This Hands-On Lab exercise is designed to help you learn how to build and manage Iceberg tables with Snowflake Cortex LLM nodes within Coalesce. In this lab, you'll explore the Coalesce interface, load Iceberg tables into your project, learn how to easily transform and model your data with our core capabilities, and use the Cortex LLM functions node that Coalesce provides users.
Prerequisites
- A basic understanding of SQL
What You'll Learn
- How to navigate the Coalesce interface
- Load in iceberg tables
- How to add data sources to your graph
- How to prepare your data for transformations with Stage nodes
- How to union tables
- How to set up and configure Cortex LLM Nodes
- How to analyze the output of your results in Snowflake
What You'll Need
- A Snowflake trial account
- A Coalesce trial account created via Snowflake Partner Connect
- Basic knowledge of SQL, database concepts, and objects
- The Google Chrome browser
What You'll Build
- A Directed Acyclic Graph (DAG) that builds an Cortex LLM Pipeline which leverages Iceberg tables
To complete this lab, please create free trial accounts with Snowflake and Coalesce by following the steps below. You have the option of setting up Git-based version control for your lab, but this is not required to perform the following exercises. Please note that none of your work will be committed to a repository unless you set Git up before developing.
We recommend using Google Chrome as your browser for the best experience.
Note: Not following these steps will cause delays and reduce your time spent in the Coalesce environment! |
Step 1: Create a Snowflake Trial Account
- Fill out the Snowflake trial account form here. Use an email address that is not associated with an existing Snowflake account.
- When signing up for your Snowflake account, select AWS as the cloud provider and either Oregon (us-west-2) or Ohio (us-east-2) and choose Enterprise as your Snowflake edition. Remember which region you set up your trial account in.
- After registering, you will receive an email from Snowflake with an activation link and URL for accessing your trial account. Finish setting up your account following the instructions in the email.
Step 2: Create a Coalesce Trial Account with Snowflake Partner Connect
Once you are logged into your Snowflake account, sign up for a free Coalesce trial account using Snowflake Partner Connect. Check your Snowflake account profile to make sure that it contains your fist and last name.
Once you are logged into your Snowflake account, sign up for a free Coalesce trial account using Snowflake Partner Connect. Check your Snowflake account profile to make sure that it contains your fist and last name.
- Select Data Products > Partner Connect in the navigation bar on the left hand side of your screen and search for Coalesce in the search bar.
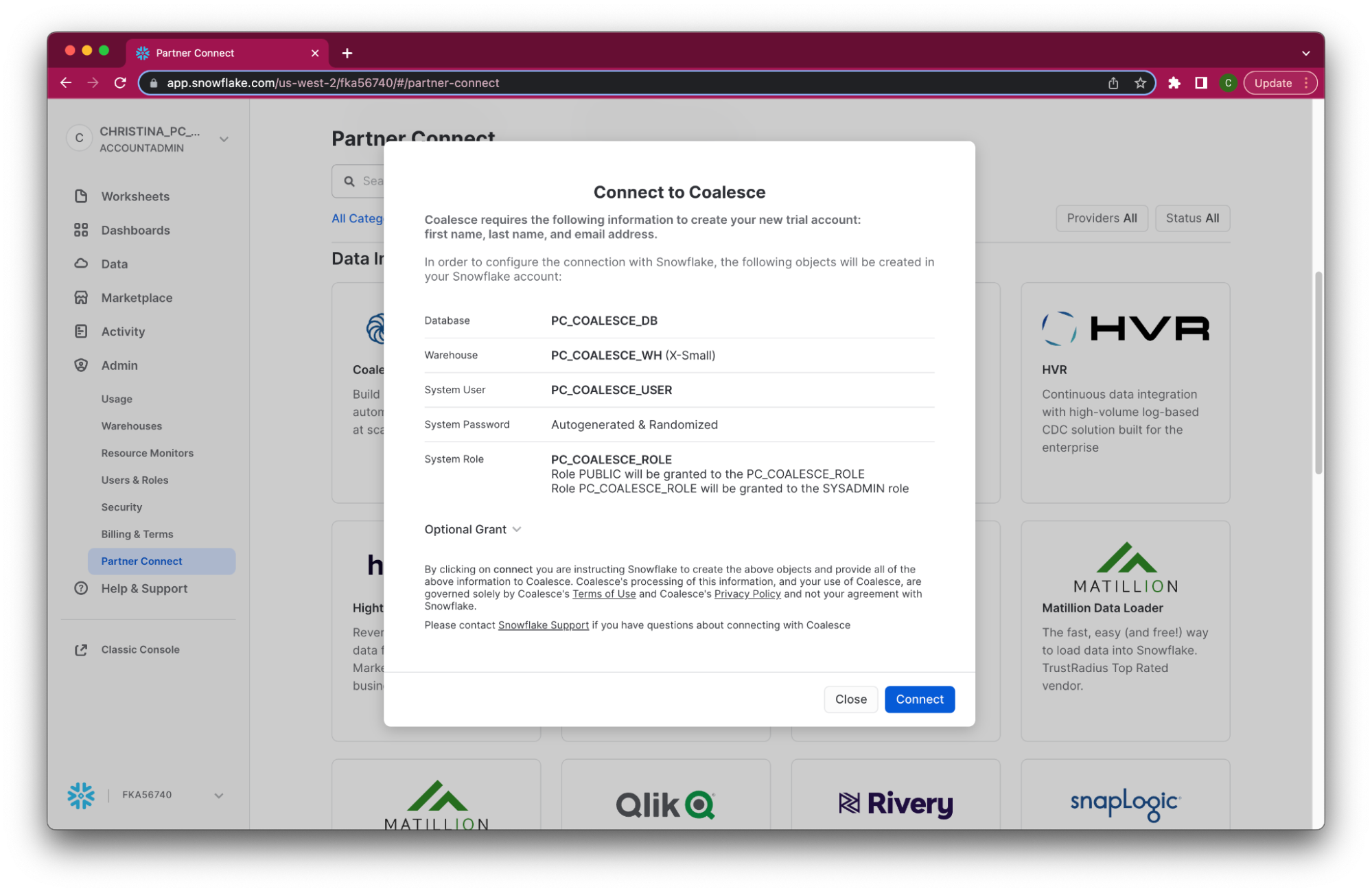
- Review the connection information and then click Connect.
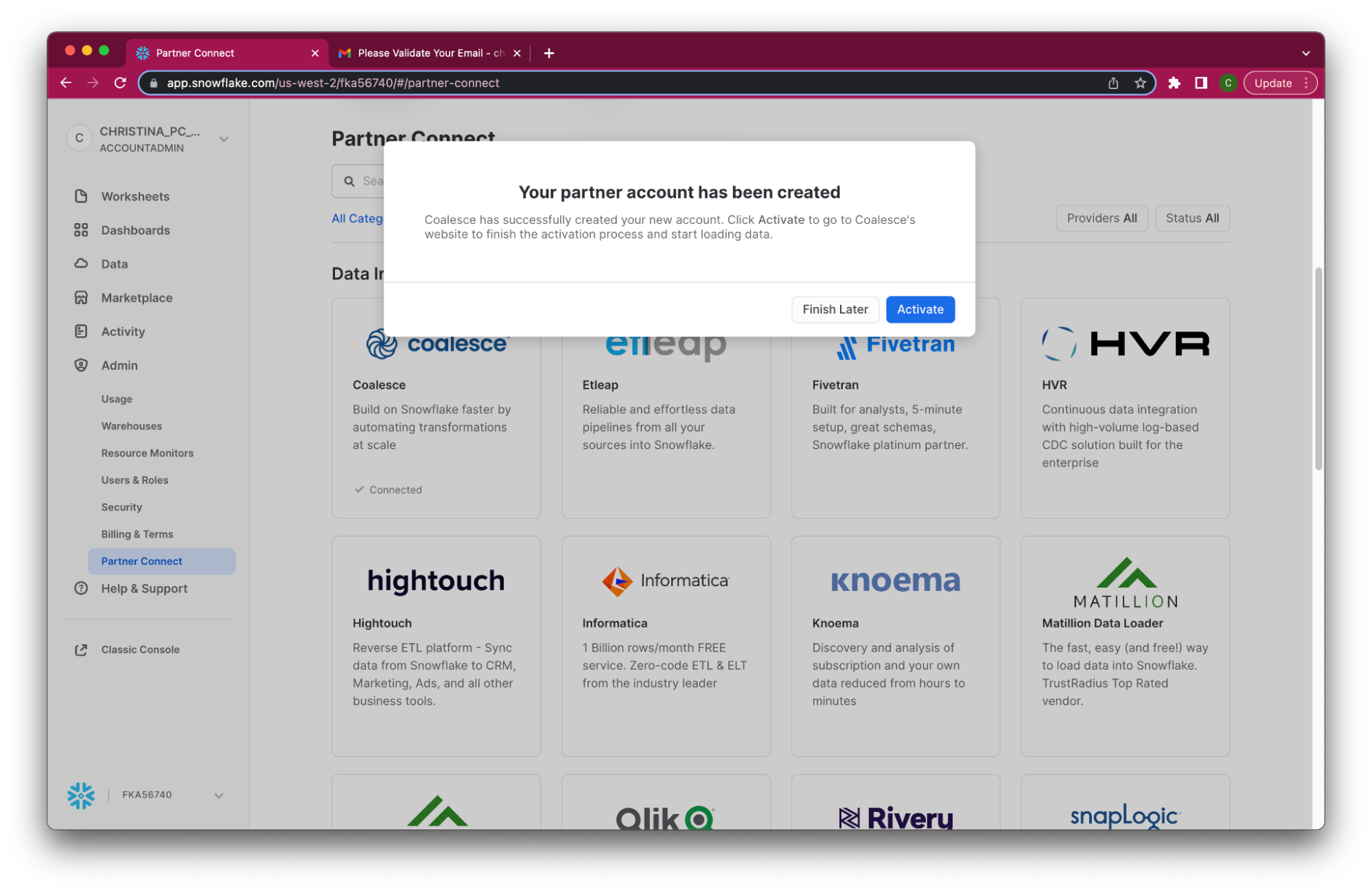
- When prompted, click Activate to activate your account. You can also activate your account later using the activation link emailed to your address.
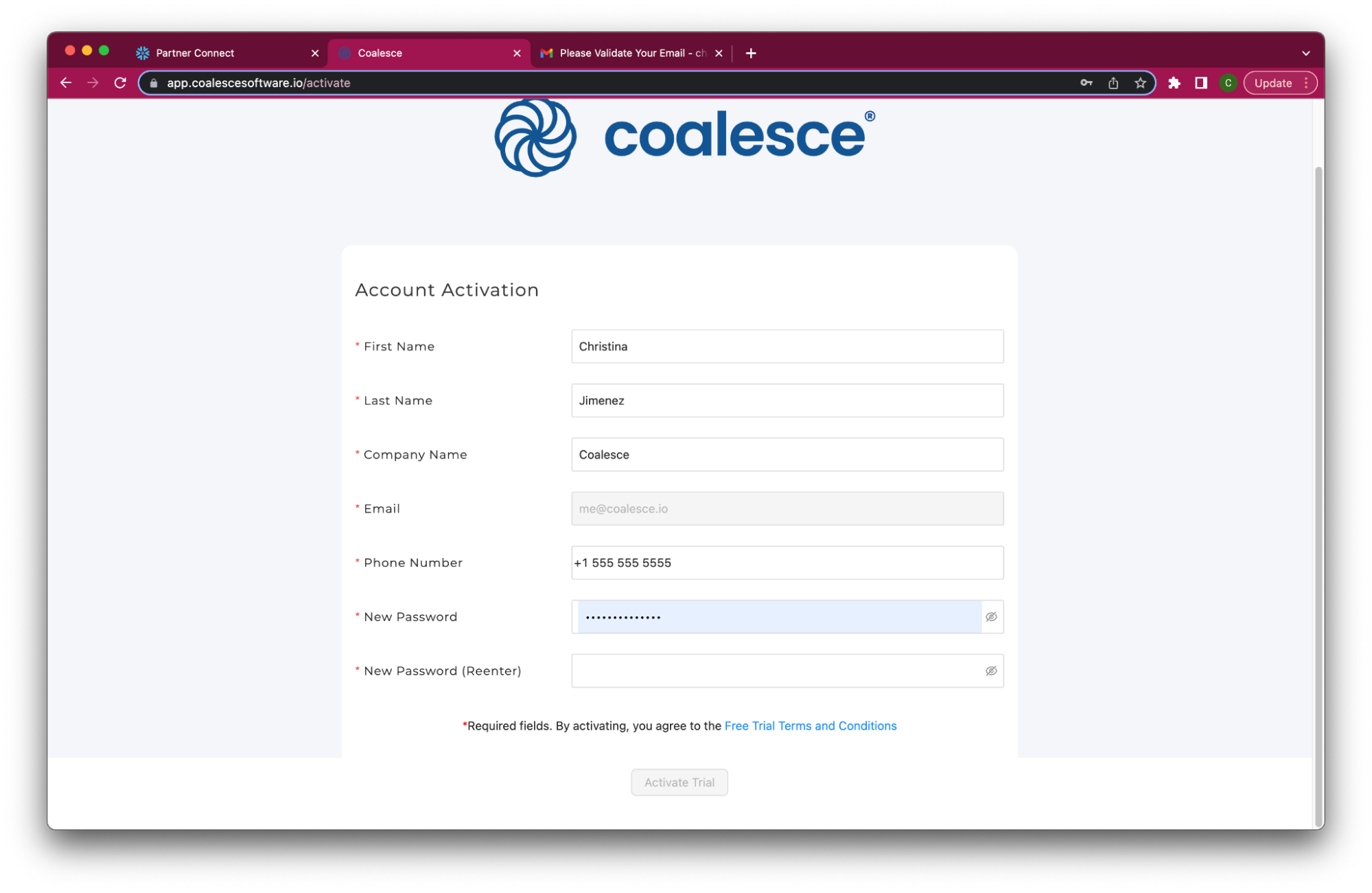
- Once you've activated your account, fill in your information to complete the activation process.
Congratulations! You've successfully created your Coalesce trial account.
Step 3: Set Up External Volume and Catalog Integration
We will be using a dataset from a public S3 bucket for this lab. The bucket has been provisioned so that any Snowflake account can access the dataset. In order to use Iceberg tables, you are required to set up an external integration as well as a catalog integration. This step will walk you through how to do this.
- Within Worksheets, click the "+" button in the top-right corner of Snowsight and choose "SQL Worksheet."
- If you set up your Snowflake trial account in the Oregon (us-west-2) region, you can copy and paste the following code into your worksheet. Ensure you are using the ACCOUNTADMIN role in Snowflake for this process.
CREATE OR REPLACE EXTERNAL VOLUME iceberg_external_volume
STORAGE_LOCATIONS =
(
(
NAME = 'us-west-2'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://iceberg-hol-west/'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::034362027654:role/iceberg-hol-role'
STORAGE_AWS_EXTERNAL_ID = 'iceberg-hol'
)
);
CREATE OR REPLACE CATALOG INTEGRATION iceberg_catalog_integration
CATALOG_SOURCE = OBJECT_STORE
TABLE_FORMAT = ICEBERG
ENABLED = TRUE;
GRANT USAGE ON EXTERNAL VOLUME iceberg_external_volume TO ROLE pc_coalesce_role;
GRANT USAGE ON INTEGRATION iceberg_catalog_integration TO ROLE pc_coalesce_role;
3. If you set up your Snowflake trial account in the Ohio (us-east-2) region, you can copy and paste the following code into your worksheet. Ensure you are using the ACCOUNTADMIN role in Snowflake for this process.
CREATE OR REPLACE EXTERNAL VOLUME iceberg_external_volume
STORAGE_LOCATIONS =
(
(
NAME = 'us-east-2'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://iceberg-hol-east/'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::034362027654:role/iceberg-role-east'
STORAGE_AWS_EXTERNAL_ID = 'iceberg-hol-east'
)
);
CREATE OR REPLACE CATALOG INTEGRATION iceberg_catalog_integration
CATALOG_SOURCE = OBJECT_STORE
TABLE_FORMAT = ICEBERG
ENABLED = TRUE;
GRANT USAGE ON EXTERNAL VOLUME iceberg_external_volume TO ROLE pc_coalesce_role;
GRANT USAGE ON INTEGRATION iceberg_catalog_integration TO ROLE pc_coalesce_role;
- You have now successfully set up an external volume and catalog integration.
About this lab: Screenshots (product images, sample code, environments) depict examples and results that may vary slightly from what you see when you complete the exercises. This lab exercise does not include Git (version control). Please note that if you continue developing in your Coalesce account after this lab, none of your work will be saved or committed to a repository unless you set up before developing. |
Let's get familiar with Coalesce by walking through the basic components of the user interface.
Once you've activated your Coalesce trial account and logged in, you will land in your Projects dashboard. Projects are a useful way of organizing your development work by a specific purpose or team goal, similar to how folders help you organize documents in Google Drive.
Your trial account includes a default Project to help you get started.
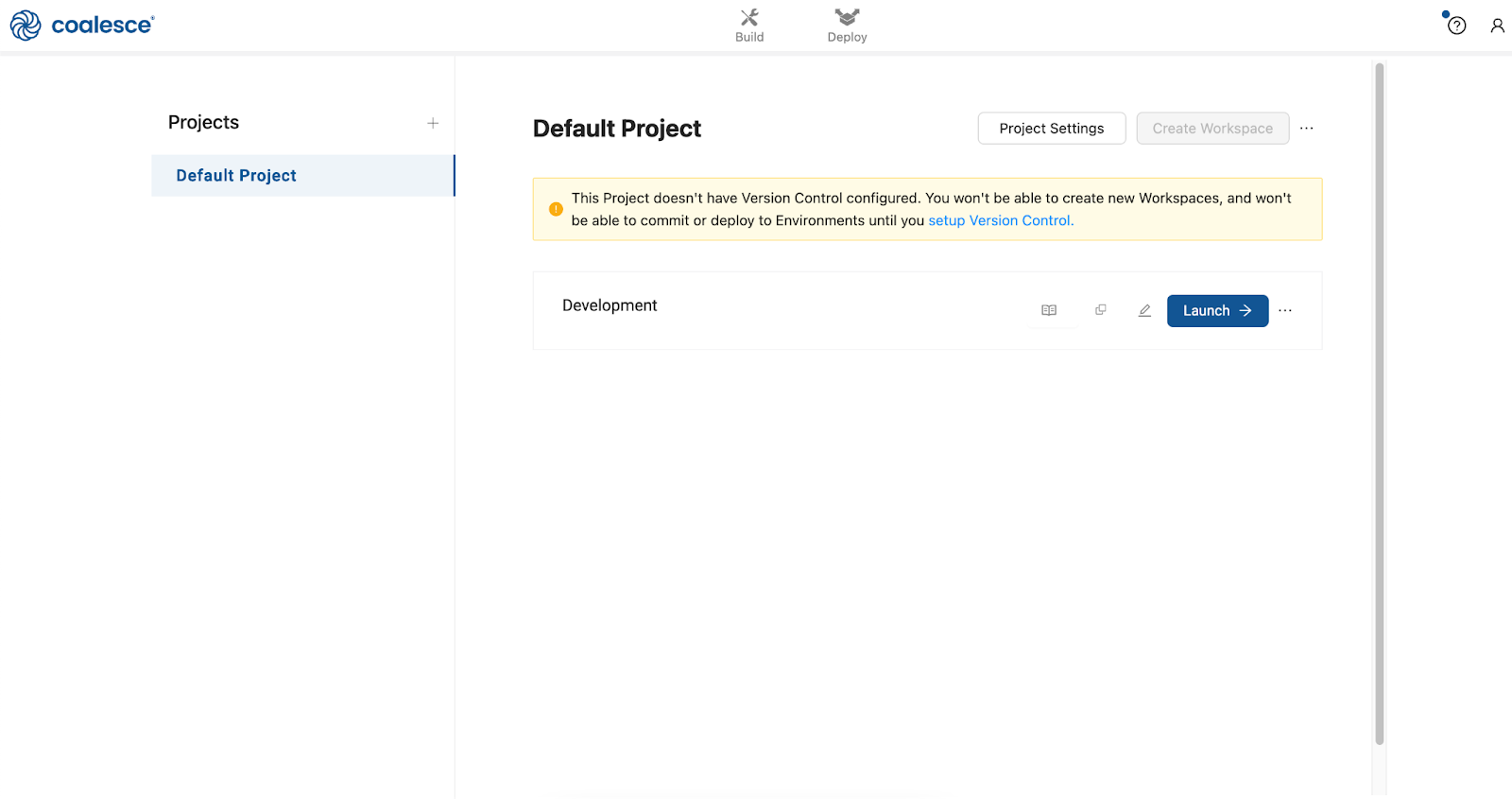
- Launch your Development Workspace by clicking the Launch button and navigate to the Build Interface of the Coalesce UI. This is where you can create, modify and publish nodes that will transform your data.Nodes are visual representations of objects in Snowflake that can be arranged to create a Directed Acyclic Graph (DAG or Graph). A DAG is a conceptual representation of the nodes within your data pipeline and their relationships to and dependencies on each other.
- In the Browser tab of the Build interface, you can visualize your node graph using the Graph, Node Grid, and Column Grid views. In the upper right hand corner, there is a person-shaped icon where you can manage your account and user settings.
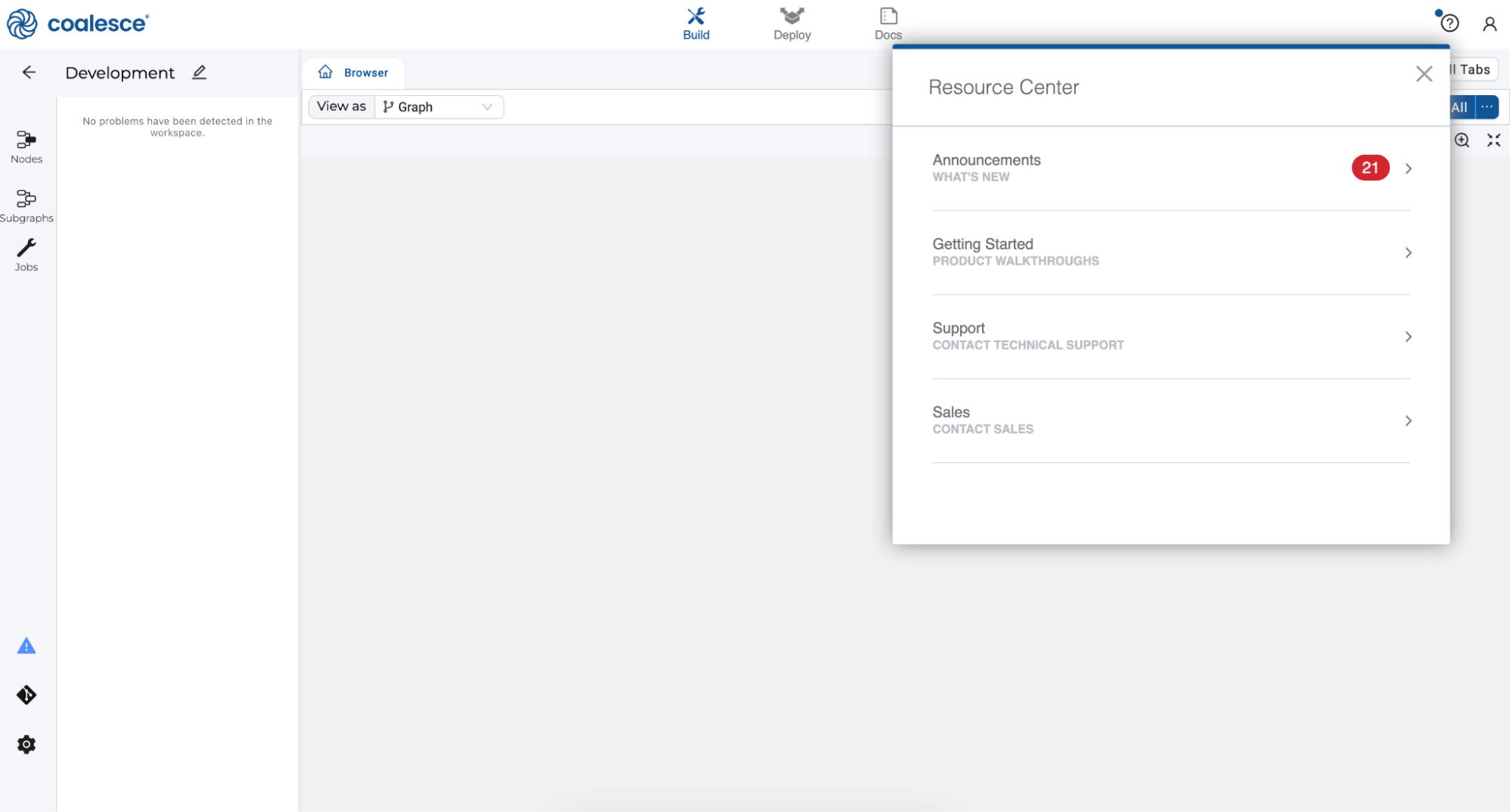
- By clicking the question mark icon, you can access the Resource Center to find product guides, view announcements, request support, and share feedback.
- The Browser tab of the Build interface is where you'll build your pipelines using nodes. You can visualize your graph of these nodes using the Graph, Node Grid, and Column Grid views. While this area is currently empty, we will build out nodes and our Graph in subsequent steps of this lab.
- Next to the Build interface is the Deploy interface. This is where you will push your pipeline to other environments such as Testing or Production.
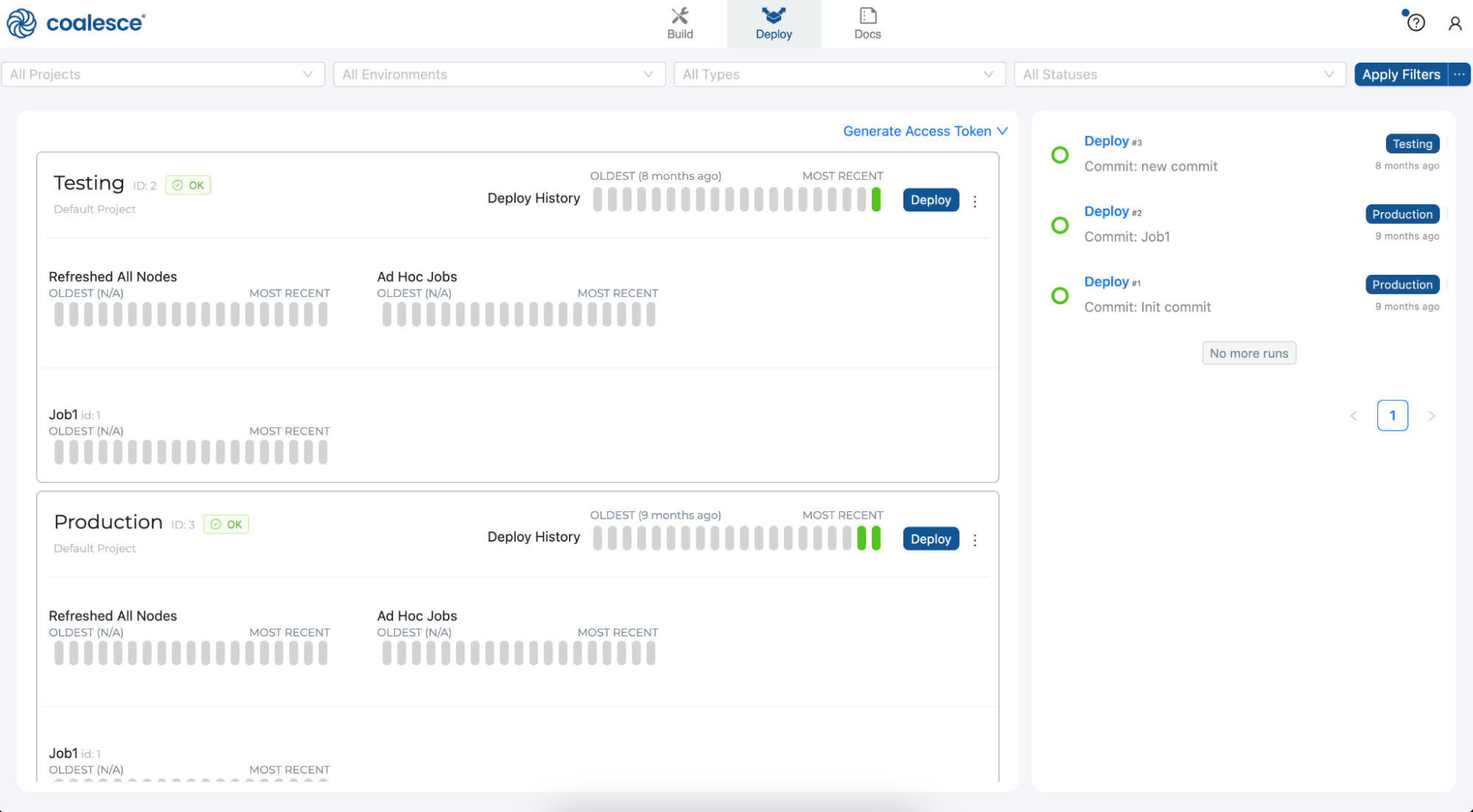
- Next to the Deploy interface is the Docs interface. Documentation is an essential step in building a sustainable data architecture, but is sometimes put aside to focus on development work to meet deadlines. To help with this, Coalesce automatically generates and updates documentation as you work.
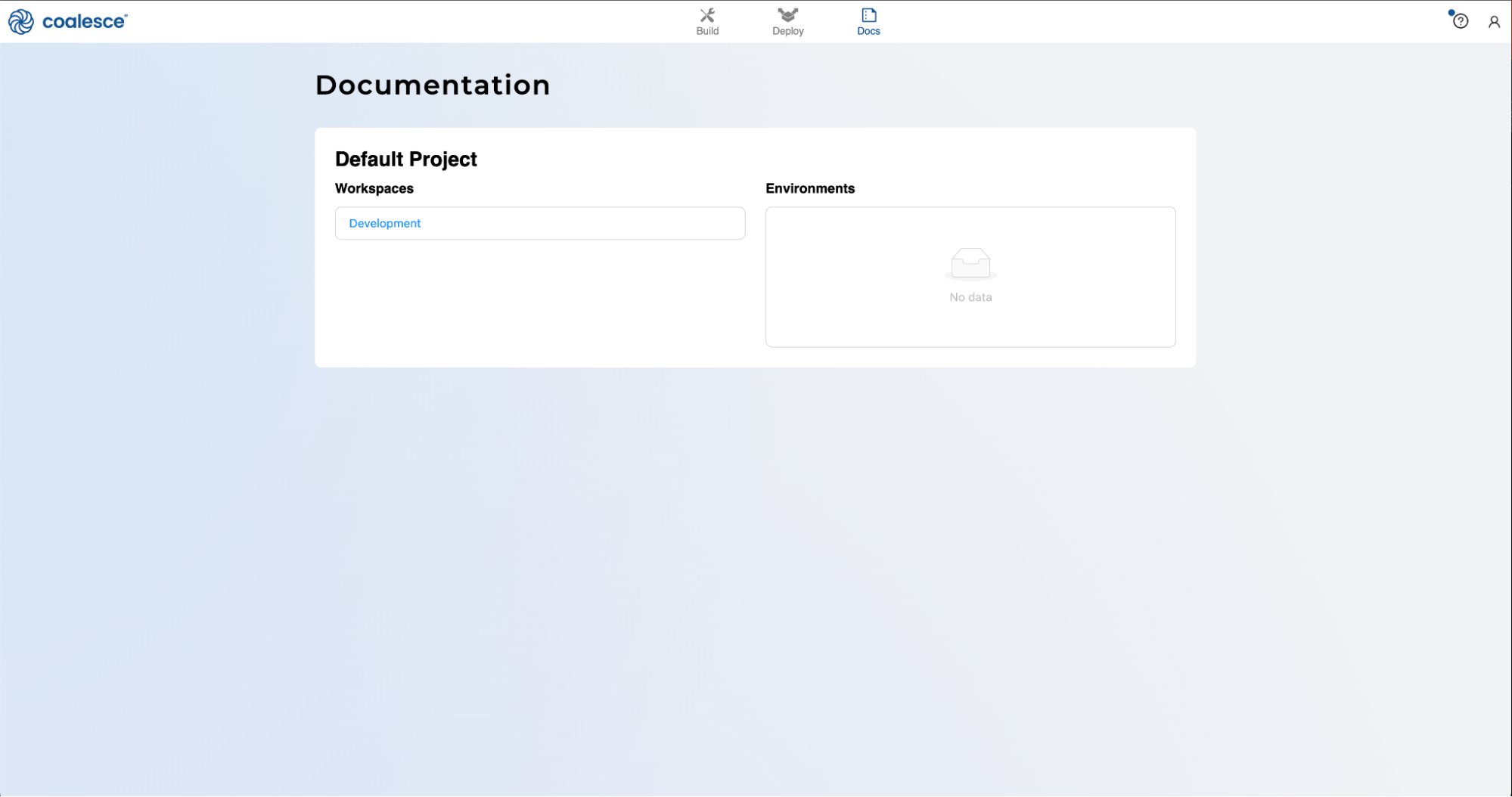
In order to leverage Iceberg table functionality, we need to add Iceberg table nodes to our workspace. Using Coalesce Marketplace, we can easily install Iceberg nodes that will be immediately available to use, which will allow us to read in and manage data in Iceberg table format. Additionally, we will be working with a dataset that contains multiple languages in the form of call transcripts. We want to explore these transcripts further using Cortex LLM functions, so we'll need to use the Cortex package from Coalesce Marketplace.
- In the build interface, navigate to the build settings in the lower left corner of the screen.
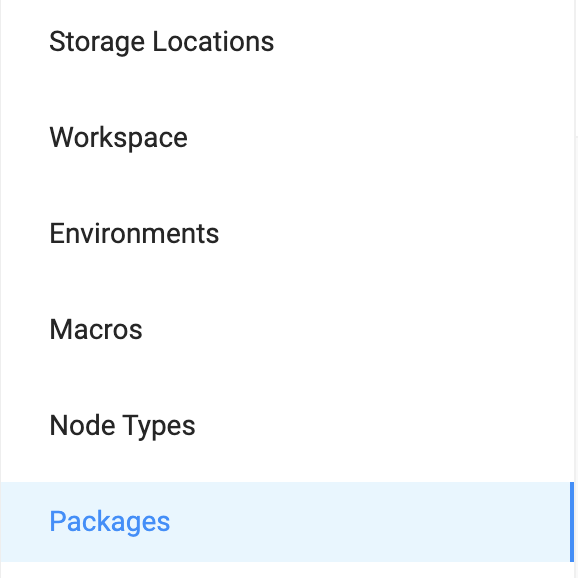
- Select Packages from the menu list presented.
- Select the Browse button in the upper right corner of the screen. This will open a new tab for Coalesce Marketplace.
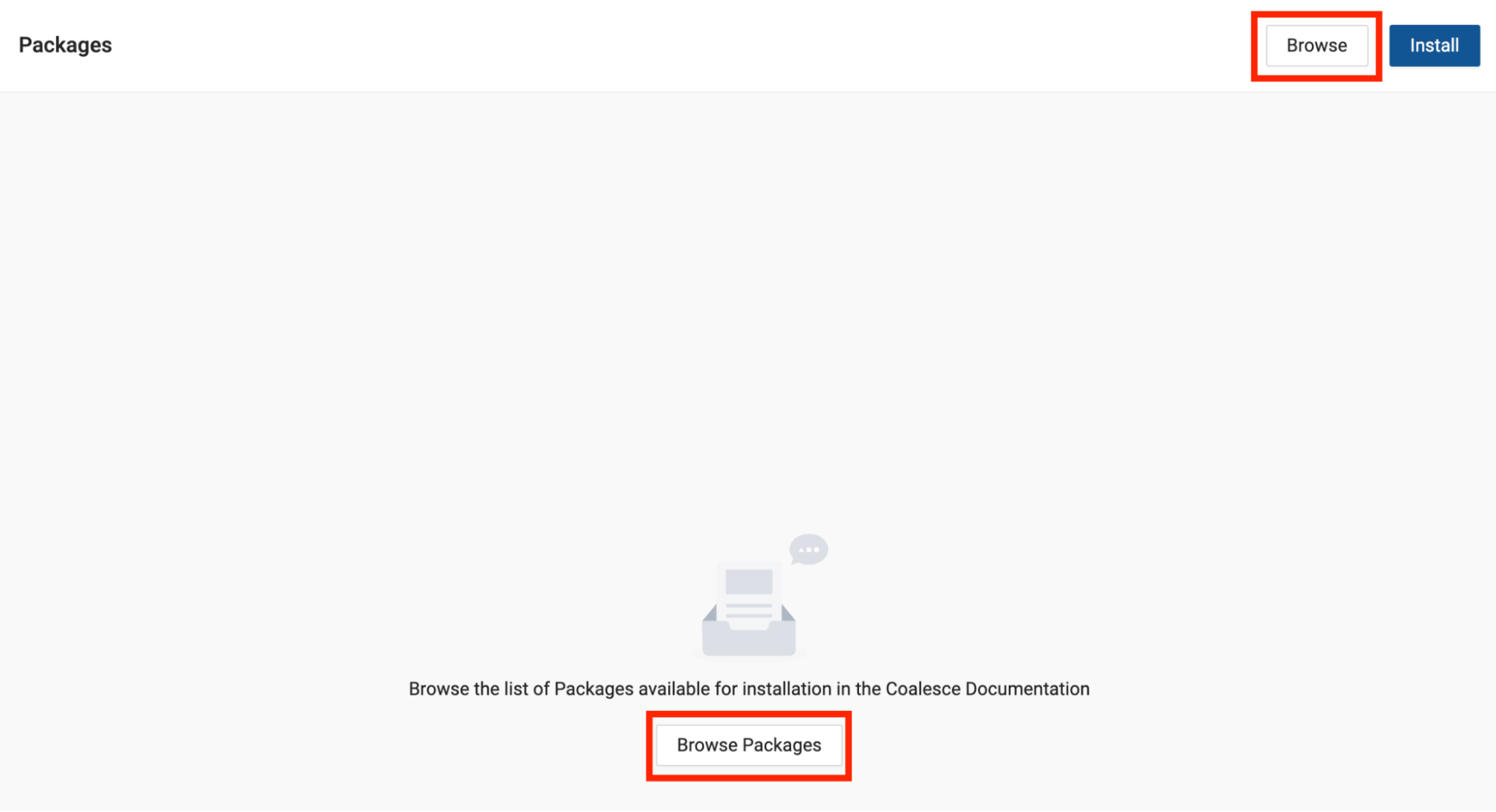
- Navigate to the Iceberg package and select "Find out more"
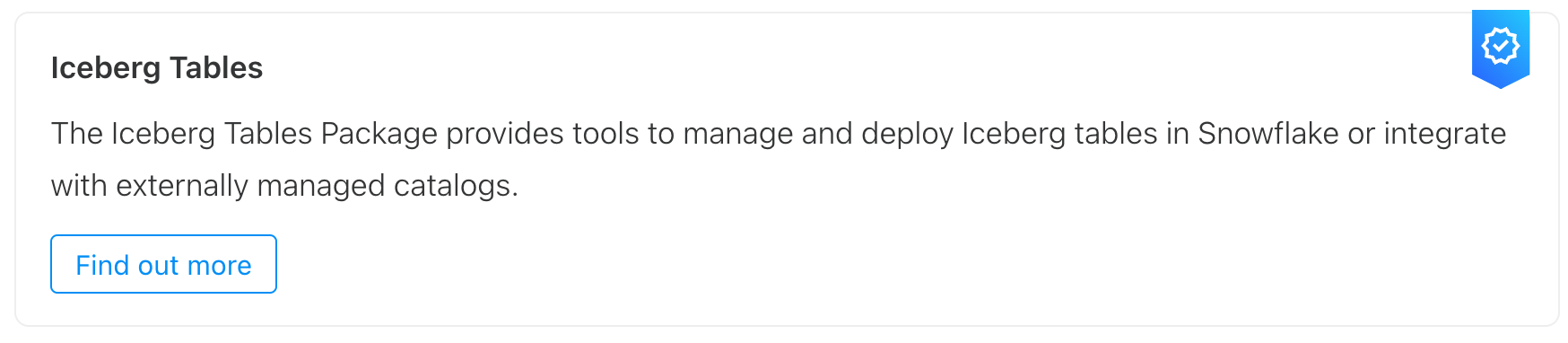
- In the package details, find the Package ID and copy it.

