The Coherent Spark Connector transforms business logic designed in Microsoft Excel spreadsheets into reusable SQL functions that call our Spark APIs from Snowflake Data Cloud. Joint customers can save significant time on development and testing, and hence roll out their products to the market quickly while the original dataset remains in the Snowflake environment. The entire workflow comes with enterprise-grade security and scalability. Please see the FAQs in Step 6 for additional information.
Benefits
- Transform Excel logic into Snowflake functions - Create SQL functions from your Excel spreadsheets within minutes so you can use consumer data on the Snowflake Data Cloud with Spark's APIs.
- Effective governance - Data remains in the Snowflake environment except when being processed by Spark. This process takes place via secure API and is fully auditable.
- Get value faster - Boost logic execution efficiency by leveraging batch process with Snowflake data.
- Easy set up with sample queries - Procedures are integrated into the application, which is accessible via private sharing or the public marketplace. No coding is required. Consumers can securely install and run directly in their Snowflake instance with just a few clicks. Sample queries are provided with the native connector for guidance.
- Auto-sync to keep logic up to date - The automatic synchronization ensures the SQL functions work with the latest Spark models.
- Receive application updates instantly - The development team rolls out regular updates to improve the application's quality. Consumers who maintained an instance of the native application in their Snowflake platform will receive the update instantly without any work required.
Prerequisites
- Familiarity with Snowflake and basic SQL queries
What You'll Learn
By the end of this guide, you'll learn:
- how to install Spark Connector in your Snowflake environment.
- how to grant the needed permissions.
- how to synchronize your Spark services with Snowflake.
- how to use Spark services in Snowflake.
What You'll Need
- A Snowflake account
- Access to a Coherent Spark tenant, with at least one service uploaded. If you are not already a Coherent customer, please contact us!
What You'll Build
- A working installation of Spark Connector
- Database functions in Snowflake for each Spark Service in the folder you synchronize with
Additional Technical Information
Naming convention
Make sure model names and Xparameter names meet the Snowflake identifier requirements, otherwise, the synchronization process might fail.
A name:
- can contain up to 128 characters.
- must begin with a letter (A-Z, a-z) or an underscore (
_). - contains only letters, underscores (
_), decimal digits (0-9), and dollar signs ($). - can't be a reserved word in Snowflake such as WHERE or VIEW. For a complete list of reserved words, refer to the Snowflake documentation.
- can't be the same as another Snowflake object of the same type.
Supported/Unsupported Xservices
This table defines the active Xservices which are supported or not supported in the Snowflake native connector.
Spark model(s) using any Xservices defined below as "Not supported", might fail to be imported as Snowflake UDFs in the synchronization process, or the imported Snowflake UDFs might fail to return correct results.
This connector aims to support all Xservices available in Spark and this table will be updated regularly when there are new releases. It's always recommended to update the Snowflake native connector to the latest version.
Certain legacy Xservices are not included in this table and they will not be supported in the Snowflake connector unless further notice.
Xservices | Supported |
| YES |
| YES |
| YES |
| NO |
| YES |
| YES |
| NO |
| NO |
| NO |
| NO |
| NO |
| NO |
| NO |
| NO |
| NO |
Table last updated: 3rd June 2023.
