
This guide will provide step-by-step instructions for how to build a simple CI/CD pipeline for Snowflake with Azure DevOps. My hope is that this will provide you with enough details to get you started on your DevOps journey with Snowflake and Azure DevOps.
DevOps is concerned with automating the development, release and maintenance of software applications. As such, DevOps is very broad and covers the entire Software Development Life Cycle (SDLC). The landscape of software tools used to manage the entire SDLC is complex since there are many different required capabilities/tools, including:
- Requirements management
- Project management (Waterfall, Agile/Scrum)
- Source code management (Version Control)
- Build management (CI/CD)
- Test management (CI/CD)
- Release management (CI/CD)
This guide will focus primarily on automated release management for Snowflake by leveraging the Azure Pipelines service from Azure DevOps. Additionally, in order to manage the database objects/changes in Snowflake I will use the schemachange Database Change Management (DCM) tool.
Let's begin with a brief overview of Azure DevOps and schemachange.
Prerequisites
This guide assumes that you have a basic working knowledge of Git repositories.
What You'll Learn
- A brief history and overview of Azure DevOps
- A brief history and overview of schemachange
- How database change management tools like schemachange work
- How a simple release pipeline works
- How to create CI/CD pipelines in Azure DevOps
- Ideas for more advanced CI/CD pipelines with stages
- How to get started with branching strategies
- How to get started with testing strategies
What You'll Need
You will need the following things before beginning:
- Snowflake
- A Snowflake Account.
- A Snowflake Database named DEMO_DB.
- A Snowflake User created with appropriate permissions. This user will need permission to create objects in the DEMO_DB database.
- Azure DevOps
- An Azure DevOps Services Account. If you don't already have an Azure DevOps Services account you can create a Basic Plan for free. Click on the
Start freebutton on the Azure DevOps Overview page. - An Azure DevOps Organization. If you don't already have an Organization created, log in to Azure DevOps and click on the
New organizationlink in the left navigation bar. - An Azure DevOps Project. If you don't already have a Project created, log in to Azure DevOps, make sure the correct Organization is selected in the left navigation bar, and click on the
+ New projectbutton near the top right of the window. Keep the default setting for a Private project with Git version control. - An Azure DevOps Git Repository. A Git repository should have automatically been created in your Project when the Project was created (and by default has the same name as the Project). If you don't have one, or would like to create a new one, open the Project, click on
Reposin the left navigation bar, click on the drop down arrow next to the current repository name in the top navigation bar breadcrumbs and click on+ New repository. - Integrated Development Environment (IDE)
- Your favorite IDE with Git integration. If you don't already have a favorite IDE that integrates with Git I would recommend the great, free, open-source Visual Studio Code.
- Your project repository cloned to your computer. For connection details about the Git repository in your project, open the Project and click on the
Reposicon in the left navigation bar. If your repository is empty you will see the options for cloning to your computer. If your repository has files in it already you will see aClonebutton near the top right of the window which will give you the options.
What You'll Build
- A simple, working release pipeline for Snowflake in Azure DevOps

"Azure DevOps provides developer services for support teams to plan work, collaborate on code development, and build and deploy applications. Developers can work in the cloud using Azure DevOps Services or on-premises using Azure DevOps Server." (from Microsoft's What is Azure DevOps?)
