"데이터 엔지니어는 기본적으로 여러 단계를 거쳐 데이터를 전송하는 데이터 파이프라인을 구축 및 유지하는 데 집중하고 이를 사용 가능한 상태로 만듭니다. 데이터 엔지니어링 프로세스에는 한 장소에서 다른 장소로 데이터를 전송하는 것을 자동화하고 이러한 데이터를 특정 유형의 분석을 위해 특성 형식으로 변환하는 데이터 파이프라인을 생성하기 위한 종합적인 노력이 포함됩니다. 이러한 측면에서 보면 데이터 엔지니어링은 한 번에 끝낼 수 있는 작업이 아닙니다. 이는 지속적인 관행이며 데이터를 수집하고, 준비하고, 변환하고, 전달해야 합니다. 데이터 파이프라인은 신뢰할 수 있는 방식으로 반복할 수 있도록 이러한 작업을 자동화하는 것을 돕습니다. 이는 특정 기술이라기보다는 오히려 관행입니다." (출처: Cloud Data Engineering for Dummies, Snowflake 특별 에디션)
데이터 엔지니어링 파이프라인을 구축하기 위해 Snowpark Python의 위력을 활용하는 데 관심이 있으신가요? 그렇다면 이 Quickstart가 도움이 될 것입니다! 여기에서는 데이터 사이언스가 아니라 Python을 사용하여 데이터 엔지니어링 파이프라인을 구축하는 방법에 집중하겠습니다. Snowpark Python을 사용한 데이터 사이언스의 사례는 Machine Learning with Snowpark Python: - Credit Card Approval Prediction Quickstart를 참조하십시오.
이 Quickstart는 많은 내용을 다룹니다. 이 가이드를 완료하는 시점에는 Snowpark Python 저장 프로시저를 사용하여 강력한 데이터 엔지니어링 파이프라인을 구축했을 것입니다. 이러한 파이프라인은 데이터를 증분적으로 처리하고, Snowflake 작업과 조정되고, CI/CD 파이프라인을 통해 배포됩니다. 또한, Snowflake의 새로운 개발자 CLI 도구 및 Visual Studio Code 확장 프로그램을 사용하는 방법을 배우게 됩니다. 간략한 시각적 개요는 다음과 같습니다.
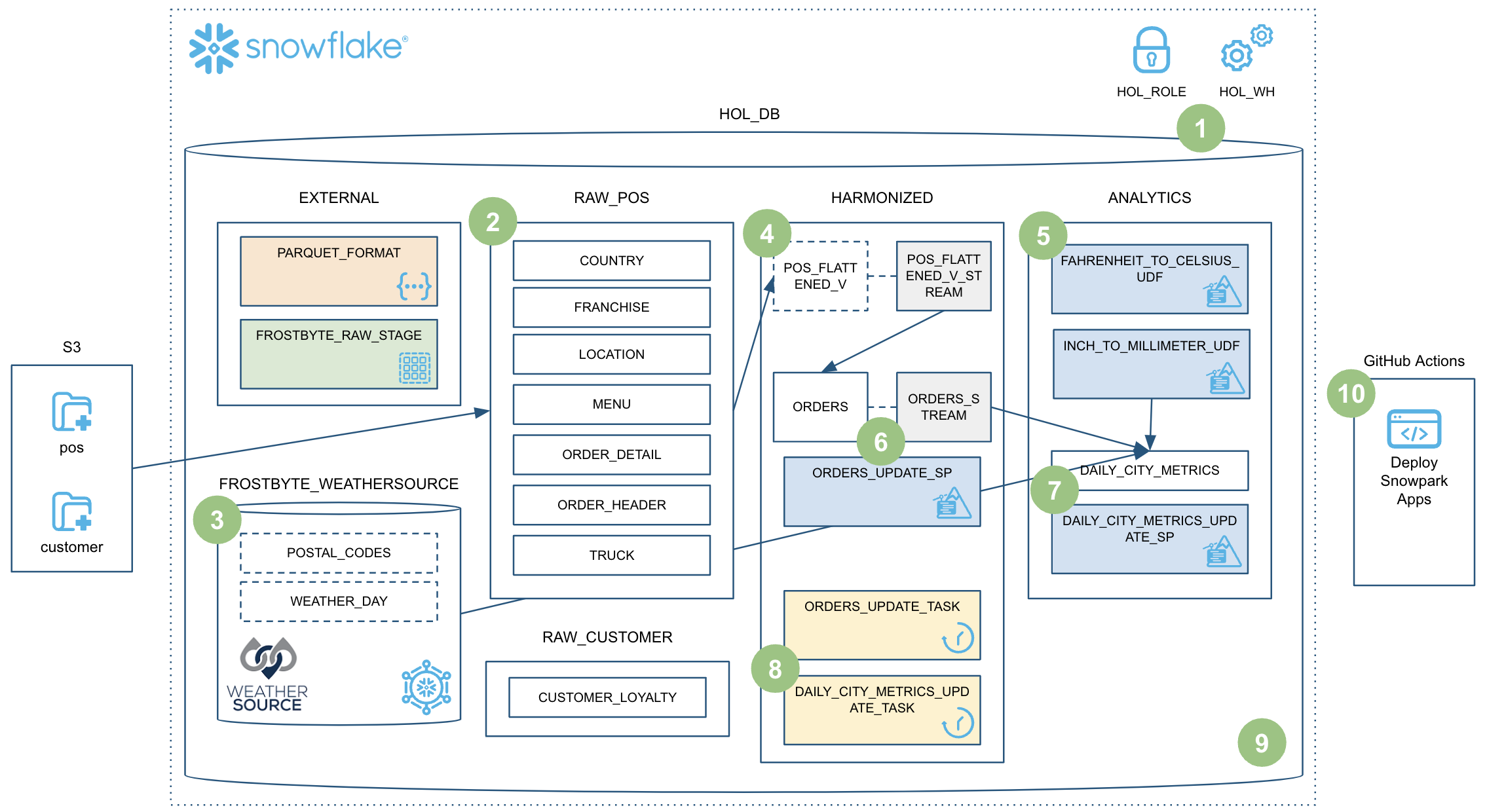
마음의 준비를 하십시오!
사전 필요 조건 및 지식
- Python 사용 경험
- DataFrame API 사용 경험
- Snowflake 사용 경험
- Git 리포지토리 및 GitHub 사용 경험
학습할 내용
이 Quickstart를 진행하는 동안 다음 Snowflake 기능을 학습하게 됩니다.
- Snowflake의 테이블 형식
- COPY를 사용한 데이터 수집
- 스키마 추론
- 데이터 공유 및 마켓플레이스(ETL 대신)
- 증분적 처리를 위한 스트림(CDC)
- 뷰의 스트림
- Python UDF(서드 파티 패키지 포함)
- Python 저장 프로시저
- Snowpark DataFrame API
- Snowpark Python 프로그램 가능성
- 웨어하우스 탄력성(동적 규모 조정)
- Visual Studio Code Snowflake 네이티브 확장 프로그램(PuPr, Git 통합)
- SnowCLI(PuPr)
- 작업(스트림 트리거 포함)
- 작업 관측 가능성
- GitHub Actions(CI/CD) 통합
필요한 것
시작하기 전에 다음이 필요합니다.
- Snowflake
- Snowflake 계정
- ACCOUNTADMIN 권한을 포함하여 생성된 Snowflake 사용자 이 사용자를 사용하여 Snowflake에서 설정을 진행합니다.
- Anaconda 사용 약관 수락 서드 파티 패키지에서 시작하기 섹션을 참조하십시오.
- Miniconda
- 컴퓨터에 Miniconda 설치 Miniconda를 다운로드 및 설치합니다. 대신에 Python 3.8을 포함한 다른 모든 Python 환경을 사용할 수 있습니다.
- SnowSQL
- 컴퓨터에 SnowSQL 설치 SnowSQL 다운로드 페이지로 이동하여 상세 정보를 SnowSQL 설치 페이지에서 확인하십시오.
- Git
- 컴퓨터에 Git 설치 상세 정보는 시작하기 - Git 설치 페이지에서 확인하십시오.
- 자신의 사용자 이름 및 이메일 주소로 Git 구성 아직 구성하지 않았다면 로컬 컴퓨터에서 Git 사용자 이름 및 Git 이메일 주소를 설정하십시오.
- 필수 확장 프로그램을 포함한 Visual Studio Code
- 컴퓨터에 Visual Studio Code 설치 다운로드 페이지 링크는 Visual Studio Code 홈페이지에서 확인하십시오.
- Python 확장 프로그램 설치 VS Code의 Extensions 창에서 ‘Python' 확장 프로그램(Microsoft 제공)을 검색 및 설치하십시오.
- Snowflake 확장 프로그램 설치 VS Code의 Extensions 창에서 ‘Snowflake' 확장 프로그램(Snowflake 제공)을 검색 및 설치하십시오.
- 로컬에서 포크 및 복제된 랩 리포지토리를 포함한 GitHub 계정
- GitHub 계정 GitHub 계정이 아직 없다면 무료로 생성할 수 있습니다. 시작하려면 GitHub 가입 페이지를 방문하십시오.
구축할 것
이 Quickstart를 진행하는 동안 다음 작업을 완수하게 됩니다.
- 스키마 추론을 사용하여 Snowflake로 Parquet 데이터 로드
- Snowflake 마켓플레이스 데이터에 대한 액세스 설정
- 온도 변환을 위해 Python UDF 생성
- 증분적 데이터 처리를 위해 Python 저장 프로시저로 데이터 엔지니어링 파이프라인 생성
- 파이프라인을 작업과 조정
- Snowsight로 파이프라인 모니터링
- CI/CD 파이프라인을 통해 Snowpark Python 저장 프로시저 배포
Quickstart를 위해 리포지토리 포크 및 복제
자신의 GitHub 계정에서 이 Quickstart를 위한 리포지토리 포크를 생성해야 합니다. Data Engineering Pipelines with Snowpark Python(Snowpark Python을 사용한 데 파이프라인) 관련 GitHub 리포지토리를 방문하여 오른쪽 상단 부근에 있는 ‘Fork' 버튼을 클릭합니다. 모든 필수 필드를 완료하고 ‘Create Fork'를 클릭합니다.