Download from Private Sharing
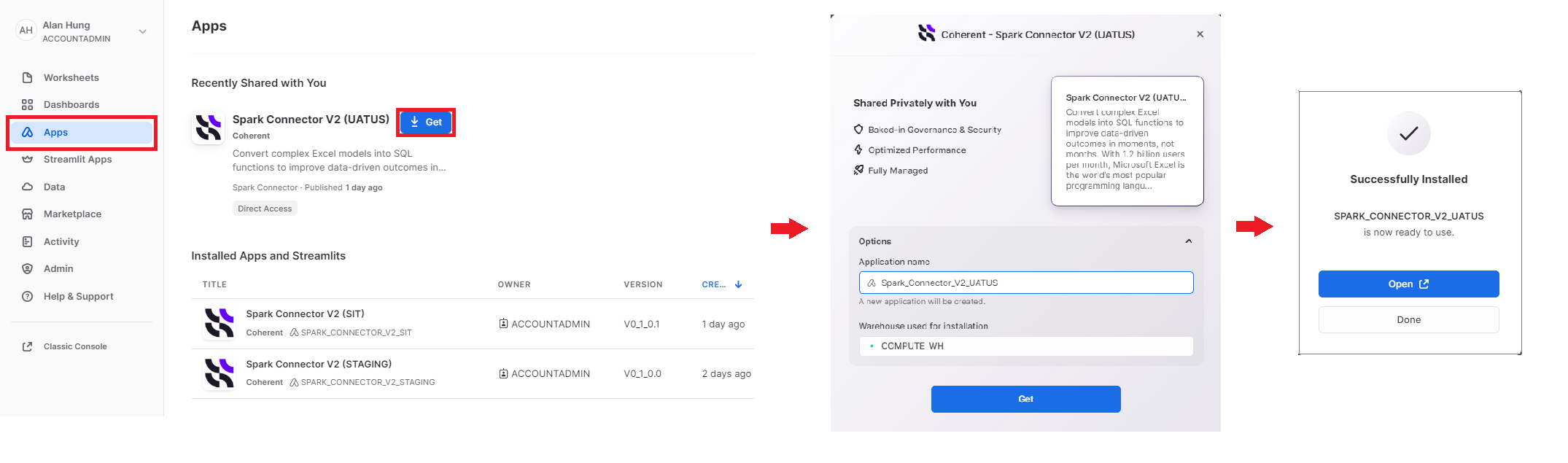
- Sign into the Snowflake platform.
- Go to "Apps" on the left panel and "Spark Connector' should appear under "Shared with you" if the Snowflake account is given access to the private application. Click the application widget to visit the full information page.
- Click "Get" to open the installation pop up.
- Select your preferred installation options (database name, account role for access) and then click "Get" again. Spark Connector will be installed in the consumer platform.
- Once Spark Connector is successfully installed, click "Open" to begin.
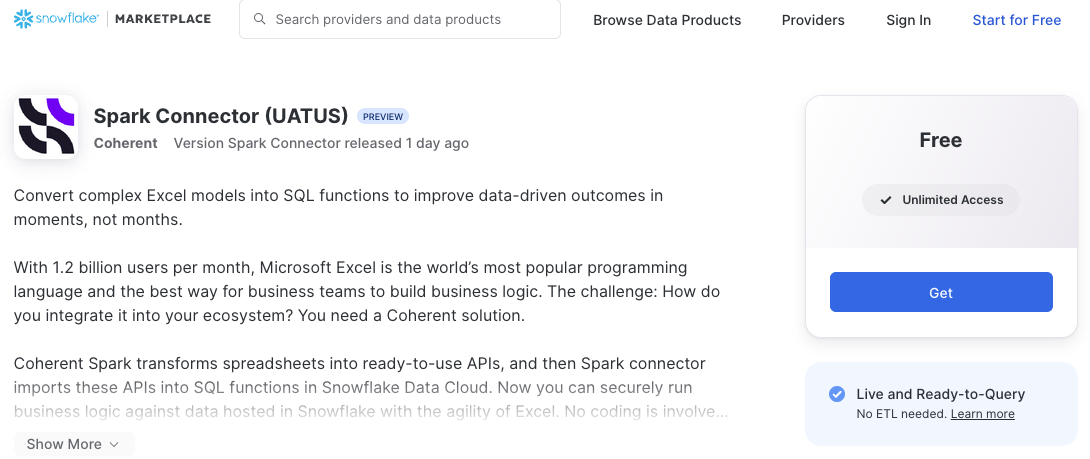
Download from Public Marketplace
- Go to our Marketplace listing or search for "Spark Connector" in the Marketplace.
- Click "Get" to open the installation pop up.
- Select your preferred installation options (database name, account role for access) and then click "Get" again. Spark Connector will be installed in the consumer platform.
- Once Spark Connector is successfully installed, click "Open" to begin.
