolkit.get_data_connection('YOUR_DATA_CONNECTION_NAME')
session = hex_snowflake_conn.get_snowpark_session()
session.sql('USE SCHEMA DASH_SCHEMA').collect()
Streamlitアプリをローカルで実行する
ターミナルウィンドウでこのフォルダを参照し、次のコマンドを実行して、StreamlitアプリケーションSnowpark_Streamlit_Revenue_Prediction.pyをマシンのローカルで実行します。
streamlit run Snowpark_Streamlit_Revenue_Prediction.py
問題がなければ、次のようにアプリが読み込まれた状態でブラウザウィンドウが開きます。
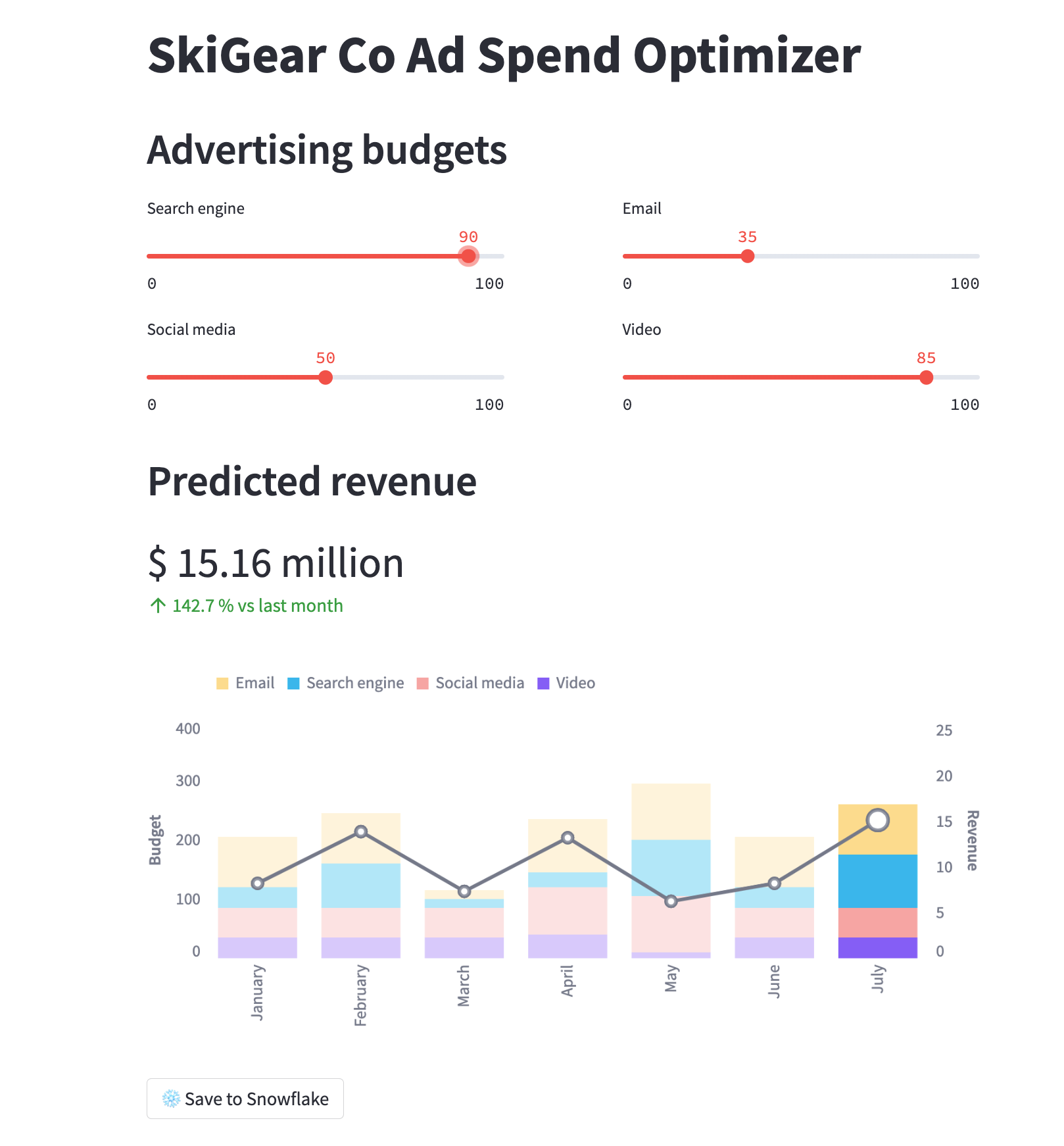
StreamlitアプリをSnowflakeで実行する - Streamlit-in-Snowflake(SiS)
アカウントでSiSを有効にしている場合は、次の手順に従って、アプリケーションをマシンのローカルではなく、Snowsightで実行します。
重要:2023年6月現在、SiSはプライベートプレビュー中です。
- 左側のナビゲーションメニューで 「Streamlit」 をクリックします。
- 右上の 「+ Streamlitアプリ」 をクリックします。
- アプリ名 を入力します。
- Streamlitアプリケーションを作成する 「ウェアハウス」 と 「アプリの場所」(データベースとスキーマ)を選択します。
- 「作成」 をクリックします。
- この時点で、Streamlitのサンプルアプリケーションのコードが提供されます。Snowpark_Streamlit_Revenue_Prediction_SiS.pyを開き、コードをStreamlitのサンプルアプリケーションにコピーして貼り付けます。
- 右上の 「実行」 をクリックします。
問題がなければ、以下に示すように、Snowsightに次のアプリが表示されます。