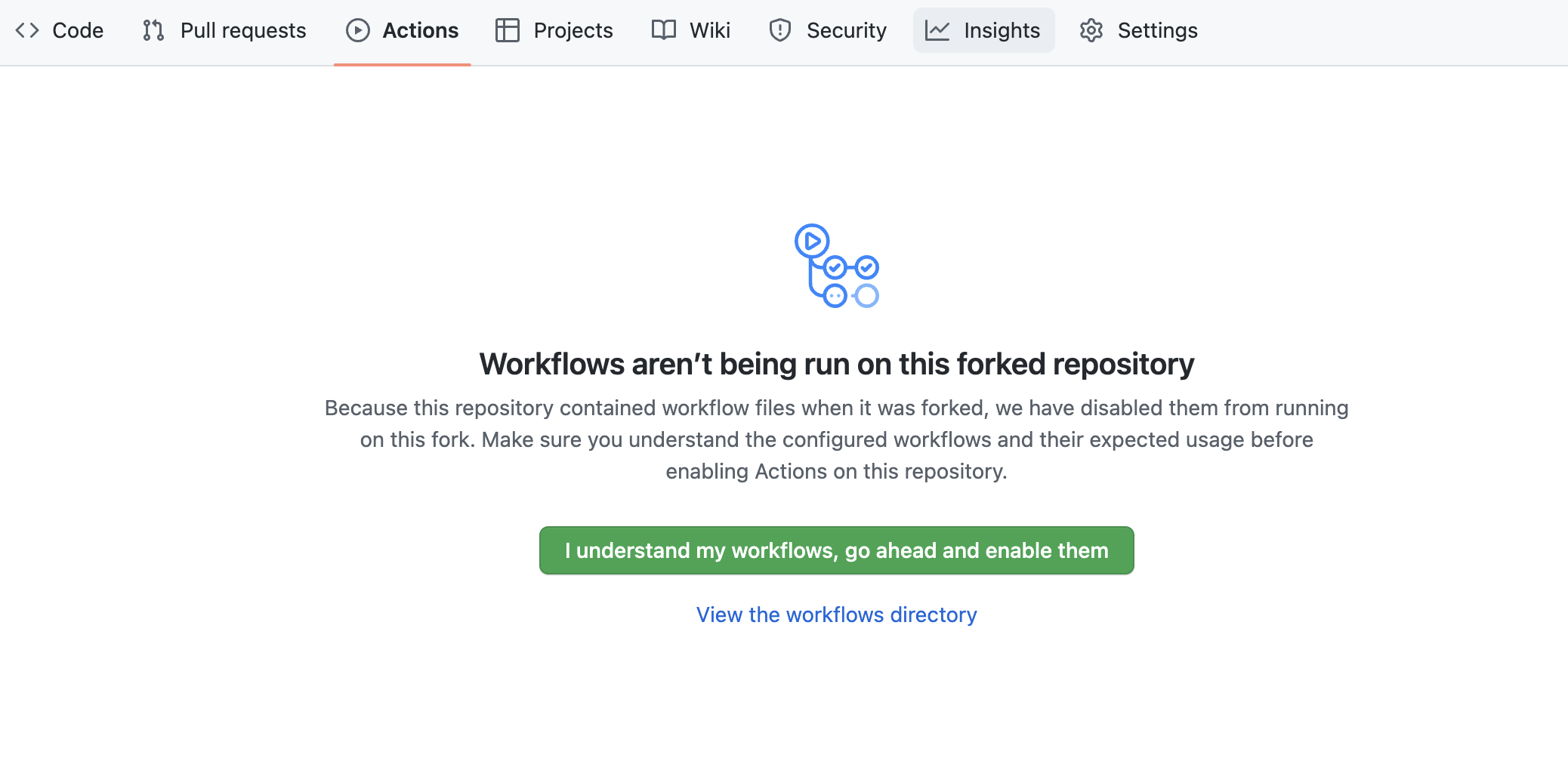
기본값으로 GitHub Actions는 포크된 리포지토리에 정의된 모든 워크플로우(또는 CI/CD 파이프라인)를 비활성화합니다. 이 리포지토리에는 나중에 사용할 Snowpark Python UDF 및 저장 프로시저를 배포하기 위한 워크플로우가 포함되어 있습니다. 지금은 GitHub에서 포크된 리포지토리를 열어 이 워크플로우를 활성화합니다. 페이지 상단 중앙 부근에 있는 Actions 탭을 클릭한 다음 I understand my workflows, go ahead and enable them 녹색 버튼을 클릭합니다.
다음으로 새로운 포크된 리포지토리를 로컬 컴퓨터로 복제해야 합니다. 새로운 Git 리포지토리에 대한 연결 세부 정보를 확인하려면 리포지토리를 열고, 페이지 상단 부근에 있는 녹색 ‘Code' 아이콘을 클릭하고, ‘HTTPS' 링크를 복사합니다.
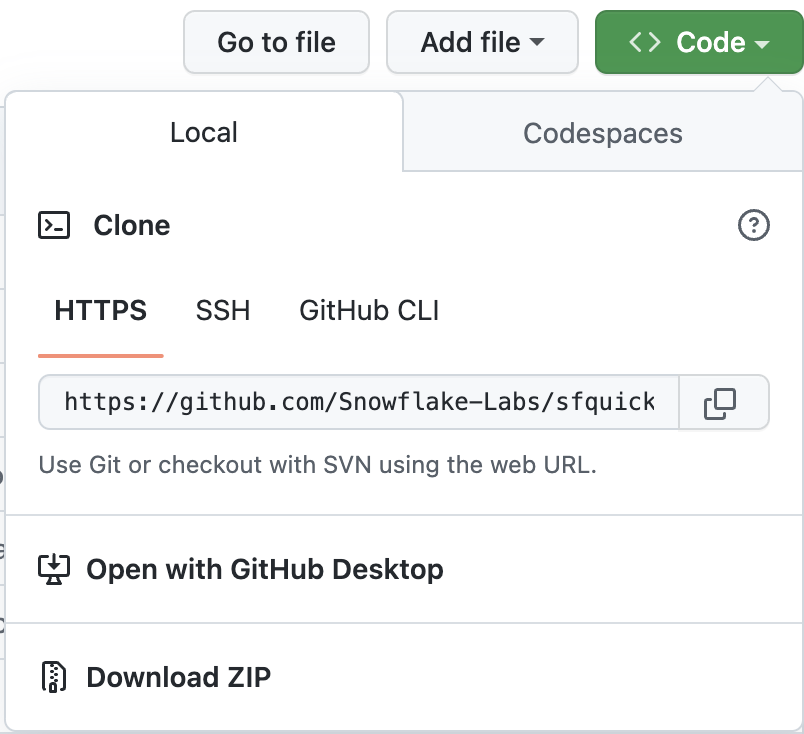
VS Code에서 이 링크를 사용하여 리포지토리를 컴퓨터에 복제합니다. 상세 정보를 위해 Visual Studio Code에서 GitHub 리포지토리 복제 및 사용 지침을 따르십시오. 또한, 선호에 따라 다음 명령을 실행하여 명령줄에서 리포지토리를 복제할 수도 있습니다.
git clone <your-forked-repo-url>
cd sfguide-data-engineering-with-snowpark-python/
포크된 리포지토리가 로컬 컴퓨터에 복제되면 VS Code로 폴더를 엽니다.
자격 증명 구성
이 Quickstart에서 SnowSQL 명령줄 클라이언트를 바로 사용하지는 않겠지만, ~/.snowsql/config에 있는 SnowSQL 구성 파일에 Snowflake 연결 세부 정보를 저장하겠습니다. 해당 SnowSQL 구성 파일이 존재하지 않는다면 빈 구성 파일을 생성하십시오.
다음 섹션을 ~/.snowsql/config 파일에 추가하여 이 랩을 위한 SnowSQL 구성을 생성합니다(계정 이름, 사용자 이름 및 암호는 자신의 값으로 바꿈).
[connections.dev]
accountname = myaccount
username = myusername
password = mypassword
rolename = HOL_ROLE
warehousename = HOL_WH
dbname = HOL_DB
참고: SnowCLI 도구(및 이 Quickstart의 확장 프로그램)는 현재 키 쌍 인증과 작동하지 않습니다. 이는 사용자 이름과 암호 세부 정보를 공유 SnowSQL 구성 파일에서 가져오기만 합니다.
Anaconda 환경 생성
제공된 conda_env.yml 파일을 사용하여 이 랩을 위한 Conda 환경을 생성 및 활성화합니다. 포크된 로컬 리포지토리 루트의 터미널에서 이 명령을 실행합니다.
conda env create -f conda_env.yml
conda activate pysnowpark
VS Code용 Snowflake 확장 프로그램
다양한 방식(Snowsight UI, SnowSQL 등)으로 Snowflake에 대해 SQL 쿼리를 실행할 수 있지만, 이 Quickstart에서는 VS Code용 Snowflake 확장 프로그램을 사용하겠습니다. Snowflake의 VS Code용 네이티브 확장 프로그램에 대한 간략한 개요는 VS Code 마켓플레이스 Snowflake 확장 프로그램 페이지에서 확인하십시오.
스크립트 실행
이 Quickstart를 위해 Snowflake에서 필요할 모든 객체를 설정하려면 steps/01_setup_snowflake.sql 스크립트를 실행해야 합니다.
VS Code의 왼쪽 탐색 메뉴에서 Snowflake 확장 프로그램을 클릭하여 시작합니다. 그런 다음 ACCOUNTADMIN 권한을 가진 사용자로 Snowflake 계정에 로그인합니다. Snowflake에 로그인한 후 왼쪽 탐색 메뉴에 있는 파일 탐색기로 되돌아가 VS Code에서 steps/01_setup_snowflake.sql 스크립트를 엽니다.
모든 쿼리를 이 스크립트에서 실행하려면 편집기 창의 오른쪽 상단 모서리에 있는 ‘Execute All Statements' 버튼을 사용합니다. 묶어서 실행하고 싶다면 실행할 쿼리를 선택하고 CMD/CTRL+Enter 바로 가기 키를 누릅니다.
이 단계에서는 가공 전 Tasty Bytes POS 및 고객 충성도 데이터를 s3://sfquickstarts/data-engineering-with-snowpark-python/에 있는 가공 전 Parquet 파일에서 Snowflake의 RAW_POS 및 RAW_CUSTOMER 스키마로 로드하겠습니다. 또한, Snowpark Python API를 사용하여 노트북에서 Python으로 이 프로세스를 조정하게 됩니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 2단계로 이동합니다.
스크립트 실행
가공 전 데이터를 로드하려면 steps/02_load_raw.py 스크립트를 실행합니다. VS Code에서는 다양한 방식(터미널에서 또는 VS Code에서 바로 실행)으로 이를 실행할 수 있습니다. 이 데모에서는 Python 스크립트를 터미널에서 실행해야 합니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps
python 02_load_raw.py
명령이 실행되는 동안 VS Code에서 스크립트를 열고 현황을 파악하기 위해 이 페이지를 계속 진행합니다.
로컬에서 Snowpark Python 실행
이 단계에서는 노트북으로 로컬에서 Snowpark Python 코드를 실행하겠습니다. 스크립트 하단에는 로컬 디버깅에 사용되는 코드 블록(if __name__ == "__main__": 블록 아래)이 있습니다.
# For local debugging
if __name__ == "__main__":
# Add the utils package to our path and import the snowpark_utils function
import os, sys
current_dir = os.getcwd()
parent_dir = os.path.dirname(current_dir)
sys.path.append(parent_dir)
from utils import snowpark_utils
session = snowpark_utils.get_snowpark_session()
load_all_raw_tables(session)
# validate_raw_tables(session)
session.close()
여기에서 몇 가지 중요한 점을 말씀드리겠습니다. 우선, Snowpark session은 utils/snowpark_utils.py 모듈에 생성됩니다. 자격 증명을 가져오는 방식은 다양하지만, 이 Quickstart에서는 ~/.snowsql/config에 있는 SnowSQL 구성 파일에서 자격 증명을 가져옵니다. 상세 정보는 utils/snowpark_utils.py 모듈의 코드에서 확인하십시오.
Snowpark session을 가져오고 나면, 이는 힘든 작업을 수행하는 load_all_raw_tables(session) 메소드를 호출합니다. 다음 몇 개의 섹션은 핵심 내용을 강조합니다.
