이 실습 랩에서는 Snowflake 마켓플레이스에 Knoema가 게시한 Economical Data Atlas를 활용하여 데이터 애플리케이션을 구축합니다.
Snowpark로 데이터를 처리하고, 단순한 ML 모델을 개발하고, Snowflake에서 Python 사용자 정의 함수(UDF)를 생성한 다음 Streamlit으로 데이터를 시각화합니다.
핵심 기능 및 기술
- Snowflake 마켓플레이스
- Snowpark for Python
- Python 라이브러리
- Python 사용자 정의 함수(UDF)
- Streamlit
사전 필요 조건 및 지식
- ACCOUNTADMIN 역할 액세스 또는 Snowflake 평가판 계정(https://signup.snowflake.com/)
- SQL, 데이터베이스 개념 및 객체에 대한 기본 지식
- Python 사용 경험 (랩을 위한 모든 코드는 제공됩니다.)
- 컴퓨터에서 소프트웨어를 설치 및 실행할 능력
- VSCode 설치
학습할 내용
- Snowflake 마켓플레이스에 있는 데이터 세트 소비하기
- DataFrame을 사용하여 Python에서 데이터에 대한 쿼리 수행하기
- 기존 Python 라이브러리 활용하기
- Snowflake에서 Snowpark Python 사용자 정의 함수 생성하기
- 데이터 시각화를 위해 Streamlit으로 데이터 애플리케이션 생성하기
구축할 것
- Snowpark for Python으로 Snowflake와 연결하고 선형 회귀 모델 훈련을 위한 피처를 준비하는 Python 노트북
- Python 학습 모델을 기반으로 한 Snowflake 사용자 정의 함수(UDF)
- Streamlit 대시보드 데이터 애플리케이션
- pip install conda를 실행하여 별도의 환경을 관리하기 위해 Conda를 설치합니다. 참고: 대신 Miniconda를 사용할 수도 있습니다.
- 터미널이나 명령 프롬프트를 엽니다.
conda create --name snowpark -c https://repo.anaconda.com/pkgs/snowflake python=3.8을 실행하여 환경을 생성합니다.conda activate snowpark를 실행하여 Conda 환경을 활성화합니다.conda install -c https://repo.anaconda.com/pkgs/snowflake snowflake-snowpark-python pandas scikit-learn을 실행하여 Snowpark for Python, Pandas 및 scikit-learn을 설치합니다.pip install streamlit또는conda install streamlit을 실행하여 Streamlit을 설치합니다.- 폴더(예: ‘Summit HOL PCE')를 생성하고 해당 폴더에 랩 파일을 다운로드 및 저장합니다.
- 필수 파일 링크: https://drive.google.com/drive/folders/1CN6Ljj59XWv2B3Epqxk4DtfDmCH1co_Q?usp=sharing
pyarrow 관련 이슈 해결
pyarrow라이브러리가 이미 설치되어 있다면 Snowpark를 설치하기 전에 이를 제거합니다.pyarrow가 설치되어 있지 않은 경우 이를 스스로 설치할 필요가 없습니다. Snowpark를 설치하면 자동으로 적절한 버전이 설치됩니다.- Snowpark를 설치한 후 다른 버전의
pyarrow를 다시 설치하지 마십시오.
Snowflake 마켓플레이스로 작업
Snowflake 마켓플레이스는 비즈니스 프로세스를 변환하는 데 사용되는 데이터 요소에 대한 액세스를 확장하는 서드 파티 데이터 스튜어드가 제공하는 다양한 데이터 세트에 대한 가시성을 제공합니다. 또한, Snowflake 마켓플레이스는 데이터 공급자가 전적으로 유지하는 데이터 세트에 대한 안전한 액세스를 제공하므로 데이터를 통합하거나 모델링할 필요가 없습니다.
Snowflake 마켓플레이스로 작업하는 것을 검토하기 전에 Snowflake 평가판 버전을 설치했는지 확인합니다. 설치하지 않았다면 Install Snowflake Trial을 클릭합니다. 사용 가능한 평가판 계정을 보유하고 있으며 Snowflake 콘솔에 로그인했다면 다음 단계를 따릅니다.
- 왼쪽 상단 모서리에서 ACCOUNTADMIN으로 로그인되어 있는지 확인합니다. 만약 그렇지 않다면 역할을 전환합니다.
- Marketplace를 클릭합니다.
- 검색 바에 Knoema Economy를 입력한 다음 Economy Data Atlas라는 타일 상자를 클릭합니다.