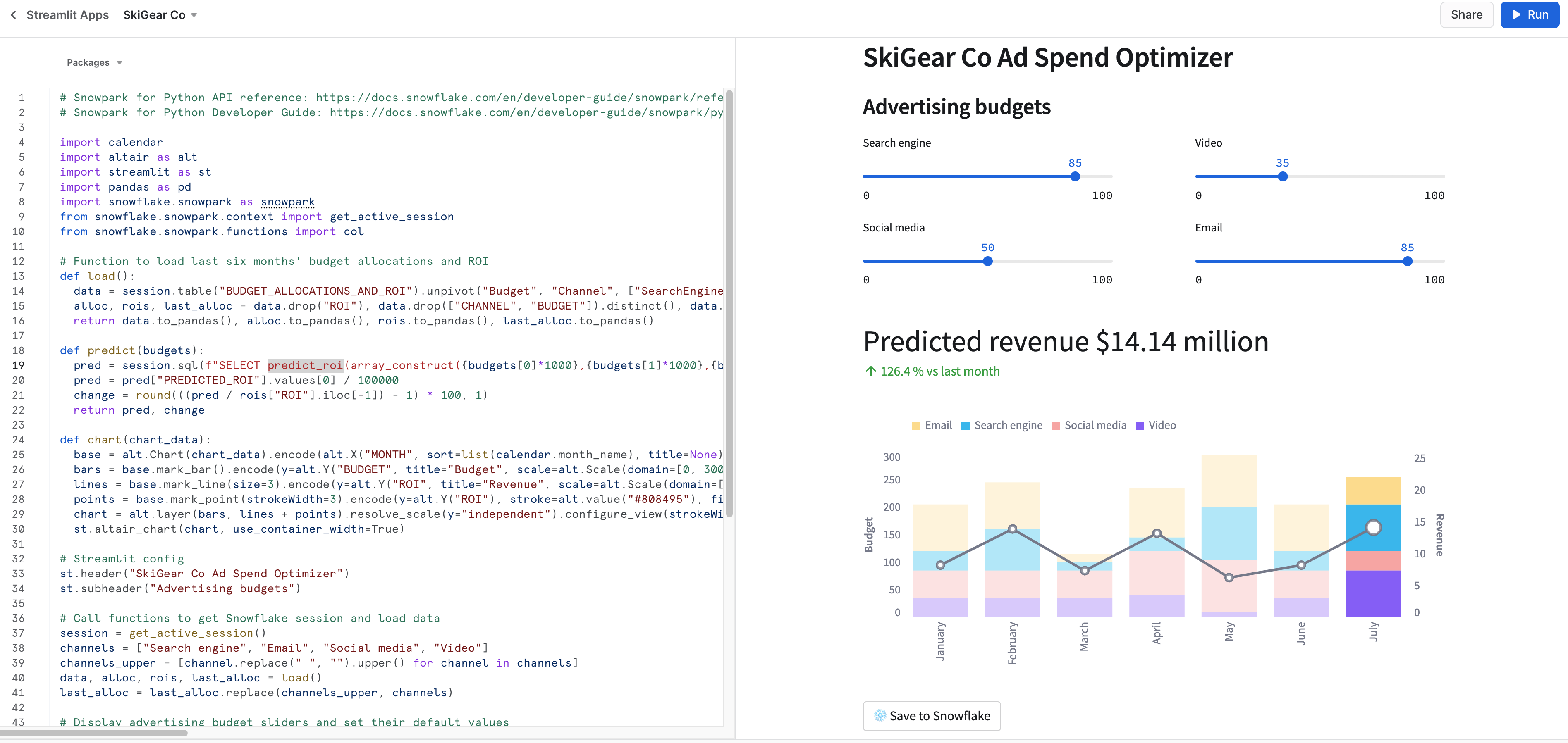
データをSnowflakeに保存する
両方のアプリケーションで、広告予算スライダーを調整して、それらの割り当ての予測ROIを確認します。 「Snowflakeに保存」 ボタンをクリックして、現在の割り当てと予測ROIをBUDGET_ALLOCATIONS_AND_ROI Snowflakeテーブルに保存することもできます。
2つのStreamlitアプリの違い
Streamlitアプリケーションをローカルで実行する場合とSnowflake(SiS)で実行する場合の主な違いは、セッションオブジェクトを作成してアクセスする方法です。
ローカルで実行する場合は、次のように新しいセッションオブジェクトを作成してアクセスします。
# Function to create Snowflake Session to connect to Snowflake
def create_session():
if "snowpark_session" not in st.session_state:
session = Session.builder.configs(json.load(open("connection.json"))).create()
st.session_state['snowpark_session'] = session
else:
session = st.session_state['snowpark_session']
return session
Snowflake(SiS)で実行する場合は、次のように現在のSessionオブジェクトにアクセスします。
session = snowpark.session._get_active_session()
「データエンジニアリング」セクションまたは「データパイプライン」セクションの一部として、2つのタスクmonthly_revenue_data_pipeline_taskとcampaign_spend_data_pipeline_taskを開始/再開した場合は、不要なリソース使用を回避するため、次のコマンドを実行してこれらのタスクを一時停止することが重要です。
