In this guide, we'll be walking you through how to auto-ingest streaming and event-driven data from Twitter into Snowflake using Snowpipe. While this guide is Twitter-specific, the lessons found within can be applied to any streaming or event-driven data source. All source code for this guide can be found on GitHub. Let's get going!
Prerequisites
- Familiarity with command-line navigation
What You'll Need
- A Snowflake Account
- A Text Editor (such as Visual Studio Code)
- git
- Twitter Developer account (free)
- AWS account (12-month free tier)
What You'll Learn
- Data Loading: Load Twitter streaming data in an event-driven, real-time fashion into Snowflake with Snowpipe
- Semi-structured data: Querying semi-structured data (JSON) without needing transformations
- Secure Views: Create a Secure View to allow data analysts to query the data
- Snowpipe: Overview and configuration
What You'll Build
- A python application that listens and saves live tweets; those tweets are uploaded into Snowflake using AWS S3 as a file stage.
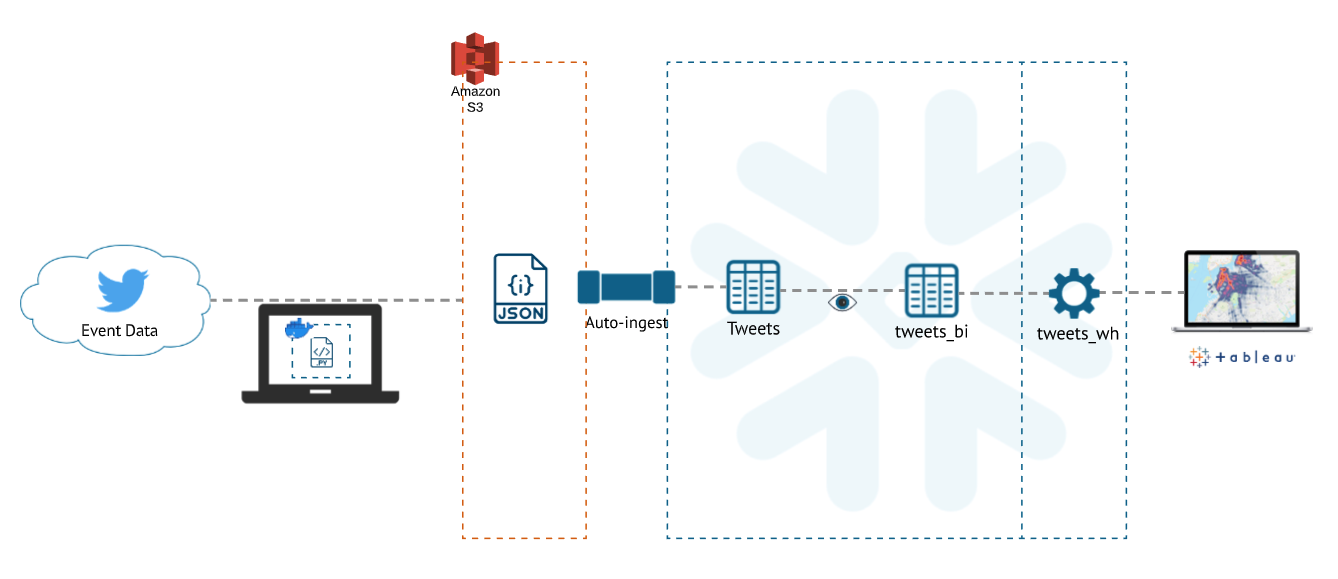
It's important to understand how the data flows within this application. This application consists of four main parts:
- A Python application: this is running locally and listens for live tweets using the Twitter REST API.
- An AWS S3 staging environment: this is used to store the live tweets from the Python application
- Snowpipe: this listens for new objects created in AWS S3 and ingests the data into a user-configured table in Snowflake
- Snowflake: we use Snowflake to directly query and transform the raw, semi-structured JSON data.
Architecture Diagram
The demo can be found as a repository on Snowflake's GitHub. After installing git, you can clone the repository using your terminal. Open a terminal and run the following line to clone the repository to your local system. It'll download the repository in your home folder by default, so you may want to navigate to another folder if that's where you want the demo to be located.
git clone https://github.com/Snowflake-Labs/sfguide-twitter-auto-ingest
Great! You now have the demo on your computer. You'll need to be in the repository to be able to modify it. Navigate to the repository using the following command:
cd sfguide-twitter-auto-ingest
Now that you're in the correct folder let's begin adding the correct information for you.