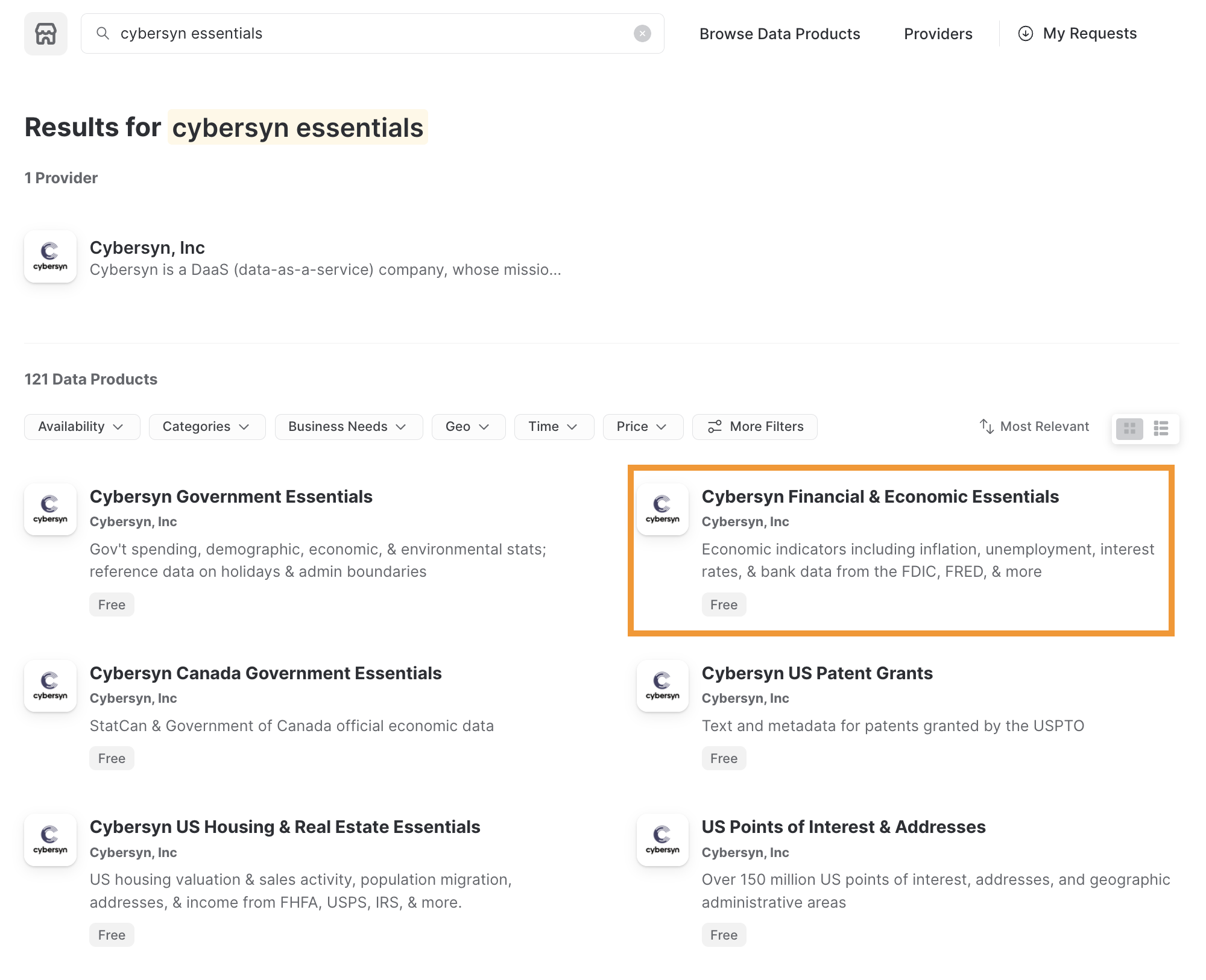
- 오른쪽 상단 모서리에서 Get Data를 선택합니다.
- 생성되는 데이터베이스에 액세스할 적절한 역할을 선택하고 Snowflake 소비자 사용 약관과 Knoema 사용 약관을 수락합니다.
- 데이터베이스 생성
- 이제 Query Data를 선택하면 쿼리 사례가 포함된 워크시트가 열립니다.