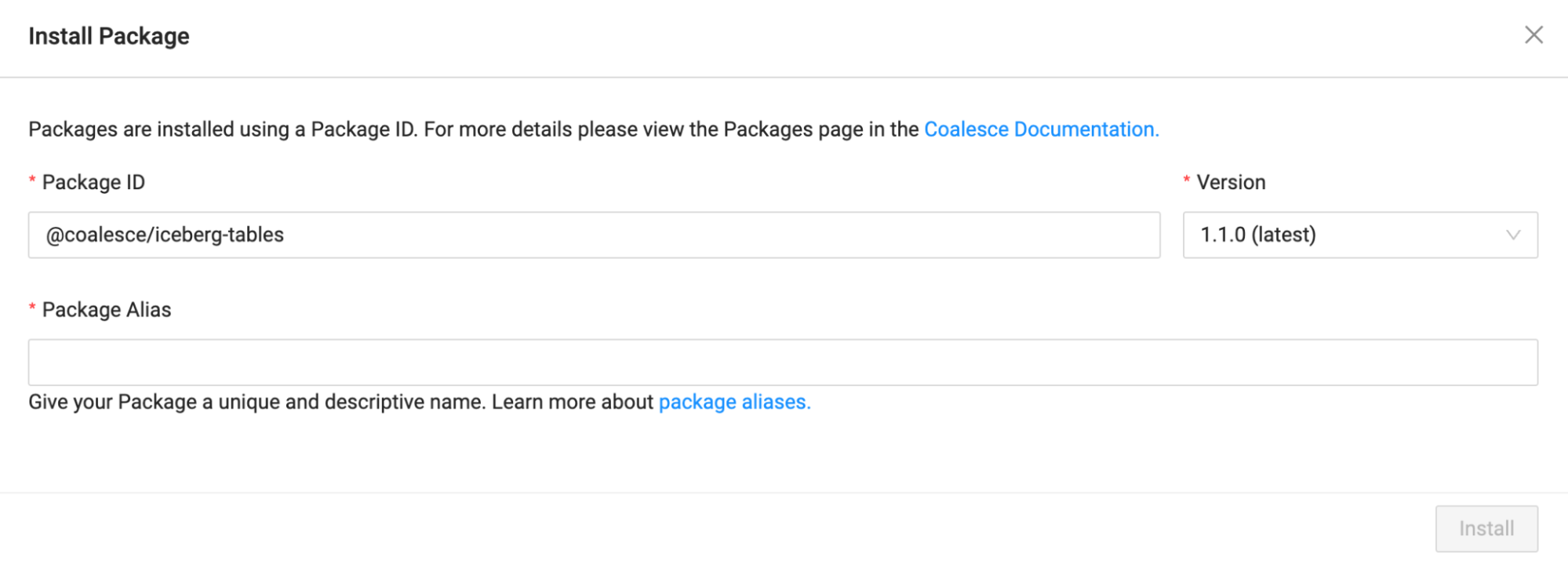
- Navigate back to Coalesce and select the Install button in the upper right corner of the screen.

- Paste in the Package ID into the Install Package modal. Coalesce will automatically select the most recent version of the package.
- Provide a Package Alias. The Package Alias will be the name of the package as it is displayed within the Build Interface of Coalesce. In this case, we'll call the package Iceberg.
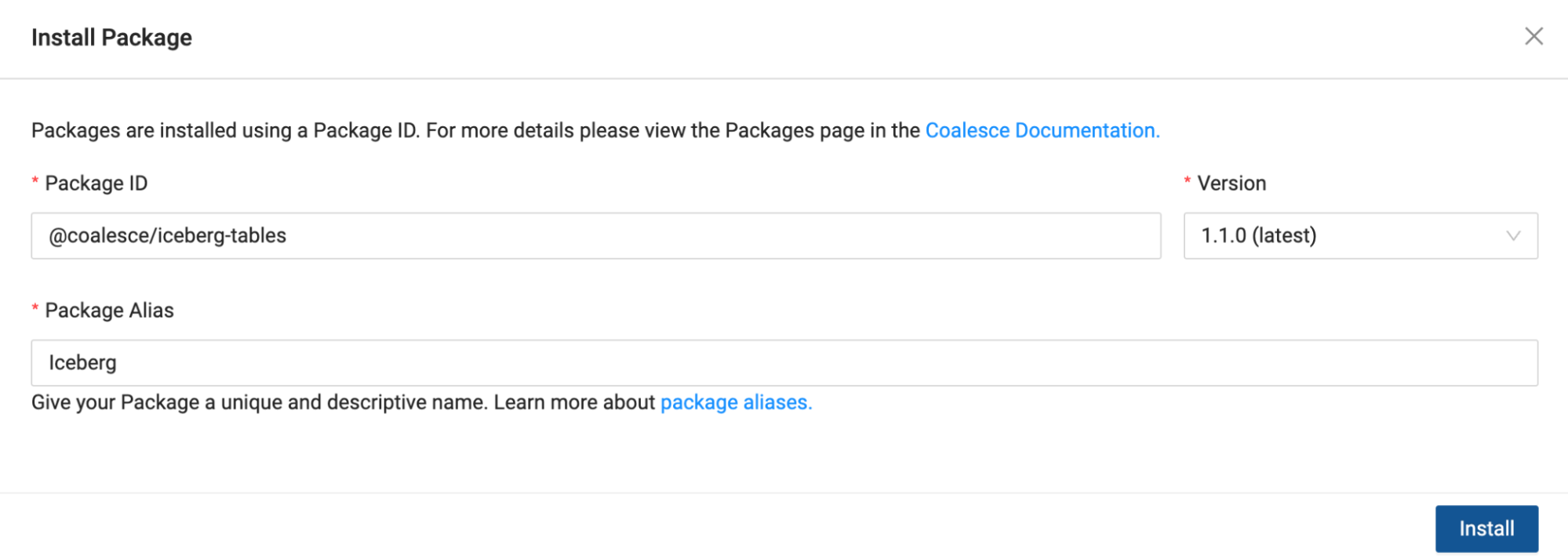
- Select Install once you have filled out all of the information in the modal.