###Python dependencies
After downloading the repository, we need to install our python dependencies. Run the following commands:
pip install boto3
pip install awscli
pip install tweepy
pip install datetime
AWS configuration
- The AWS access keys can be found on the AWS Account and Access Keys page.
- The Twitter API and Access credentials can be found on the Twitter Developer Portal.
Now lets configure our AWS environment using the AWS information we have previously acquired. Run the commands:
aws configure set aws_access_key_id $AWS_Access_Key_ID
aws configure set aws_secret_access_key $AWS_Secret_Access_Key
There are two files you'll need to edit to specify your own credentials. The first file is twitter_local.py. Open the file with a text editor. The lines you need to edit start at line 30:
##############
# KEYS
##############
#get your Twitter API Key and Secret https://developer.twitter.com/en/apply-for-access
consumer_key = "*************************"
consumer_secret = "**************************************************"
# get your Twitter Access Token and Secret https://developer.twitter.com/en/apply-for-access
access_token = "**************************************************"
access_token_secret = "*********************************************"
#AWS bucket name
bucket = "my-twitter-bucket"
# specify your own default twitter keyword here.
keyword = "#covid"
You need to replace all the asterisk-filled strings with your own credentials. You can grab these from two places:
- The AWS access keys can be found on the AWS Account and Access Keys page.
- The Twitter API and Access credentials can be found on the Twitter Developer Portal.
The second file you need to modify is 0_setup_twitter_snowpipe.sql. Open the file and navigate to the section beginning on line 18. You'll need to replace the x-filled strings on lines 24 and 25 with your AWS credentials.
The other line you need to modify is line 23, which specifies the URL that directs to your AWS S3 bucket; this is where you want the data to be stored.
/*********************************************************************************
Create external S3 stage pointing to the S3 buckets storing the tweets
*********************************************************************************/
CREATE or replace STAGE twitter_db.public.tweets
URL = 's3://my-twitter-bucket/'
CREDENTIALS = (AWS_KEY_ID = 'xxxxxxxxxxxxxxxxxxxx'
AWS_SECRET_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx')
file_format=(type='JSON')
COMMENT = 'Tweets stored in S3';
Make sure to save both files. With both of them modified, you have now successfully added your AWS and Twitter credentials.
To run the application we run the following command:
python ./twitter_local.py
Running this command will provide an output that takes this form:
..................................................100 tweets retrieved
==> writing 100 records to tweets_20210129193748.json
==> uploading to #success/2021/1/29/19/37/tweets_20210129193748.json
==> uploaded to #success/2021/1/29/19/37/tweets_20210129193748.json
..................................................200 tweets retrieved
These are all the tweets being pulled. Now that we can pull the tweets in let's get it ingested with Snowpipe.
First, you'll need to login to your Snowflake account. Then, load the 0_setup_twitter_snowpipe.sql script. You can load a script into a Snowflake Worksheet via the three dots on the top right of the worksheet.
Within the SQL command interface, execute the script one statement at a time. If everything goes smoothly, you'll see information related to the pipe you created under "Results." Find the value under notification_channel and copy it, you'll need it in the next step.
Event notifications for your S3 bucket notify Snowpipe when new data is available to load. There are a variety of ways to configure event notifications in AWS S3. We have a section dedicated to the options here.
For this example, we'll be using SQS queues to deliver event notifications. First head over the S3 console. Click into the relevant bucket, then tab over to "Properties". Complete the fields as follows:
- Event Name: Name of the event notification (e.g. Auto-ingest Snowflake).
- Event types: Select "All object create events" option.
- Destination: Select SQS Queue, then "Enter SQS queue ARN", and past the SQS queue name from your SHOW PIPES output. Now Snowpipe with auto-ingest is operational!
The setup is now complete! You're good to go, but it's important to be cognizant of Twitter API rate limits. In order to not exceed Twitter API rate limits, you'll want to stop your python application.
To stop the python application type CTRL + C in the terminal your python application is running in.
Snowflake offers a lot of options for what you can do with this data once you've added it with Snowpipe. Check out our Getting Started with Python guide to see how you can use Python to empower your interactions with your data. And of course, be sure to check out the full documentation.
What we've covered
- Data Loading: Load Twitter streaming data in an event-driven, real-time fashion into Snowflake with Snowpipe
- Semi-structured data: Querying semi-structured data (JSON) without needing transformations
- Secure Views: Create a Secure View to allow data analysts to query the data
- Snowpipe: Overview and configuration