Review the installed application in the consumer platform
- Clicking "Get" will bring users into the SQL query layout, with the database/application list on the left panel. Spark Connector is displayed in the database list, but it has a distinct icon that sets it apart from other databases or legacy native applications (V1).
- Snowflake will create a new worksheet with sample queries to help the user to operate with the Spark Connector.
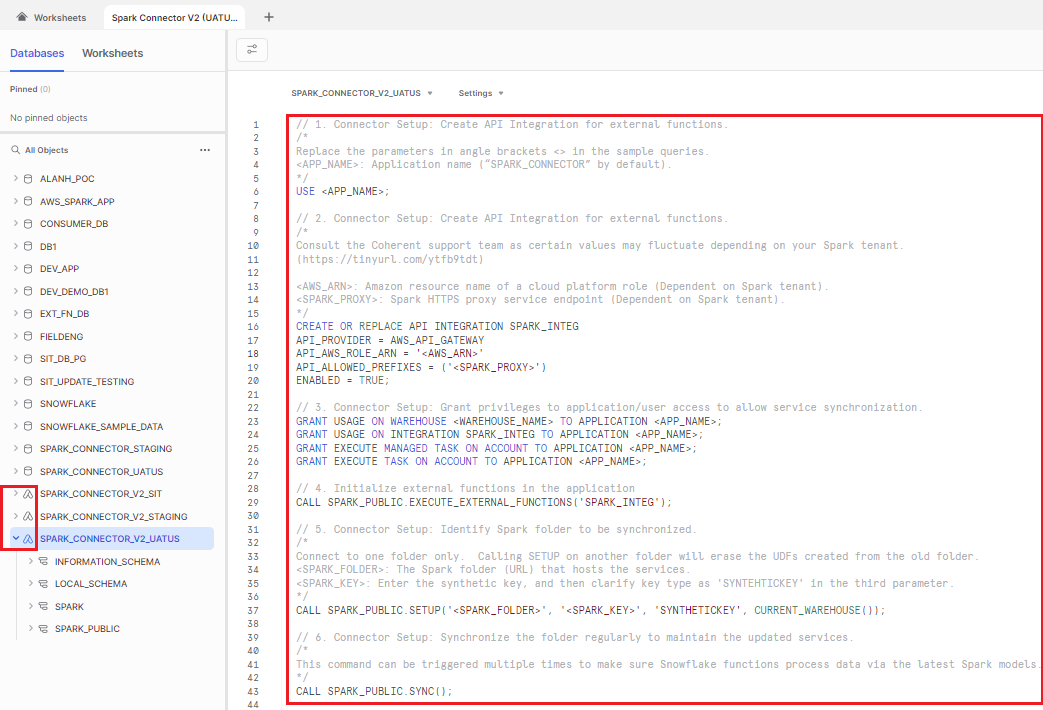
1. Specify the active application for the session.
Replace the parameters in the curly brackets { } in the SQL queries, then execute in the Snowflake environment.
{APP_NAME}: Application name ("SPARK_CONNECTOR" by default).
USE {APP_NAME};
2. Create API Integration for external functions.
Create and configure API integration based on the specific Snowflake native application you are operating.
{AWS_ARN}: Amazon resource name of a cloud platform role.
Spark Connector (UATUS)
Parameters | Configuration for Spark Connector (UATUS) |
arn:aws:iam::533606394992:role/Snowflake-WASM-Server-Invoker | |
https://ymeen1pkt6.execute-api.us-east-1.amazonaws.com |
Spark Connector (PRODUS)
Parameters | Configuration for Spark Connector (PRODUS) |
(Coming soon...) | |
(Coming soon...) |
CREATE OR REPLACE API INTEGRATION SPARK_INTEG
API_PROVIDER = AWS_API_GATEWAY
API_AWS_ROLE_ARN = '{AWS_ARN}'
API_ALLOWED_PREFIXES = ('{SPARK_PROXY}')
ENABLED = TRUE;
3. Grant privileges to application/user access to allow service synchronization.
GRANT USAGE ON WAREHOUSE {WAREHOUSE_NAME} TO APPLICATION {APP_NAME};
GRANT USAGE ON INTEGRATION SPARK_INTEG TO APPLICATION {APP_NAME};
4. Initialize external functions in the application.
CALL SPARK_PUBLIC.EXECUTE_EXTERNAL_FUNCTIONS('SPARK_INTEG');
5. Identify the Spark folder to be synchronized.
{SPARK_FOLDER}: The Spark folder (URL) that hosts the services.