- Repeat these steps to install the Cortex Package and call the Package Alias CortexML.
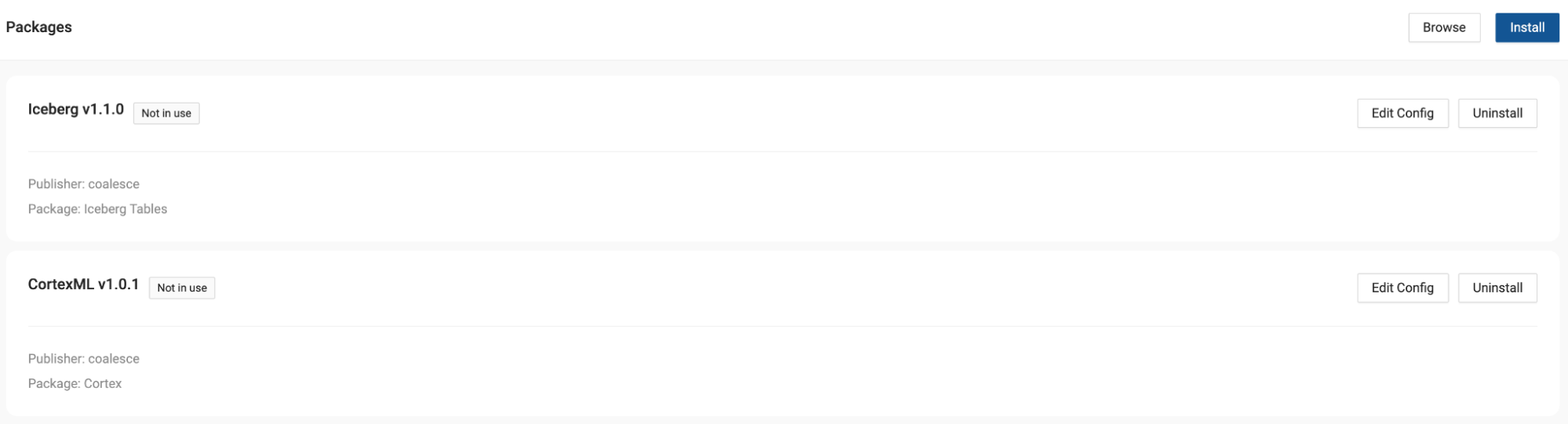
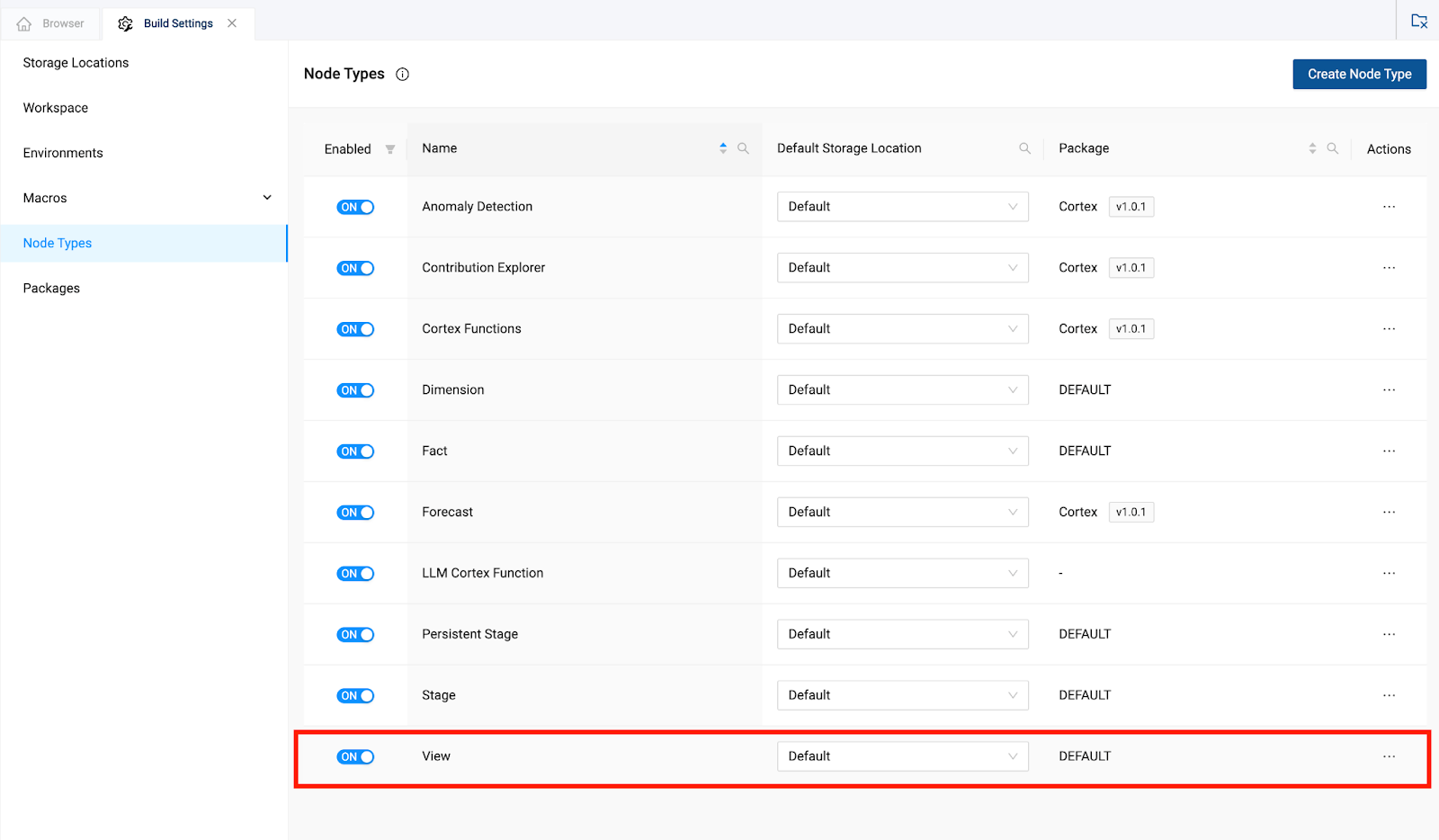
- Finally, navigate to Node Types in the build settings and toggle on View. You will need this in a later step.
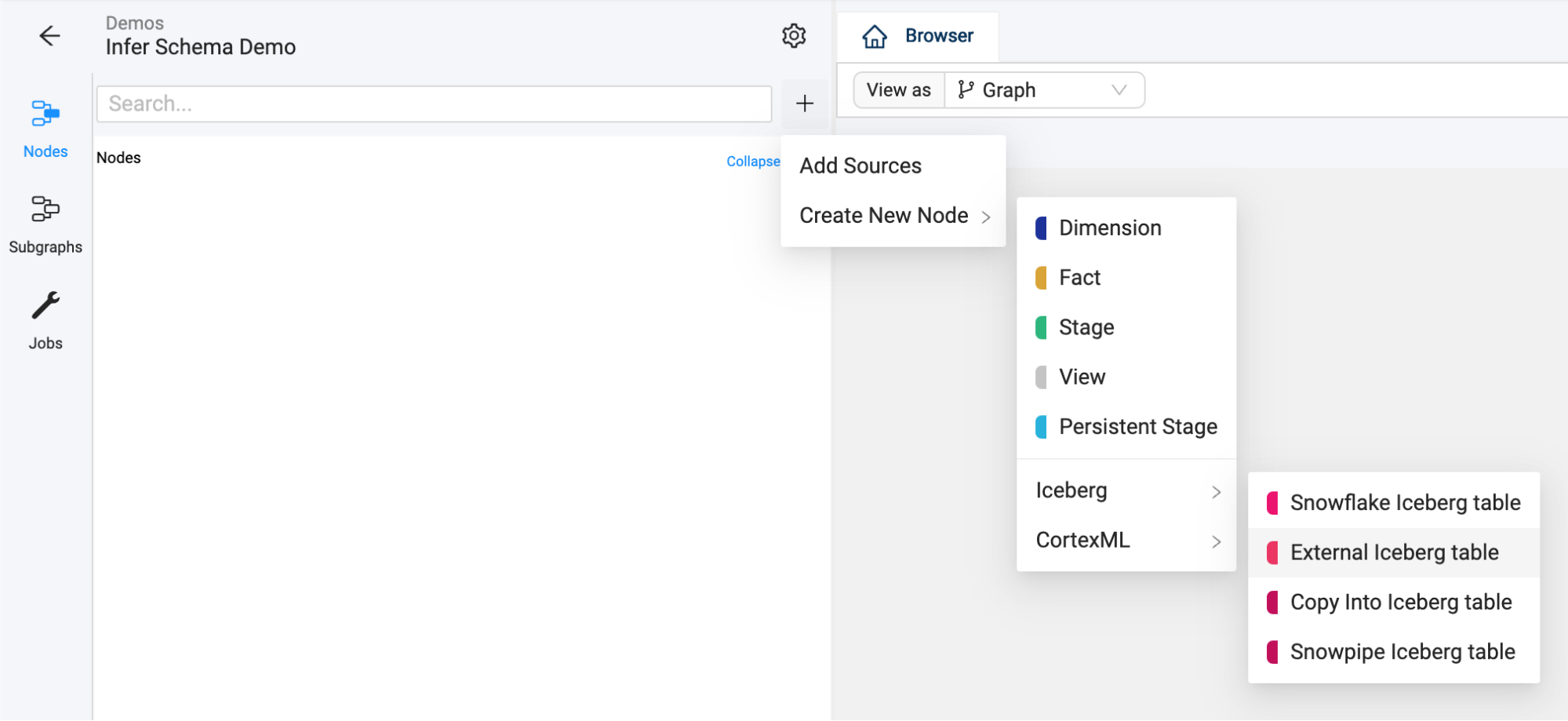
Let's start to build the foundation of your LLM data pipeline by creating a Graph (DAG) and adding data in the form of Iceberg Tables.
- Start in the Build interface and click on Nodes in the left sidebar (if not already open). Click the + icon and navigate to Create New Node → Iceberg → External Iceberg Table.
- Coalesce will automatically open the Iceberg node which we can configure using the information from the SQL we ran in section 4 of the lab guide. Select the Iceberg Options dropdown from within the node.
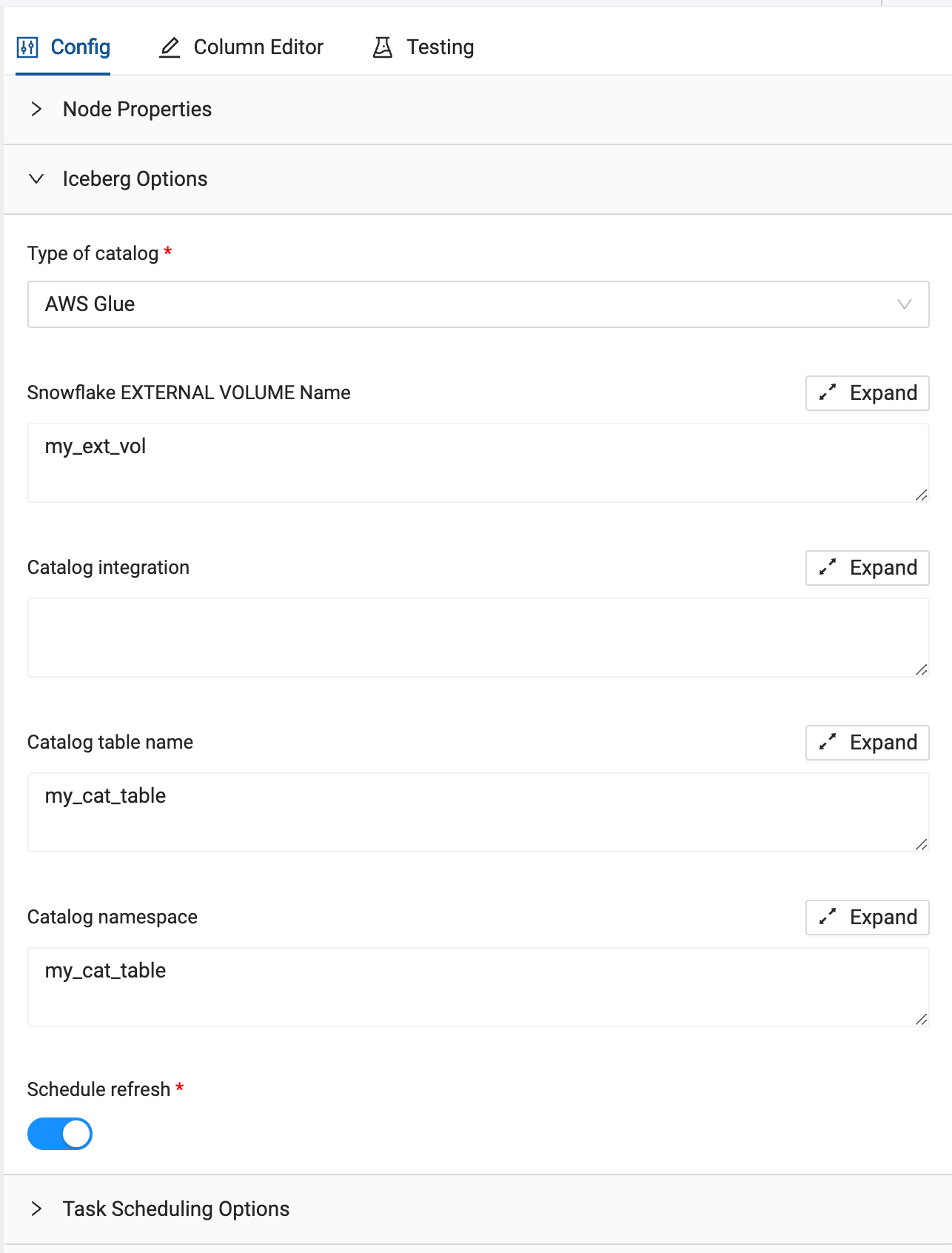
- For the Type of catalog dropdown, we will be using an AWS S3 bucket, so select Object Storage.

- For the External Volume parameter, we will pass through the external volume that was created in section 4 of this lab guide. The external volume is called iceberg_external_volume.

- For the Catalog Integration, again, we will use the name of the integration that we set up in section 4 of this lab guide. The catalog integration is called iceberg_catalog_integration.

- Finally, for the Metadata file path, we will need to provide the metadata JSON file that contains the information to read in the parquet file containing our data. Copy and paste the metadata file path listed below into the parameter:
transcriptions_customer/metadata/00001-31af3f7b-6ea2-4ba9-9130-0e14d2fd5337.metadata.json

- Finally, toggle off the Schedule Refresh toggle, as we won't be concerned for this lab with setting up this Iceberg table on a continual refresh, but note that we can schedule any Iceberg table with this functionality.

- Rename the node to CALL_TRANSCRIPTS.
- Select Create and then Run to create the object in Snowflake and populate it with the data in the Iceberg table format from S3.
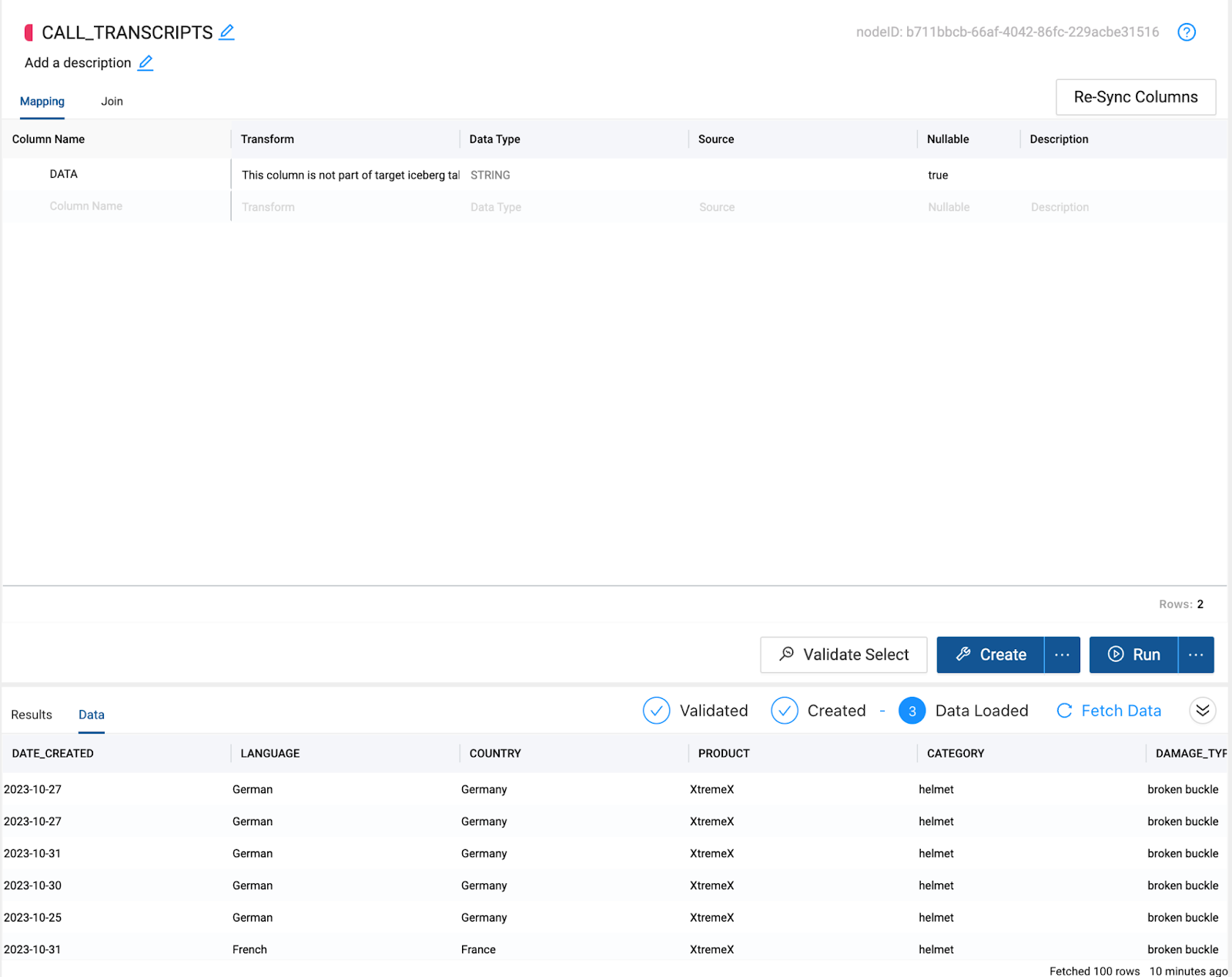
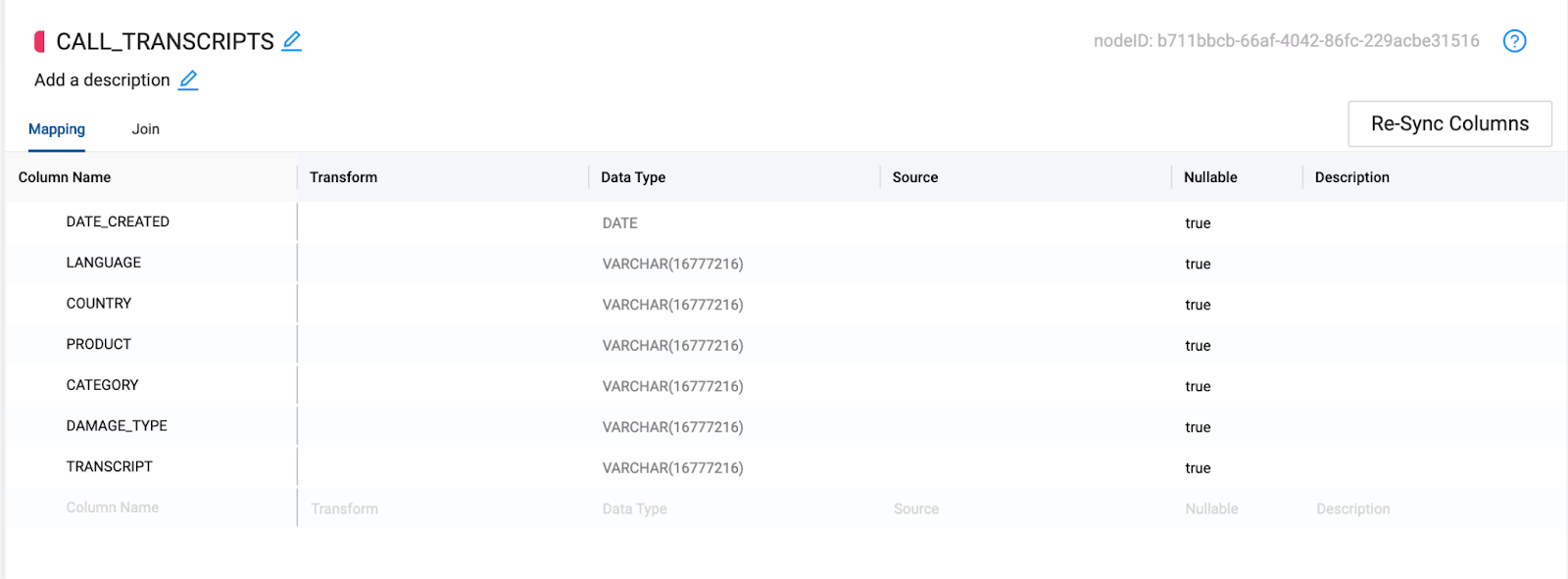
- With the data read from the S3 bucket, we can now resync the columns of the node to reflect the columns we have read in from the S3 bucket. Select the Re-Sync Columns button to do this.