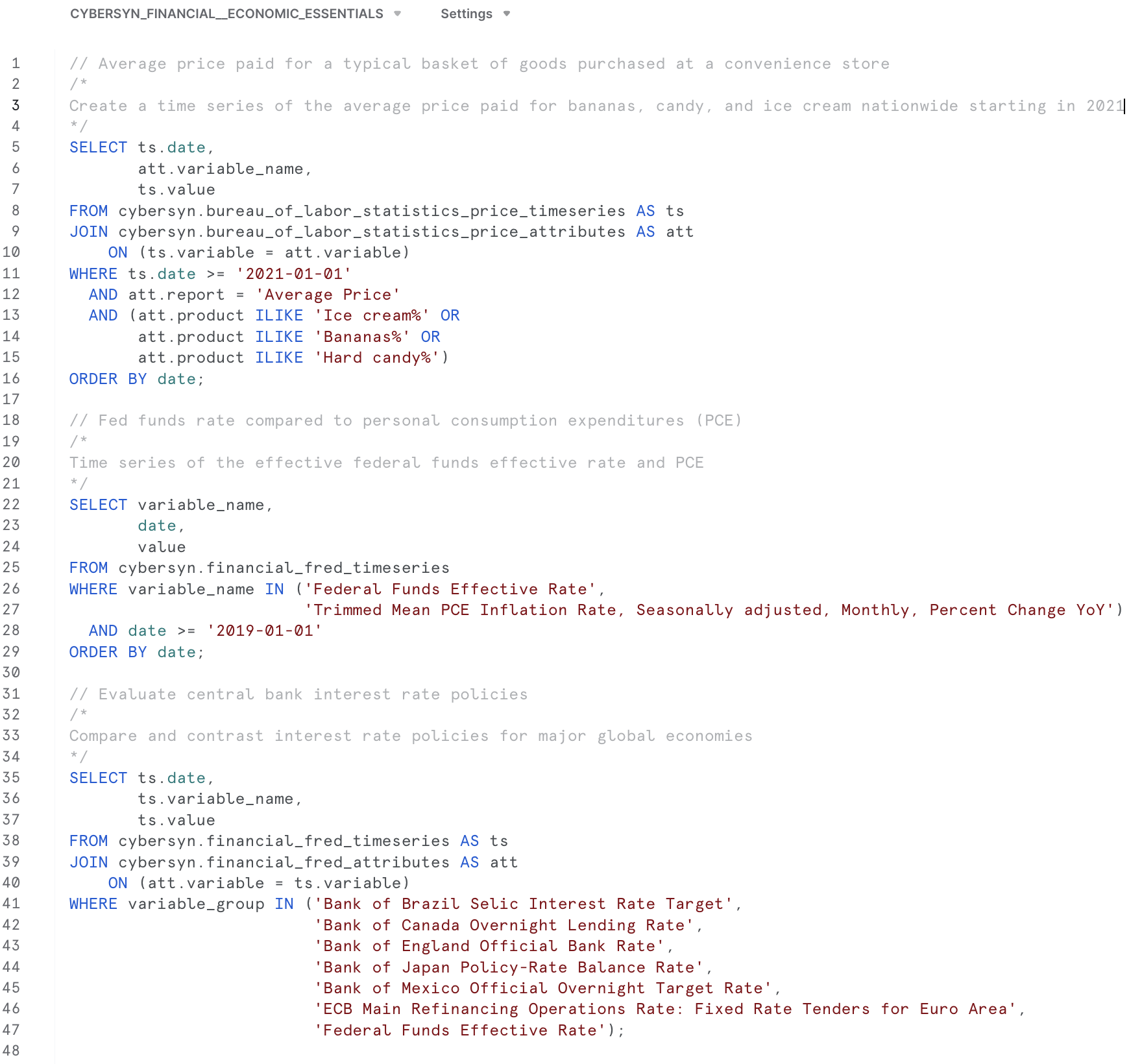
- 우리는 미국 인플레이션 데이터에 관심이 있으므로
What is the US inflation over time?쿼리를 사용하여 애플리케이션을 위한 데이터를 탐색하겠습니다.SELECT * FROM "ECONOMY"."BEANIPA" WHERE "Table Name" = 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product' AND "Indicator Name" = 'Personal consumption expenditures (PCE)' AND "Frequency" = 'A' ORDER BY "Date"
새로운 데이터베이스 생성
이제 Economy Data Atlas를 사용하여 데이터베이스를 생성했으니 사용자 정의 함수를 저장할 애플리케이션을 위한 데이터베이스를 생성해야 합니다.
Snowflake 홈 메뉴에서 ‘Worksheets'를 선택합니다.  버튼을 선택하여
버튼을 선택하여
새로운 워크시트를 생성합니다.
워크시트에서 다음 스크립트를 복사합니다.
-- First create database using the Knoema Economical Data Atlas
-- Go to Marketplace to get database
-- Setup database, need to be logged in as accountadmin role */
--Set role and warehouse (compute)
USE ROLE accountadmin;
USE WAREHOUSE compute_wh;
--Create database and stage for the Snowpark Python UDF
CREATE DATABASE IF NOT EXISTS summit_hol;
CREATE STAGE IF NOT EXISTS udf_stage;
--Test the data
-- What's the size?
SELECT COUNT(*) FROM ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA;
-- What is the US inflation over time?