ノートブックでSnowpark Python APIを使用する場合
session.sql("alter task campaign_spend_data_pipeline_task suspend").collect()
session.sql("alter task monthly_revenue_data_pipeline_task suspend").collect()
Snowsightの場合
alter task campaign_spend_data_pipeline_task suspend;
alter task monthly_revenue_data_pipeline_task suspend;
おめでとうございます。Snowpark for Pythonとscikit-learnを使用して、データエンジニアリングタスクを正常に実行し、検索、ビデオ、ソーシャルメディア、メールなど複数のチャネルで変動する広告費予算の将来のROI(投資収益率)を予測する線形回帰モデルトレーニングしました。次に、そのモデルを使用して、ユーザー入力に基づいて新しい予算配分の予測を生成するStreamlitアプリケーションを作成しました。
このクイックスタートガイドに関するフィードバックをお待ちしています。こちらのフィードバックフォームからフィードバックをお寄せください。
学習した内容
- Snowpark DataFramesとAPIを利用してデータを分析し、データエンジニアリングタスクを実行する方法
- 厳選されたSnowflake AnacondaチャネルからオープンソースのPythonライブラリを使用する方法
- SnowflakeでSnowpark MLを使用してMLモデルをトレーニングする方法
- オンライン推論とオフライン推論のそれぞれに、スカラーおよびベクトル化されたSnowpark Pythonユーザー定義関数(UDF)を作成する方法
- Snowflakeタスクを作成してデータパイプラインとモデルの(再)トレーニングを自動化する方法
- 推論にスカラーUDFを使用するStreamlitウェブアプリケーションを作成する方法