- You should now see all of the columns from the data source coming from the S3 bucket.
Now that you've added your Source node, let's prepare the data by adding business logic with Stage nodes. Stage nodes represent staging tables within Snowflake where transformations can be previewed and performed. Let's start by adding a standardized "stage layer" for the data source.
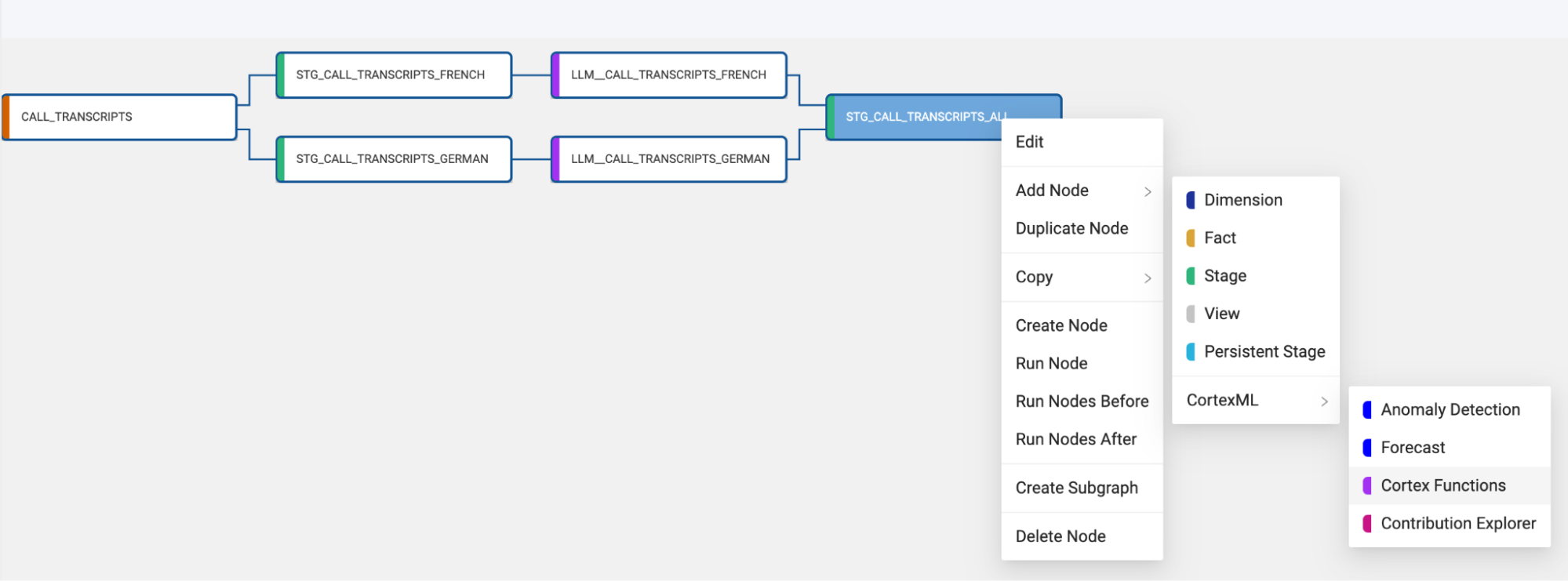
- Select the CALL_TRANSCRIPT source node then right click and select Add Node > Stage from the drop down menu. This will create a new stage node and Coalesce will automatically open the mapping grid of the node for you to begin transforming your data.
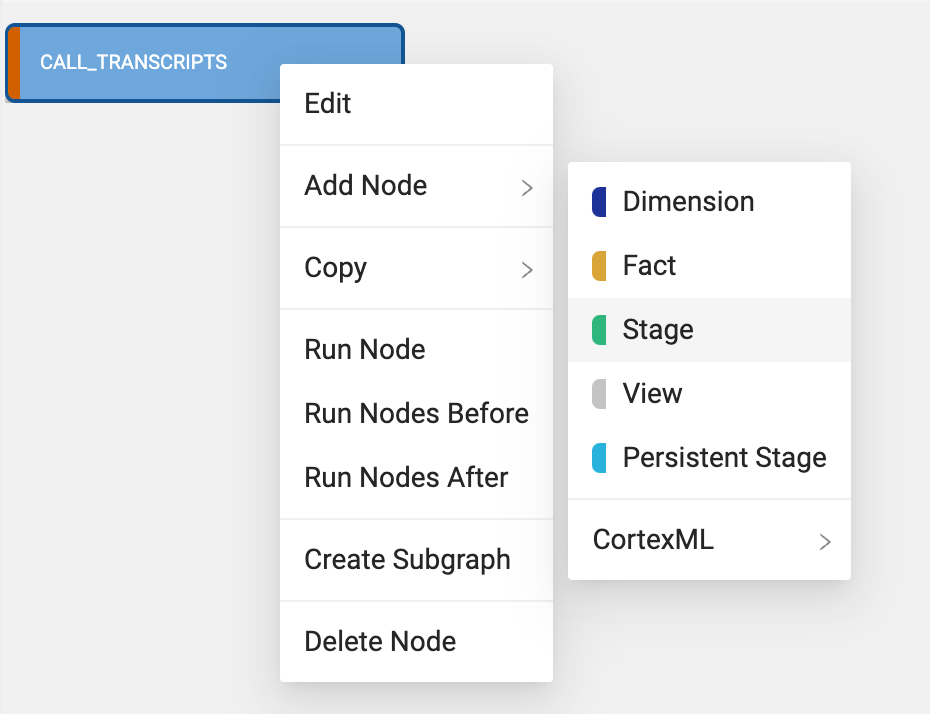
- Within the Node, the large middle section is your Mapping grid, where you can see the structure of your node along with column metadata like transformations, data types, and sources.
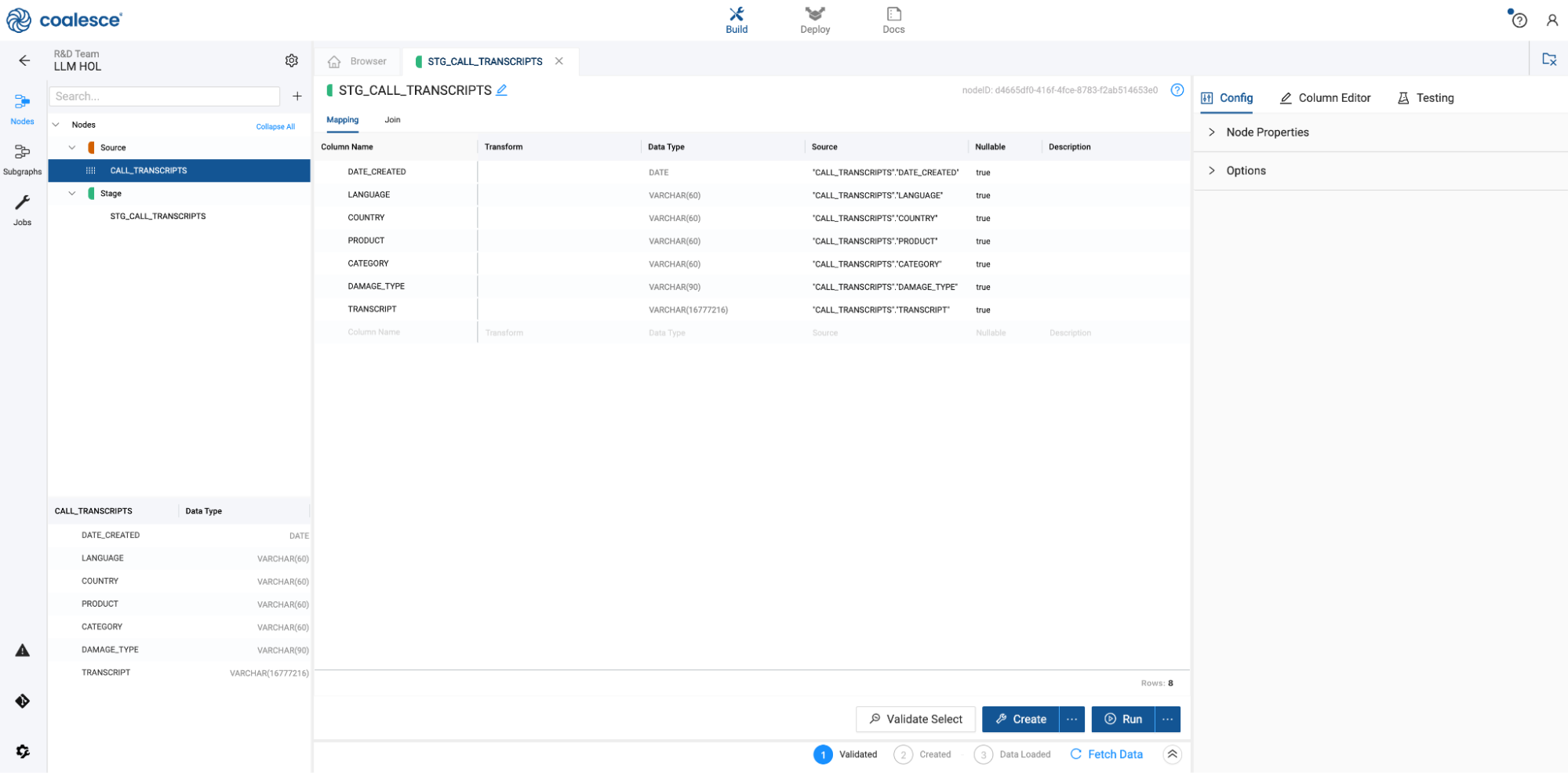
- On the right hand side of the Node Editor is the Config section, where you can view and set configurations based on the type of node you're using.
 ![][image34]
![][image34]
- At the bottom of the Node Editor, press the arrow button to view the Data Preview pane.
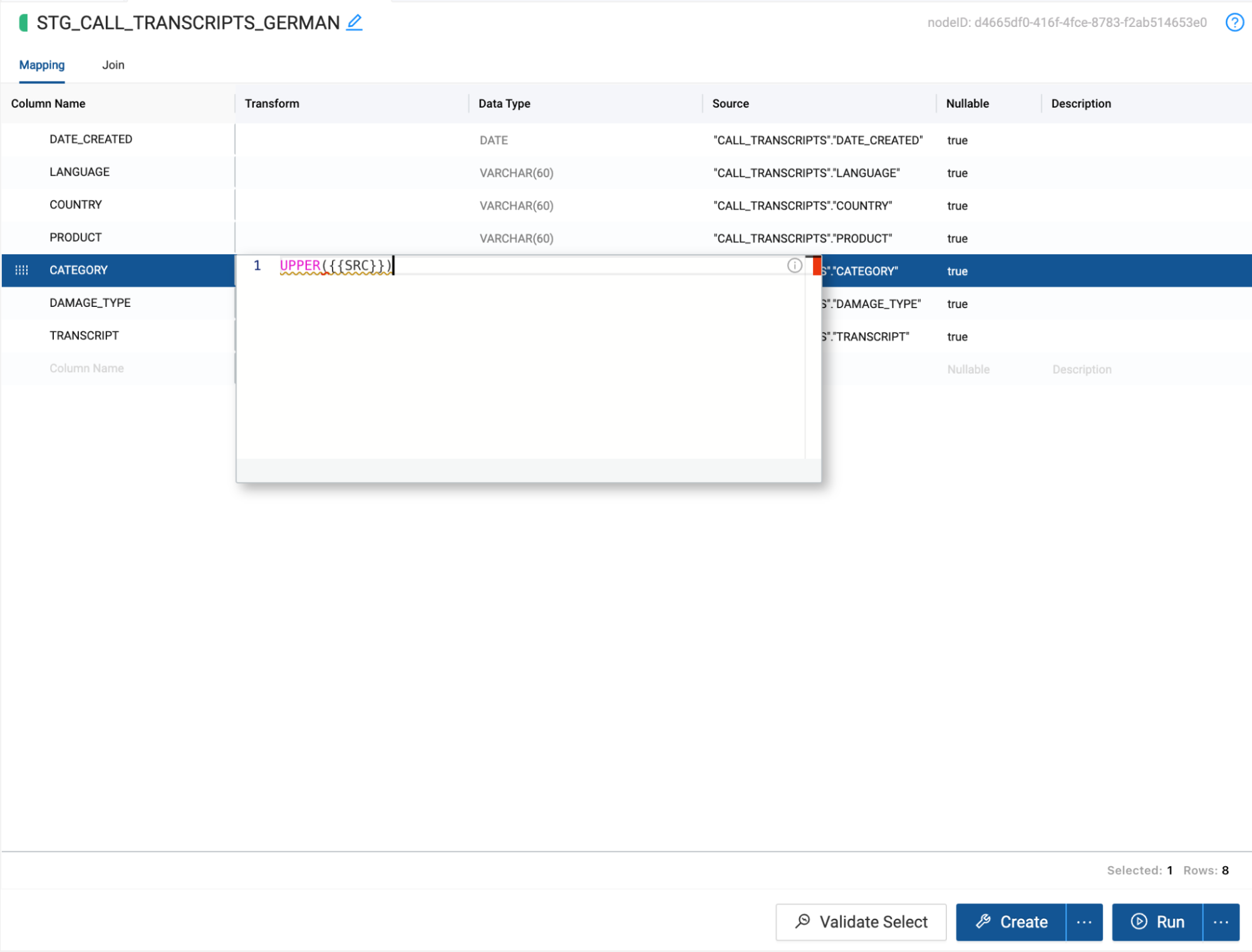
- Rename the node to STG_CALL_TRANSCRIPTS_GERMAN

- Within Coalesce, you can use the Transform column to write column level transformations using standard Snowflake SQL. We will transform the Category column to use an upper case format using the following function:UPPER({{SRC}})
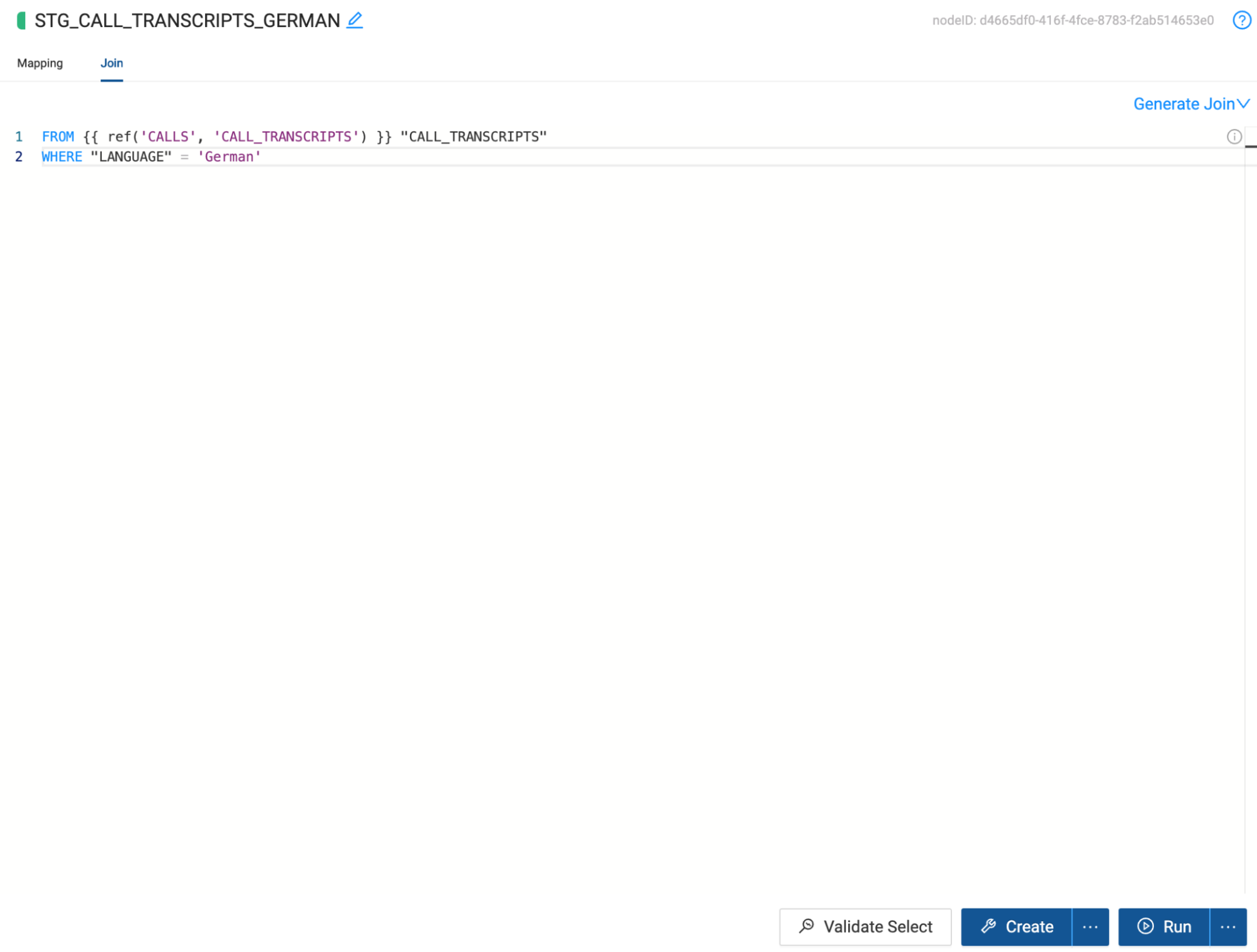
- Coalesce also allows you to write as much custom SQL as needed for your business use case. In this case, we need to process French and German language records in separate tables so that we can pass each language to its own Cortex translation function and union the tables together.To do this, navigate to the Join tab, where you will see the node dependency listed within the Ref function. Within the Join tab, we can write any Snowflake supported SQL. In this use case, we will add a filter to limit our dataset to only records with German data, using the following code snippet:WHERE "LANGUAGE" = ‘German'
- Now that we have transformed and filtered the data for our German node, we now need to process our French data. Coalesce leverages metadata to allow users to quickly and easily build objects in Snowflake. Because of this metadata, users can duplicate existing objects, allowing everything contained in one node to be duplicated in another, including SQL transformations.
Navigate back to the Build Interface and right click on the STG_CALL_TRANSCRIPTS_GERMAN node and select duplicate node.
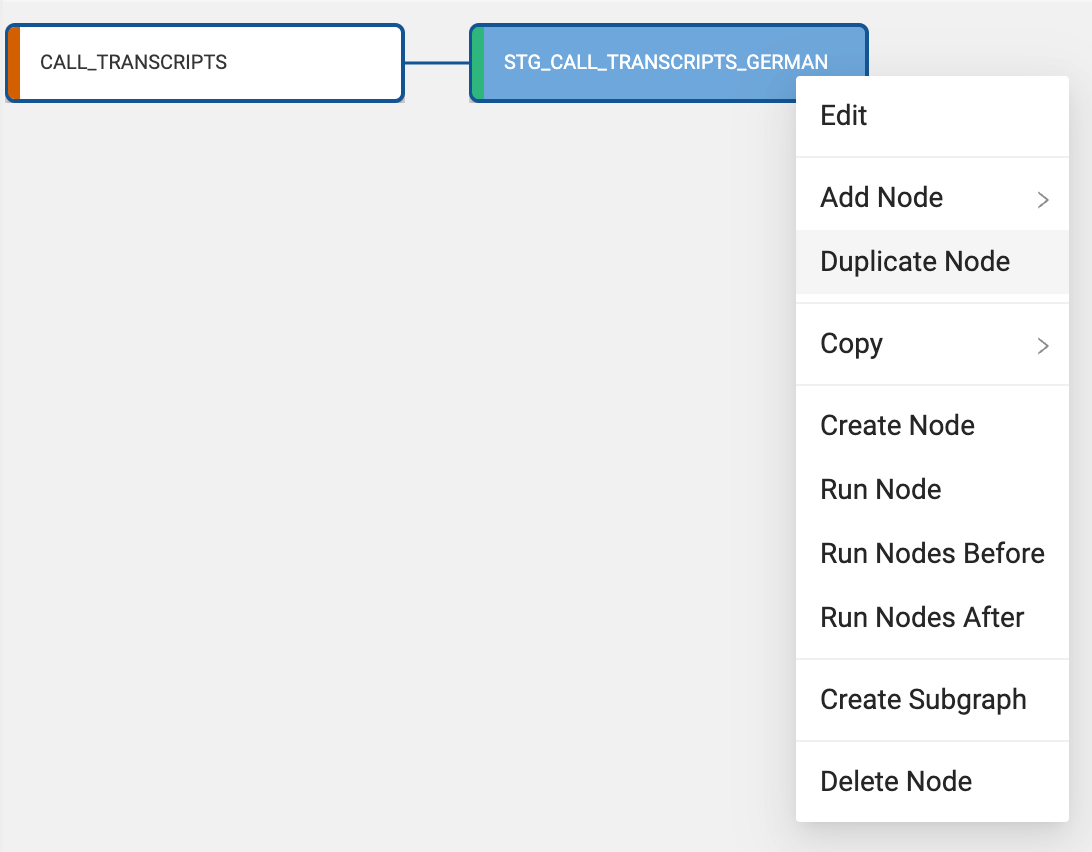
- Double click on the duplicated node, and once inside the node, rename the node to STG_CALL_TRANSCRIPTS_FRENCH.

- Navigate to the Join tab, where we will update the where condition to an IN to include both French and English data.WHERE "LANGUAGE" IN (‘French', ‘English')
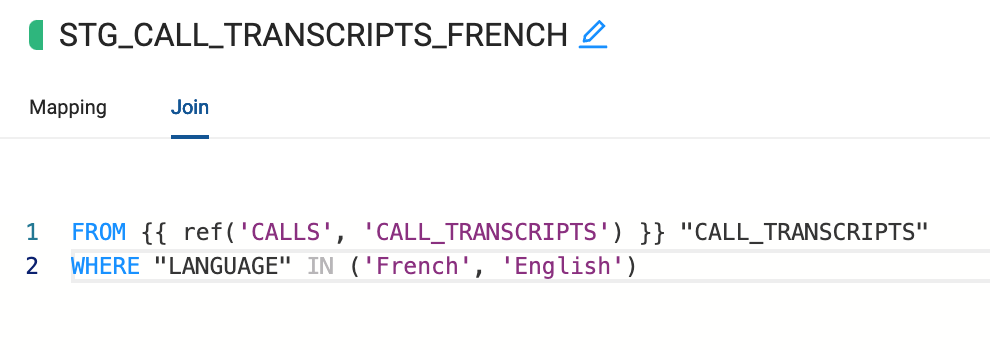
- All the changes made from the STG_CALL_TRANSCRIPTS_GERMAN carry over into this node, so we don't need to rewrite any of our transformations. Let's change the view back to Graph and select Create All and then Run All