SELECT * FROM ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA
WHERE "Table Name" = 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product'
AND "Indicator Name" = 'Personal consumption expenditures (PCE)'
AND "Frequency" = 'A'
ORDER BY "Date"
;
-- Now create UDF in VS Code / Notebook
-- Once we created the UDF with the Python Notebook we can test the UDF
SELECT predict_pce_udf(2021);
이제 애플리케이션에 사용할 수 있는 데이터베이스를 보유하고 있으니 데이터를 탐색하고 애플리케이션이 사용할 수 있는 사용자 정의 함수(UDF)의 ML 모델을 생성하고자 합니다.
VS Code를 열고 앞서 생성한 Python 스크립트가 포함된 폴더를 엽니다.
Python 노트북(my_snowpark_pce.ipynb)과 Streamlit 애플리케이션 스크립트(my_snowpark_streamlit_app_pce.py)를 열 수 있습니다. 다양한 코드를 검토하겠습니다.
VS Code가 Python 환경을 요구할 수도 있습니다. \
앞서 생성한 ‘snowpark' Conda 환경을 선택해야 합니다.
오른쪽 하단 모서리에서 클릭하여 인터프리터를 선택할 수 있습니다. \

노트북 초기화, 라이브러리 가져오기, Snowflake 연결 생성
Python 스크립트를 생성하고 필수 라이브러리를 포함시키기 위해 가져오기 문을 추가하며 시작하겠습니다.
from snowflake.snowpark.session import Session
from snowflake.snowpark.types import IntegerType, FloatType
from snowflake.snowpark.functions import avg, sum, col, udf, call_udf, call_builtin, year
import streamlit as st
import pandas as pd
from datetime import date
# scikit-learn (install: pip install -U scikit-learn)
from sklearn.linear_model import LinearRegression
Snowflake와 연결
이 단계에서는 Snowflake와 연결하기 위한 Session 객체를 생성하게 됩니다. 이를 빠르게 진행하는 방법은 다음과 같지만, 프로덕션 환경에서는 코드에 바로 하드 코딩 자격 증명을 사용하는 것이 권장되지 않습니다. 프로덕션 환경에 더 적합한 접근 방식은 예를 들어 AWS Secrets Manager 또는 Azure Key Vault에서 자격 증명을 로드하는 것입니다.
Snowflake 설정 섹션에서 생성한 데이터베이스를 사용하겠습니다.
# Session
connection_parameters = {
"account": "<account_identifier>",
"user": "<username>",
"password": "<password>",
"warehouse": "compute_wh",
"role": "accountadmin",
"database": "summit_hol",
"schema": "public"
}
session = Session.builder.configs(connection_parameters).create()
# test if we have a connection
session.sql("select current_warehouse() wh, current_database() db, current_schema() schema, current_version() v").show()
위 코드 조각에서 "<>" 안에 있는 변수를 자신의 값으로 바꿉니다.
SQL 문 및 Snowpark DataFrame을 사용하여 데이터 쿼리
이 단계에서는 Session 객체에 있는 SQL 문을 실행하는 전통적인 메소드를 사용하여 데이터를 쿼리하겠습니다. 이는 Python 커넥터를 위해 Snowflake로 데이터를 쿼리하는 것과 비슷합니다.
# SQL query to explore the data
session.sql("SELECT * FROM ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA WHERE \"Table Name\" = 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product' AND \"Indicator Name\" = 'Personal consumption expenditures (PCE)' AND \"Frequency\" = 'A' ORDER BY \"Date\"").show()
이제 Snowpark DataFrame으로 데이터를 쿼리하겠습니다. Snowpark는 느긋한 계산법을 사용하기에 쿼리 및 필터 조건이 생성되면 show() 메소드가 이를 쿼리가 실행될 Snowflake 서버로 푸시합니다. 그러면 Snowflake와 클라이언트 또는 애플리케이션 간에 교환되는 데이터의 양이 줄어듭니다.
# Now use Snowpark dataframe
snow_df_pce = (session.table("ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA")
.filter(col('Table Name') == 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product')
.filter(col('Indicator Name') == 'Personal consumption expenditures (PCE)')
.filter(col('"Frequency"') == 'A')
.filter(col('"Date"') >= '1972-01-01'))
snow_df_pce.show()
ML 훈련을 위한 피처 생성
애플리케이션의 일환으로 개인소비지출 가격 지수에 대한 몇 가지 예측을 얻어 보겠습니다. 따라서 모델을 scikit-learn 선형 회귀 모델로 훈련하는 데 사용할 수 있는 Pandas DataFrame을 생성하겠습니다. Python용 Snowpark API는 Snowpark DataFrame을 Pandas로 변환하기 위해 메소드를 노출시킵니다. 이번에도 Snowpark의 느긋한 계산법을 사용하면 DataFrame 쿼리를 만들 수 있고, to_pandas() 함수는 해당 쿼리를 Snowflake로 푸시하고 결과를 Pandas DataFrame으로 반환합니다.