Azure DevOps Services
Azure DevOps provides a complete, end-to-end set of software development tools to manage the SDLC. In particular Azure DevOps provides the following services (from Microsoft's What is Azure DevOps?):
- Azure Repos provides Git repositories or Team Foundation Version Control (TFVC) for source control of your code
- Azure Pipelines provides build and release services to support continuous integration and delivery of your apps
- Azure Boards delivers a suite of Agile tools to support planning and tracking work, code defects, and issues using Kanban and Scrum methods
- Azure Test Plans provides several tools to test your apps, including manual/exploratory testing and continuous testing
- Azure Artifacts allows teams to share packages such as Maven, npm, NuGet and more from public and private sources and integrate package sharing into your CI/CD pipelines
Azure DevOps History
If you've worked with Microsoft products for a while you will know that over time product names evolve. The first version of what is today called Azure DevOps was released on March 17, 2006 as a component of the Visual Studio 2005 Team System under the name Team Foundation Server (TFS). Over the years it has been known by various names including Team Foundation Server (TFS), Visual Studio Online (VSO), Visual Studio Team Services (VSTS), and Azure DevOps. For fun, here is the history of product names from Wikipedia's Azure DevOps Server page:
Product name | Form | Release year |
Visual Studio 2005 Team System | On-premises | 2006 |
Visual Studio Team System 2008 | On-premises | 2008 |
Team Foundation Server 2010 | On-premises | 2010 |
Team Foundation Service Preview | Cloud | 2012 |
Team Foundation Server 2012 | On-premises | 2012 |
Visual Studio Online | Cloud | 2013 |
Team Foundation Server 2013 | On-premises | 2013 |
Team Foundation Server 2015 | On-premises | 2015 |
Visual Studio Team Services | Cloud | 2015 |
Team Foundation Server 2017 | On-premises | 2017 |
Team Foundation Server 2018 | On-premises | 2017 |
Azure DevOps Services | Cloud | 2018 |
Azure DevOps Server 2019 | On-premises | 2019 |