Now that we have prepared the call transcript data by creating nodes for each language, we can now process the language of the transcripts and translate them into a singular language. In this case, English.
- Select the STG_CALL_TRANSCRIPTS_GERMAN node and hold the Shift key and select the STG_CALL_TRANSCRIPTS_FRENCH node. Right click on either node and navigate to Add Node. You should see the Cortex package that you installed from the Coalesce Marketplace. By hovering over the Cortex package, you should see the available nodes. Select Cortex Functions. This will add the Cortex Function node to each STG node.
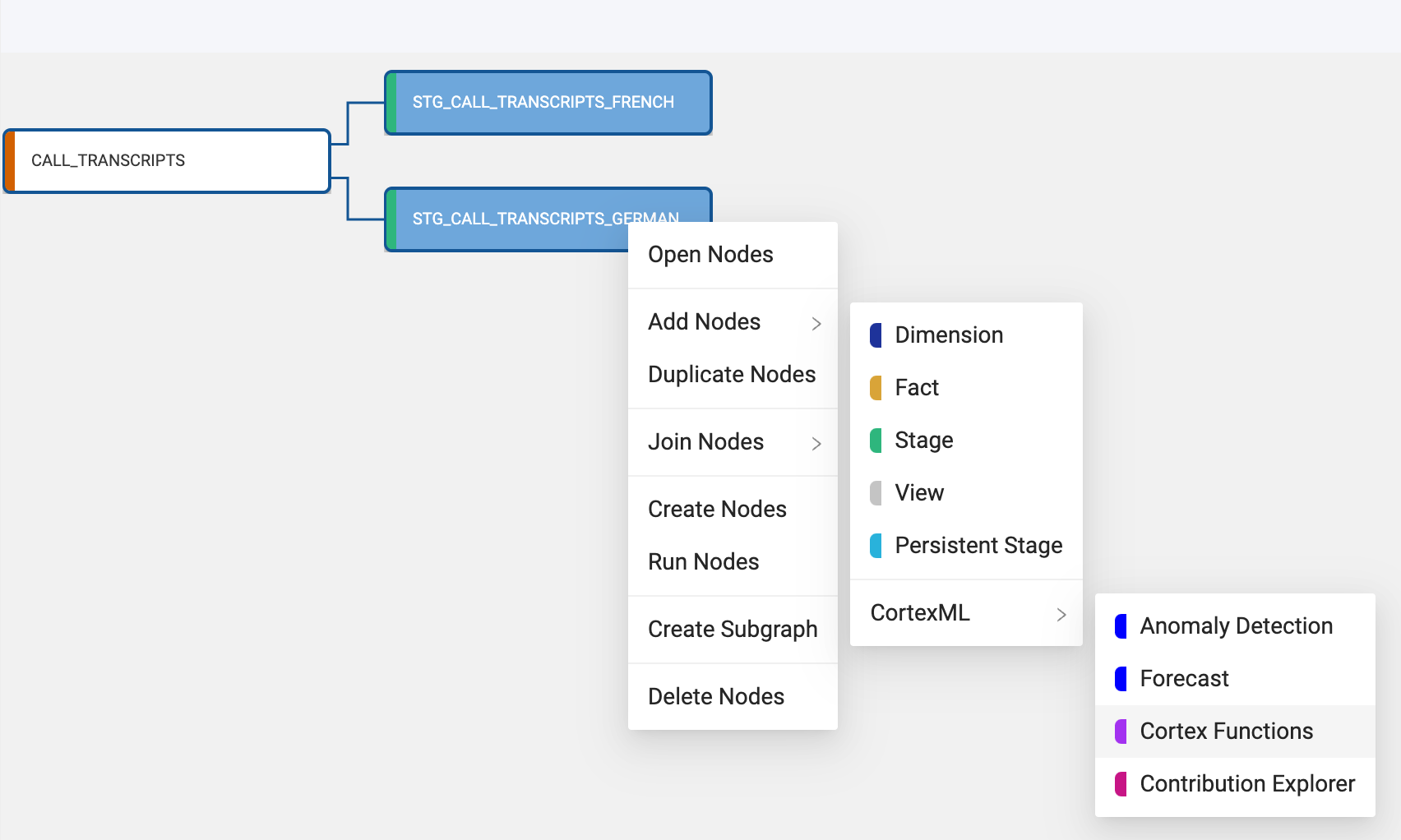
- You now need to configure the Cortex Function nodes to translate the language of the transcripts. Double click on the LLM_CALL_TRANSCRIPTS_GERMAN node to open it.
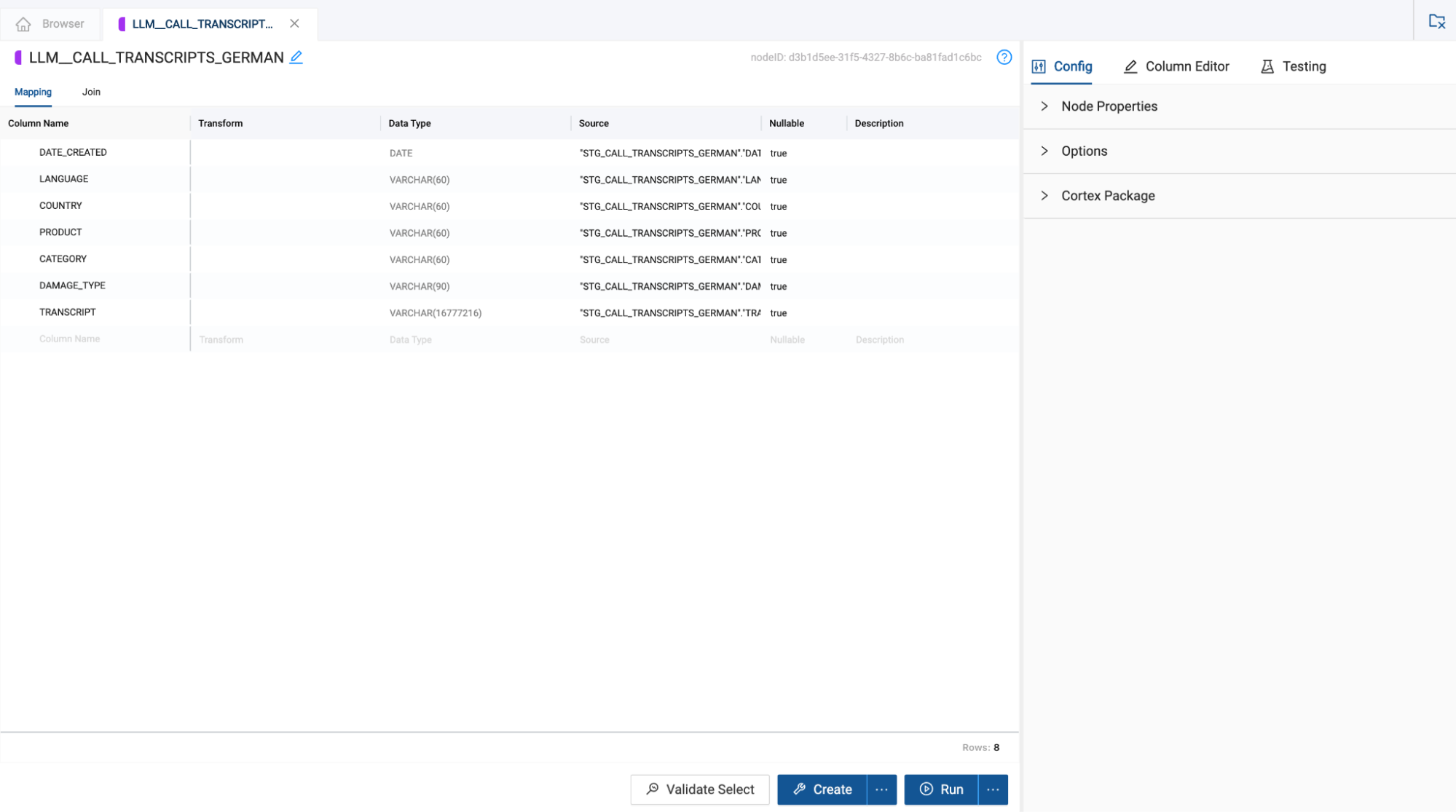
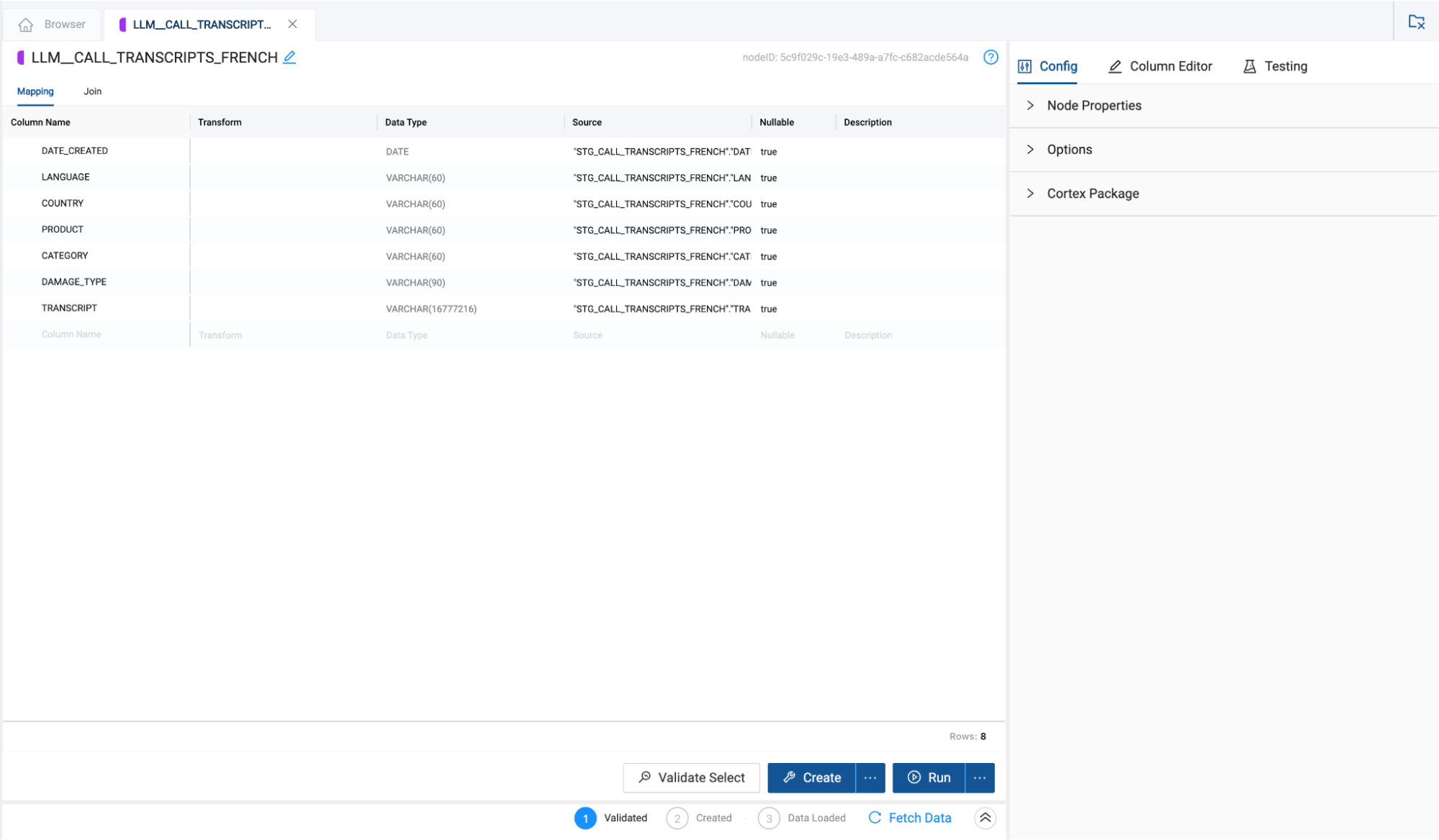
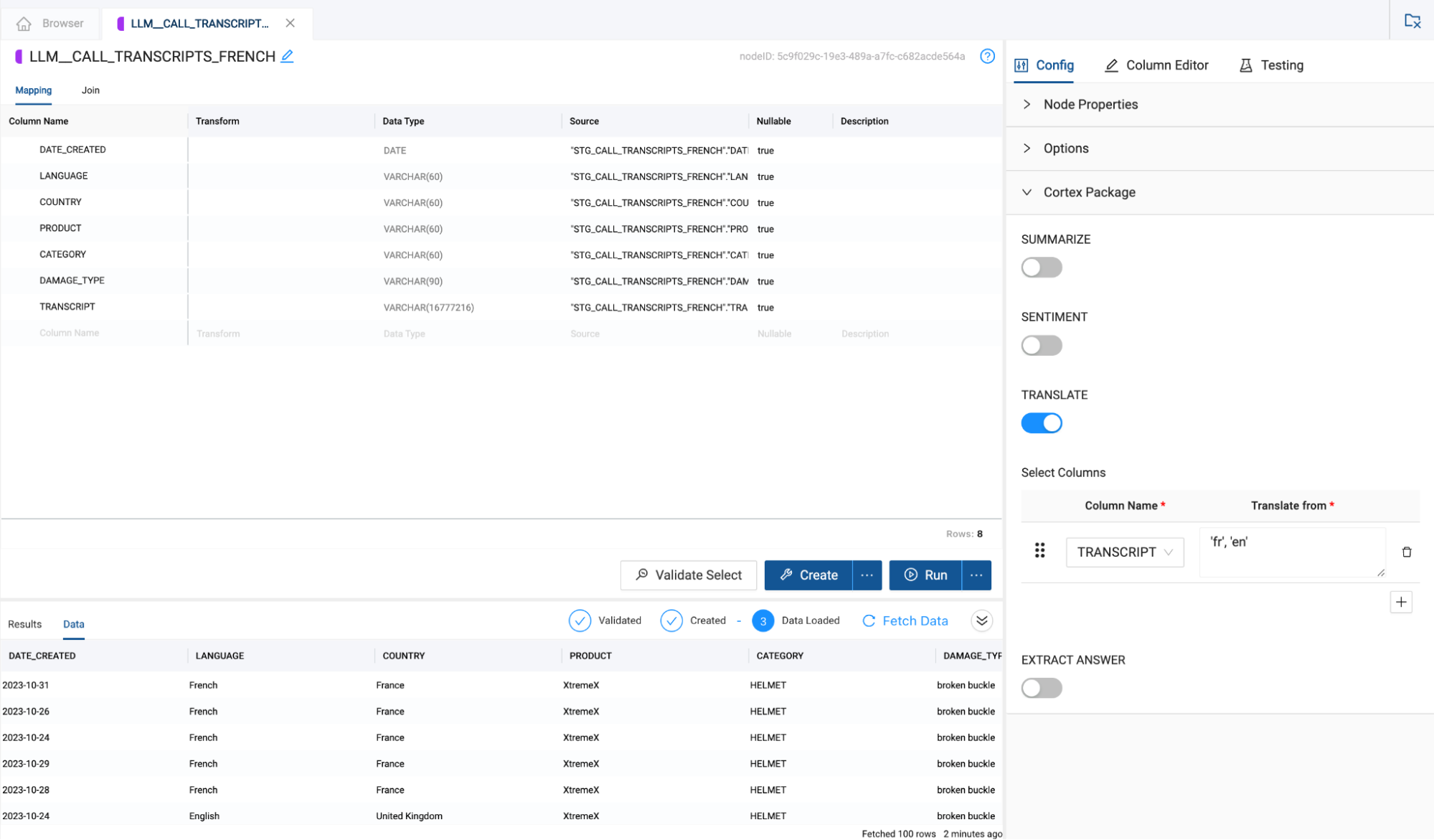
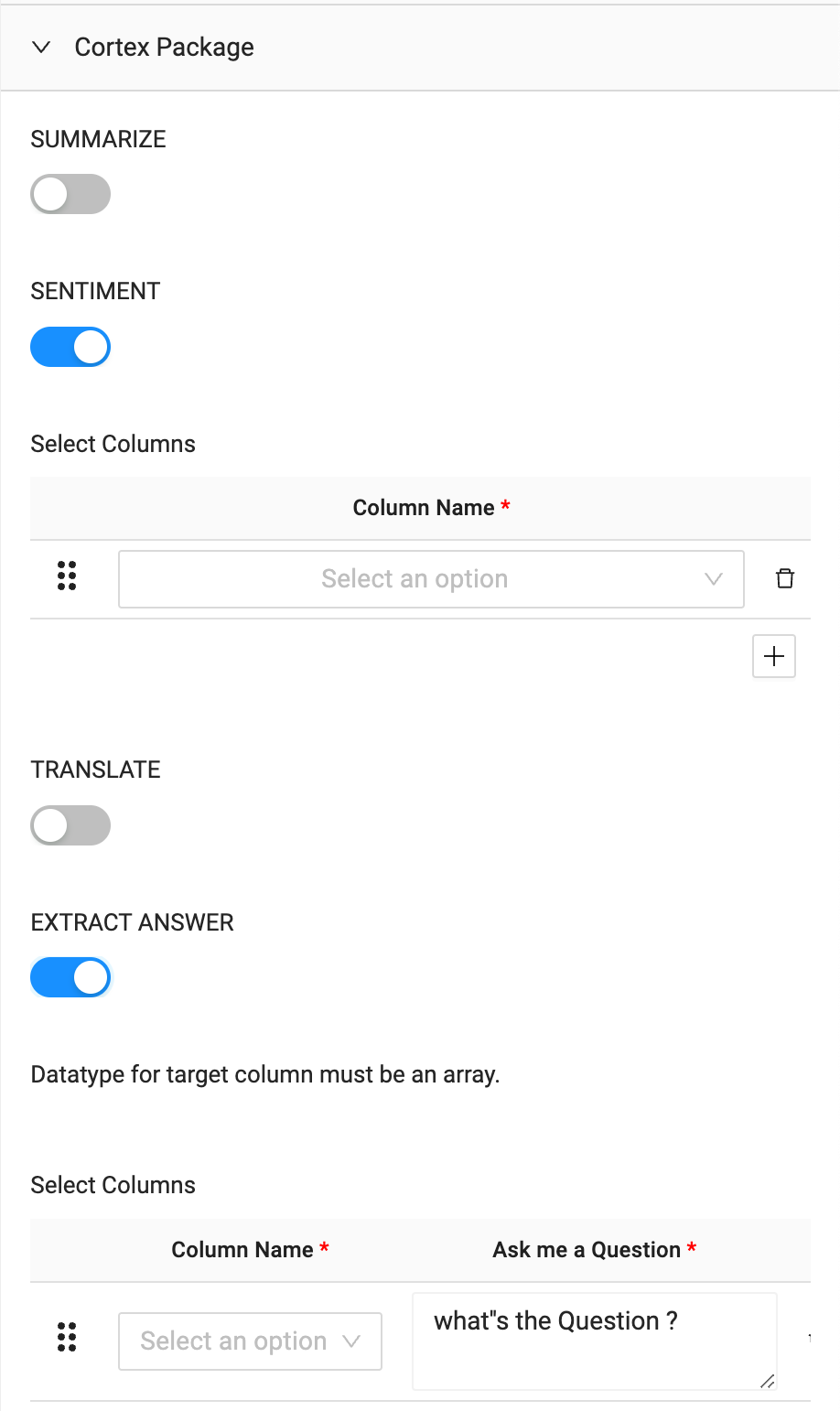
- In the configuration options on the right hand side of the node, open the Cortex Package dropdown and toggle on TRANSLATE.
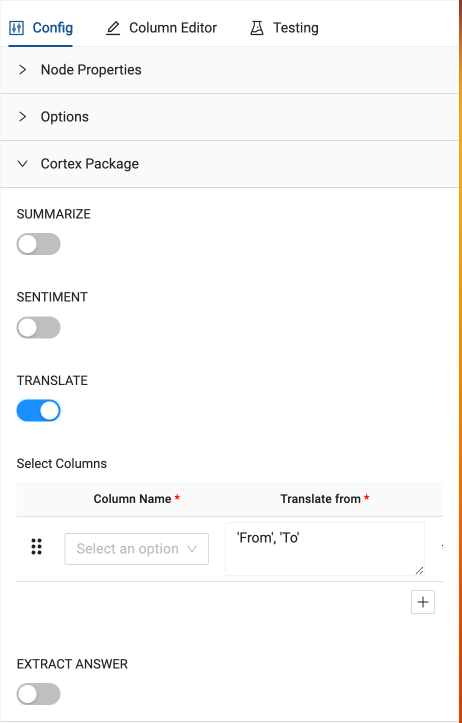
- With the TRANSLATE toggle on, In the column name selector dropdown, you need to select the column to translate. In this case, the TRANSCRIPT column.
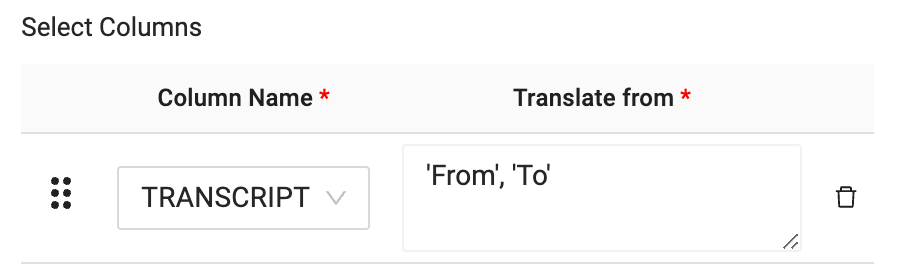
- Now that you have selected the column that will be translated, you will pass through the language you wish to translate from and the language you wish to translate to, into the translation text box. In this case, you want to translate from German to English. The language code for this translation is as follows:‘de', ‘en'
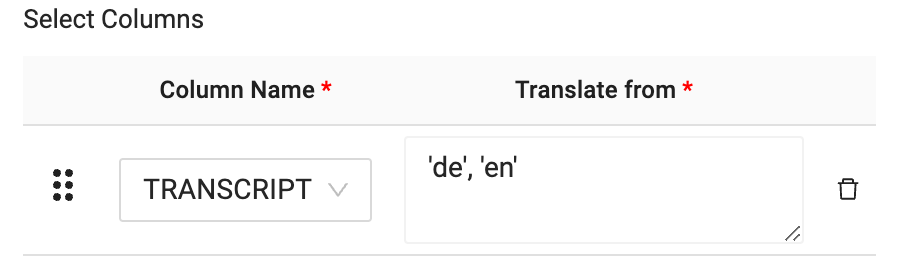
- Now that you have configured the LLM node to translate German data to English, you can click Create and Run to build the table in Snowflake and populate it with data.
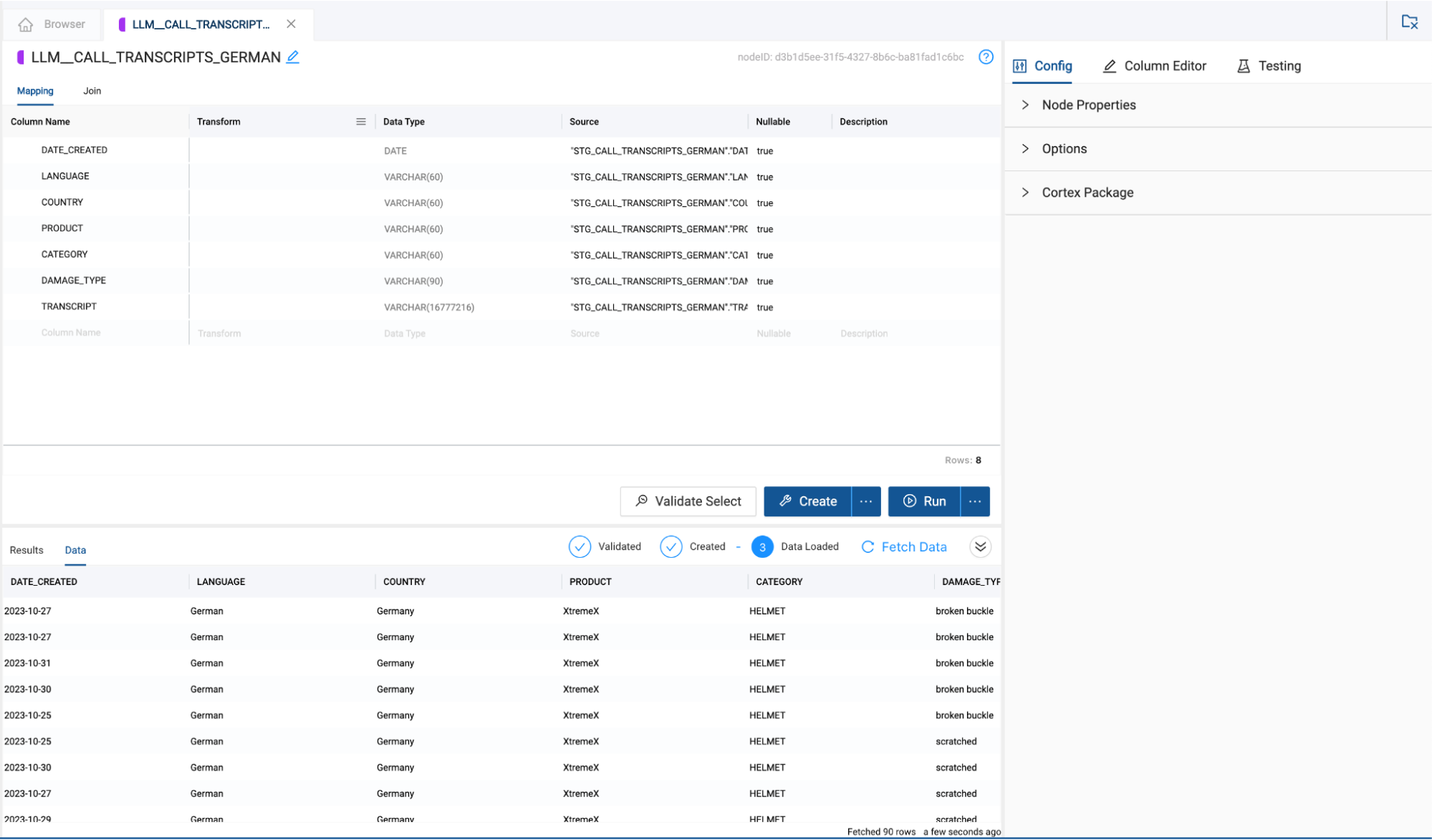
- While the LLM_CALL_TRANSCRIPT_GERMAN node is running, you can configure the LLM_CALL_TRANSCRIPT_FRENCH. Double click on the LLM_CALL_TRANSCRIPT_FRENCH node to open it.
- Open the Cortex Package dropdown on the right hand side of the node and toggle on TRANSLATE.
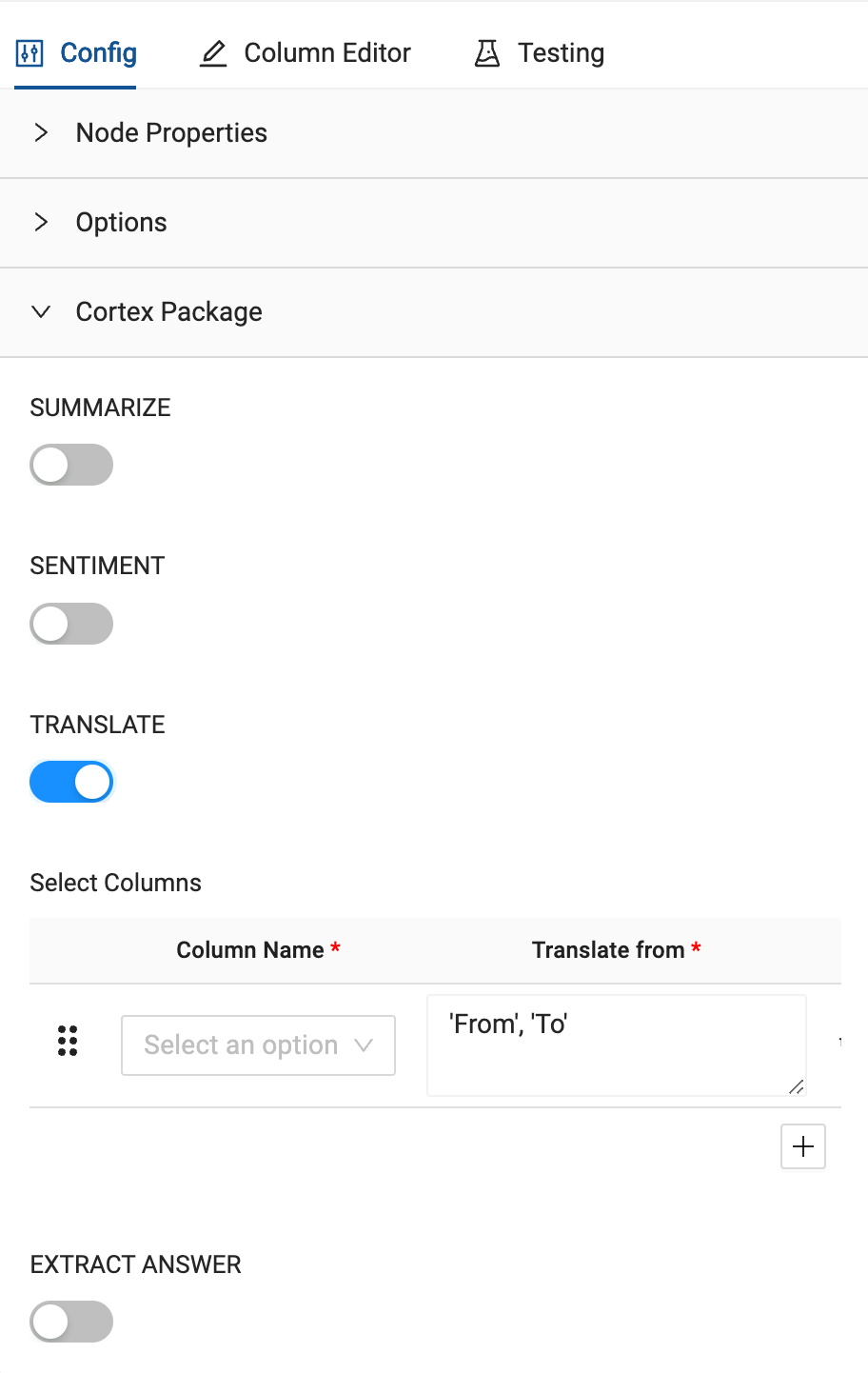
- Just like the German node translation, you will pass the TRANSCRIPT column through as the column you want to translate.
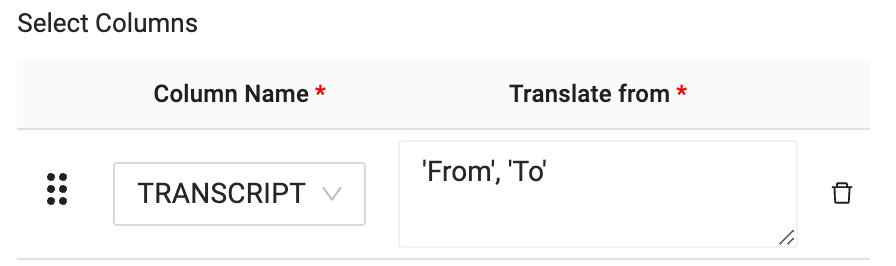
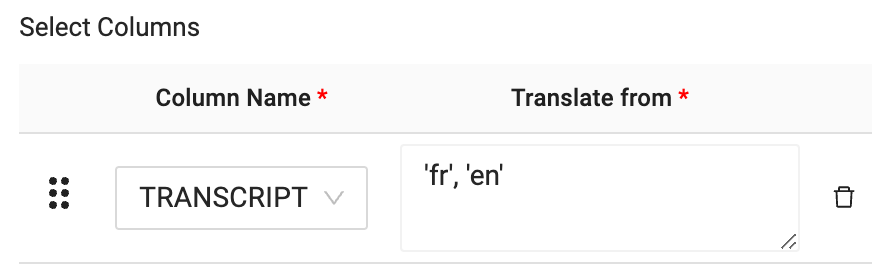
- Finally, you will configure the language code for what you wish to translate the language of the transcript column from to the language you wish to translate to. In this case, the language code is as follows:‘fr', ‘en'
Any values in the transcript field which do not match the language being translated from will be ignored. In this case, there are both French and English language values in the TRANSCRIPT field. Because the English values are not in French, they will automatically pass through as their original values. Since those values are already in English, they don't require any additional processing.
- Select Create and Run to build the object in Snowflake and populate it with data
You have now processed the transcript data by translating the German and French transcripts into English. However, this translated data exists in two different tables, and in order to build an analysis on all of our transcript data, we need to unify the two tables together into one.
- Select the LLM_CALL_TRANSCRIPTS_GERMAN node and Add Node > Stage.
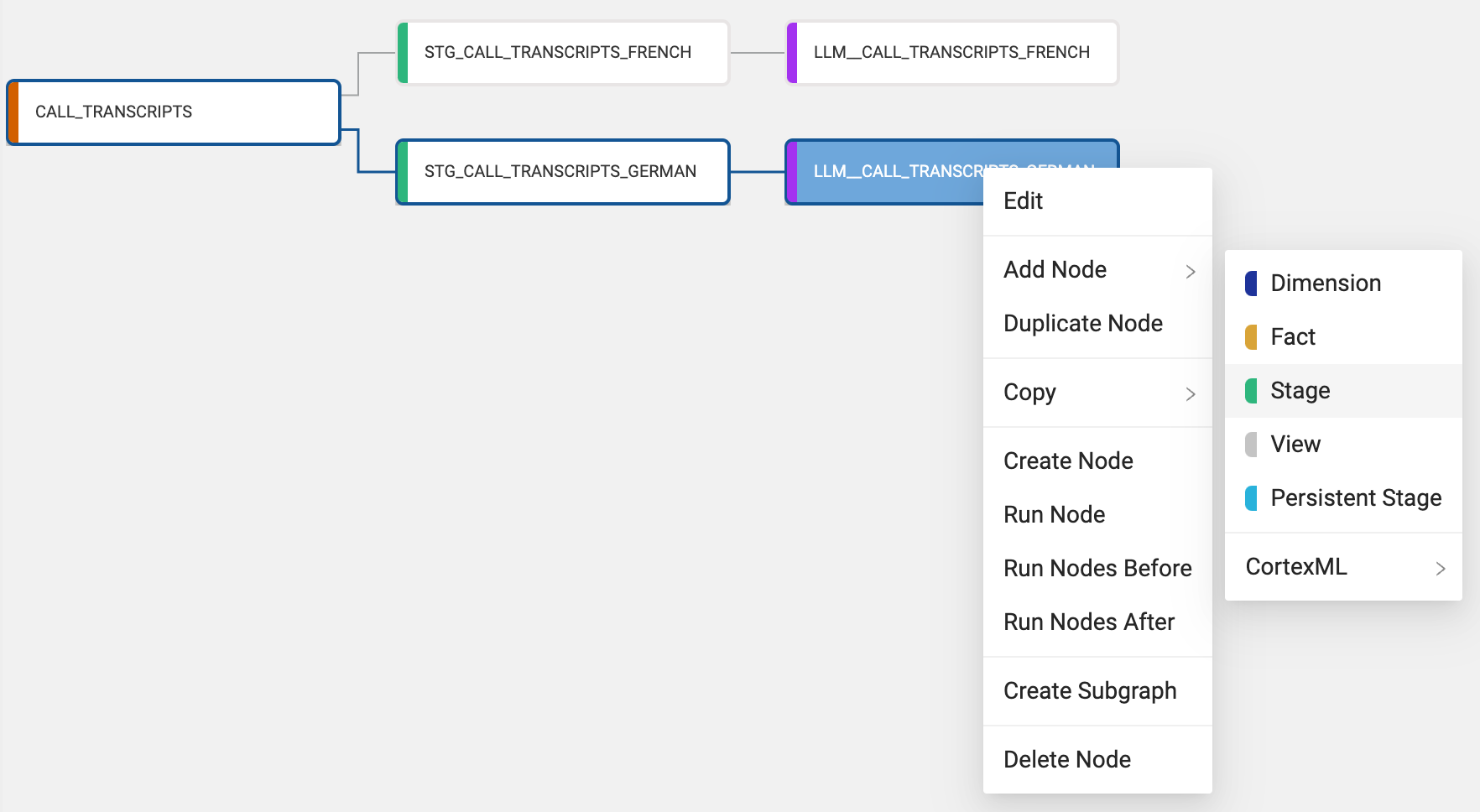
- Rename the node to STG_CALL_TRANSCRIPTS_ALL.