# Let Snowflake perform filtering using the Snowpark pushdown and display results in a Pandas dataframe
snow_df_pce = (session.table("ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA")
.filter(col('"Table Name"') == 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product')
.filter(col('"Indicator Name"') == 'Personal consumption expenditures (PCE)')
.filter(col('"Frequency"') == 'A')
.filter(col('"Date"') >= '1972-01-01'))
pd_df_pce_year = snow_df_pce.select(year(col('"Date"')).alias('"Year"'), col('"Value"').alias('PCE') ).to_pandas()
pd_df_pce_year
선형 회귀 모델 훈련
이제 피처를 생성했으니 모델을 훈련할 수 있습니다. 이 단계에서는 NumPy 라이브러리를 사용하여 피처를 포함한 Pandas DataFrame을 배열로 변환하겠습니다. 훈련이 끝나면 예측을 표시할 수 있게 됩니다.
# train model with PCE index
x = pd_df_pce_year["Year"].to_numpy().reshape(-1,1)
y = pd_df_pce_year["PCE"].to_numpy()
model = LinearRegression().fit(x, y)
# test model for 2021
predictYear = 2021
pce_pred = model.predict([[predictYear]])
# print the last 5 years
print (pd_df_pce_year.tail() )
# run the prediction for 2021
print ('Prediction for '+str(predictYear)+': '+ str(round(pce_pred[0],2)))
훈련된 모델로 Snowflake에서 사용자 정의 함수 생성
이 단계에서는 함수 입력을 기반으로 PCE 지수를 예측하기 위해 훈련된 모델을 사용할 Python 함수를 생성하겠습니다. 그런 다음, Snowpark API를 사용하여 UDF를 생성하겠습니다. Snowpark 라이브러리는 내부 스테이지에 함수를 위한 코드(및 훈련된 모델)를 업로드합니다. UDF를 호출하면 Snowpark 라이브러리는 데이터가 있는 서버에서 함수를 실행합니다. 결과적으로, 함수가 데이터를 처리하기 위해 데이터를 클라이언트로 전송할 필요가 없습니다.
def predict_pce(predictYear: int) -> float:
return model.predict([[predictYear]])[0].round(2).astype(float)
_ = session.udf.register(predict_pce,
return_type=FloatType(),
input_type=IntegerType(),
packages= ["pandas","scikit-learn"],
is_permanent=True,
name="predict_pce_udf",
replace=True,
stage_location="@udf_stage")
이제 Python에서 SQL 명령을 사용하여 UDF를 테스트할 수 있습니다.
session.sql("select predict_pce_udf(2021)").show()
필수 라이브러리 가져오기
이제 훈련된 ML 모델을 보유하고 있고 예측을 수행하기 위한 UDF를 생성했으니 Streamlit 애플리케이션을 생성할 수 있습니다.
노트북과 비슷하게 Python 스크립트를 생성하고 필수 라이브러리를 포함시키기 위해 가져오기 문을 추가합니다.
# Import required libraries
# Snowpark
from snowflake.snowpark.session import Session
from snowflake.snowpark.types import IntegerType
from snowflake.snowpark.functions import avg, sum, col, call_udf, lit, call_builtin, year
# Pandas
import pandas as pd
#Streamlit
import streamlit as st
애플리케이션 페이지 콘텍스트 설정
애플리케이션 페이지의 콘텍스트를 설정해야 합니다.
#Set page context
st.set_page_config(
page_title="Economical Data Atlas",
page_icon="🧊",
layout="wide",
initial_sidebar_state="expanded",
menu_items={
'Get Help': 'https://developers.snowflake.com',
'About': "This is an *extremely* cool app powered by Snowpark for Python, Streamlit, and Snowflake Marketplace"
}
)
Snowflake와 연결
이 단계에서는 Snowflake와 연결하기 위한 Session 객체를 생성하게 됩니다. 이를 빠르게 진행하는 방법은 다음과 같지만, 프로덕션 환경에서는 코드에 바로 하드 코딩 자격 증명을 사용하는 것이 권장되지 않습니다. 프로덕션 환경에 더 적합한 접근 방식은 예를 들어 AWS Secrets Manager 또는 Azure Key Vault에서 자격 증명을 로드하는 것입니다.
Snowflake 설정 섹션에서 생성한 데이터베이스를 사용하겠습니다.
# Create Session object
def create_session_object():
connection_parameters = {
"account": "<account_identifier>",
"user": "<username>",
"password": "<password>",
"warehouse": "compute_wh",
"role": "accountadmin",
"database": "SUMMIT_HOL",
"schema": "PUBLIC"
}
session = Session.builder.configs(connection_parameters).create()
print(session.sql('select current_warehouse(), current_database(), current_schema()').collect())
return session
위 코드 조각에서 "<>" 안에 있는 변수를 자신의 값으로 바꿉니다.