마지막으로, 이 Quickstart의 거의 모든 Python 스크립트에는 로컬 디버깅 블록이 포함되어 있습니다. 추후에 Snowpark Python 저장 프로시저 및 UDF를 생성할 것이며 이러한 Python 스크립트는 비슷한 블록을 보유하게 됩니다. 따라서 이 패턴을 이해하는 것이 중요합니다.
Snowflake에서 결과 확인
Snowflake의 쿼리 내역은 매우 강력한 기능입니다. 쿼리를 시작한 도구나 프로세스와 관계없이 Snowflake 계정에 대해 실행되는 모든 쿼리를 기록합니다. 또한, 이 기능은 클라이언트 도구 및 API로 작업할 때 특히나 유용합니다.
방금 실행한 Python 스크립트는 로컬에서 적은 양의 작업을 수행했습니다. 기본적으로 각 테이블을 거치고 데이터를 로드하기 위해 명령을 Snowflake에 내려 프로세스를 조정했습니다. 하지만 모든 힘든 작업은 Snowflake 내부에서 실행되었습니다! 이 푸시다운은 Snowpark API의 특징이며 사용자가 Snowflake의 확장성과 컴퓨팅 파워를 활용할 수 있도록 합니다.
Snowflake 계정에 로그인하여 Snowpark API가 생성한 SQL을 잠깐 확인합니다. 이렇게 확인하면 API 현황을 더 잘 이해하고 발생할 수 있는 모든 이슈를 디버그하는 데 도움이 됩니다.
스키마 추론
Snowflake의 매우 유용한 기능으로는 작업할 스테이지에서 파일 스키마를 추론하는 것이 있습니다. 이는 INFER_SCHEMA() 함수를 사용하여 SQL에서 완수됩니다. Snowpark Python API는 사용자가 session.read() 메소드를 호출하면 사용자를 대신해 자동으로 이 작업을 수행합니다. 코드 조각은 다음과 같습니다.
# we can infer schema using the parquet read option
df = session.read.option("compression", "snappy") \
.parquet(location)
COPY를 사용한 데이터 수집
데이터를 Snowflake 테이블에 로드하기 위해 DataFrame에서 copy_into_table() 메소드를 사용하겠습니다. 이 메소드는 추론된 스키마(존재하지 않을 경우)를 사용하여 Snowflake에서 대상 테이블을 생성합니다. 그런 다음 고도로 최적화된 Snowflake COPY INTO <table>명령을 호출합니다. 코드 조각은 다음과 같습니다.
df.copy_into_table("{}".format(tname))
Snowflake의 테이블 형식
Snowflake의 주요 이점 중 하나는 파일 기반 데이터 레이크를 관리할 필요가 없다는 것입니다. 또한, Snowflake는 처음부터 이러한 목적을 염두에 두고 설계되었습니다. 이 단계에서는 가공 전 데이터를 정형 Snowflake 관리형 테이블에 로드하겠습니다. 하지만 Snowflake 테이블은 기본적으로 정형 및 반정형 데이터를 지원할 수 있습니다. 또한, Snowflake의 성숙한 클라우드 테이블 형식(Hudi, Delta 또는 Iceberg 이전)에 저장됩니다.
데이터는 Snowflake에 로드되면 안전하게 저장 및 관리됩니다. 가공 전 파일의 보호 및 관리를 걱정할 필요가 없습니다. 또한, 가공 전 데이터든 정형 데이터든 이러한 데이터는 SQL 또는 원하는 언어를 사용하여 Snowflake에서 변환 및 쿼리할 수 있습니다. Spark와 같은 별도의 컴퓨팅 서비스를 관리할 필요가 없습니다.
이는 Snowflake 고객이 누리는 엄청난 이점입니다.
웨어하우스 탄력성(동적 규모 조정)
Snowflake에는 가상 웨어하우스라는 단 하나의 사용자 정의 컴퓨팅 클러스터 유형이 있습니다. 사용하는 언어(SQL, Python, Java, Scala, Javascript 등)와 관계없이 이는 해당 데이터를 처리합니다. 즉, Snowflake에서 데이터로 작업하는 것이 훨씬 더 간단해집니다. 또한, 데이터 거버넌스는 컴퓨팅 클러스터와 완전히 분리되어 있습니다. 따라서 웨어하우스 설정 또는 사용하는 언어와 관계없이 Snowflake 거버넌스를 우회할 방법이 없습니다.
이러한 가상 웨어하우스의 크기는 동적으로 조정되며 1초 이내에 다양한 크기의 웨어하우스를 대부분 조정할 수 있습니다! 즉, 코드에서 동적으로 컴퓨팅 환경의 크기를 조정하여 짧은 시간 내에 코드 섹션을 실행할 용량을 늘릴 수 있습니다. 그런 다음 동적으로 크기를 다시 조정하여 용량을 줄일 수 있습니다. Snowflake는 요금을 초 단위로 청구하기에(최소 60초) 짧은 시간 내에 해당 코드 섹션을 실행하는 데 추가 요금을 지불하지 않아도 됩니다.
이 작업이 얼마나 쉬운지 알아보겠습니다. 코드 조각은 다음과 같습니다.
_ = session.sql("ALTER WAREHOUSE HOL_WH SET WAREHOUSE_SIZE = XLARGE WAIT_FOR_COMPLETION = TRUE").collect()
# Some data processing code
_ = session.sql("ALTER WAREHOUSE HOL_WH SET WAREHOUSE_SIZE = XSMALL").collect()
첫 번째 ALTER WAREHOUSE 문에 WAIT_FOR_COMPLETION 매개변수가 포함되어 있다는 점도 참고하십시오. 이 매개변수를 TRUE로 설정하면 크기 조정이 모든 컴퓨팅 리소스의 프로비저닝을 완료할 때까지 ALTER WAREHOUSE 명령의 반환을 차단하게 됩니다. 이렇게 하면 이를 사용하여 그 어떠한 데이터도 처리하기 전에 전체 클러스터를 확보할 수 있습니다.
이 Quickstart를 진행하는 동안 이 패턴을 몇 번 더 사용하겠습니다. 따라서 이 내용을 이해하는 것이 중요합니다.
이 단계에서는 가공 전 날씨 데이터를 Snowflake로 ‘로드'하겠습니다. 하지만 ‘로드'는 이 작업을 올바르게 설명하는 단어는 아닙니다. 왜냐하면 우리가 Snowflake의 고유한 데이터 공유 기능을 사용하기 때문입니다. 우리는 실질적으로 사용자 정의 ETL 프로세스를 사용하여 Snowflake 계정에 데이터를 복사할 필요가 없습니다. 대신 Snowflake 데이터 마켓플레이스에서 Weather Source가 공유하는 날씨 데이터에 바로 액세스할 수 있습니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 3단계로 이동합니다.
Snowflake 데이터 마켓플레이스
Weather Source는 선도적인 전 세계 날씨 및 기후 데이터 공급자입니다. 이 회사의 OnPoint Product Suite는 비즈니스가 여러 산업에 걸쳐 다양한 사용 사례에 대한 의미 있고 실행 가능한 인사이트를 빠르게 생성하는 데 필요한 날씨 및 기후 데이터를 제공합니다. 다음 단계에 따라 Snowflake 데이터 마켓플레이스에 등록된 Weather Source가 제공하는 Weather Source LLC: frostbyte 피드와 연결하겠습니다.
- Snowsight에 로그인합니다.
- 왼쪽 탐색 메뉴에 있는
Marketplace링크를 클릭합니다. - 검색 상자에 ‘Weather Source LLC: frostbyte'를 입력하고 Return을 클릭합니다.
- ‘Weather Source LLC: frostbyte' 목록 타일을 클릭합니다.
- 파란색 ‘Get' 버튼을 클릭합니다.
- ‘Options' 대화를 확장합니다.
- ‘Database name'을 ‘FROSTBYTE_WEATHERSOURCE'(전부 대문자)로 바꿉니다.
- 새로운 데이터베이스에 대한 액세스를 보유하기 위해 ‘HOL_ROLE' 역할을 선택합니다.
- 파란색 ‘Get' 버튼을 클릭합니다.
끝났습니다. 이제 이 데이터를 업데이트하기 위해 그 어떠한 작업도 수행할 필요가 없습니다. 공급자가 대신 데이터를 업데이트하며 데이터가 공유되고 있기에 공급자가 게시하는 모든 것을 사용자가 항상 확인하게 됩니다. 놀라운 일입니다. 항상 최신 상태인 서드 파티 데이터 세트에 대한 액세스를 얻는 것이 얼마나 간단했는지 생각해 보십시오!
스크립트 실행
왼쪽 탐색 메뉴에 있는 파일 탐색기의 VS Code에서 steps/03_load_weather.sql 스크립트를 열고 해당 스크립트를 실행합니다. Snowflake 마켓플레이스를 통해 공유된 데이터를 쿼리하는 것이 이렇게 간단합니다! Snowflake에 있는 다른 테이블이나 뷰에 액세스하는 것처럼 액세스합니다.
SELECT * FROM FROSTBYTE_WEATHERSOURCE.ONPOINT_ID.POSTAL_CODES LIMIT 100;
이 단계에서는 6개의 각기 다른 테이블을 결합하고 필요한 열만 골라 뷰를 생성하여 가공 전 POS 스키마를 간소화하겠습니다. 정말 멋진 부분은 Snowpark DataFrame API로 해당 뷰를 정의하게 된다는 것입니다! 그런 다음 증분적으로 모든 POS 테이블에 대한 변경 사항을 처리할 수 있도록 해당 뷰에서 Snowflake 스트림을 생성하겠습니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 4단계로 이동합니다.
스크립트 실행
뷰와 스트림을 생성하려면 steps/04_create_pos_view.py 스크립트를 실행합니다. 2단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps
python 04_create_pos_view.py
명령이 실행되는 동안 VS Code에서 스크립트를 열고 현황을 파악하기 위해 이 페이지를 계속 진행합니다.
Snowpark DataFrame API
우선, create_pos_view() 함수에서 확인해야 하는 부분은 Snowpark DataFrame API를 사용하여 Snowflake 뷰를 정의하는 점입니다. 뷰에 있기를 원하는 모든 로직을 캡처하는 최종 DataFrame을 정의한 후 Snowpark create_or_replace_view() 메소드를 호출하기만 하면 됩니다. create_pos_view() 함수의 마지막 줄은 다음과 같습니다.
final_df.create_or_replace_view('POS_FLATTENED_V')
Snowpark Python DataFrame API에 대한 상세 정보는 Snowpark Python에서 DataFrame으로 작업하기 페이지에서 확인하십시오.
증분적 처리를 위한 스트림(CDC)
Snowflake는 증분적인 데이터 처리를 매우 쉽게 만듭니다. 전통적으로 데이터 엔지니어는 테이블에서 새로운 기록만을 처리하기 위해 상위 워터마크(일반적으로 날짜/시간 열)를 기록해야 했습니다. 이 작업을 위해 어딘가에서 해당 워터마크를 추적 및 지속한 다음 이를 소스 테이블에 대한 모든 쿼리에서 사용해야 했습니다. 하지만 Snowflake 스트림을 사용하면 모든 힘든 작업을 Snowflake가 대신 수행합니다. 상세 정보는 테이블 스트림을 사용한 변경 내용 추적 사용자 가이드에서 확인하십시오.