- In the configuration options on the right hand side of the node, open the options dropdown and toggle on Multi Source.
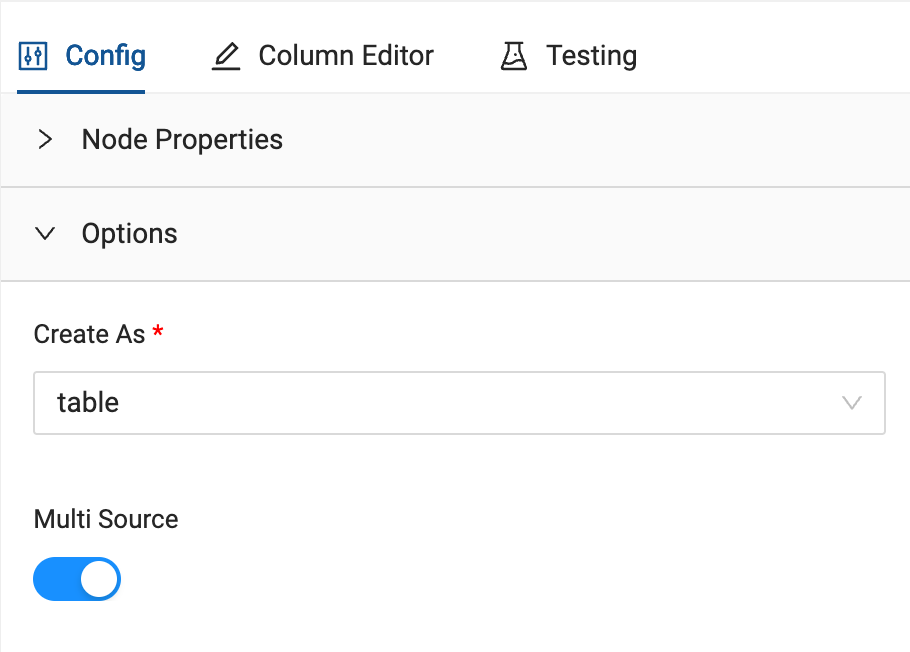
- Multi Source allows you to union together nodes with the same schema without having to write any of the code to do so. Click on the Multi Source Strategy dropdown and select UNION ALL.