Snowpark DataFrame에 데이터 로드
이 단계에서는 연간 미국 인플레이션(개인소비지출, PCE) 데이터로 DataFrame을 생성하겠습니다. BEANIPA 테이블(BEA NIPA: 미국 상무부 경제 분석국 국민소득생산계정 데이터)을 사용하겠습니다. 이 테이블에는 약 160만 개의 행이 포함되어 있습니다. 이 데이터는 Snowpark의 느긋한 계산법을 사용하여 Snowflake에서 처리됩니다.
노트북 섹션에서 생성한 훈련된 ML 모델을 포함한 UDF를 기반으로 실제 및 예상 PCE 값으로 DataFrame을 생성하겠습니다.
그리고 데이터를 단일 그래프로 표시할 수 있도록 실제 및 예상 DataFrame을 새로운 하나의 DataFrame으로 결합하겠습니다.
Streamlit으로 작업할 때는 Pandas DataFrame이 필요하며 Python용 Snowpark API는 Snowpark DataFrame을 Pandas로 변환하기 위해 메소드를 노출시킵니다.
그리고 몇 가지 주요 지표를 표시하고자 하기에 DataFrame에서 지표를 추출하겠습니다.
이에 더해 선택한 연도의 분기별 PCE 데이터와 주요 제품 유형별 분석 결과를 표시하고자 합니다. 이 데이터를 위해 2개의 DataFrame을 생성하겠습니다.
#US Inflation, Personal consumption expenditures (PCE) per year
#Prepare data frame, set query parameters
snow_df_pce = (session.table("ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA")
.filter(col('Table Name') == 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product')
.filter(col('Indicator Name') == 'Personal consumption expenditures (PCE)')
.filter(col('"Frequency"') == 'A')
.filter(col('"Date"') >= '1972-01-01'))
#Select columns, substract 100 from value column to reference baseline
snow_df_pce_year = snow_df_pce.select(year(col('"Date"')).alias('"Year"'), (col('"Value"')-100).alias('PCE')).sort('"Year"', ascending=False)
#convert to pandas dataframe
pd_df_pce_year = snow_df_pce_year.to_pandas()
#round the PCE series
pd_df_pce_year["PCE"] = pd_df_pce_year["PCE"].round(2)
#create metrics
latest_pce_year = pd_df_pce_year.loc[0]["Year"].astype('int')
latest_pce_value = pd_df_pce_year.loc[0]["PCE"]
delta_pce_value = latest_pce_value - pd_df_pce_year.loc[1]["PCE"]
#Use Snowflake UDF for Model Inference
snow_df_predict_years = session.create_dataframe([[int(latest_pce_year+1)], [int(latest_pce_year+2)],[int(latest_pce_year+3)]], schema=["Year"])
pd_df_pce_predictions = snow_df_predict_years.select(col("year"), call_udf("predict_pce_udf", col("year")).as_("pce")).sort(col("year")).to_pandas()
pd_df_pce_predictions.rename(columns={"YEAR": "Year"}, inplace=True)
#round the PCE prediction series
pd_df_pce_predictions["PCE"] = pd_df_pce_predictions["PCE"].round(2).astype(float)-100
#Combine actual and predictions dataframes
pd_df_pce_all = (
pd_df_pce_year.set_index('Year').sort_index().rename(columns={"PCE": "Actual"})
.append(pd_df_pce_predictions.set_index('Year').sort_index().rename(columns={"PCE": "Prediction"}))
)
#Data per quarter
snow_df_pce_q = (session.table("ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA")
.filter(col('Table Name') == 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product')
.filter(col('Indicator Name') == 'Personal consumption expenditures (PCE)')
.filter(col('"Frequency"') == 'Q')
.select(year(col('"Date"')).alias('Year'),
call_builtin("date_part", 'quarter', col('"Date"')).alias('"Quarter"') ,
(col('"Value"')-100).alias('PCE'))
.sort('Year', ascending=False))
# by Major Type Of Product
snow_df_pce_all = (session.table("ECONOMY_DATA_ATLAS.ECONOMY.BEANIPA")
.filter(col('"Table Name"') == 'Price Indexes For Personal Consumption Expenditures By Major Type Of Product')
.filter(col('"Indicator Name"') != 'Personal consumption expenditures (PCE)')
.filter(col('"Frequency"') == 'A')
.filter(col('"Date"') >= '1972-01-01')
.select('"Indicator Name"', year(col('"Date"')).alias('Year'), (col('"Value"')-100).alias('PCE') ))
웹 페이지 구성 요소 추가
이 단계에서는 다음을 추가하겠습니다.