기본 테이블 또는 뷰에 대해 Snowflake에서 STREAM 객체를 생성하고 해당 스트림을 Snowflake에 있는 다른 테이블과 마찬가지로 쿼리하기만 하면 됩니다. 이 스트림은 수행한 마지막 DML 옵션 이후 변경된 기록만 반환합니다. 변경된 기록으로 작업하는 것을 돕기 위해 Snowflake 스트림은 다음 메타데이터 열과 기본 테이블 또는 뷰 열을 제공합니다.
- METADATA$ACTION
- METADATA$ISUPDATE
- METADATA$ROW_ID
이러한 스트림 메타데이터 열에 대한 상세 정보는 Snowflake 설명서의 스트림 열 섹션에서 확인하십시오.
뷰의 스트림
Snowflake의 증분적 및 CDC 스트림 기능에서 정말 멋진 부분은 뷰에서 스트림을 생성할 수 있다는 점입니다! 이 사례에서는 6개의 가공 전 POS 테이블을 결합한 뷰에서 스트림을 생성하겠습니다. 이 작업을 위한 코드는 다음과 같습니다.
def create_pos_view_stream(session):
session.use_schema('HARMONIZED')
_ = session.sql('CREATE OR REPLACE STREAM POS_FLATTENED_V_STREAM \
ON VIEW POS_FLATTENED_V \
SHOW_INITIAL_ROWS = TRUE').collect()
변경된 기록을 찾기 위해 POS_FLATTENED_V_STREAM 스트림을 쿼리할 때 Snowflake는 실질적으로 뷰에 포함된 6개의 테이블 중 아무 테이블에서 변경된 기록을 찾습니다. 이와 같은 비정규화된 스키마에 대한 증분적 및 CDC 프로세스를 구축하려고 시도한 경험이 있는 분이라면, 여기에서 Snowflake가 제공하는 매우 강력한 기능의 진가를 알아볼 것입니다.
상세 정보는 Snowflake 설명서의 뷰의 스트림 섹션에서 확인하십시오.
이 단계에서는 첫 번째 Snowpark Python 객체를 생성하고 이를 사용자 정의 함수(또는 UDF)인 Snowflake에 배포하겠습니다. 처음에는 UDF가 매우 단순하지만, 추후 단계에서는 서드 파티 Python 패키지를 포함하도록 업데이트할 것입니다. 또한, 이 단계에서는 새로운 개발자 명령줄 도구인 새로운 SnowCLI를 소개하겠습니다. SnowCLI는 개발자가 Snowpark Python 객체를 구축하고 이를 Snowflake로 배포하는 경험을 일관되게 만듭니다. SnowCLI에 대한 상세 정보는 다음과 같습니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 5단계로 이동합니다.
로컬에서 UDF 실행
로컬에서 UDF를 테스트하려면 steps/05_fahrenheit_to_celsius_udf/app.py 스크립트를 실행합니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/05_fahrenheit_to_celsius_udf
python app.py 35
UDF를 개발하는 동안 간단히 로컬에서 VS Code로 이를 실행할 수 있습니다. 또한, UDF가 Snowflake의 데이터를 쿼리할 필요가 없다면 이 프로세스는 전부 로컬에서 진행됩니다.
UDF를 Snowflake에 배포
UDF를 Snowflake에 배포하기 위해 SnowCLI 도구를 사용하겠습니다. SnowCLI 도구는 애플리케이션을 패키지로 만들고, 이를 Snowflake 스테이지에 복사하고, Snowflake에서 객체를 생성하는 모든 힘든 작업을 수행합니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/05_fahrenheit_to_celsius_udf
snow function create
명령이 실행되는 동안 VS Code에서 스크립트를 열고 현황을 파악하기 위해 이 페이지를 계속 진행합니다.
Snowflake에서 UDF 실행
Snowflake에서 UDF를 실행하는 방법에는 여러 가지가 있습니다. Snowflake에서 모든 UDF는 다음과 같이 SQL을 통해 호출할 수 있습니다.
SELECT ANALYTICS.FAHRENHEIT_TO_CELSIUS_UDF(35);
또한, SnowCLI 유틸리티를 사용하면 다음과 같이 VS Code의 터미널에서 UDF를 호출할 수 있습니다.
snow function execute -f "fahrenheit_to_celsius_udf(35)"
결과적으로 SnowCLI 도구는 위 SQL 쿼리를 생성하고 이를 Snowflake 계정에 대해 실행합니다.
SnowCLI 도구 개요
SnowCLI 도구는 개발자를 위한 명령줄 도구이며 명령줄에서 snow로 실행됩니다.
SnowCLI는 다음 Snowflake 객체의 개발 및 배포를 간소화합니다.
- Snowpark Python UDF
- Snowpark Python 저장 프로시저
- Streamlit 애플리케이션
이 Quickstart에서는 처음 두 개의 객체를 집중적으로 다루겠습니다. SnowCLI는 특히나 Snowpark Python UDF와 저장 프로시저를 위해 객체를 Snowflake에 배포하는 모든 힘든 작업을 수행합니다. SnowCLI 배포 명령이 대신 수행하는 단계를 간략히 요약하면 다음과 같습니다.
- 서드 파티 패키지 처리
- Anaconda 채널에서 바로 액세스할 수 있는 패키지의 경우, SnowCLI는
CREATE PROCEDURE또는CREATE FUNCTIONSQL 명령의PACKAGES목록에 이를 추가합니다. - 현재 Anaconda 채널에서 제공되지 않는 패키지의 경우, SnowCLI는 코드를 다운로드하고 이를 프로젝트 압축 파일에 포함시킵니다.
- Anaconda 채널에서 바로 액세스할 수 있는 패키지의 경우, SnowCLI는
- 프로젝트에 있는 모든 것의 압축 파일 생성
- Snowflake 스테이지에 해당 프로젝트 압축 파일 복사
- Snowflake 함수 또는 저장 프로시저 객체 생성
이렇게 하면 Python 애플리케이션을 해당하는 Snowflake 데이터베이스 객체로 만드는 것을 걱정하지 않고 개발 및 테스트할 수 있습니다.
Snowpark Python UDF에 대한 추가 정보
이 단계에서는 아주 단순한 Python UDF를 Snowflake에 배포했습니다. 추후 단계는 서드 파티 패키지를 사용하도록 업데이트됩니다. 또한, SnowCLI 명령으로 이를 Snowflake에 배포했기 때문에 Snowflake에서 객체를 생성하기 위한 SQL DDL 구문을 걱정할 필요가 없었습니다. 단, 참고를 위해 Python UDF 작성하기 개발자 가이드를 확인해 주시기 바랍니다.
SnowCLI 도구가 함수를 배포하기 위해 생성한 SQL 쿼리는 다음과 같습니다.
CREATE OR REPLACE FUNCTION fahrenheit_to_celsius_udf(temp_f float)
RETURNS float
LANGUAGE PYTHON
RUNTIME_VERSION=3.8
IMPORTS=('@HOL_DB.ANALYTICS.deployments/fahrenheit_to_celsius_udftemp_f_float/app.zip')
HANDLER='app.main'
PACKAGES=();
이 단계에서는 첫 번째 Snowpark Python 저장 프로시저를 생성하고 이를 Snowflake에 배포하겠습니다. 이 저장 프로시저는 HARMONIZED.POS_FLATTENED_V_STREAM 스트림의 변경 사항을 대상 HARMONIZED.ORDERS 테이블과 병합합니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 6단계로 이동합니다.
로컬에서 저장 프로시저 실행
로컬에서 프로시저를 테스트하려면 steps/06_orders_update_sp/app.py 스크립트를 실행합니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/06_orders_update_sp
python app.py
저장 프로시저를 개발하는 동안 간단히 로컬에서 VS Code로 이를 실행할 수 있습니다. Python 코드는 노트북으로 로컬에서 실행되지만, Snowpark DataFrame 코드는 Snowflake 계정에 SQL 쿼리를 발급하게 됩니다.
저장 프로시저를 Snowflake에 배포
저장 프로시저를 Snowflake에 배포하기 위해 SnowCLI 도구를 사용하겠습니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/06_orders_update_sp
snow procedure create
명령이 실행되는 동안 VS Code에서 스크립트를 열고 현황을 파악하기 위해 이 페이지를 계속 진행합니다.
Snowflake에서 저장 프로시저 실행
Snowflake에서 저장 프로시저를 실행하는 방법에는 여러 가지가 있습니다. Snowflake에서 모든 저장 프로시저는 다음과 같이 SQL을 통해 호출할 수 있습니다.
CALL ORDERS_UPDATE_SP();
또한, SnowCLI 유틸리티를 사용하면 다음과 같이 VS Code의 터미널에서 UDF를 호출할 수 있습니다.
snow procedure execute -p "orders_update_sp()"
결과적으로 SnowCLI 도구는 위 SQL 쿼리를 생성하고 이를 Snowflake 계정에 대해 실행합니다.
Snowpark Python 저장 프로시저에 대한 추가 정보
이 단계에서는 Python 저장 프로시저를 Snowflake에 배포했습니다. 또한, SnowCLI 명령으로 이를 Snowflake에 배포했기 때문에 Snowflake에서 객체를 생성하기 위한 SQL DDL 구문을 걱정할 필요가 없었습니다. 단, 참고를 위해 Snowpark(Python)로 저장 프로시저 작성하기 가이드를 확인해 주시기 바랍니다.
SnowCLI 도구가 프로시저를 배포하기 위해 생성한 SQL 쿼리는 다음과 같습니다.
CREATE OR REPLACE PROCEDURE orders_update_sp()
RETURNS string
LANGUAGE PYTHON
RUNTIME_VERSION=3.8
IMPORTS=('@HOL_DB.HARMONIZED.deployments/orders_update_sp/app.zip')
HANDLER='app.main'
PACKAGES=('snowflake-snowpark-python','toml')
EXECUTE AS CALLER;
Snowpark API에 대한 추가 정보
이 단계에서는 데이터 변환을 위해 실질적으로 Snowpark DataFrame API를 사용하기 시작합니다. Snowpark API는 Spark SQL API로 동일한 기능을 제공합니다. 시작하려면 Snowpark session 객체를 생성해야 합니다. PySpark와 비슷하게 이는 Session.builder.configs().create() 메소드로 완수됩니다. 로컬에서 실행할 때는 utils.snowpark_utils.get_snowpark_session() 도우미 함수를 사용하여 대신 session 객체를 생성합니다. 하지만 Snowflake에 배포할 때는 Snowflake가 자동으로 대신 session 객체를 프로비저닝합니다. 또한, 계약에 따르면 Snowpark Python 저장 프로시저를 구축할 때 진입점(또는 핸들러) 함수에 대한 첫 번째 인수는 Snowpark session입니다.
steps/06_orders_update_sp/app.py 스크립트에서 관찰할 수 있는 첫 번째 부분은 Snowflake에서 객체를 생성하고 객체 상태를 확인하기 위해 SQL을 사용하는 몇몇 함수가 있다는 것입니다. Snowpark API로 Snowflake에 SQL 문을 발급하려면 예상할 수 있듯이 session.sql() 함수를 사용합니다. 하나의 사례는 다음과 같습니다.
def create_orders_stream(session):
_ = session.sql("CREATE STREAM IF NOT EXISTS HARMONIZED.ORDERS_STREAM ON TABLE HARMONIZED.ORDERS \
SHOW_INITIAL_ROWS = TRUE;").collect()
강조할 두 번째 부분은 소스 뷰에서 대상 테이블로 변경 사항을 병합하기 위해 DataFrame을 사용하는 방법입니다. Snowpark DataFrame API는 merge() 메소드를 제공합니다. 이는 결과적으로 Snowflake에서 MERGE 명령을 생성합니다.
source = session.table('HARMONIZED.POS_FLATTENED_V_STREAM')
target = session.table('HARMONIZED.ORDERS')
# TODO: Is the if clause supposed to be based on "META_UPDATED_AT"?
cols_to_update = {c: source[c] for c in source.schema.names if "METADATA" not in c}
metadata_col_to_update = {"META_UPDATED_AT": F.current_timestamp()}
updates = {**cols_to_update, **metadata_col_to_update}
# merge into DIM_CUSTOMER
target.merge(source, target['ORDER_DETAIL_ID'] == source['ORDER_DETAIL_ID'], \
[F.when_matched().update(updates), F.when_not_matched().insert(updates)])
다시 한번, Snowpark Python DataFrame API에 대한 상세 정보는 Snowpark Python에서 DataFrame으로 작업하기 페이지에서 확인하십시오.