{SPARK_KEY}: Enter the synthetic key, and then clarify key type as ‘SYNTHETICKEY' in the third parameter.
CALL SPARK_PUBLIC.SETUP('{SPARK_FOLDER}', '{SPARK_KEY}', 'SYNTHETICKEY', CURRENT_WAREHOUSE());
Synchronize the folder regularly to maintain the updated services.
CALL SPARK_PUBLIC.SYNC();
Synchronize multiple versions of a single Spark service.
{SERVICE_NAME}: The service name as presented in the Spark platform.
CALL SPARK_PUBLIC.SYNC('{SERVICE_NAME}');
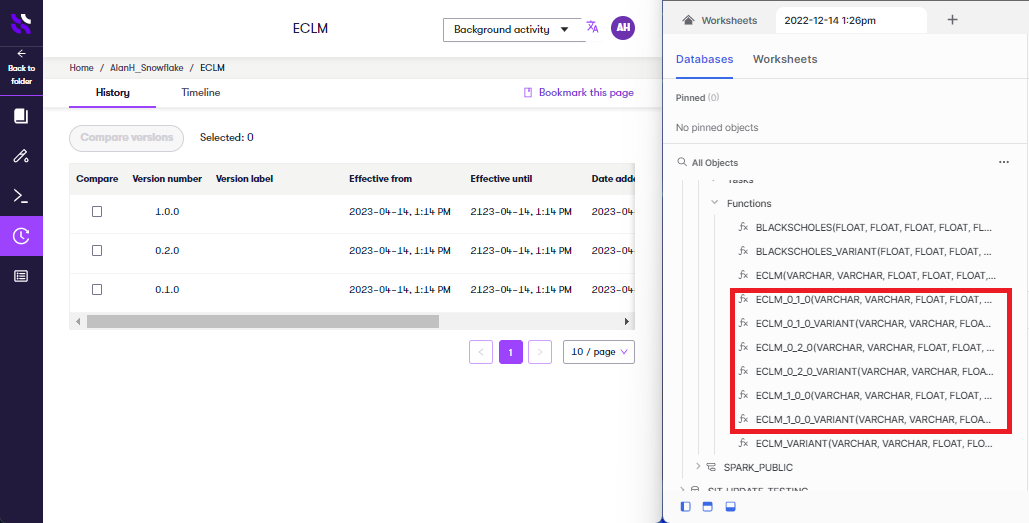
For each version of each service in a synchronized folder, you will see two database functions, one called {SERVICE_NAME} and one called {SERVICE_NAME}_VARIANT. You'll learn how to use these in the next step.
The two database functions operate in different modes:
{SERVICE_NAME}(Parameters): Returns results in a tabular format.