- 헤더 및 하위 헤더(Streamlit의 columns() 및 _container()_를 사용하여 애플리케이션 콘텐츠를 정리하기 위해 컨테이너와 열을 사용하기도 함)
- Streamlit의 지표 함수를 사용하는 델타를 포함한 지표 디스플레이
- Streamlit의 selectbox_()_ 및 _bar_chart()_를 사용하는 인터랙티브 막대형 그래프
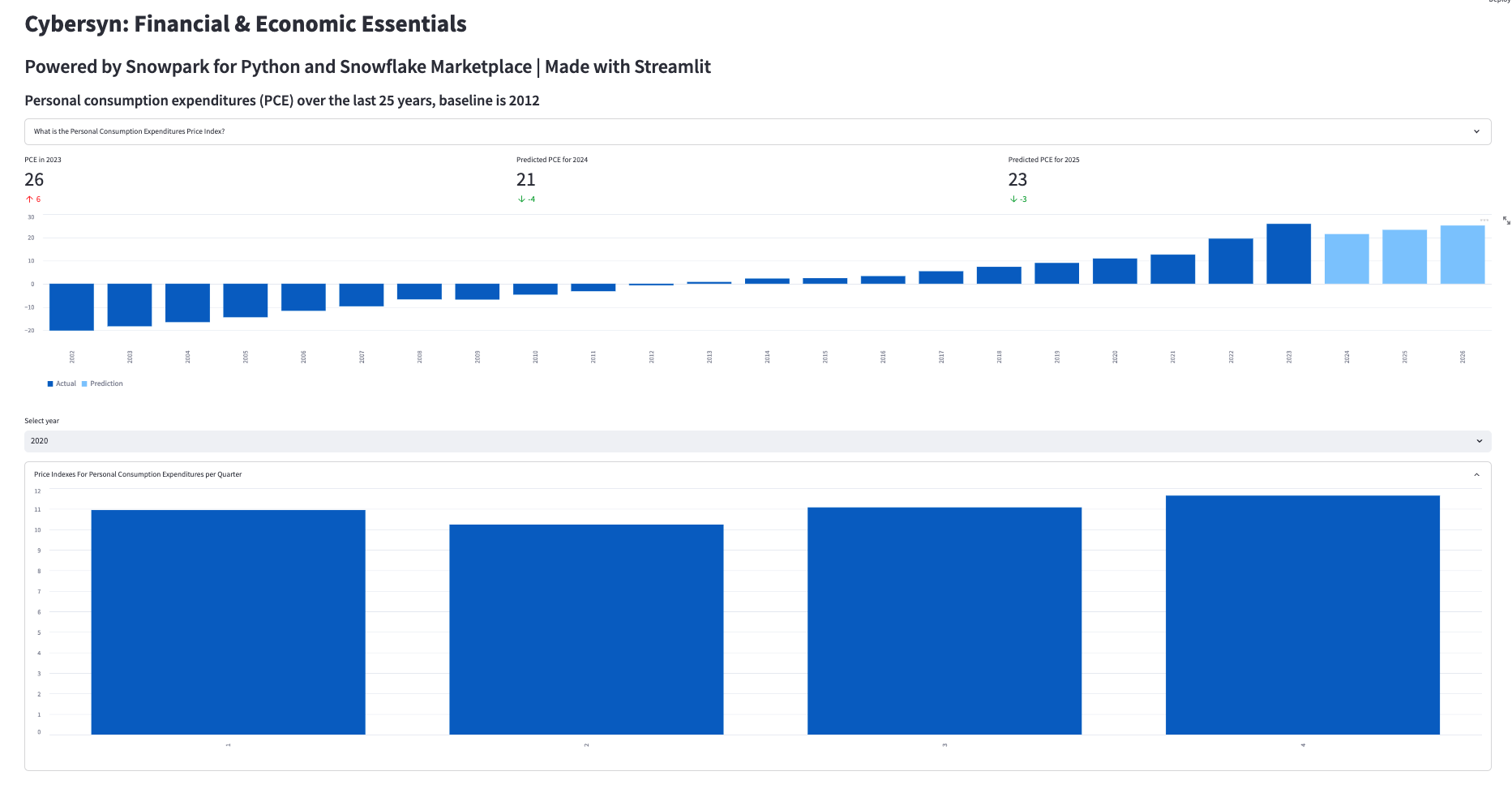
# Add header and a subheader
st.title("Knoema: Economical Data Atlas")
st.header("Powered by Snowpark for Python and Snowflake Marketplace | Made with Streamlit")
st.subheader("Personal consumption expenditures (PCE) over the last 25 years, baseline is 2012")
# Add an explanation on the PCE Price Index that can be expanded
with st.expander("What is the Personal Consumption Expenditures Price Index?"):
st.write("""
The prices you pay for goods and services change all the time – moving at different rates and even in different directions. Some prices may drop while others are going up. A price index is a way of looking beyond individual price tags to measure overall inflation (or deflation) for a group of goods and services over time.