이 단계에서는 두 번째 Snowpark Python 저장 프로시저를 생성하고 이를 Snowflake에 배포하겠습니다. 이 저장 프로시저는 ANALYTICS.DAILY_CITY_METRICS라는 분석을 위해 집계된 최종 테이블을 생성하기 위해 HARMONIZED.ORDERS 데이터와 Weather Source 데이터를 결합합니다. 다른 Snowflake 스트림을 사용하여 해당 데이터를 HARMONIZED.ORDERS 테이블에서 증분적으로 처리하겠습니다. 또한, 다시 한번 Snowpark DataFrame merge() 메소드를 사용하여 데이터를 병합 또는 업서트하겠습니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 7단계로 이동합니다.
로컬에서 저장 프로시저 실행
로컬에서 프로시저를 테스트하려면 steps/07_daily_city_metrics_update_sp/app.py 스크립트를 실행합니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/07_daily_city_metrics_update_sp
python app.py
저장 프로시저를 개발하는 동안 간단히 로컬에서 VS Code로 이를 실행할 수 있습니다. Python 코드는 노트북으로 로컬에서 실행되지만, Snowpark DataFrame 코드는 Snowflake 계정에 SQL 쿼리를 발급하게 됩니다.
저장 프로시저를 Snowflake에 배포
저장 프로시저를 Snowflake에 배포하기 위해 SnowCLI 도구를 사용하겠습니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/07_daily_city_metrics_update_sp
snow procedure create
명령이 실행되는 동안 VS Code에서 스크립트를 열고 현황을 파악하기 위해 이 페이지를 계속 진행합니다.
Snowflake에서 저장 프로시저 실행
Snowflake에서 저장 프로시저를 실행하는 방법에는 여러 가지가 있습니다. Snowflake에서 모든 저장 프로시저는 다음과 같이 SQL을 통해 호출할 수 있습니다.
CALL DAILY_CITY_METRICS_UPDATE_SP();
또한, SnowCLI 유틸리티를 사용하면 다음과 같이 VS Code의 터미널에서 UDF를 호출할 수 있습니다.
snow procedure execute -p "daily_city_metrics_update_sp()"
결과적으로 SnowCLI 도구는 위 SQL 쿼리를 생성하고 이를 Snowflake 계정에 대해 실행합니다.
데이터 모델링 모범 사례
분석을 위해 데이터를 모델링할 때의 모범 사례는 테이블의 스키마를 명확히 정의하고 관리하는 것이었습니다. 가공 전 데이터를 Parquet에서 로드한 2단계에서는 Snowflake의 스키마 감지 기능의 이점을 활용하여 Parquet 파일과 동일한 스키마로 테이블을 생성했습니다. 이 단계에서는 DataFrame 구문에서 스키마를 확실하게 정의하고 이를 사용하여 테이블을 생성합니다.
def create_daily_city_metrics_table(session):
SHARED_COLUMNS= [T.StructField("DATE", T.DateType()),
T.StructField("CITY_NAME", T.StringType()),
T.StructField("COUNTRY_DESC", T.StringType()),
T.StructField("DAILY_SALES", T.StringType()),
T.StructField("AVG_TEMPERATURE_FAHRENHEIT", T.DecimalType()),
T.StructField("AVG_TEMPERATURE_CELSIUS", T.DecimalType()),
T.StructField("AVG_PRECIPITATION_INCHES", T.DecimalType()),
T.StructField("AVG_PRECIPITATION_MILLIMETERS", T.DecimalType()),
T.StructField("MAX_WIND_SPEED_100M_MPH", T.DecimalType()),
]
DAILY_CITY_METRICS_COLUMNS = [*SHARED_COLUMNS, T.StructField("META_UPDATED_AT", T.TimestampType())]
DAILY_CITY_METRICS_SCHEMA = T.StructType(DAILY_CITY_METRICS_COLUMNS)
dcm = session.create_dataframe([[None]*len(DAILY_CITY_METRICS_SCHEMA.names)], schema=DAILY_CITY_METRICS_SCHEMA) \
.na.drop() \
.write.mode('overwrite').save_as_table('ANALYTICS.DAILY_CITY_METRICS')
dcm = session.table('ANALYTICS.DAILY_CITY_METRICS')
복잡한 집계 쿼리
merge_daily_city_metrics() 함수에는 복잡한 집계 쿼리가 포함되어 있습니다. 이는 POS 및 Weather Source 데이터를 결합 및 집계하기 위해 사용됩니다. 표현된 복잡한 일련의 조인 및 집계를 살펴보고 5단계에서 생성한 Snowpark UDF도 활용하는 모습을 확인해 보십시오!
그런 다음 복잡한 집계 쿼리는 Snowpark merge() 메소드를 사용하여 최종 분석 테이블과 병합됩니다. 아직 확인하지 않았다면 Snowflake 쿼리 내역을 확인하여 Snowpark API가 어떤 쿼리를 생성했는지 알아보십시오. 이 경우, Snowpark API는 병합을 비롯한 모든 복잡한 로직을 사용하고 실행할 단일 Snowflake 쿼리를 생성했을 것입니다!
이 단계에서는 새로운 Snowpark 파이프라인과 Snowflake의 기본 오케스트레이션 기능인 작업을 조정하겠습니다. 각 저장 프로시저를 위한 2개의 작업을 생성하고 이를 연결하겠습니다. 그런 다음 작업을 실행하겠습니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 8단계로 이동합니다.
스크립트 실행
이는 SQL 스크립트이므로 이를 실행하기 위해 네이티브 VS Code 확장 프로그램을 사용하겠습니다. 간단히 VS Code에서 steps/08_orchestrate_jobs.sql 스크립트를 열고 편집기 창의 오른쪽 상단 모서리에 있는 ‘Execute All Statements' 버튼을 사용하여 모든 것을 실행합니다.
실행되는 동안 VS Code에서 스크립트를 읽고 현황을 파악하기 위해 이 페이지를 계속 진행합니다.
작업 실행
이 단계에서는 작업 DAG를 위한 일정을 생성하지 않았습니다. 따라서 이 지점에서는 스스로 실행되지 않습니다. 이 스크립트는 다음과 같이 DAG를 수동으로 실행하게 됩니다.
EXECUTE TASK ORDERS_UPDATE_TASK;
이 작업을 방금 실행했을 때의 결과를 확인하려면 스크립트에서 이 주석이 달린 쿼리를 선택 및 실행(CMD/CTRL+Enter 바로 가기 키 사용)합니다.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
SCHEDULED_TIME_RANGE_START=>DATEADD('DAY',-1,CURRENT_TIMESTAMP()),
RESULT_LIMIT => 100))
ORDER BY SCHEDULED_TIME DESC
;
작업 기록 출력에서 ORDERS_UPDATE_TASK 작업을 건너뛰었다는 것을 알 수 있습니다. HARMONIZED.POS_FLATTENED_V_STREAM 스트림에는 데이터가 없기에 이는 올바른 내용입니다. 몇 가지 새로운 데이터를 추가하고 다음 단계에서 다시 실행하겠습니다.
작업에 대한 추가 정보
작업은 Snowflake의 기본 일정 관리 또는 오케스트레이션 기능입니다. 작업으로 다음 SQL 코드 유형 중 하나를 실행할 수 있습니다.
- 단일 SQL 문
- 저장 프로시저 호출
- Snowflake Scripting 개발자 가이드를 사용한 프로시저 로직
이 Quickstart에서는 Snowpark 저장 프로시저를 호출하겠습니다 두 번째 작업을 생성하기 위한 SQL DDL 코드는 다음과 같습니다.
CREATE OR REPLACE TASK DAILY_CITY_METRICS_UPDATE_TASK
WAREHOUSE = HOL_WH
AFTER ORDERS_UPDATE_TASK
WHEN
SYSTEM$STREAM_HAS_DATA('ORDERS_STREAM')
AS
CALL ANALYTICS.DAILY_CITY_METRICS_UPDATE_SP();
몇 가지 중요한 점을 말씀드리겠습니다. 우선, WAREHOUSE 절로 작업을 실행할 때 사용할 Snowflake 가상 웨어하우스를 지정합니다. AFTER 절을 통해 여러 작업 간의 관계를 정의할 수 있습니다. 또한, 이 관계의 구조는 오케스트레이션 도구 대부분이 제공하는 것처럼 방향성 비순환 그래프(또는 DAG)입니다. AS 절을 통해 작업이 실행되면 수행하는 작업을 정의할 수 있습니다. 이 경우, 저장 프로시저를 호출하는 것입니다.
WHEN 절은 정말 훌륭합니다. 데이터를 증분적으로 처리하도록 하여 Snowflake에서 스트림이 작동하는 모습을 이미 확인했습니다. 뷰(여러 테이블을 결합함)에서 스트림을 생성하고 데이터를 증분적으로 처리하기 위해 해당 뷰에서 스트림을 생성하는 방법도 확인했습니다! WHEN 절에서는 지정된 스트림에 새로운 데이터가 있으면 참을 반환하는 SYSTEM$STREAM_HAS_DATA() 시스템 함수를 호출하고 있습니다. WHEN 절을 사용하면 가상 웨어하우스는 스트림에 새로운 데이터가 있을 때만 시작됩니다. 따라서 작업이 실행될 때 새로운 데이터가 없다면 웨어하우스가 시작되지 않고 요금이 부과되지 않습니다. 처리할 새로운 데이터가 있을 때만 요금이 부과됩니다. 훌륭한 기능입니다.
앞서 말씀드렸듯이 루트 작업의 SCHEDULE을 정의하지 않았기에 이 DAG는 스스로 실행되지 않습니다. 이 Quickstart에서는 괜찮지만 현실에서는 일정을 정의해야 합니다. 상세 정보는 CREATE TASK에서 확인하십시오.
또한, 작업에 대한 상세 정보는 작업 소개에서 확인하십시오.