- There will be a union pane next to the columns in the mapping grid that will list all of the nodes associated with the multi source strategy of the node. Click the + button to add a node to union to the current node. You will see a new node get added to the pane called New Source.
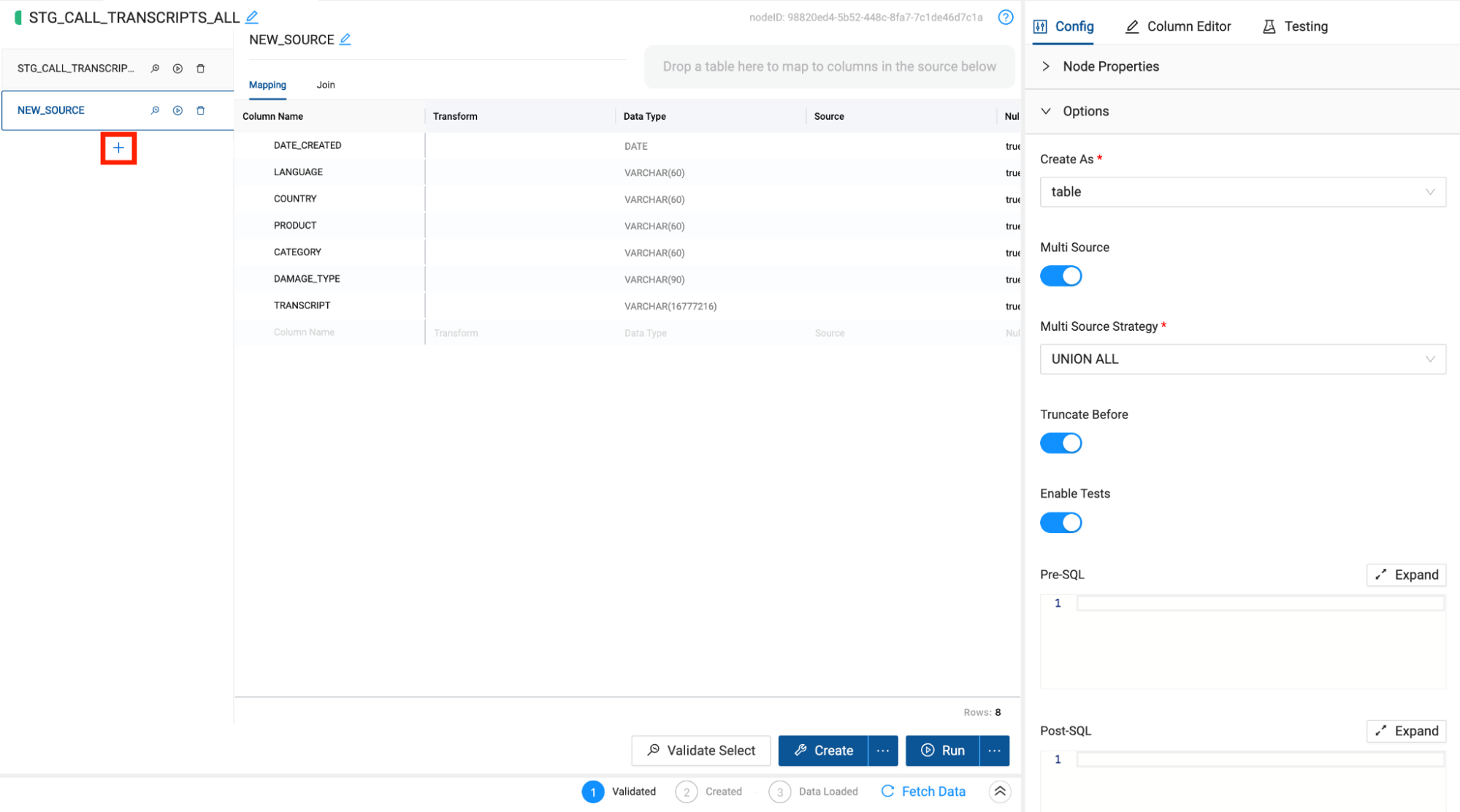
- Within this new source, there is an area to drag and drop any node from your workspace into the grid to automatically map the columns to the original node. Make sure you have the Nodes navigation menu item selected so you can view all of the nodes in your project.
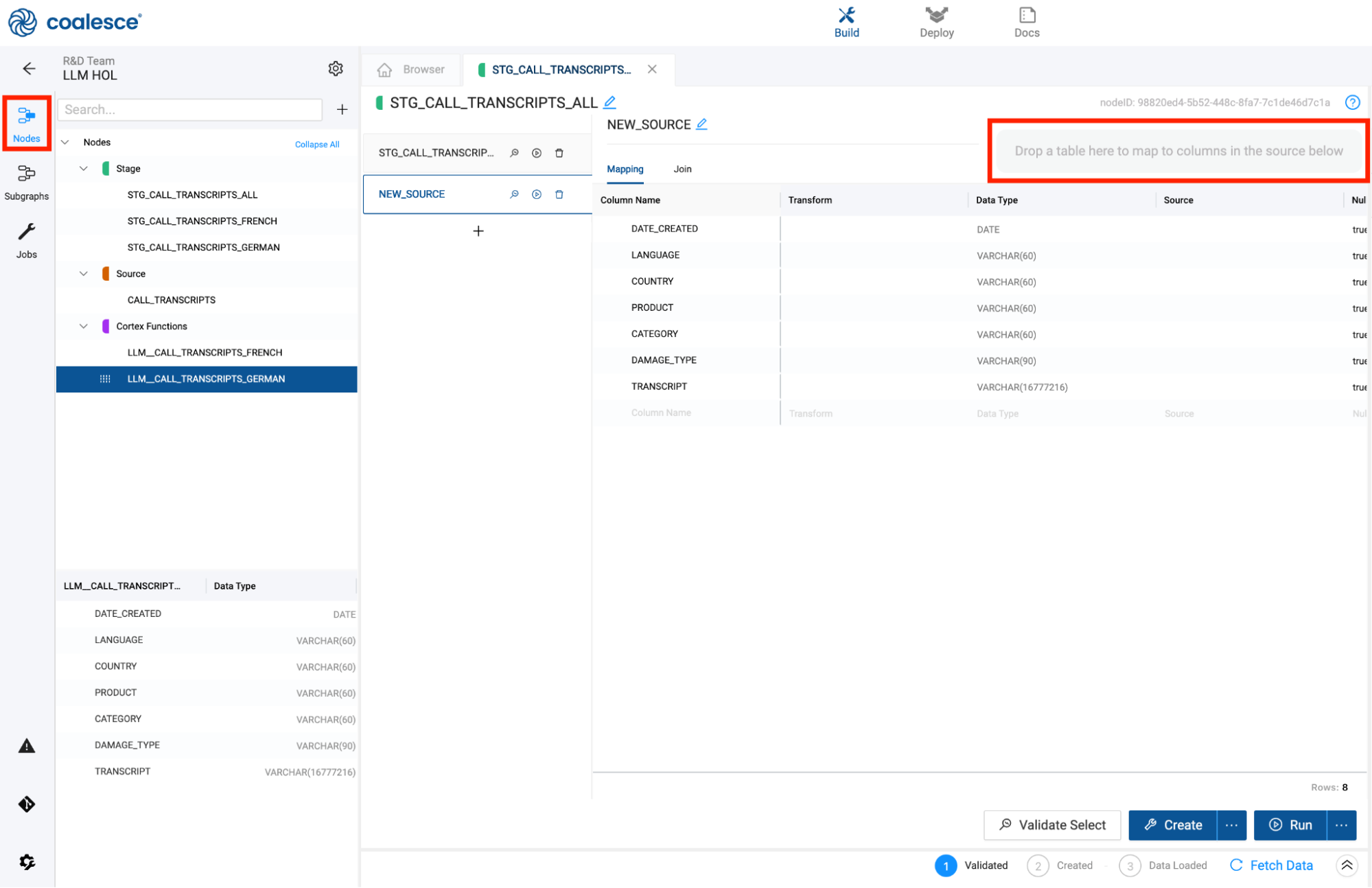
- You will now drag and drop the LLM_CALL_TRANSCRIPTS_FRENCH node into the multi source mapping area of the node. This will automatically map the columns to the original node i.e. LLM_CALL_TRANSCRIPTS_GERMAN.
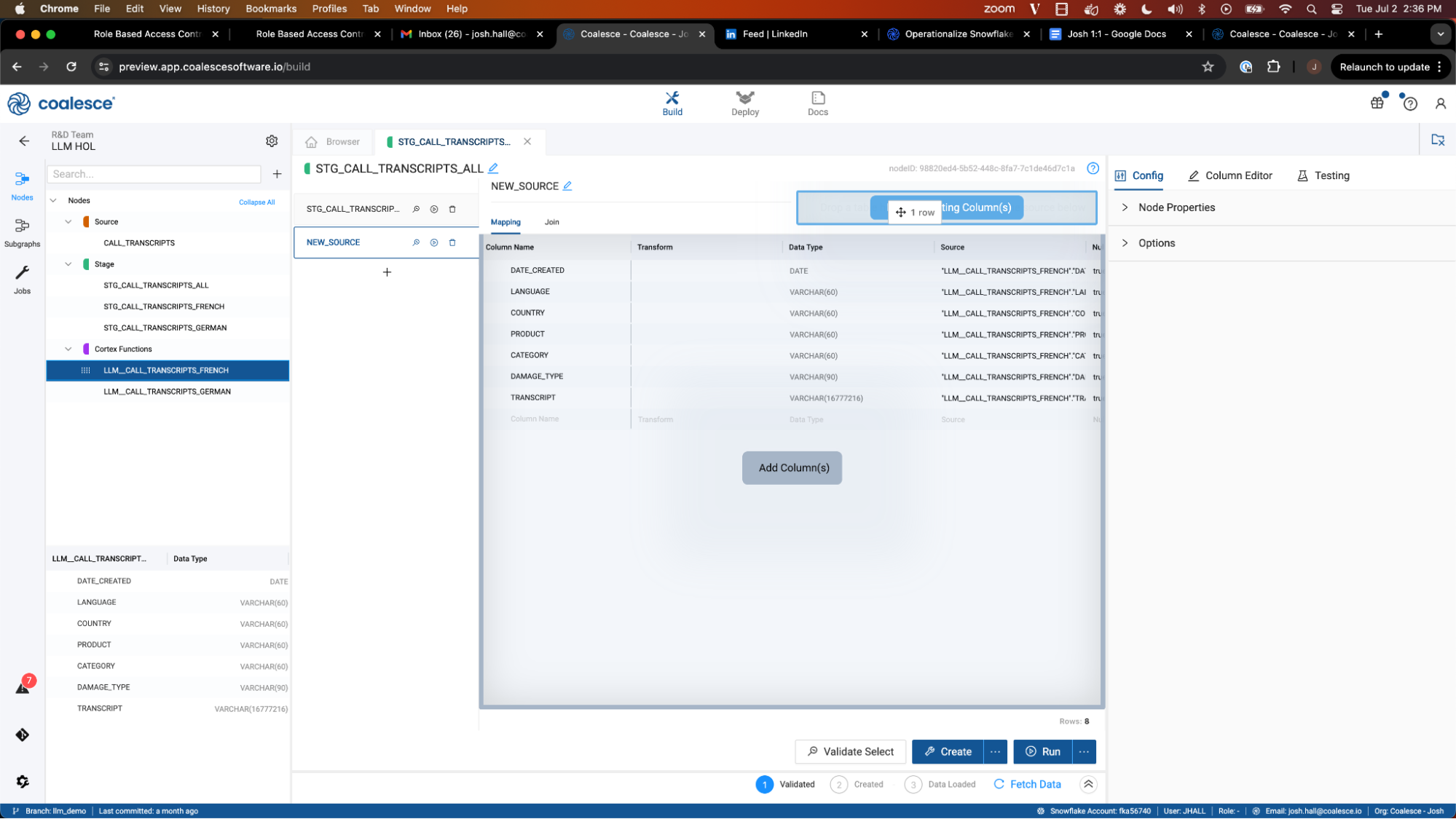
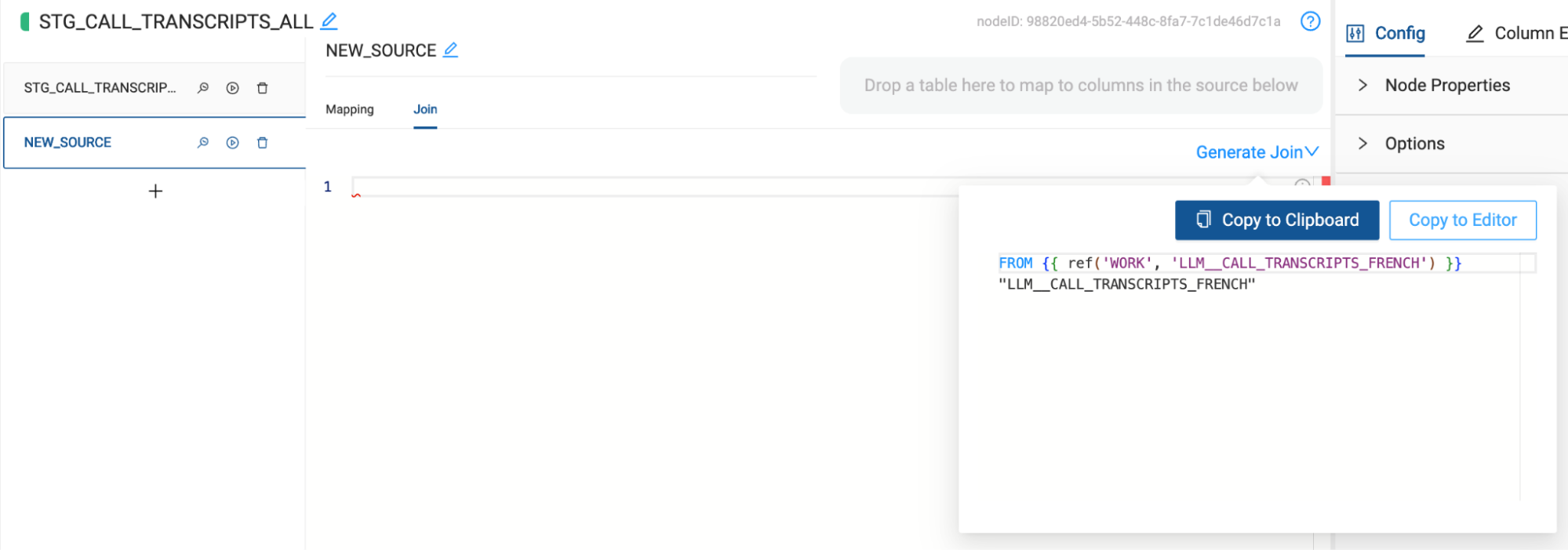
- Finally, select the join tab to configure the reference of the node we are mapping. Using metadata, Coalesce is automatically able to generate this reference for you. Hover over the Generate Join button and select Copy to Editor. Coalesce will automatically insert the code into the editor, and just like that, you have successfully unioned together the two datasets without writing a single line of code.
- Select Create and Run to build the object and populate it with data.
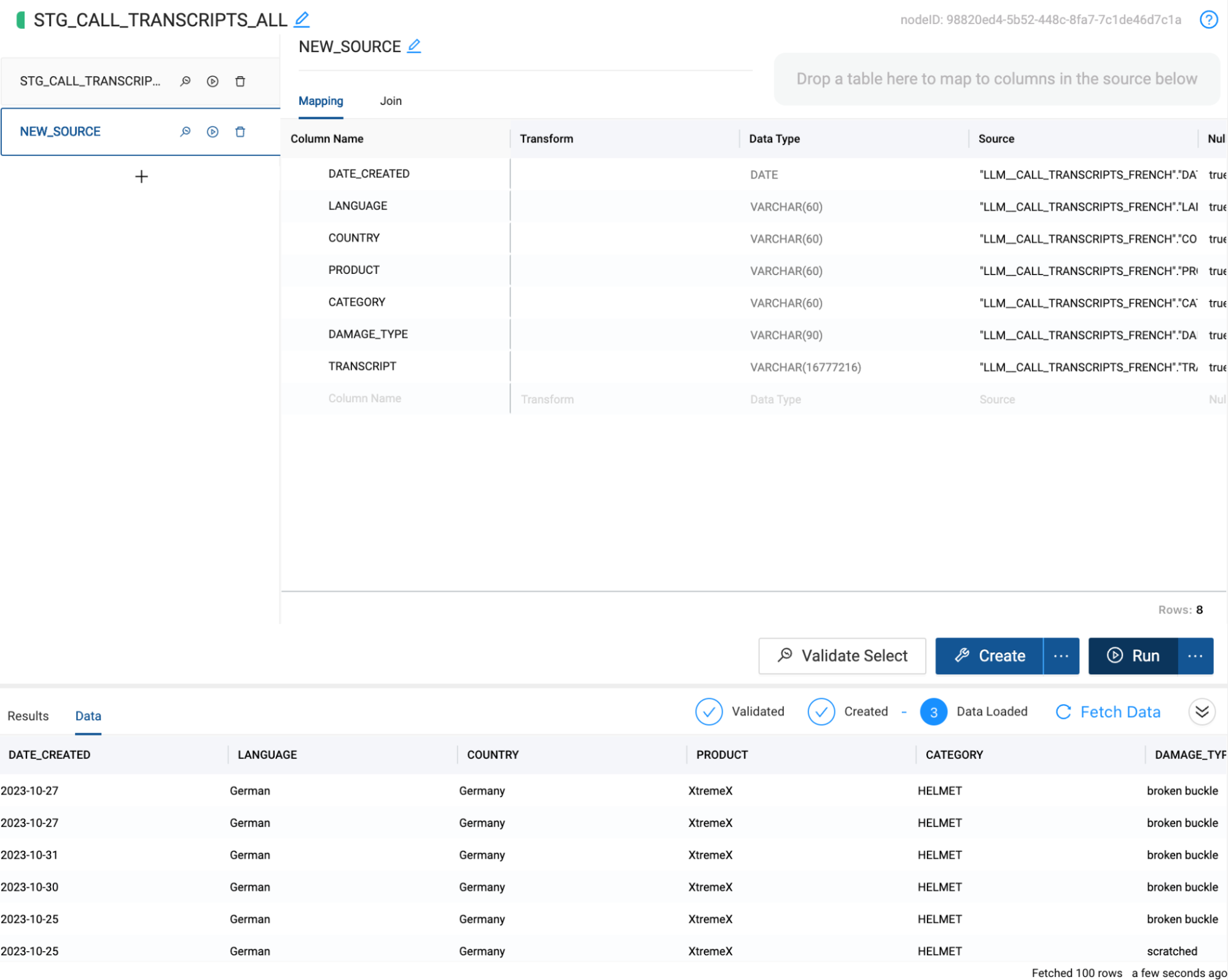
Now that we have all of our translated transcript data in the same table, we can now begin our analysis and extract insights from the data. For the sake of our use case, we want to perform a sentiment analysis on the Transcript, to understand how each of our customers felt during their interaction with our company.
Additionally, our call center reps are trained to ask for the customer's name when someone calls into the call center. Since we have this information, we want to extract the customer name from the transcript so we can associate the sentiment score with our customer to better understand their experience with our company.
- Right click on the STG_CALL_TRANSCRIPTS_ALL node and we will add one last Cortex Function node. Add Node > CortexML > Cortex Functions.
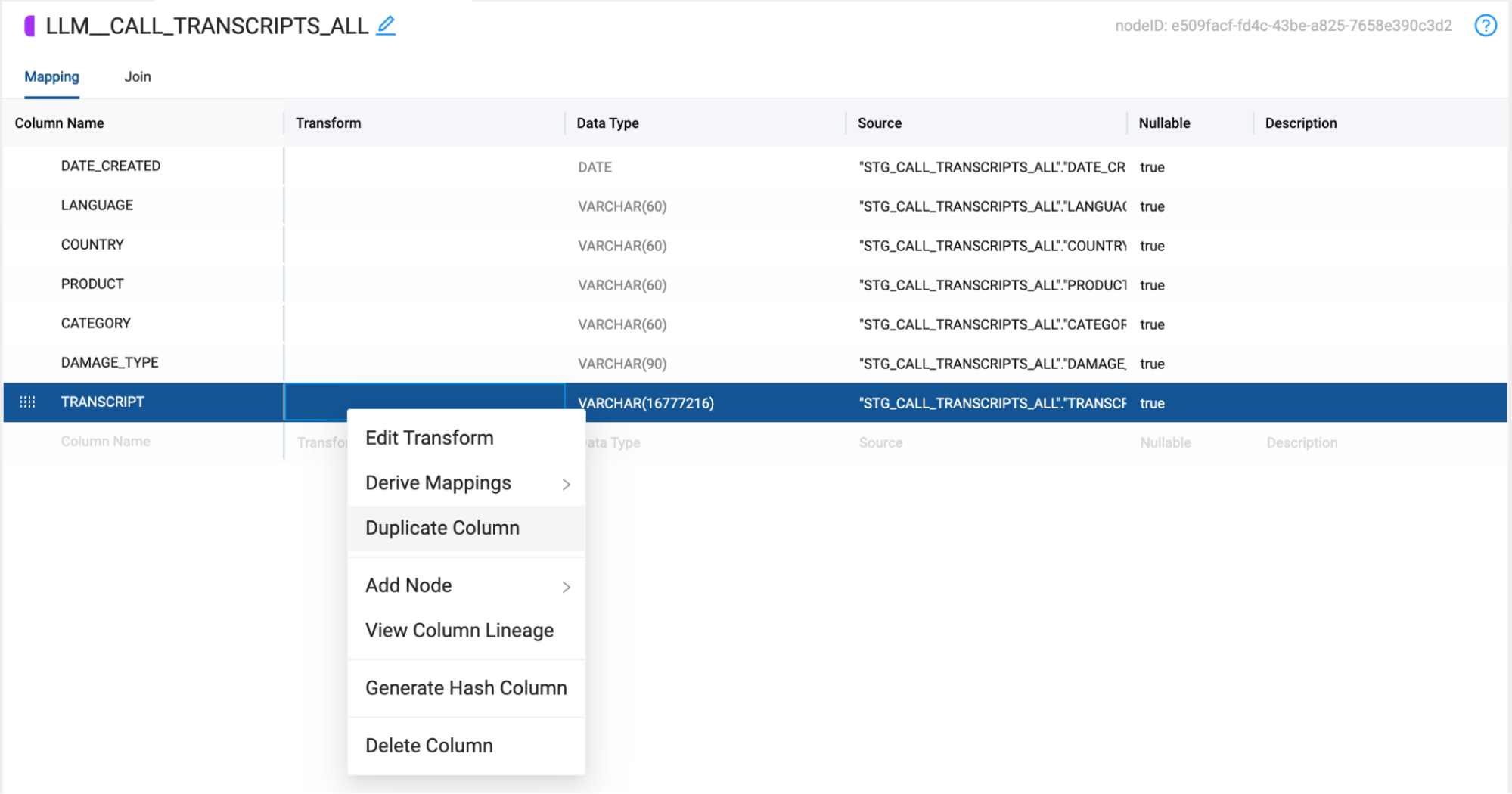
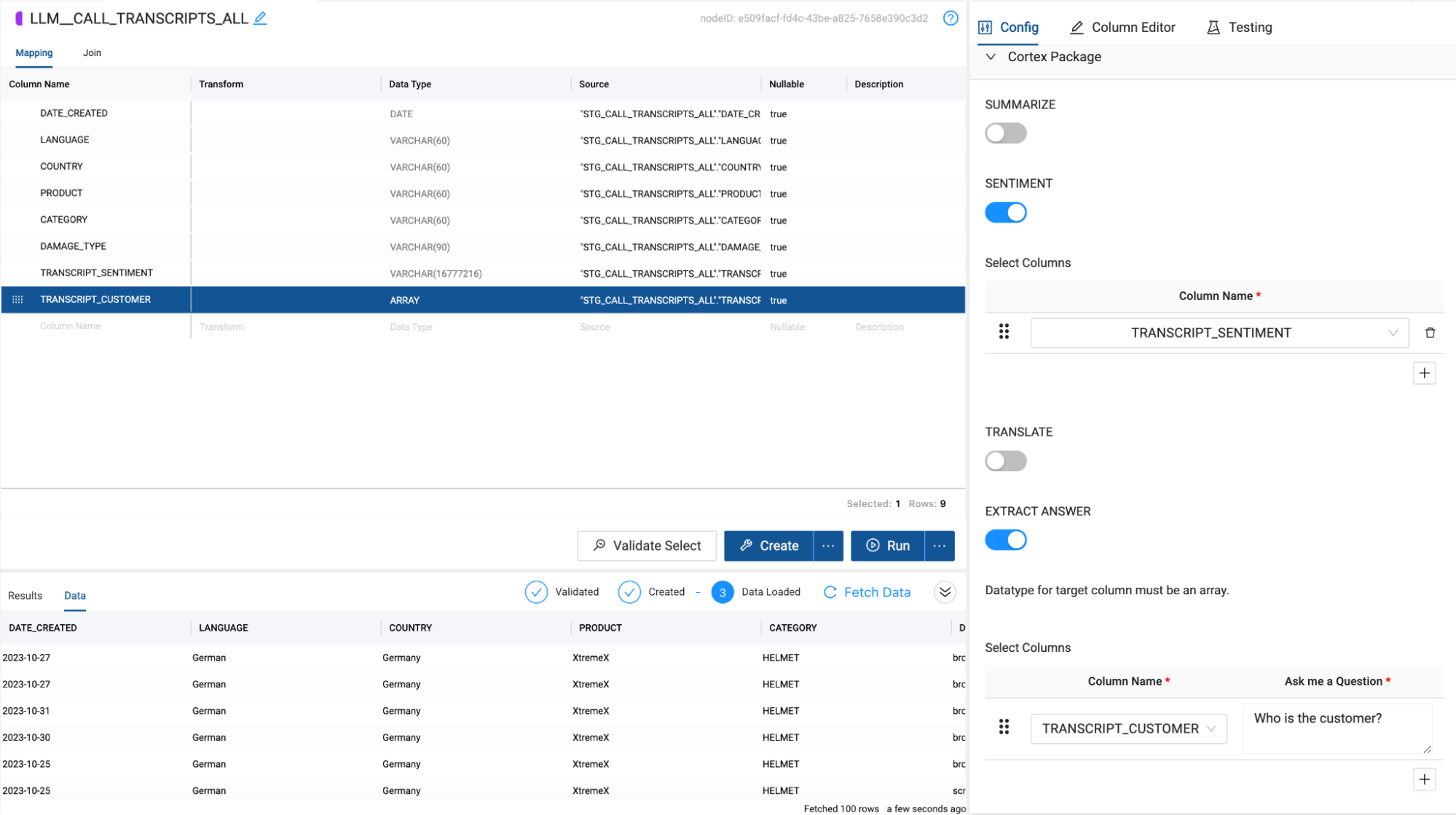
- Within the node click on the Cortex Package dropdown and toggle on SENTIMENT and EXTRACT ANSWER.
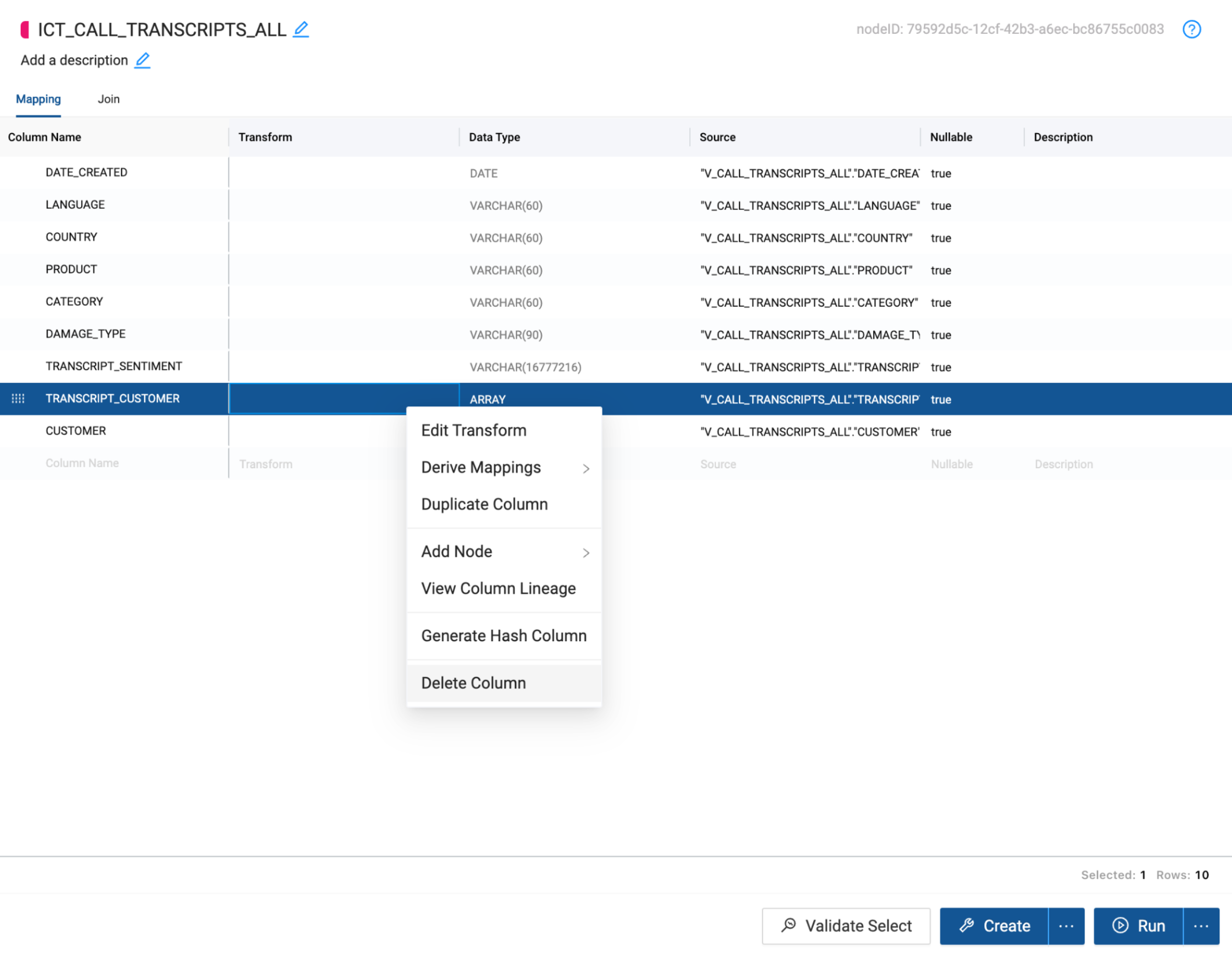
- When cortex functions are applied to a column, they overwrite the preexisting values of the column. Because of this, you will need two transcript columns to pass through to your two functions. One to perform the sentiment analysis, and one to extract the customer name from the transcript. Right click on the TRANSCRIPT column and select Duplicate Column.
- Double click on the original TRANSCRIPT column name and rename the column to TRANSCRIPT_SENTIMENT.
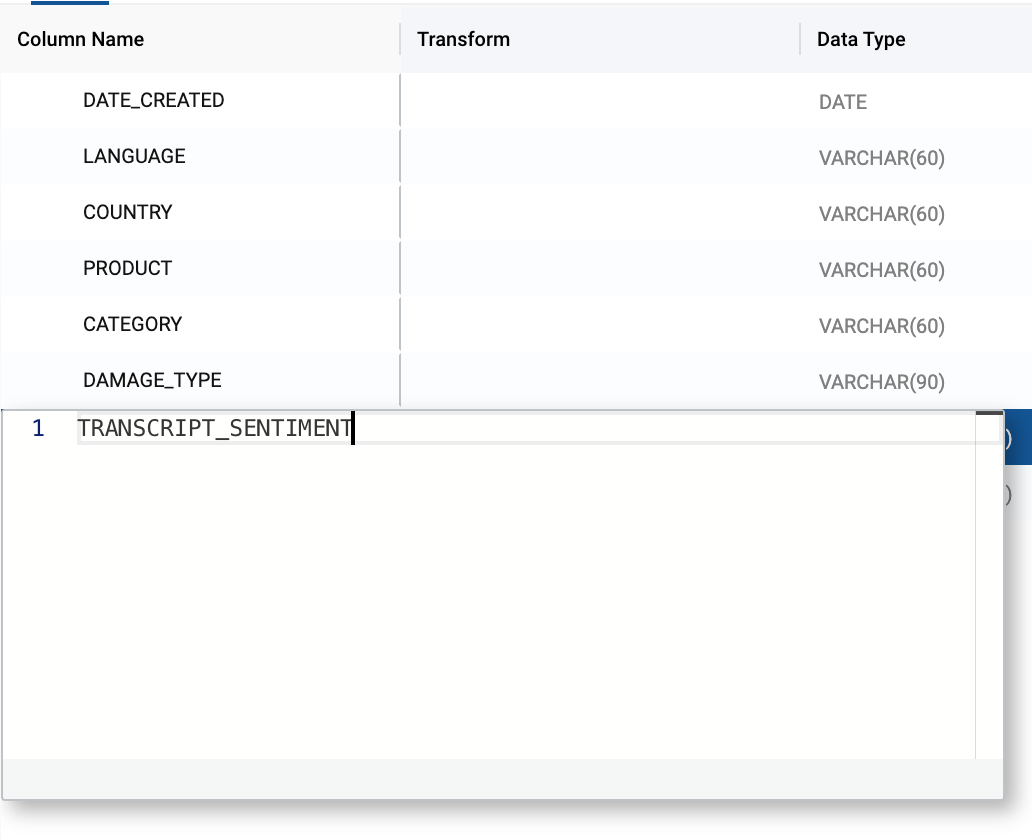
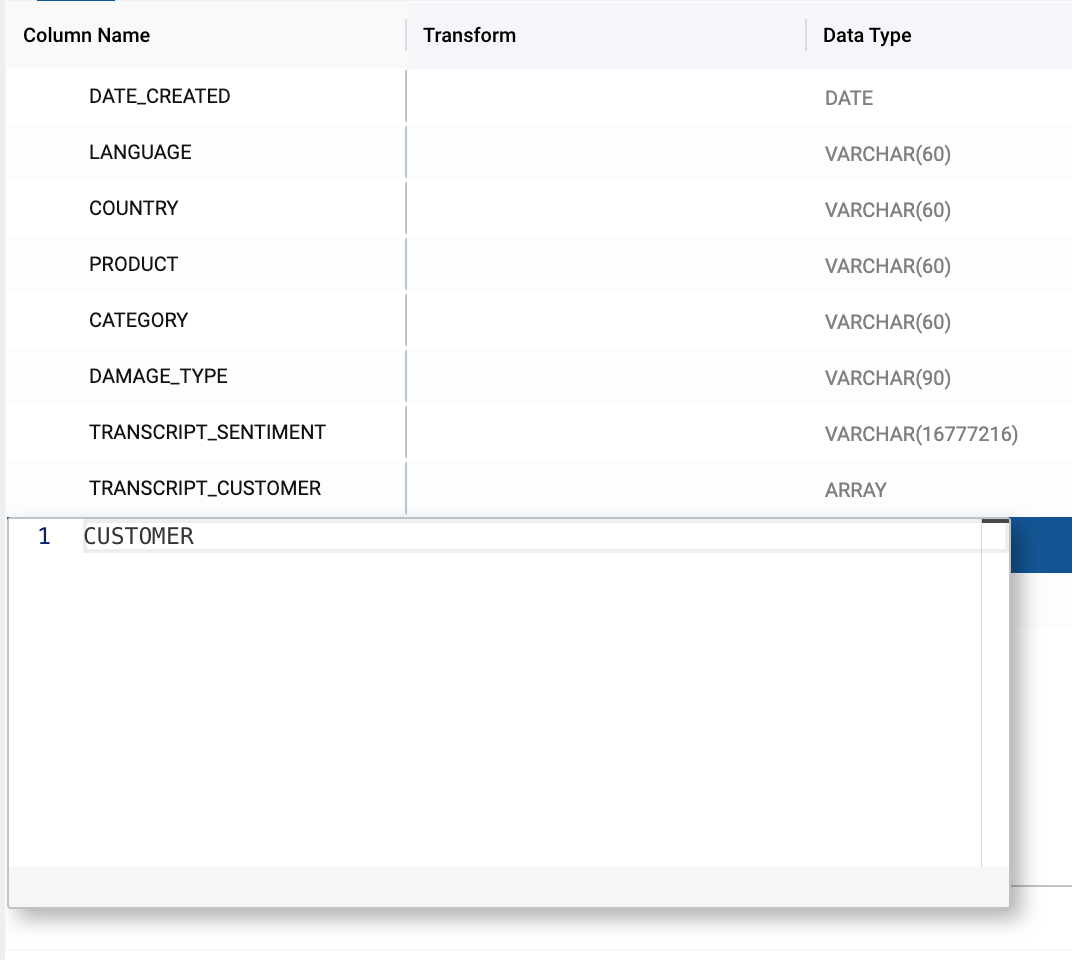
- Double click on the duplicated TRANSCRIPT column name and rename the column to TRANSCRIPT_CUSTOMER.
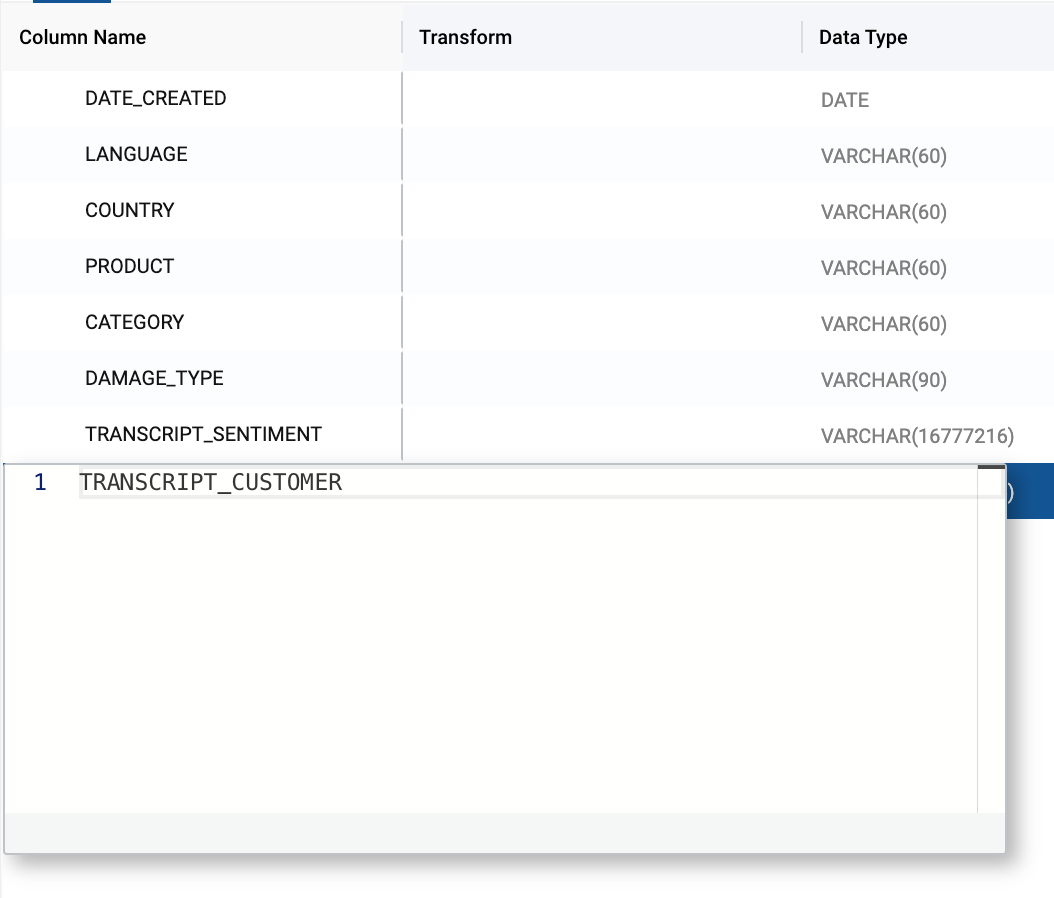
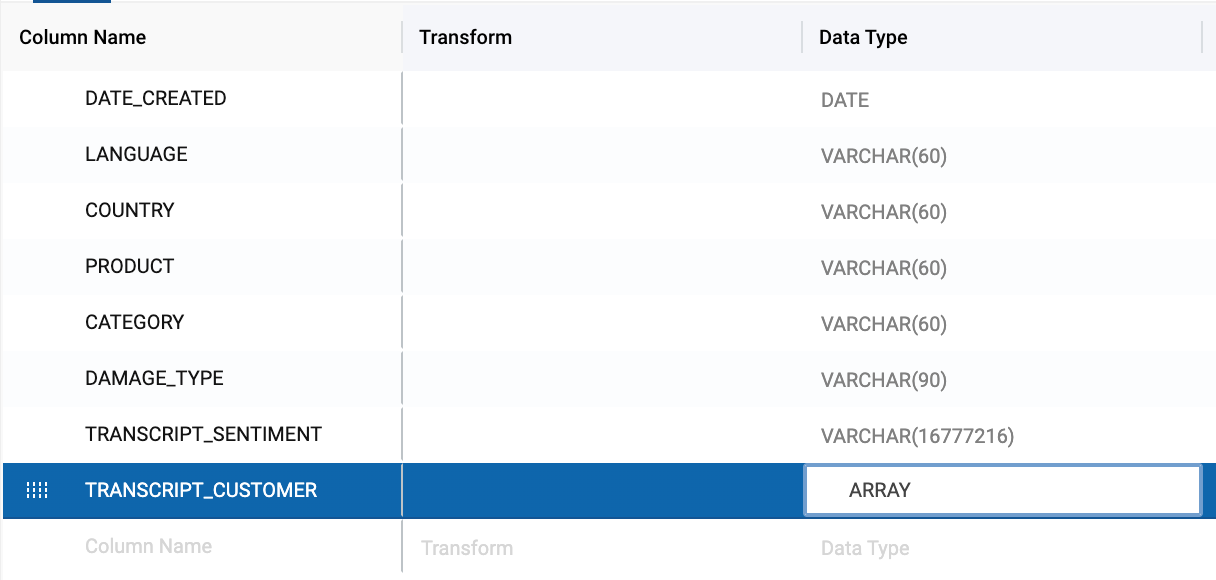
- Next, double click on the data type value for the TRANSCRIPT_CUSTOMER column. Change the data type to ARRAY. This is necessary because the output of the EXTRACT ANSWER function is an array that contains JSON values from the extraction.
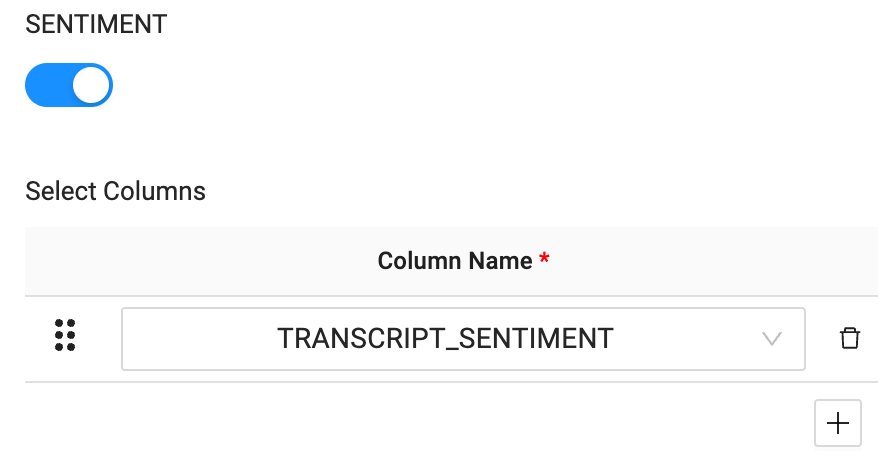
- Now that your columns are ready to be processed, we can pass them through to each function in the Cortex Package. For the SENTIMENT ANALYSIS, select the TRANSCRIPT_SENTIMENT column as the column name.
- For the EXTRACT ANSWER function, select the TRANSCRIPT_CUSTOMER column as the column name.
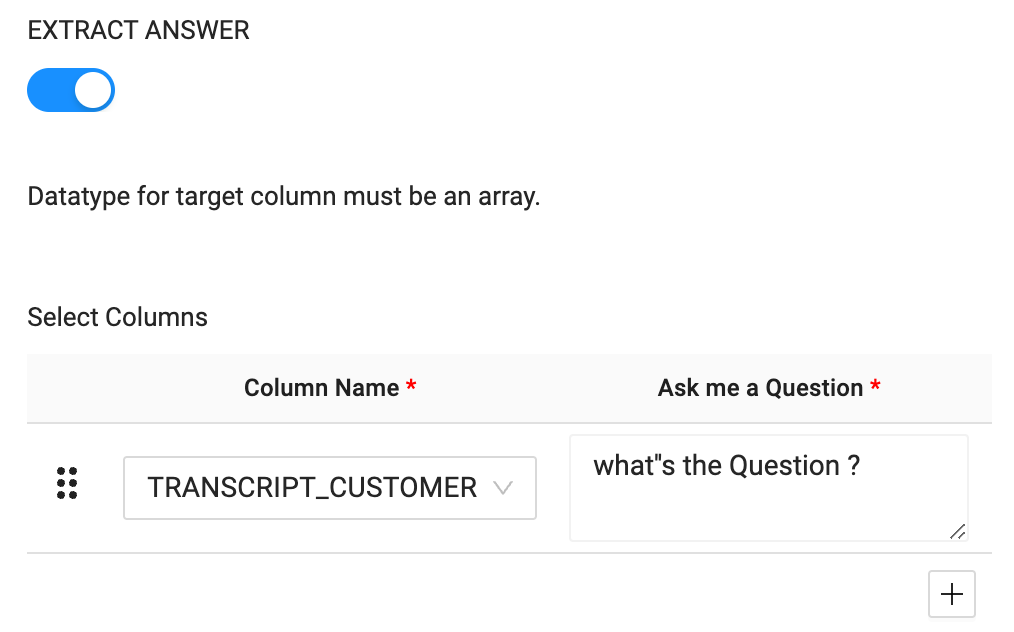