The Personal Consumption Expenditures Price Index is a measure of the prices that people living in the United States, or those buying on their behalf, pay for goods and services.The PCE price index is known for capturing inflation (or deflation) across a wide range of consumer expenses and reflecting changes in consumer behavior.
""")
# Use columns to display metrics for global value and predictions
col11, col12, col13 = st.columns(3)
with st.container():
with col11:
st.metric("PCE in " + str(latest_pce_year), round(latest_pce_value), round(delta_pce_value), delta_color=("inverse"))
with col12:
st.metric("Predicted PCE for " + str(int(pd_df_pce_predictions.loc[0]["Year"])), round(pd_df_pce_predictions.loc[0]["PCE"]),
round((pd_df_pce_predictions.loc[0]["PCE"] - latest_pce_value)), delta_color=("inverse"))
with col13:
st.metric("Predicted PCE for " + str(int(pd_df_pce_predictions.loc[1]["Year"])), round(pd_df_pce_predictions.loc[1]["PCE"]),
round((pd_df_pce_predictions.loc[1]["PCE"] - latest_pce_value)), delta_color=("inverse"))
# Barchart with actual and predicted PCE
st.bar_chart(data=pd_df_pce_all.tail(25), width=0, height=0, use_container_width=True)
# Display interactive chart to visualize PCE per quarter and per major type of product.
with st.container():
year_selection = st.selectbox('Select year', pd_df_pce_year['Year'].head(25),index=0 )
pd_df_pce_q = snow_df_pce_q.filter(col('Year') == year_selection).sort(col('"Quarter"')).to_pandas().set_index('Quarter')
with st.expander("Price Indexes For Personal Consumption Expenditures per Quarter"):
st.bar_chart(data=pd_df_pce_q['PCE'], width=0, height=500, use_container_width=True)
pd_df_pce_all = snow_df_pce_all.filter(col('Year') == year_selection).sort(col('"Indicator Name"')).to_pandas().set_index('Indicator Name')
st.write("Price Indexes For Personal Consumption Expenditures By Major Type Of Product")
st.bar_chart(data=pd_df_pce_all['PCE'], width=0, height=500, use_container_width=True)
위 코드 조각에서는 매개변수 중 하나로 DataFrame을 사용하는 Streamlit의 _bar_chart()_를 사용하여 막대형 그래프가 만들어 졌습니다. 이 경우, 이는 훈련된 ML 모델이 포함되어 있는 Snowflake 사용자 정의 함수를 활용하는 예상 PCE 값이 포함된 Snowpark DataFrame의 _filter() _combined를 통해 날짜별로 필터링된 개인소비지출(PCE) 가격 지수 DataFrame의 하위 집합(25년)입니다. 최신 PCE 값과 작년 델타를 포함한 향후 2개의 예측과 같은 주요 지표는 Streamlit _metric() _function을 사용하여 표시됩니다.
상세 정보는 연도 선택(Streamlit_ selectbox() _ function), 선택한 연도의 분기별 값을 포함한 그래프, 선택한 연도의 주요 제품 유형 PCE 값에 대한 상세한 그래프를 사용하여 표시할 수 있습니다. 연도를 선택할 때마다 쿼리가 Snowflake에서 실행되고 결과가 Snowpark 및 Streamlit으로 표시됩니다.
재미 있는 부분입니다! Python 스크립트에 구문 및 연결 오류가 없다면 애플리케이션을 실행할 준비가 된 것입니다.
명령줄 또는 VS Code의 터미널 섹션에서 다음을 실행하여 애플리케이션을 실행할 수 있습니다.streamlit run my_snowpark_streamlit_app_pce.py (my_snowpark_streamlit_app_pce.py를 자신의 Python 스크립트로 바꿉니다.)
conda activate snowpark 터미널 명령을 사용하여 ‘snowpark' Conda 환경이 활성화되어 있는지 확인합니다.
올바른 Conda 환경을 선택했음을 나타내는 터미널 프롬프트가 나타납니다.
(base) user SummitHOL % conda activate snowpark
(snowpark) user SummitHOL %
애플리케이션에서:
- ‘+'로 표시된 확장 섹션을 클릭할 수 있습니다.
- 상세 정보를 표시하기 위해 연도를 선택할 수 있습니다.
- 분기별 PCE 값은 기본값으로 축소되어 있습니다. ‘+'를 클릭해 확장할 수 있습니다.