작업 메타데이터
Snowflake는 사용자가 수행하는 거의 모든 작업의 메타데이터를 보관하고 쿼리(및 이에 대한 모든 프로세스 유형을 생성)할 수 있도록 이러한 메타데이터를 제공합니다. 작업이라고 다르지 않습니다. Snowflake는 방대한 양의 메타데이터를 유지하여 작업 실행의 모니터링을 돕습니다. 다음은 작업 실행을 모니터링하기 위해 사용할 수 있는 몇 가지 샘플 SQL 쿼리입니다.
-- Get a list of tasks
SHOW TASKS;
-- Task execution history in the past day
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
SCHEDULED_TIME_RANGE_START=>DATEADD('DAY',-1,CURRENT_TIMESTAMP()),
RESULT_LIMIT => 100))
ORDER BY SCHEDULED_TIME DESC
;
-- Scheduled task runs
SELECT
TIMESTAMPDIFF(SECOND, CURRENT_TIMESTAMP, SCHEDULED_TIME) NEXT_RUN,
SCHEDULED_TIME,
NAME,
STATE
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY())
WHERE STATE = 'SCHEDULED'
ORDER BY COMPLETED_TIME DESC;
작업 모니터링
원하는 운영 또는 모니터링 프로세스를 자유롭게 생성할 수 있지만, Snowflake는 Snowsight UI에서 다양한 작업 관측 가능성 기능을 제공합니다. 다음 단계에 따라 직접 사용해 보십시오.
- Snowsight 탐색 메뉴에서 Data » Databases를 클릭합니다.
- 오른쪽 창에서 객체 탐색기를 사용하여 데이터베이스와 스키마로 이동합니다.
- 선택한 스키마에 대해 Tasks를 선택하고 확장합니다.
- 작업을 선택합니다. Task Details, Graph 및 Run History 하위 탭을 비롯한 작업 정보가 표시됩니다.
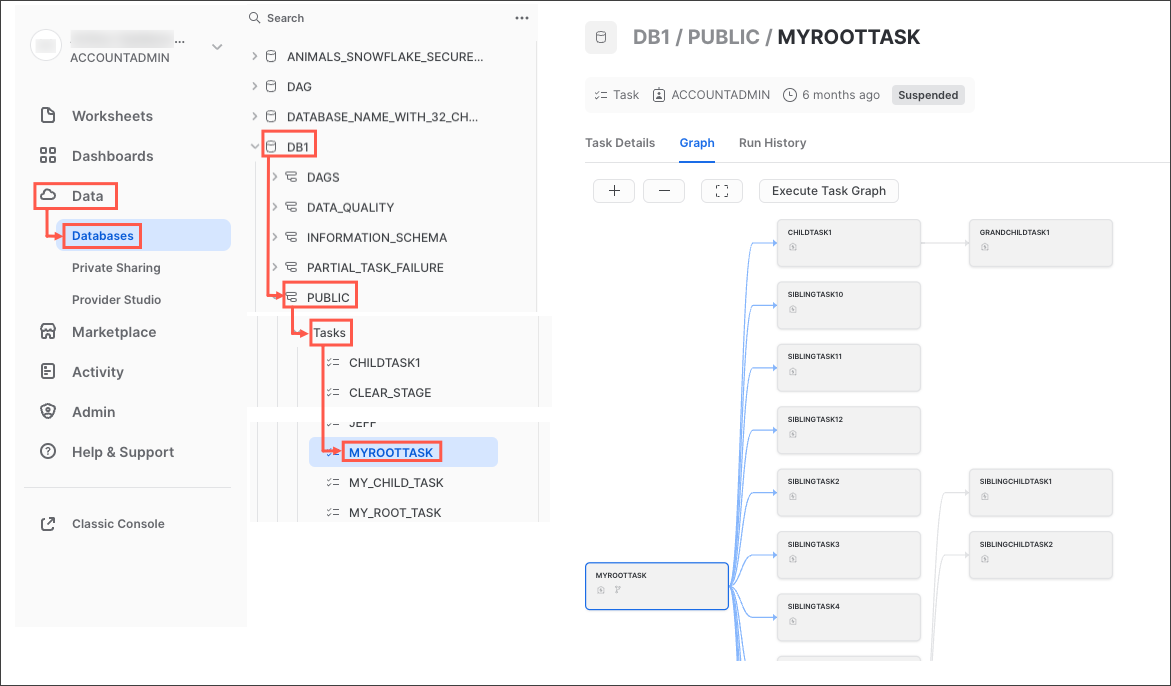
- Graph 탭을 선택합니다. 하위 작업의 계층 구조를 표시하는 작업 그래프가 나타납니다.
- 세부 정보를 보려면 작업을 선택합니다.
작업 그래프는 다음과 같습니다.
또한, 작업 실행 기록의 사례는 다음과 같습니다.
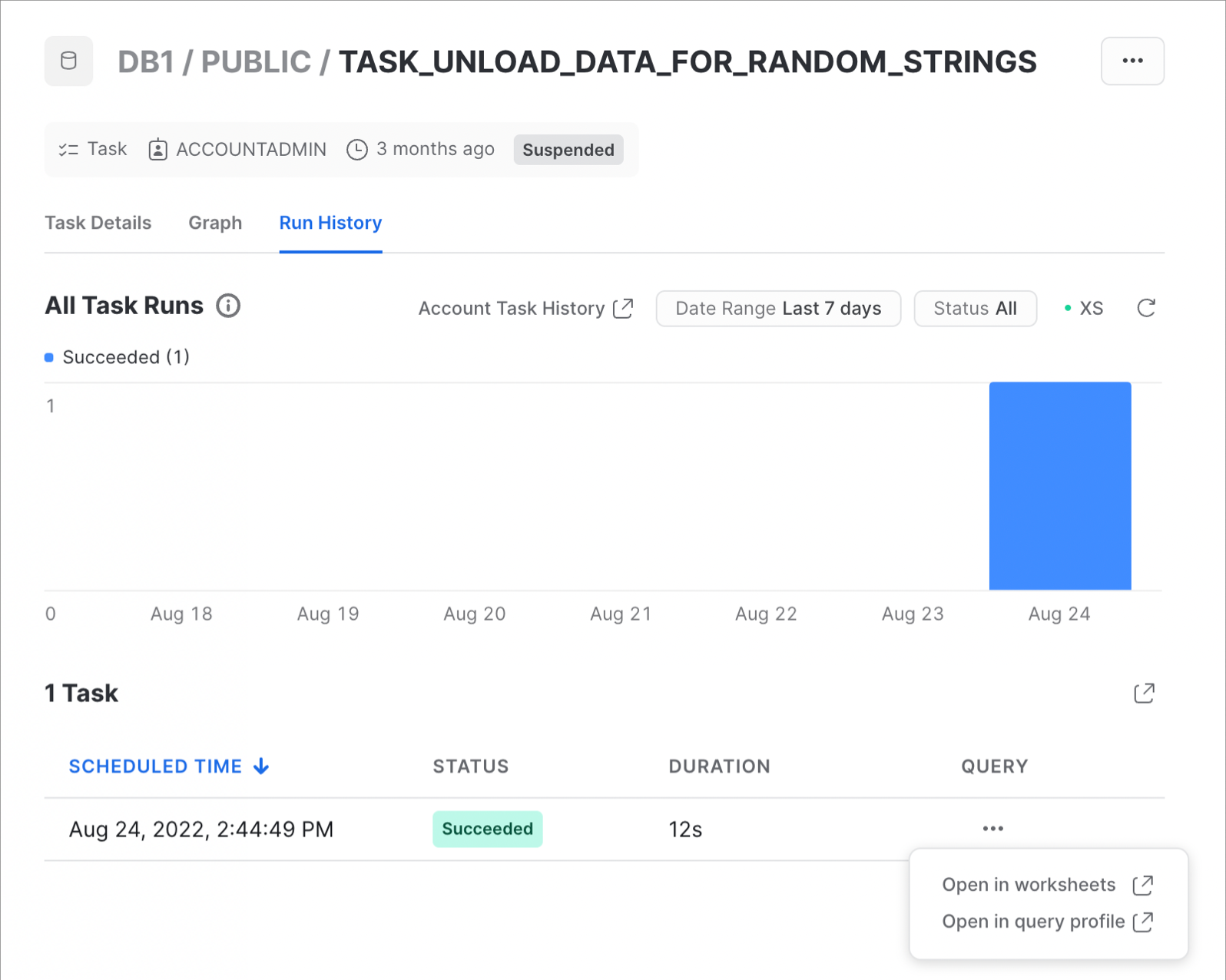
상세 정보와 계정 수준 작업 기록을 확인하는 것에 대해 알아보려면 작업 기록 보기 설명서를 확인하십시오.
이 단계에서는 새로운 데이터를 POS 주문 테이블에 추가한 다음 새로운 데이터를 처리하기 위해 전체 엔드 투 엔드 파이프라인을 실행하겠습니다. 또한, 이 전체 파이프라인은 Snowflake의 고급 스트림 및 CDC 기능을 활용하여 데이터를 증분적으로 처리하게 됩니다. 콘텍스트에 적용하기 위해 데이터 흐름 개요의 9단계로 이동합니다.
스크립트 실행
이는 SQL 스크립트이므로 이를 실행하기 위해 네이티브 VS Code 확장 프로그램을 사용하겠습니다. 간단히 VS Code에서 steps/09_process_incrementally.sql 스크립트를 열고 편집기 창의 오른쪽 상단 모서리에 있는 ‘Execute All Statements' 버튼을 사용하여 모든 것을 실행합니다.
실행되는 동안 현황을 간략히 알아보겠습니다. 2단계와 마찬가지로 Parquet의 데이터를 가공 전 POS 테이블로 로드하겠습니다. 2단계에서는 ORDER_HEADER 및 ORDER_DETAIL의 2022년 데이터를 제외한 모든 주문 데이터를 로드했습니다. 따라서 이제 나머지 데이터를 로드하겠습니다.
이번에는 Python 대신 SQL을 통해 데이터를 로드하겠습니다. 하지만 프로세스는 동일합니다. 웨어하우스의 크기를 조정하겠습니다. 데이터를 더 빠르게 로드할 수 있도록 크기를 늘린 다음 작업이 끝나면 크기를 다시 줄이겠습니다. 또한, 새로운 데이터가 로드된 후 작업 DAG를 다시 실행하겠습니다. 이번에는 2개의 작업이 모두 실행되며 새로운 데이터를 처리합니다.
작업 기록 보기
이전 단계와 마찬가지로 이 작업 DAG를 실행했을 때의 결과를 확인하려면 스크립트에서 이 주석이 달린 쿼리를 선택 및 실행(CMD/CTRL+Enter 바로 가기 키 사용)합니다.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
SCHEDULED_TIME_RANGE_START=>DATEADD('DAY',-1,CURRENT_TIMESTAMP()),
RESULT_LIMIT => 100))
ORDER BY SCHEDULED_TIME DESC
;
이번에는 HARMONIZED.POS_FLATTENED_V_STREAM 스트림에 새로운 데이터가 있기에 ORDERS_UPDATE_TASK 작업을 건너뛰지 않을 것입니다. 몇 분 후에 ORDERS_UPDATE_TASK 작업과 DAILY_CITY_METRICS_UPDATE_TASK 작업이 성공적으로 완료된 것을 확인할 수 있습니다.