This guide will be focused on the Azure Pipelines service.

Database Change Management (DCM) refers to a set of processes and tools which are used to manage the objects within a database. It's beyond the scope of this guide to provide details around the challenges with and approaches to automating the management of your database objects. If you're interested in more details, please see my blog post Embracing Agile Software Delivery and DevOps with Snowflake.
schemachange is a lightweight Python-based tool to manage all your Snowflake objects. It follows an imperative-style approach to database change management (DCM) and was inspired by the Flyway database migration tool. When schemachange is combined with a version control tool and a CI/CD tool, database changes can be approved and deployed through a pipeline using modern software delivery practices.
For more information about schemachange please see the schemachange project page.
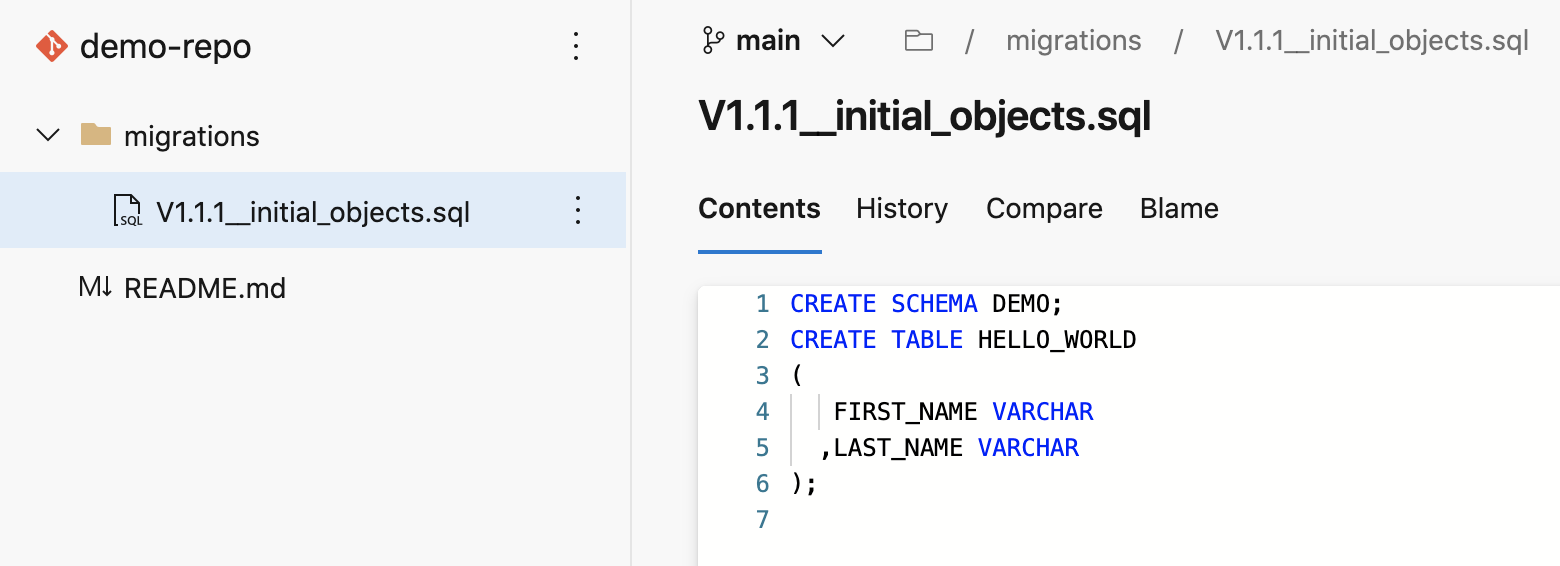
Open up your cloned repository in your favorite IDE and create a folder named migrations. In that new folder create a script named V1.1.1__initial_objects.sql (make sure there are two underscores after the version number) with the following contents:
CREATE SCHEMA DEMO;
CREATE TABLE HELLO_WORLD
(
FIRST_NAME VARCHAR
,LAST_NAME VARCHAR
);
Then commit the new script and push the changes to your Azure DevOps repository. Assuming you started from an empty repository, initialized with only a README.md file, your repository should look like this:
Libraries in the Azure Pipelines service are used to securely store variables and files which will be used in your CI/CD pipelines. In this step we will create a variable group to store all the parameters used by schemachange.
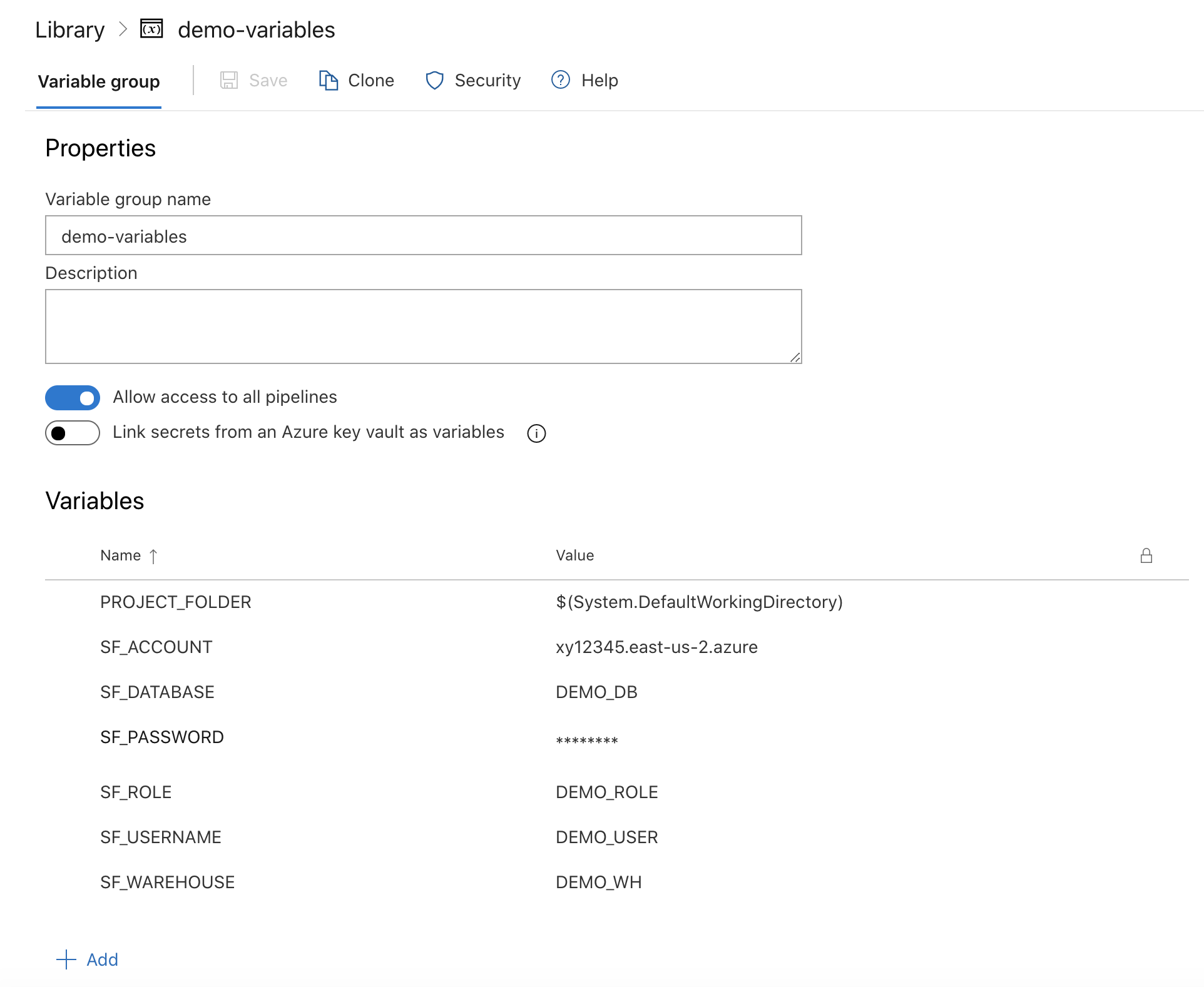
In the left navigation bar, click on Pipelines and then Library. On the Library page, the Variable groups tab should be selected. Click on the + Variable group button. Name your variable group demo-variables and add the following variables to the group (adjusting the values as appropriate):
Variable name | Variable value | Secret? |