- The EXTRACT ANSWER function accepts a plain text question as a parameter to use to extract the values from the text being processed. In this case, we'll ask the question "Who is the customer?"
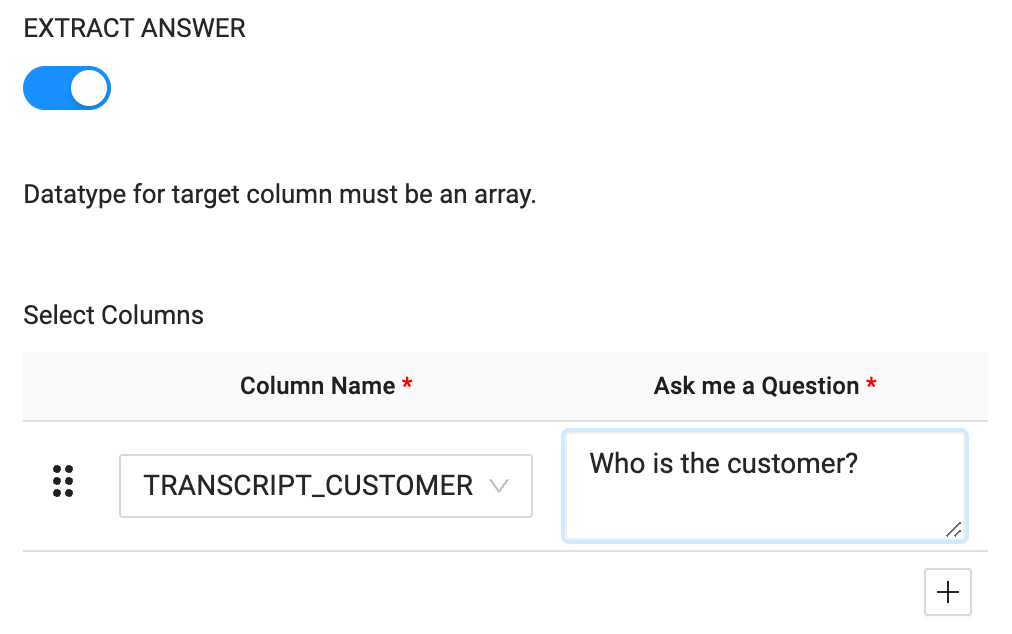
- With the node fully configured to process our sentiment analysis and answer extraction, you can Create and Run the node to build the object and populate it with the values being processed.
You have now used Cortex LLM Functions to process all of your text data without writing any code to configure the cortex functions, which are now ready for analysis. Let's perform some final transformations to expose for your analysis.
- Right click on the LLM_CALL_TRANSCRIPTS_ALL node and Add Node > View.
- Select the Create button and then Fetch Data. You will see the output from our LLM functions is the sentiment score and an array value containing a customer value with a confidence interval. We want to be able to extract the customer name out of the array value so we can associate the sentiment score with the customer name.Right click on the TRANSCRIPT_CUSTOMER column and hover over Derive Mappings and select From JSON.
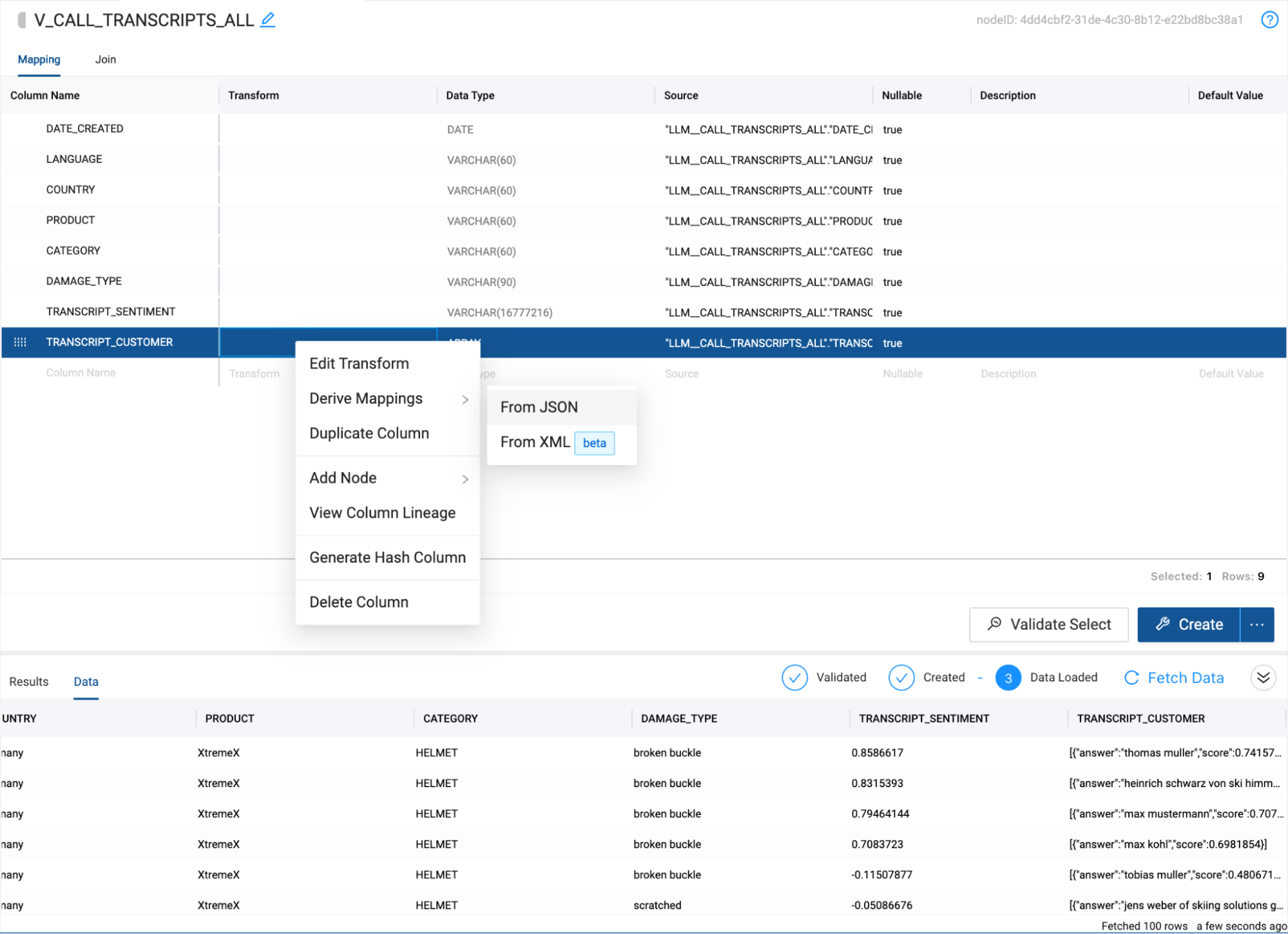
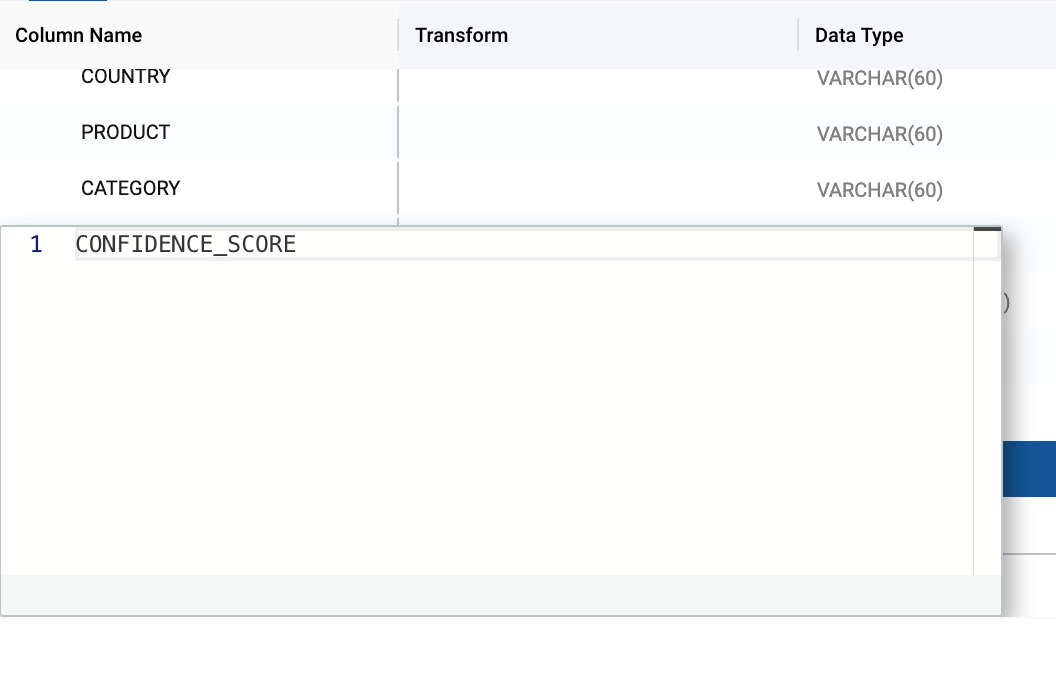
- You will see two new columns automatically created. Answer and score. The answer column contains our customer name. Double click on the answer column name and rename it to CUSTOMER.
- Rename the score column to CONFIDENCE_SCORE.
- Rerun the view by selecting Create, which will automatically rerun the query that generates the view, which will contain the updated CUSTOMER column we just created.
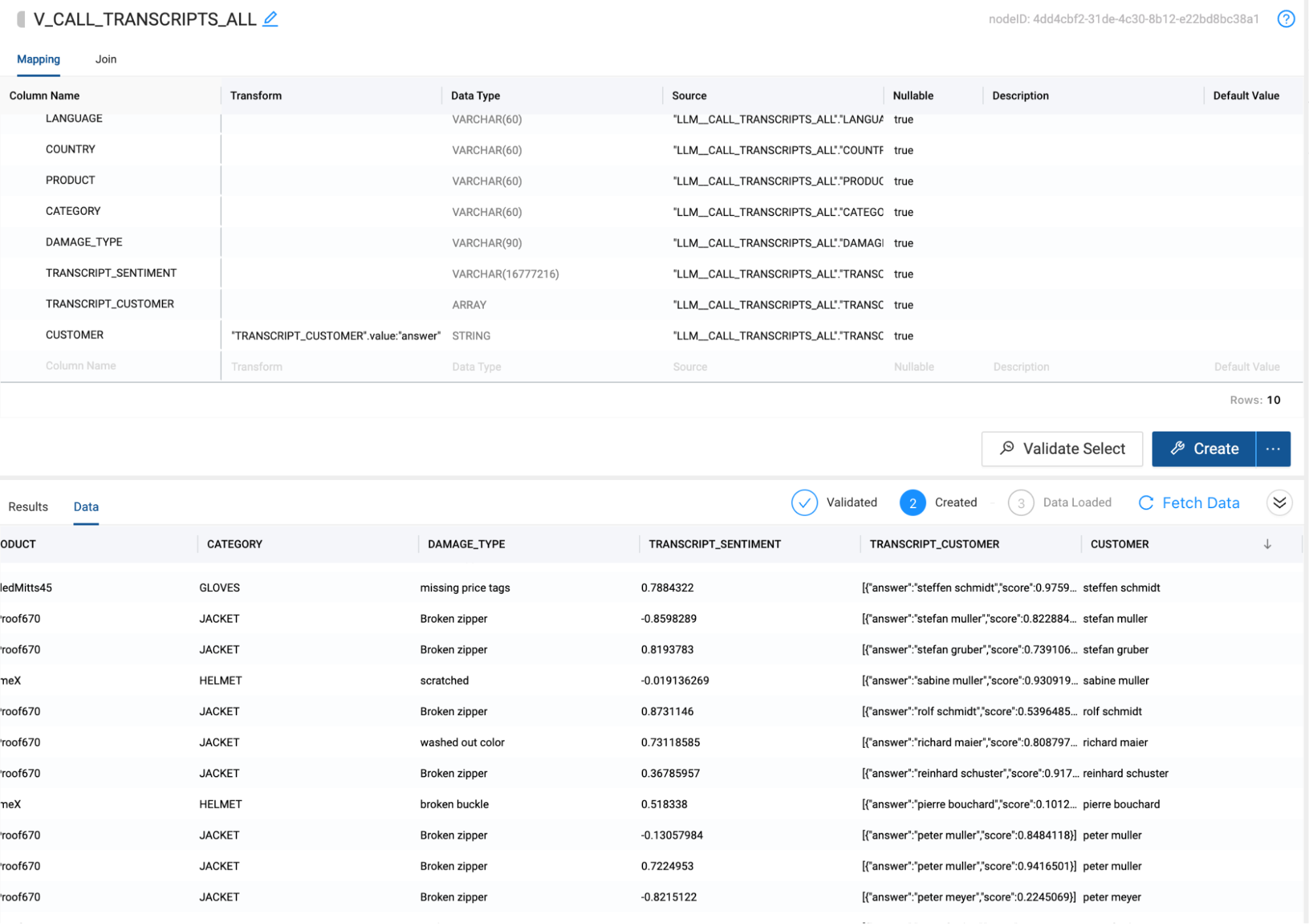
We now have a view that creates an output that can be used by our organization in a variety of ways. In some cases, other systems in our organization may need access to this output in order to allow our company to make decisions. In this case, we can allow everyone to operate on a single copy of data, by using Iceberg tables to output this data.
- Select the V_CALL_TRANSCRIPTS_ALL node and right click on the node. Select Add Node → Iceberg → Snowflake Iceberg Table. This will create a Snowflake managed Iceberg table in your object storage location.
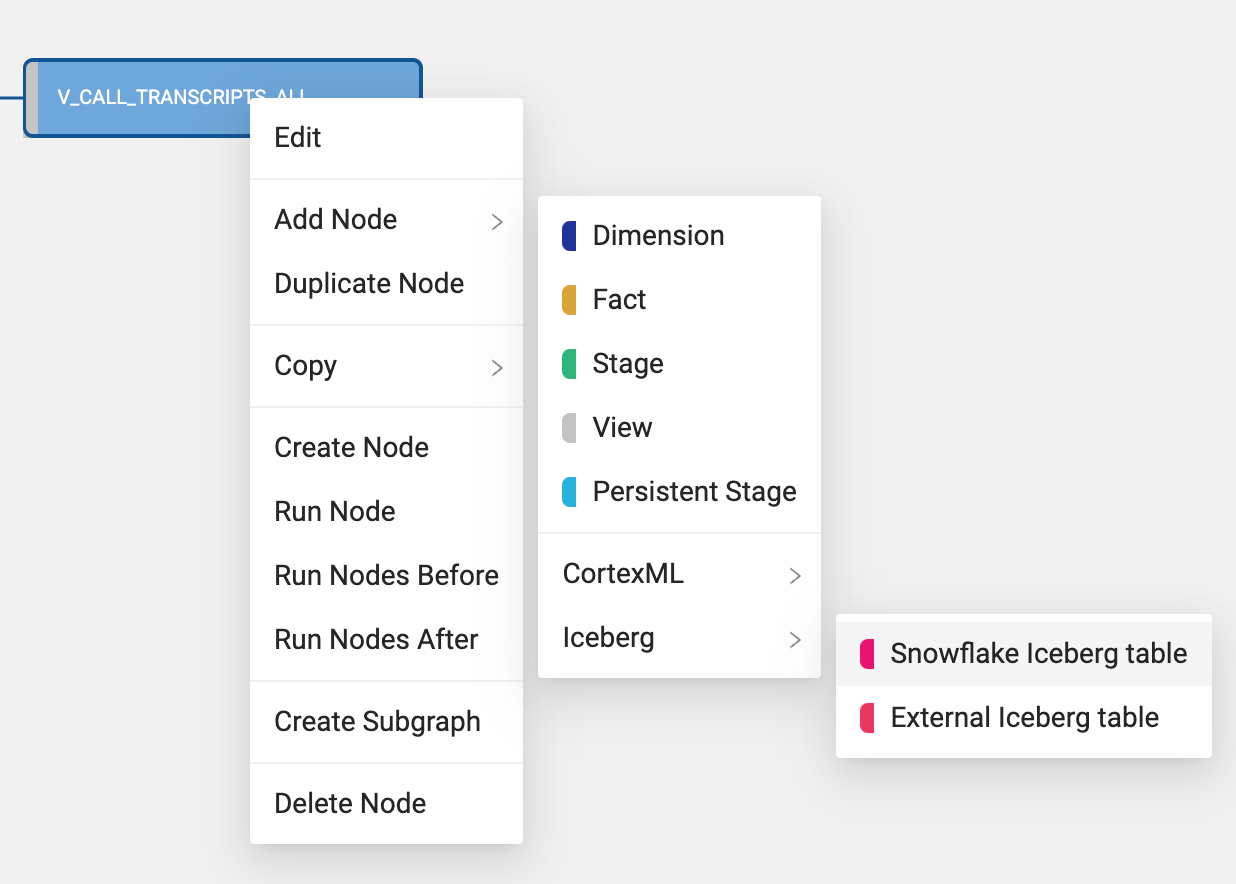
- Within the mapping grid, delete the TRANSCRIPT_CUSTOMER column which is an array data type, as Iceberg tables do not support array data types.
- Within the node, select the Iceberg Options dropdown.
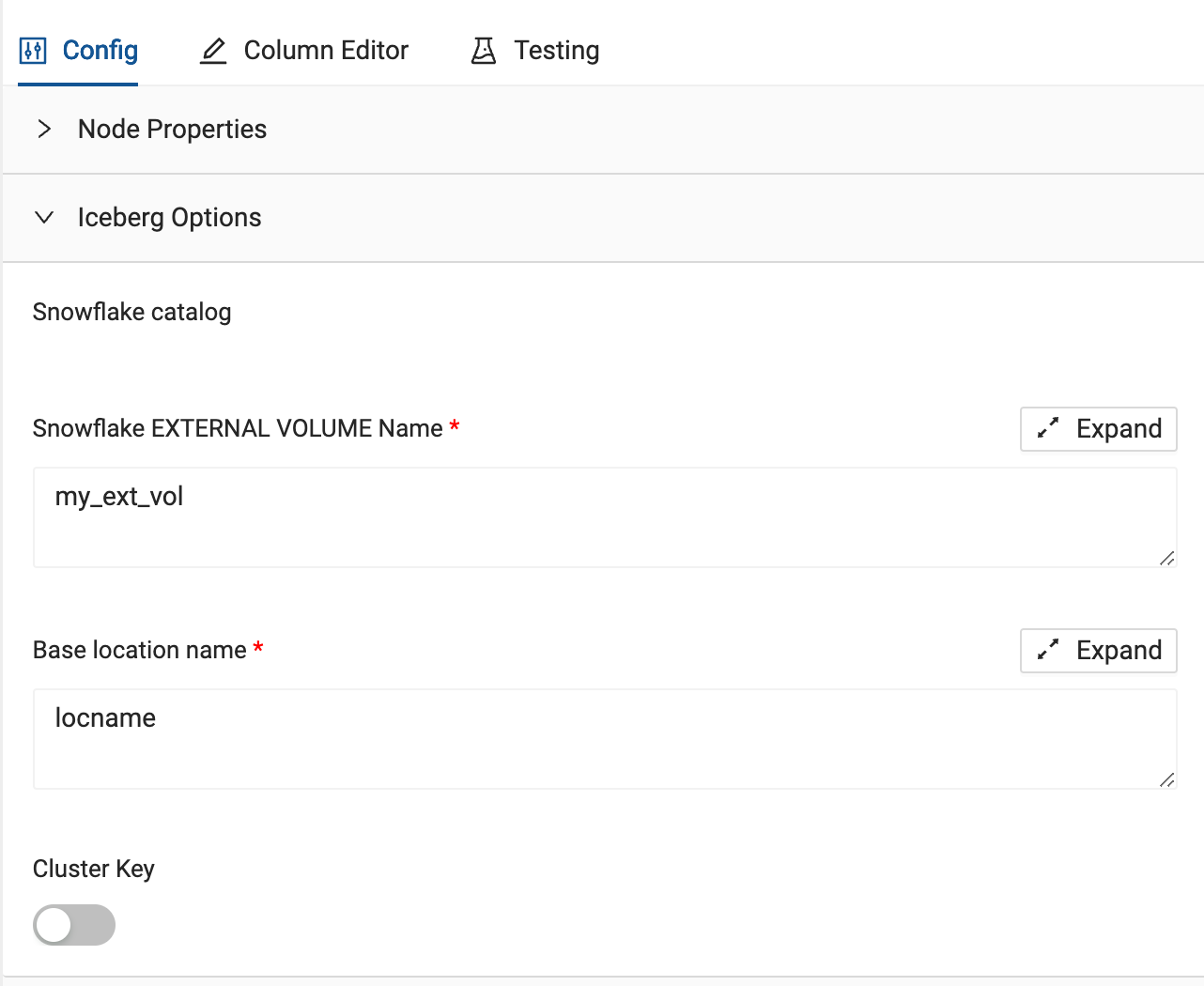
- For the External Volume, pass through the external volume that was configured in step 4 of the lab guide:iceberg_external_volume

- Next, provide a base location name to the base location parameter. This will be the folder location within S3 that the table will be created. For the sake of this lab, use your first name and iceberg_hol as the location name so everyone has their own separate folder i.e. firstname_iceberg_hol.

- Select Create and Run to create and populate the Snowflake managed table within S3.
Conclusion
Congratulations on completing your lab! You've mastered the basics of building and managing Snowflake Cortex LLM functions in Coalesce and can now continue to build on what you learned. Be sure to reference this exercise if you ever need a refresher.
We encourage you to continue working with Coalesce by using it with your own data and use cases and by using some of the more advanced capabilities not covered in this lab.
What You Learned
- How to navigate the Coalesce interface
- Load in iceberg tables
- How to add data sources to your graph
- How to prepare your data for transformations with Stage nodes
- How to union tables
- How to set up and configure Cortex LLM Nodes
- How to analyze the output of your results in Snowflake
Resources
Reach out to our sales team at coalesce.io or by emailing sales@coalesce.io to learn more!