작업의 쿼리 내역
작업을 이해하는 데 한 가지 중요한 점은 작업으로 실행되는 쿼리가 기본 쿼리 내역 UI 설정을 사용하면 나타나지 않는다는 것입니다. 방금 실행한 쿼리를 확인하려면 다음 작업을 수행해야 합니다.
- 추후에 예정된 작업은 ‘System'으로 실행되니 이 테이블의 상단에서 필터(사용자 이름 포함)를 제거합니다.

- ‘Filter'를 클릭하고, ‘Queries executed by user tasks' 필터 옵션을 추가하고, ‘Apply Filters'를 클릭합니다.
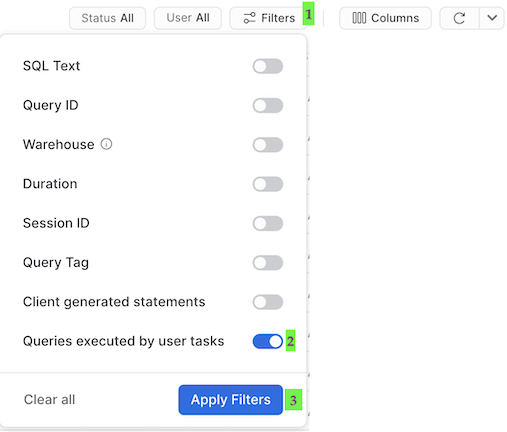
이제 작업이 실행하는 모든 쿼리를 확인할 수 있습니다! 쿼리 내역에서 각 MERGE 명령을 살펴보고 각 작업이 몇 개의 기록을 처리했는지 확인합니다. 방금 전체 파이프라인을 처리했으며 증분적으로 진행되었다는 사실을 기억해 주시기 바랍니다!
이 단계에서는 FAHRENHEIT_TO_CELSIUS_UDF() UDF에 변경 사항을 적용하고 이를 CI/CD 파이프라인을 통해 배포하겠습니다. 서드 파티 Python 패키지를 사용하기 위해 FAHRENHEIT_TO_CELSIUS_UDF() UDF를 업데이트하고, 이를 포크된 GitHub 리포지토리로 푸시하고, 마지막으로 GitHub Actions 워크플로우에서 SnowCLI를 사용하여 이를 배포하겠습니다! 콘텍스트에 적용하기 위해 데이터 흐름 개요의 10단계로 이동합니다.
화씨 섭씨 변환 UDF 업데이트
하드 코드된 온도 변환을 scipy의 패키지로 바꾸겠습니다. 우선, steps/05_fahrenheit_to_celsius_udf/app.py 스크립트에 몇 가지 변경 사항을 적용하겠습니다. 이 파일에서는 import 명령을 추가하고 main() 함수의 본문을 바꾸겠습니다. VS Code에서 steps/05_fahrenheit_to_celsius_udf/app.py 스크립트를 열고 다음 섹션을
import sys
def main(temp_f: float) -> float:
return (float(temp_f) - 32) * (5/9)
아래 섹션으로 바꿉니다.
import sys
from scipy.constants import convert_temperature
def main(temp_f: float) -> float:
return convert_temperature(float(temp_f), 'F', 'C')
변경 사항을 저장하십시오.
적용해야 하는 두 번째 변경 사항은 scipy를 requirements.txt 파일에 추가하는 것입니다. VS Code에서 steps/05_fahrenheit_to_celsius_udf/requirements.txt 파일을 열고, scipy를 포함한 새로운 줄을 추가하고, 파일을 저장합니다.
로컬에서 변경 사항 테스트
로컬에서 UDF를 테스트하려면 steps/05_fahrenheit_to_celsius_udf/app.py 스크립트를 실행합니다. 이전 단계와 마찬가지로 터미널에서 이를 실행하겠습니다. 따라서 상단 메뉴 모음의 VS Code에서 터미널(Terminal -> New Terminal)을 열고 pysnowpark Conda 환경이 활성화되어 있는지 확인한 다음, 다음 명령(터미널에 리포지토리 루트가 열려 있음을 가정함)을 실행합니다.
cd steps/05_fahrenheit_to_celsius_udf
pip install -r requirements.txt
python app.py 35
이번에는 종속 패키지가 설치되었는지 확인하기 위해 pip install도 실행하겠습니다. 함수가 성공적으로 실행된 후 CI/CD를 통해 이를 배포할 수 있습니다!
포크된 GitHub 프로젝트 구성
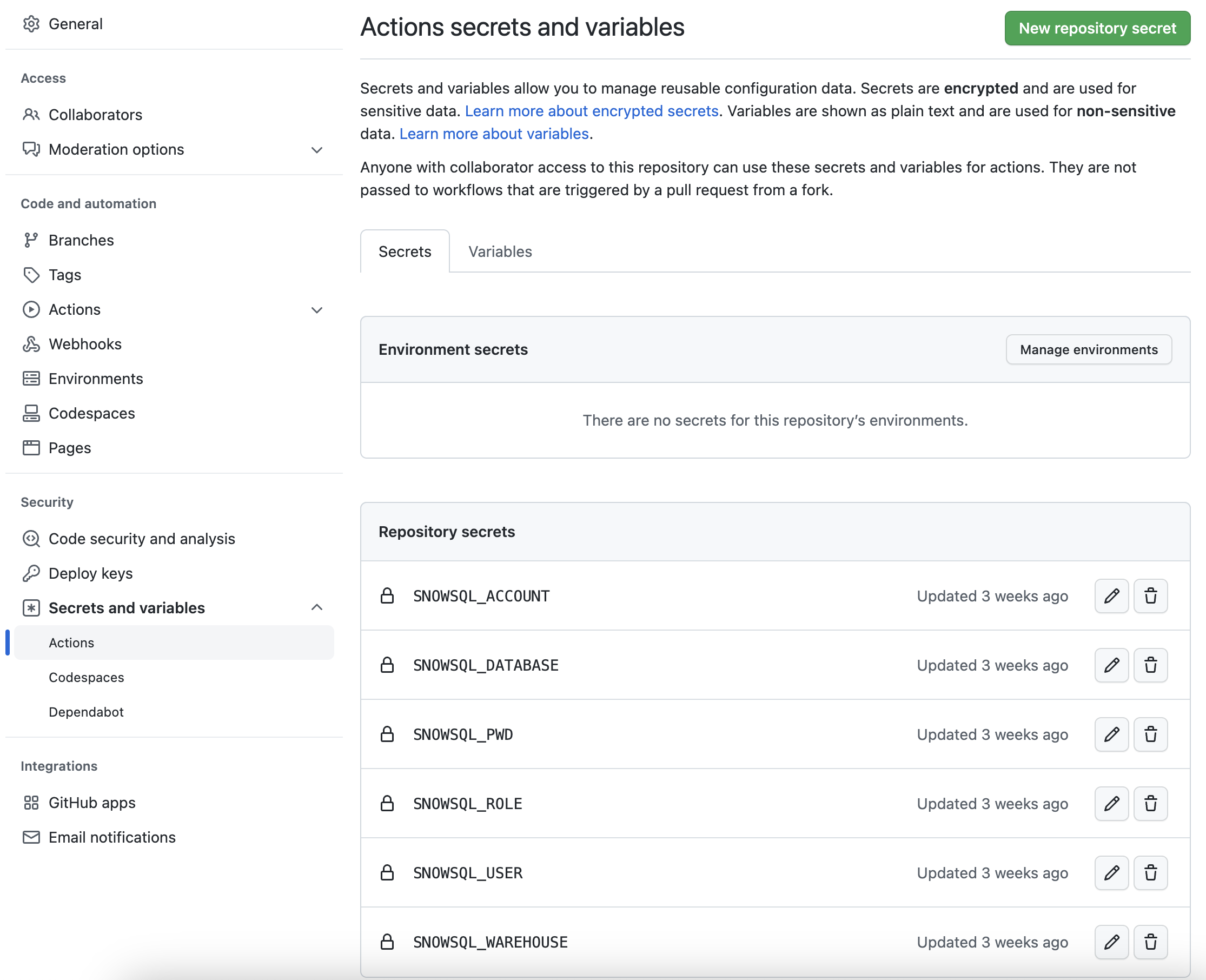
GitHub Actions 워크플로우를 Snowflake 계정과 연결하려면 Snowflake 자격 증명을 GitHub에 저장해야 합니다. GitHub의 Action Secrets는 CI/CD 파이프라인에 사용될 값과 변수를 안전하게 저장하기 위해 사용됩니다. 이 단계에서는 SnowCLI가 사용하는 각 매개변수의 비밀을 생성하겠습니다.
리포지토리에서 페이지 상단 부근에 있는 Settings 탭을 클릭합니다. 설정 페이지에서 Secrets and variables를 클릭한 다음 왼쪽 탐색에 있는 Actions 탭을 클릭합니다. Actions 비밀을 선택해야 합니다. 아래에 나열된 각 비밀을 위해 오른쪽 상단 부근에 있는 New repository secret을 클릭하고 적절한 값(적절하게 조정)과 아래에 제공된 이름을 입력합니다.
Secret name | Secret value |
SNOWSQL_ACCOUNT | myaccount |
SNOWSQL_USER | myusername |
SNOWSQL_PWD | mypassword |
SNOWSQL_ROLE | HOL_ROLE |
SNOWSQL_WAREHOUSE | HOL_WH |
SNOWSQL_DATABASE | HOL_DB |
모든 비밀을 추가했다면 페이지가 다음과 같을 것입니다.
포크된 리포지토리로 변경 사항 푸시
변경 사항이 준비 및 테스트되었고 Snowflake 자격 증명이 GitHub에 저장되어 있으니 이를 로컬 리포지토리로 커밋한 다음 포크된 리포지토리로 푸시하겠습니다. 이 작업은 명령줄에서 수행할 수 있지만, 이 단계에서는 쉽게 진행하기 위해 VS Code에서 수행하겠습니다.
왼쪽 탐색 모음에서 ‘Source Control' 확장 프로그램을 열며 시작합니다. 그러면 변경 사항이 적용된 2개의 파일이 나타납니다. 각 파일 이름의 오른쪽에 있는 +(더하기) 기호를 클릭하여 변경 사항을 실시합니다. 그럼 다음 ‘Message' 상자에 메시지를 입력하고 파란색 Commit 버튼을 클릭하여 변경 사항을 로컬에서 커밋합니다. 버튼을 클릭하기 전의 모습은 다음과 같아야 합니다.