PROJECT_FOLDER | $(System.DefaultWorkingDirectory) | No |
SF_ACCOUNT | xy12345.east-us-2.azure | No |
SF_USERNAME | DEMO_USER | No |
SF_PASSWORD | ***** | Yes |
SF_ROLE | DEMO_ROLE | No |
SF_WAREHOUSE | DEMO_WH | No |
SF_DATABASE | DEMO_DB | No |
When you're finished adding all the variables, don't forget to click the Save icon below the name of the variable group. Your variable group should look like this:
Pipelines in the Azure Pipelines service represent any automated pipeline, which includes both build and release pipelines. In this step we will create a deployment pipeline which will run schemachange and deploy changes to our Snowflake database.
- In the left navigation bar, click on
Pipelinesand thenPipelines. - Click on the
Create Pipelinebutton (orNew pipelinein the upper right if you already have another pipeline defined). - On the first
Where is your code?screen click onAzure Repos Git, then select your repository on the next screen. - On the
Configure your pipelinepage selectStarter pipeline. - And on the final
Review your pipeline YAML pagecopy and paste the following YAML pipeline definition (overwriting the sample pipeline code):
# Deploy database changes using schemachange
# https://github.com/Snowflake-Labs/schemachange
# (see https://aka.ms/yaml for the YAML schema reference)
trigger:
branches:
include:
- main
paths:
include:
- /migrations
pool:
vmImage: 'ubuntu-latest'
variables:
- group: demo-variables
steps:
- task: UsePythonVersion@0
displayName: 'Use Python 3.8.x'
inputs:
versionSpec: '3.8.x'
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Starting bash task'
echo "PROJECT_FOLDER $(PROJECT_FOLDER)"
python --version
echo 'Step 1: Installing schemachange'
pip install schemachange --upgrade
echo 'Step 2: Running schemachange'
schemachange -f $(PROJECT_FOLDER)/migrations -a $(SF_ACCOUNT) -u $(SF_USERNAME) -r $(SF_ROLE) -w $(SF_WAREHOUSE) -d $(SF_DATABASE) -c $(SF_DATABASE).SCHEMACHANGE.CHANGE_HISTORY --create-change-history-table
env:
SNOWFLAKE_PASSWORD: $(SF_PASSWORD)
Finally, click on the Save and run near the top right of the window (and on the Save and run button in the pop up window).