Query a single set of parameters
SELECT Delta, Gamma, Rho, Theta, Vega FROM TABLE
(SPARK.BLACKSCHOLES(90::float,0.5::float,0.9::float,56::float,0.5::float));
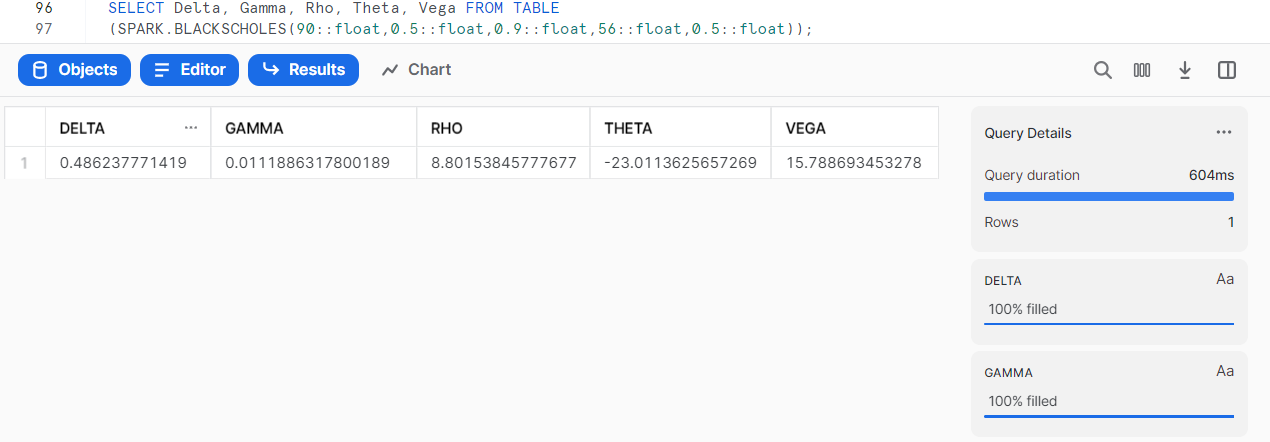
Process a table of data.
SELECT input.id,input.excercisePrice, input.risklessRate, input.stdDevi, input.stockPrice, input.timeToExpiry,output.*
FROM {TABLE_NAME} input
JOIN TABLE(SPARK.BLACKSCHOLES(
input.excercisePrice,
input.risklessRate,
input.stdDevi,
input.stockPrice,
input.timeToExpiry)) output

{SERVICE_NAME}_VARIANT(Parameters): Returns results in raw JSON format.
SELECT SPARK.BLACKSCHOLES_VARIANT(90, 0.5, 0.9, 56, 0.5);
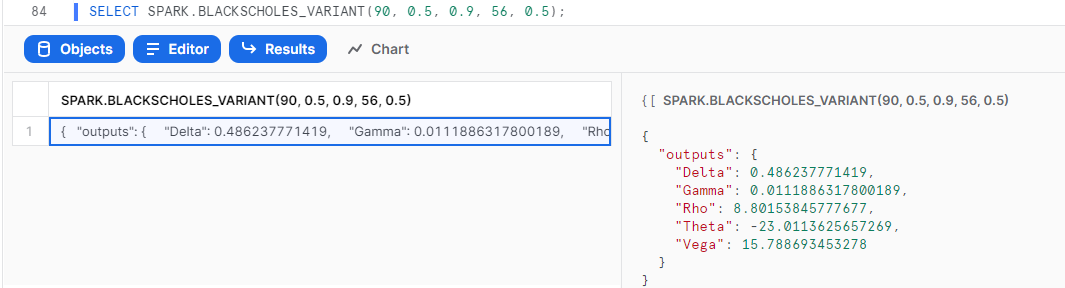
Congratulations, you're now all set up to call your Spark services from your Snowflake environment! This means you can take business logic written in Excel, upload it to Spark, and immediately use it on all of your data in Snowflake via API, no coding needed!
You can find out more about Coherent Spark on our homepage or read up about other features in our documentation.
What we've covered
- Installing Spark Connector
- Adding permissions
- Synchronizing your services
- Using Spark services in Snowflake
FAQs
1. Can I execute Spark functions against the data from another database?
Functions imported in the Spark synchronization process are ready for cross-database access. Snowflake users can execute Spark functions against the data from another database in the same cloud warehouse when the query contains the full naming conversion, for example: database.schema.function-name / database.schema.procedure-name).
SELECT SPARK_CONNECTOR.SPARK.BLACKSCHOLES_VARIANT(90, 0.5, 0.9, 56, 0.5);
2. How is my Snowflake data kept safe when using the synchronized Spark functions?
The Spark connector relies on the Spark API endpoint, which means that data from Snowflake will be taken into the Spark server for processing. All UDFs generated from the Spark connector setup process follow Snowflake's advice on ensuring the entire data transition is implemented in the secured environment. The UDF owner must grant callers appropriate privilege(s) on the UDF access and usage. Snowflake users need to provide subscription information (API key) when calling the Spark proxy service. For more information, please refer to Snowflake's documentation on external function security.