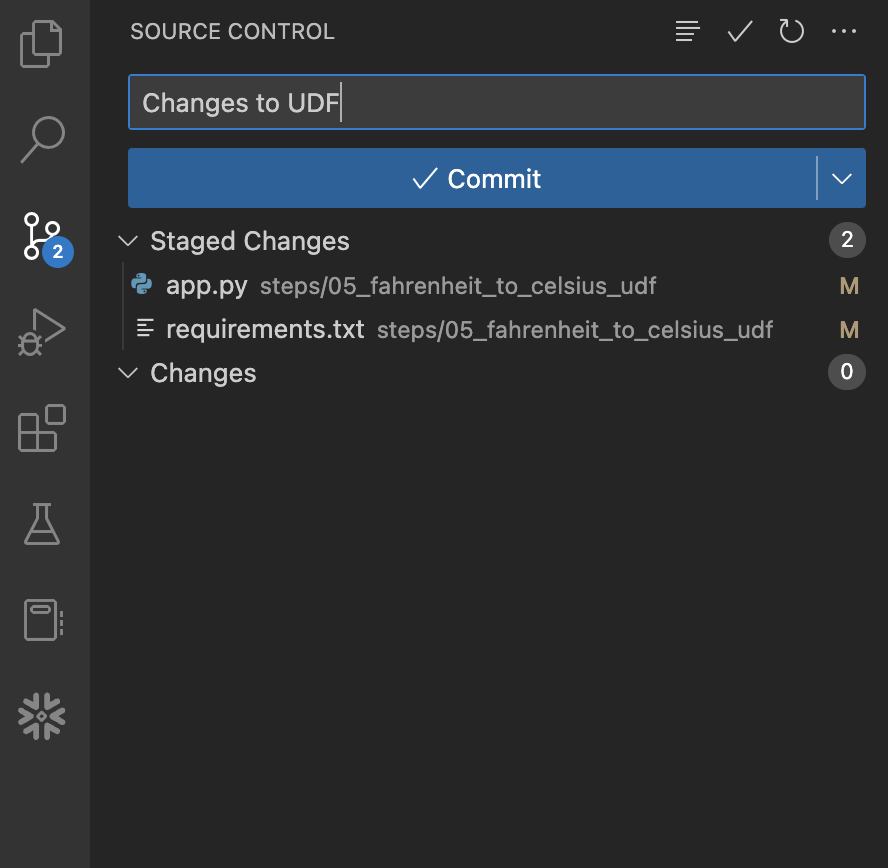
이 지점에서 이러한 변경 사항은 로컬에서만 커밋되며 GitHub에서 포크된 리포지토리로 아직 푸시되지 않았습니다. 이 작업을 수행하기 위해 간단히 파란색 Sync Changes 버튼을 클릭하여 이러한 커밋을 GitHub로 푸시합니다. 버튼을 클릭하기 전의 모습은 다음과 같아야 합니다.
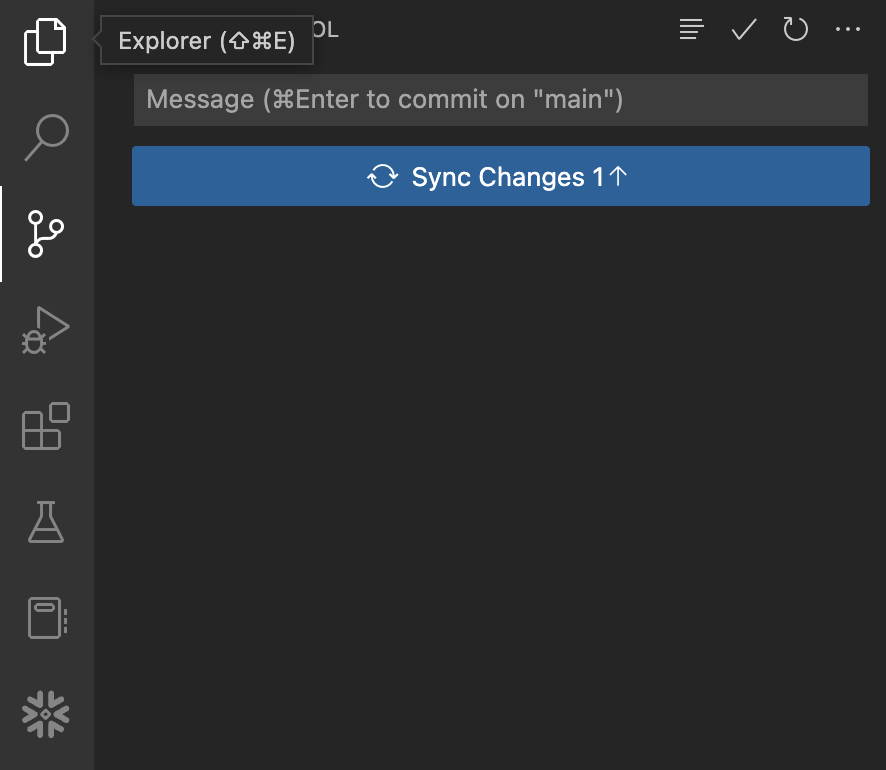
GitHub Actions 워크플로우 보기
이 리포지토리는 이미 매우 단순한 GitHub Actions CI/CD 파이프라인으로 설정되어 있습니다. 워크플로우의 코드는 VS Code에서 .github/workflows/build_and_deploy.yaml 파일을 열어 검토할 수 있습니다.
변경 사항을 GitHub의 포크된 리포지토리로 푸시하고 바로 워크플로우가 시작되었습니다. 결과를 확인하려면 GitHub 리포지토리의 홈페이지로 되돌아가 다음 작업을 수행합니다.
- 리포지토리에서 페이지 상단 중앙 부근에 있는
Actions탭을 클릭합니다. - 왼쪽 탐색 메뉴에서
Deploy Snowpark Apps워크플로우의 이름을 클릭합니다. - 가장 최근 특정 실행(입력한 주석과 일치해야 함)의 이름을 클릭합니다.
- 실행 개요 페이지에서
deploy작업을 클릭한 다음 여러 단계의 출력을 열람합니다. 특히Deploy Snowpark apps단계의 출력을 검토하면 도움이 될 수 있습니다.
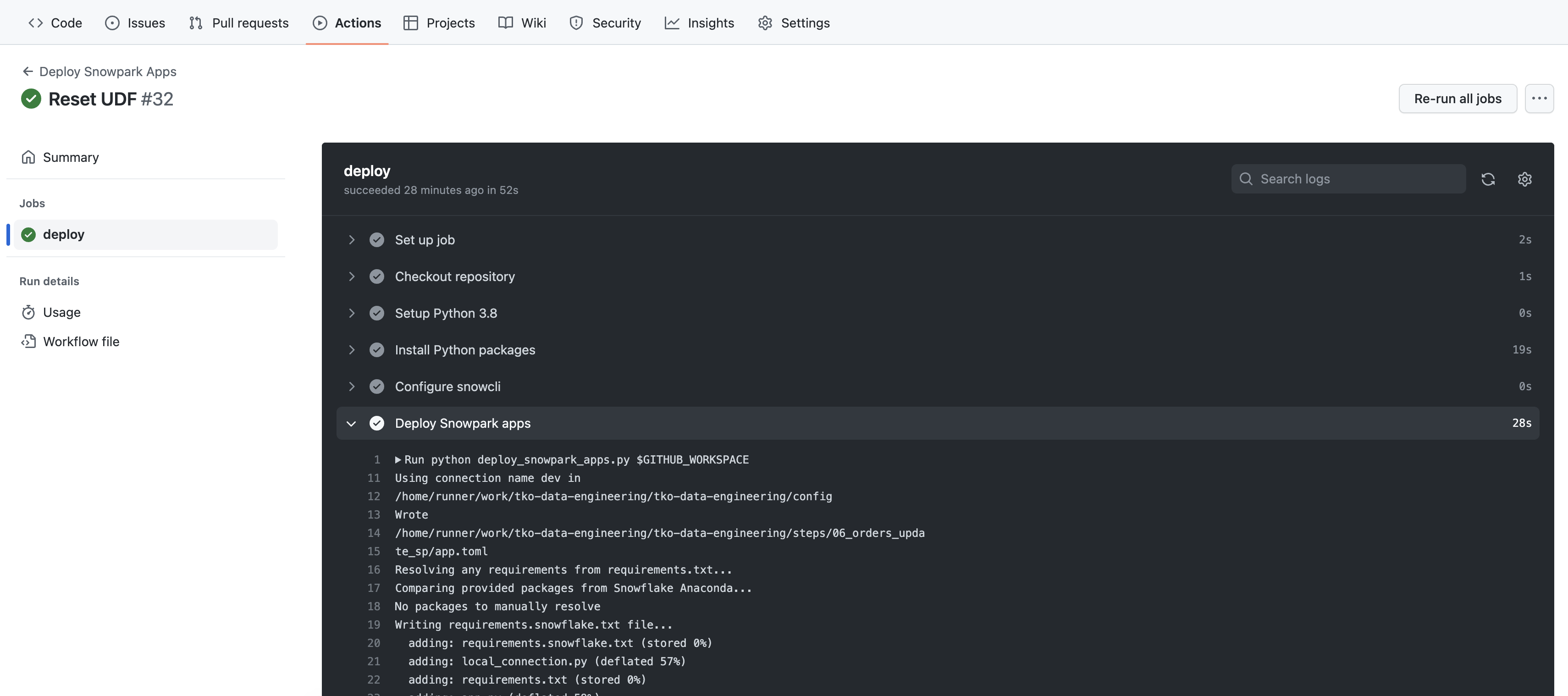
지금쯤 Deploy Snowpark apps 단계의 출력이 익숙하게 여겨질 것입니다. 이는 이전 단계에서 SnowCLI를 실행했을 때 VS Code의 터미널에서 본 내용일 것입니다. 다를 수 있는 부분은 출력 순서입니다. 하지만 현황을 파악할 수 있을 것입니다.
Quickstart를 완료하고 정리하고 싶다면 간단히 steps/11_teardown.sql 스크립트를 실행하면 됩니다. 이는 SQL 스크립트이므로 이를 실행하기 위해 네이티브 VS Code 확장 프로그램을 사용하겠습니다. 간단히 VS Code에서 steps/11_teardown.sql 스크립트를 열고 편집기 창의 오른쪽 상단 모서리에 있는 ‘Execute All Statements' 버튼을 사용하여 모든 것을 실행합니다.
이 Quickstart에서는 많은 내용을 다뤘습니다! 이렇게 Snowpark Python 저장 프로시저를 사용하여 강력한 데이터 엔지니어링 파이프라인을 구축하셨습니다. 이 파이프라인은 데이터를 증분적으로 처리하고, Snowflake 작업과 조정되고, CI/CD 파이프라인을 통해 배포됩니다. 또한, Snowflake의 새로운 개발자 CLI 도구 및 Visual Studio Code 확장 프로그램을 사용하는 방법을 배웠습니다. 간략한 시각적 요약은 다음과 같습니다.
하지만 실질적으로 Snowpark로 가능한 작업의 극히 일부만을 다뤘습니다. 기본 구성 요소와 사례를 이제 보유하고 계시기를 바랍니다. Snowpark Python으로 자신만의 데이터 엔지니어링 파이프라인을 구축하기 시작하셔야 합니다. 이제 무엇을 구축하시겠어요?
다룬 내용
이 Quickstart에서는 많은 내용을 다뤘습니다. 중요한 부분은 다음과 같습니다.
- Snowflake의 테이블 형식
- COPY를 사용한 데이터 수집
- 스키마 추론
- 데이터 공유 및 마켓플레이스(ETL 대신)
- 증분적 처리를 위한 스트림(CDC)
- 뷰의 스트림
- Python UDF(서드 파티 패키지 포함)
- Python 저장 프로시저
- Snowpark DataFrame API
- Snowpark Python 프로그램 가능성
- 웨어하우스 탄력성(동적 규모 조정)
- Visual Studio Code Snowflake 네이티브 확장 프로그램(PuPr, Git 통합)
- SnowCLI(PuPr)
- 작업(스트림 트리거 포함)
- 작업 관측 가능성
- GitHub Actions(CI/CD) 통합
관련 리소스
마지막으로 관련 리소스의 간략한 요약은 다음과 같습니다.