On the pipeline run overview page click on the Job job to see the output of each step in the pipeline. In particular, look through the Bash step logs to see the output from schemachange.
A few things to point out from the YAML pipeline definition:
- The YAML pipeline definition is saved as a file in your repository. The default name is
azure-pipelines.ymlbut that can (and should) be changed when you have multiple pipelines. - The trigger definition configures the pipeline to automatically run when a change is committed anywhere in the
migrationsfolder on themainbranch of the repository. So any change committed outside of that folder or in a different branch will not automatically trigger the pipeline to run. - Please note that if you are re-using an existing Azure DevOps Account and Organization your new Project Repository might retain the old
masterbranch naming. If so, please update the YAML above (see thetriggersection). - We're using the default Microsoft-hosted Linux agent pool to execute the pipeline.
- The
envsection of the Bash task allows us to set environment variables which will be available to the Bash script. In particular, this allows us to securely pass secret values (like the Snowflake password) to applications/scripts running in the pipeline like schemachange.
Now that your first database migration has been deployed to Snowflake, log into your Snowflake account and confirm.
Database Objects
You should now see a few new objects in your DEMO_DB database:
- A new schema
DEMOand tableHELLO_WORLD(created by the first migration script from step 4) - A new schema
SCHEMACHANGEand tableCHAGE_HISTORY(created by schemachange to track deployed changes)
Take a look at the contents of the CHANGE_HISTORY table to see where/how schemachange keeps track of state. See the schemachange README for more details.
Query History
From your Snowflake account click on the History tab at the top of the window. From there review the queries that were executed by schemachange. In particular, look at the Query Tag column to see which queries were issued by schemachange. It even tracks which migration script was responsible for which queries.
Open up your cloned repository in your favorite IDE and create a script named V1.1.2__updated_objects.sql (make sure there are two underscores after the version number) in the same migrations folder with the following contents:
USE SCHEMA DEMO;
ALTER TABLE HELLO_WORLD ADD COLUMN AGE NUMBER;
Then commit the new script and push the changes to your Azure DevOps repository. Because of the continuous integration trigger we created in the YAML definition, your pipeline should have automatically started a new run. Open up the pipeline, click on the newest run, then click on the Job job to see the output.
So now that you've got your first Snowflake CI/CD pipeline set up, what's next? The software development life cycle, including CI/CD pipelines, gets much more complicated in the real-world. Best practices include pushing changes through a series of environments, adopting a branching strategy, and incorporating a comprehensive testing strategy, to name a few.
Pipeline Stages
In the real-world you will have multiple stages in your build and release pipelines. A simple, helpful way to think about stages in a deployment pipeline is to think about them as environments, such as dev, test, and prod. Your Azure Pipelines YAML definition file can be extended to include a stage for each of your environments. For more details around how to define stages, please refer to Azure DevOp's Add stages, dependencies, & conditions page.
Branching Strategy
Branching strategies can be complex, but there are a few popular ones out there that can help get you started. To begin with I would recommend keeping it simple with GitHub flow (and see also an explanation of GitHub flow by Scott Chacon in 2011). Another simple framework to consider is GitLab flow.
Testing Strategy
Testing is an important part of any software development process, and is absolutely critical when it comes to automated software delivery. But testing for databases and data pipelines is complicated and there are many approaches, frameworks, and tools out there. In my opinion, the simplest way to get started testing data pipelines is with dbt and the dbt Test features. Another popular Python-based testing tool to consider is Great Expectations.
With that you should now have a working CI/CD pipeline in Azure DevOps and some helpful ideas for next steps on your DevOps journey with Snowflake. Good luck!
What We've Covered
- A brief history and overview of Azure DevOps
- A brief history and overview of schemachange
- How database change management tools like schemachange work
- How a simple release pipeline works
- How to create CI/CD pipelines in Azure DevOps
- Ideas for more advanced CI/CD pipelines with stages
- How to get started with branching strategies
- How to get started with testing strategies